- The paper introduces a taxonomy and benchmark that decompose RAG difficulties into reasoning, retrieval, structure, and explainability.
- It evaluates two RAG systems on granular dimensions, showing marked improvements in retrieval while exposing persistent reasoning bottlenecks.
- The study highlights actionable metrics for enterprise RAG, guiding targeted investments to address system-level weaknesses.
Multi-Dimensional Diagnostic Evaluation for Enterprise RAG: A Comprehensive Framework and Benchmark
Motivation and Problem Statement
Enterprise environments feature domain-specific requirements that challenge the deployment of Retrieval-Augmented Generation (RAG) systems beyond the simple metric of end-to-end QA accuracy. Critical factors include complex multi-hop reasoning, retrieval over highly structured documents (e.g., financial reports, compliance documents), a need for strong evidence traceability, and multifaceted explainability constraints. Existing academic benchmarks tend to reduce evaluation to monolithic metrics, making it impossible to localize system failure points or to predict performance on production-relevant tasks. This work addresses these deficits by proposing a taxonomy of RAG difficulties and introducing a benchmark dataset with granular diagnostic labels, facilitating targeted analysis of RAG model weaknesses in realistic enterprise scenarios.
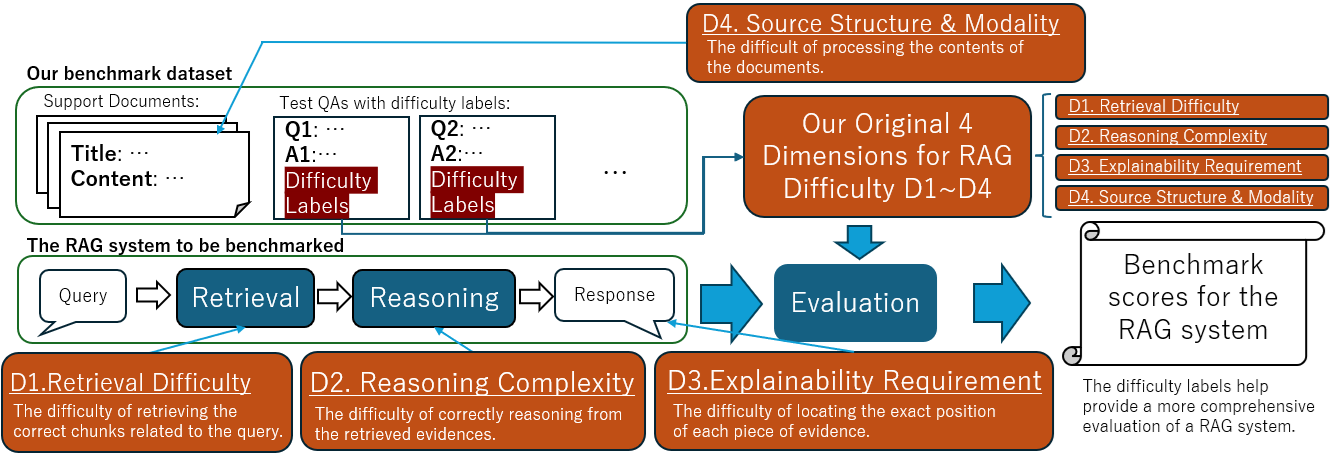
Figure 1: An overview of the evaluation framework in the proposed benchmark, with each query tagged along four axes derived from an original taxonomy of RAG difficulty.
Taxonomy of Enterprise RAG Challenges
The proposed framework decomposes RAG difficulty into four independent, operationally significant axes:
- Reasoning Complexity: Decomposition into Reasoning Depth (multi-step reasoning), Operation (quantitative calculation, negation, causal/temporal reasoning), and required output processing (e.g., summarization, translation). This axis is critical for isolating LLM-specific bottlenecks.
- Retrieval Difficulty: Captures the challenge of locating evidence, including evidence dispersion across documents/chunks, scale (number and size of candidate documents), and semantic divergence between query and evidence (abstraction gap, vocabulary mismatch).
- Source Structure and Content Modality: Focuses on the need for handling non-textual evidence (tables, images, complex layouts), essentially evaluating the LLM's competence in extracting information from enterprise-relevant heterogeneous data formats.
- Explainability Requirement: Measures the strictness of evidence presentation, from coordinate-level bounding-boxes to reference hierarchies, reflecting enterprise demands for regulatory compliance and auditability.
Annotation of evaluation instances along these axes enables systematic bottleneck identification, permitting a fine-grained diagnostic profile for both retrieval and inference components.

Figure 2: Examples of an evidence chunk demonstrating structured, non-plain-text content from the Information and Communications in Japan White Paper 2024, as used in the benchmark.
Benchmark Dataset Construction
A challenging dataset was curated from real-world enterprise sources including financial reports and technical specifications. Key statistics:
- 34 source documents, 1699 total pages
- 100 QA queries, each annotated with difficulty metadata along the four axes
- Average of 51.5 chunks per document; queries typically reference an average of 2 evidence sources
- Chunks defined at the page level, with bounding box annotation for answer evidence when strict explainability is required
Query and evidence structure are directly tied to enterprise operational needs. For instance, a query may require multi-hop reasoning over a chart, targeting a small table region, necessitating precise chunk retrieval and extraction over highly-structured content.
Experimental Evaluation and Results
Two RAG systems were evaluated:
- MRI-RAG: Baseline using multi-representation-indexing and standard zero-shot LLM inference (GPT-4o-mini).
- Agentic AI: Agent-based system featuring explicit query decomposition, hybrid filtering (vector + keyword search with RRF), and answer generation on filtered evidence.
Both systems were tested on the new dataset and on JDocQA, a comparable Japanese document QA benchmark.
Key findings:
- On the proposed dataset, Overall Accuracy was universally low (MRI-RAG: 9.0%, Agentic AI: 17.0%), confirming the much higher difficulty compared to traditional benchmarks.
- Dimensional Diagnostic Accuracy (D-value) illuminated strengths and weaknesses not visible via single-figure metrics:
| Dimension | MRI-RAG | Agentic AI |
|-------------------------------|---------|------------|
| Reasoning Complexity | 2.5 % | 5.0 % |
| Retrieval Difficulty | 0.0 % | 12.0 % |
| Source Structure/Modality | 10.0 % | 20.0 % |
| Explainability Requirement | 9.1 % | 17.2 % |
Agentic AI's multi-step query decomposition and robust filtering drive a marked improvement in Retrieval Difficulty (0% → 12%) and Source Structure/Modality (10% → 20%), directly mapping to the agentic mechanism's ability to overcome document dispersion and complex structural features. However, the gain in Reasoning Complexity remains marginal (+2.5 pt), indicating that LLM reasoning and information integration still represent the primary performance bottleneck, particularly for composite and multi-step queries.
Implications and Future Directions
This diagnostic framework exposes dimensions where targeted system improvement is necessary. Specifically, while retrieval enhancements (including query analysis, chunk filtering, hybrid search, and RRF) provide measurable advances, the lack of significant improvement in reasoning tasks points towards the limits of current LLM inference capabilities—notably in multi-hop, arithmetic, and logic-intensive enterprise queries.
Enterprise adoption of RAG can benefit from diagnostic metrics that inform data, model, and system-level interventions. Such metrics enable precise investment in toolchain improvements (retriever, LLM, or system-level orchestration agents) rather than relying on undifferentiated overall scores that can misrepresent deployed performance.
There is a strong argument for further developing benchmarks that quantify not only difficulty but also cost-performance tradeoffs—such as latency and resource utilization—enabling balanced evaluation aligned with enterprise production constraints. The current benchmark provides a road-map: it will evolve to address more diverse domains, scale to larger query sets, and model dynamic interactions among dimensions (e.g., when high retrieval and reasoning difficulty co-occur).
Conclusion
The proposed multi-dimensional diagnostic framework and benchmark dataset deliver a rigorous methodology for identifying latent bottlenecks in RAG system deployment for enterprise applications. Explicit annotation of queries along Reasoning Complexity, Retrieval Difficulty, Source Structure/Modality, and Explainability Requirement allows for a comprehensive bottleneck analysis at the system and component level. Empirical results demonstrate that conventional accuracy metrics obscure critical weaknesses relevant for enterprise adoption; agentic modular improvements drive advances in retrieval but not in LLM reasoning. Future work will expand the framework to include broader domain coverage, composite evaluation metrics, and operational efficiency analysis, offering a scalable approach to Enterprise RAG system evaluation.