AI scientists produce results without reasoning scientifically
Abstract: LLM-based systems are increasingly deployed to conduct scientific research autonomously, yet whether their reasoning adheres to the epistemic norms that make scientific inquiry self-correcting is poorly understood. Here, we evaluate LLM-based scientific agents across eight domains, spanning workflow execution to hypothesis-driven inquiry, through more than 25,000 agent runs and two complementary lenses: (i) a systematic performance analysis that decomposes the contributions of the base model and the agent scaffold, and (ii) a behavioral analysis of the epistemological structure of agent reasoning. We observe that the base model is the primary determinant of both performance and behavior, accounting for 41.4% of explained variance versus 1.5% for the scaffold. Across all configurations, evidence is ignored in 68% of traces, refutation-driven belief revision occurs in 26%, and convergent multi-test evidence is rare. The same reasoning pattern appears whether the agent executes a computational workflow or conducts hypothesis-driven inquiry. They persist even when agents receive near-complete successful reasoning trajectories as context, and the resulting unreliability compounds across repeated trials in epistemically demanding domains. Thus, current LLM-based agents execute scientific workflows but do not exhibit the epistemic patterns that characterize scientific reasoning. Outcome-based evaluation cannot detect these failures, and scaffold engineering alone cannot repair them. Until reasoning itself becomes a training target, the scientific knowledge produced by such agents cannot be justified by the process that generated it.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: Can today’s AI “scientists” really think like scientists, or do they just produce answers that look right?
The authors test LLM–based agents that are meant to run parts of scientific research on their own. They show that while these AIs can follow instructions well (like running a recipe), they often don’t reason like real scientists (like detectives who form ideas, test them, and change their minds based on evidence).
What questions did the researchers ask?
They focused on two big questions:
- Do AI agents follow the key habits of scientific thinking—like testing ideas, using evidence, and updating beliefs when data disagree?
- What matters more for success: the AI’s “brain” (the base model) or the “wrapper” around it (the scaffold) that organizes prompts, tools, and steps?
How did they study it?
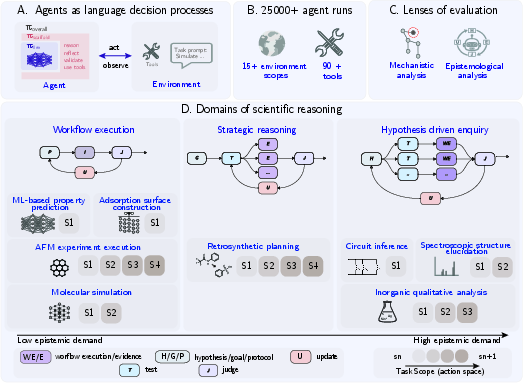
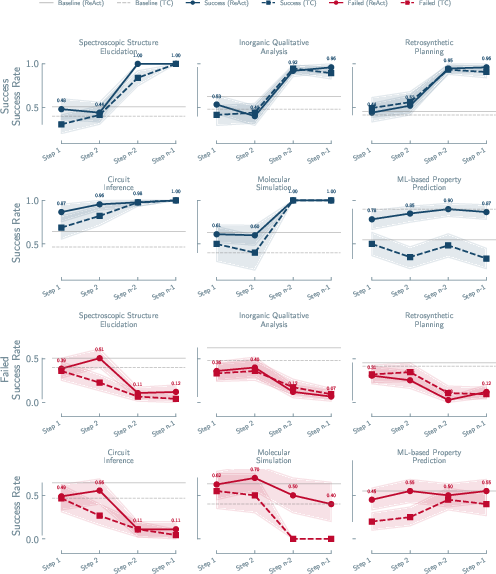
The team ran over 25,000 experiments across eight science areas (like running lab analyses, planning chemical syntheses, identifying molecules from spectra, simulating materials, and solving circuits). They examined AI agents in two complementary ways:
1) Performance: what got done
They measured how well agents completed tasks of different types:
- “Recipe-like” tasks (workflow execution): The path to the answer is clear; the agent must do the steps correctly (e.g., run a simulation, train a model).
- “Strategy” tasks: The agent must plan carefully in a big search space (e.g., planning a multi-step synthesis).
- “Detective” tasks (hypothesis-driven): The agent must guess hidden facts, design tests, gather evidence, and change its mind if needed (e.g., figuring out an unknown molecule from lab data).
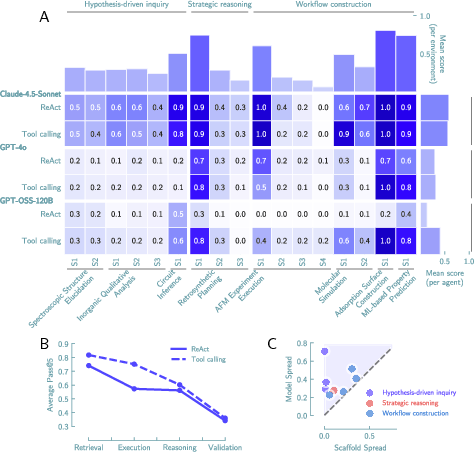
They tested three strong base models and two scaffolds (ways of organizing the agent’s steps, such as ReAct and structured tool-calling) to see which parts mattered most.
Think of:
- Base model = the AI’s “brain.”
- Scaffold = the “coach” or “planner” that gives the brain tools, formats, and a loop for acting and observing.
2) Behavior: how the AI reasoned
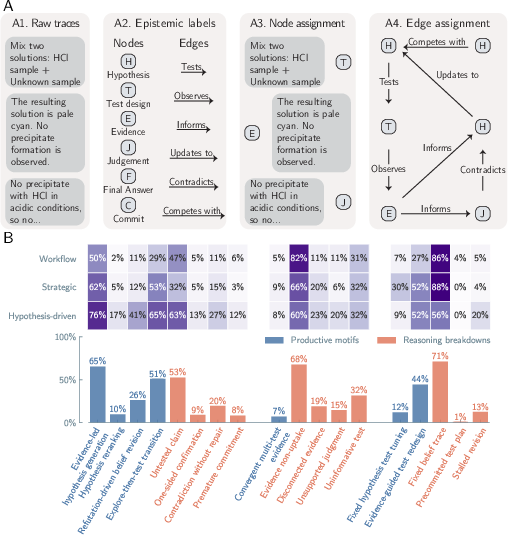
They looked inside the agents’ reasoning traces (the step-by-step thoughts and actions) and tagged each step as:
- H: Hypothesis (a guess)
- E: Evidence (data gathered)
- T: Test (an action that could confirm/refute a guess)
- J: Judgment (does the evidence support the guess?)
- U: Update (change the belief)
- C: Commitment (final choice)
They then checked for good patterns (like “guess → test → update”) and bad ones (like ignoring evidence or never testing a claim).
Extra tools and checks
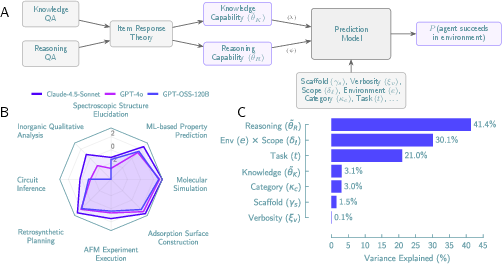
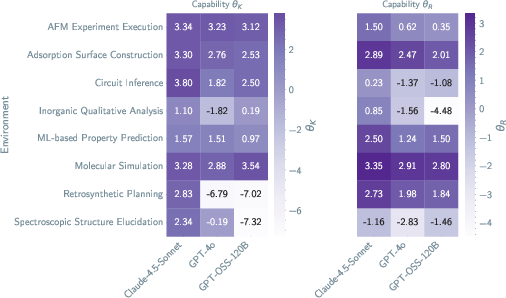
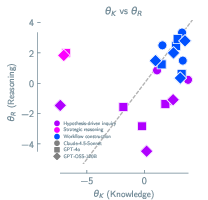
- Knowledge vs. reasoning “quizzes”: They built question sets to separately test factual knowledge and reasoning skills. Using a method called item response theory (think: a smart way to score quizzes that adjusts for question difficulty), they estimated each model’s knowledge and reasoning ability.
- Trace “hints” experiments: They tried giving agents partial “solution steps” from past runs to see if that would help—like giving a student hints from a previous correct solution.
What did they find, and why is it important?
Here are the main takeaways:
- The AI’s “brain” matters far more than the “wrapper.”
- The base model explained most of the differences in how well agents did and how they behaved.
- Numbers: reasoning ability explained about 41% of the success, while the scaffold explained about 1.5%.
- Great at following recipes, weak at being detectives.
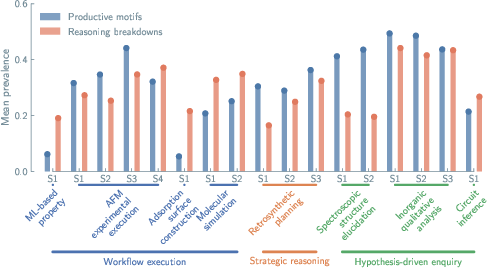
- Agents did well on clear, step-by-step tasks (like running simulations or training ML models).
- Performance dropped as tasks required more scientific thinking (forming and testing hypotheses, revising beliefs).
- The agents often ignored evidence and didn’t update beliefs.
- Evidence was ignored in 68% of reasoning traces.
- Only 26% showed “I changed my mind because the data refuted my idea.”
- Using multiple independent tests to confirm a conclusion was rare (7%).
- Same “thinking style” no matter the task.
- Whether the task needed careful testing or just execution, agents tended to use the same patterns.
- Stronger models produced more steps and fetched more facts, but they didn’t show more scientific “epistemic” discipline (like testing and revising).
- Giving partial hints helped only for recipe-like tasks.
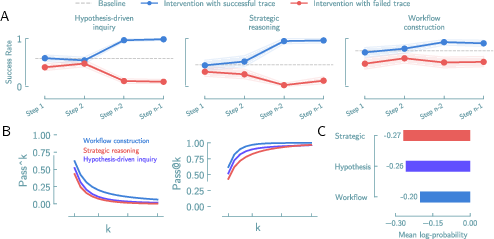
- In workflow tasks, a few helpful steps boosted success.
- In detective-style tasks, agents needed almost the entire successful path to improve—small hints didn’t fix their reasoning.
- Repeating attempts didn’t make them reliable in detective-style tasks.
- Even trying several times, consistent success stayed low for the hardest, most scientific problems.
Why this matters: In science, how you reach a result is as important as the result. If an AI lands on a correct answer but got there by ignoring evidence or skipping tests, we can’t trust it to generalize to new problems—or to alert us when it’s wrong.
What does this mean going forward?
- Don’t judge AI “scientists” only by whether they get the right answer; judge how they think. We need evaluations that check for real scientific habits: forming testable ideas, using evidence correctly, and updating beliefs when data disagree.
- “Scaffold engineering” (just changing prompts, tool wrappers, or workflows) won’t fix the core issue. The reasoning style seems to come from the base model itself.
- Training should target reasoning, not just predicting the next word. Models need incentives and feedback that reward proper scientific thinking patterns.
- Be cautious when using AI agents to produce new scientific knowledge. Until their reasoning becomes more scientific, their results may not be trustworthy by scientific standards.
- The authors provide a shared evaluation framework and environments so the community can measure and improve AI reasoning over time.
In short: Today’s AI agents can run the steps of science, but they often don’t think like scientists. To make AI a trustworthy partner in discovery, we must teach and test it on the process of good scientific reasoning—not just the outcomes.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the study, framed to guide concrete follow-up work.
- Limited model diversity: Only three base models (two closed-source, one open-source) were evaluated; conclusions about “base model dominance” need testing across broader families (e.g., smaller/older models, multilingual models, non-LLM planners, vision-LLMs).
- Narrow scaffold coverage: Only ReAct and structured tool-calling were tested; more expressive scaffolds (e.g., belief-state tracking, planning graphs, self-verification, debate/adversarial critique, multi-agent protocols, memory/working-memory modules) were not assessed.
- Temperature and sampling strategies: All runs used temperature 0.0, leaving untested whether stochastic exploration, best-of-n, self-consistency, or diverse decoding improves hypothesis testing, belief revision, or reliability.
- Iteration/compute budget constraints: Fixed iteration limits were imposed, but the sensitivity of epistemic behavior to larger budgets (more cycles, tool calls, or longer contexts) was not explored.
- Generalization beyond eight domains: Tasks are concentrated in chemistry, materials, circuits, and a single instrument (AFM). External validity to other scientific fields (e.g., biology, ecology, medicine, fluid dynamics, astronomy) remains untested.
- Real-world lab variability: Most environments are simulated or procedurally controlled; the impact of noisy, incomplete, or contradictory real-world measurements (sensor noise, failed experiments, instrument drift) on epistemic behavior is unknown.
- Multimodality limits: While instruments and spectra are available via tools, the study does not assess agents’ reasoning when directly interpreting raw multimodal inputs (e.g., images, spectra plots, microscopy videos) with vision-LLMs.
- Human baseline comparison: No side-by-side evaluation against human students/experts performing the same tasks; the magnitude and nature of the gap between agents and humans (including error patterns) remains unknown.
- Diagnostic QA validity: The IRT-based separation of “knowledge” vs “reasoning” depends on researcher-authored items; item independence, construct validity, and susceptibility to training-data leakage were not validated against external psychometrics.
- LLM-based epistemic annotation reliability: Large-scale epistemology labels were produced with an LLM (Claude Sonnet 4.5). Robustness of these labels (e.g., inter-method agreement with humans, sensitivity to prompt phrasing, cross-model bias) is not reported.
- Scope of manual validation: Only 773 traces were manually annotated by two experts; inter-annotator agreement metrics, sampling strategy, and representativeness of those traces are not detailed.
- Metric construct adequacy: The epistemic-graph taxonomy emphasizes operations like H/E/T/J/U/C; whether this schema fully captures legitimate scientific strategies (e.g., Bayesian updating, exploratory heuristics, abductive loops with pragmatics) is unexamined.
- Process vs outcome metric alignment: The link between proposed process metrics (evidence uptake, refutation-driven updates, convergent evidence) and downstream scientific utility (novelty, replicability, predictive value) remains to be empirically established.
- Causality of evidence non-uptake: It is unclear whether non-uptake stems from model limitations, token budget/context overflow, tool interface frictions, docstring design, or prompt framing; targeted ablations are needed.
- Tool verbosity effects: Main results focus on brief docstrings; the impact of more comprehensive tool documentation on epistemic patterns is deferred to the appendix and not analyzed in depth.
- Tool reliability and ambiguity: Tools return deterministic, clean signals; how agents handle ambiguous, low-SNR, or conflicting tool outputs is not tested.
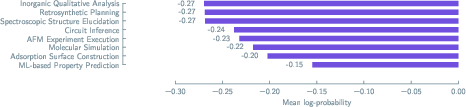
- Token-level confidence generality: Log-probability analyses rely on a single open-source model; whether token-level confidence predicts intervention recoverability across closed-source models remains an open question.
- Reliability under adaptive memory: The “probability all k trials succeed” was measured with independent trials; whether memory across trials (meta-learning/retrospective reflection) improves reliability is unknown.
- Best-of-n vs all-k reliability: The study highlights decay of P(all k succeed); analysis of P(at least one succeeds), expected best-of-n performance, and optimal sampling/selection strategies is missing.
- Effectiveness of social scaffolds: Peer-review-like multi-agent setups (critic–proposer, debate, argumentation frameworks) were not tested; whether social mechanisms induce refutation and belief revision remains open.
- Training interventions: The work argues for training on reasoning processes but does not test specific methods (e.g., process supervision, RL from epistemic feedback, counterfactual data augmentation, refutation traces, multi-evidence curricula).
- Data for epistemic training: Practical pathways for sourcing/curating process-level supervision (labeled epistemic graphs, falsification examples, multi-test convergence) and their annotation cost/quality are unspecified.
- Dynamic task difficulty and curricula: How reasoning behavior evolves under systematically staged curricula (increasing ambiguity, conflicting evidence, cost constraints) was not explored.
- Memory and belief-state modeling: Agents were not required to maintain explicit, queryable belief states; whether structured internal state (e.g., probabilistic hypotheses, test–evidence links) improves evidence uptake and belief updating is untested.
- Interpretability of failures: No mechanistic interpretability or probing of model internals was performed to identify why evidence is ignored or hypotheses remain untested.
- Context-length and long-horizon effects: The impact of very large contexts (longer histories, richer lab notebooks) on maintaining and revising beliefs was not assessed.
- Interface design sensitivity: Variations in tool APIs, error messaging, and affordances (e.g., explicit cost signals, uncertainty flags) were not ablated for their influence on epistemic behavior.
- Continual learning and adaptation: The study does not examine whether agents improve epistemic behavior over repeated exposures or with environment-specific fine-tuning.
- Governance and misuse: If agents produce results without epistemic justification, how institutions should evaluate, audit, or constrain AI-generated scientific claims remains unresolved.
- Multilingual and cross-cultural science: All evaluations appear in English; whether epistemic patterns change in other languages or cultural scientific practices is unknown.
- Reproducibility constraints: Use of closed-source frontier models limits exact replication; a standardized open set of strong baselines and trace datasets for process-level benchmarking is needed.
- External benchmark alignment: How the proposed epistemic metrics correlate with success on existing agent/science benchmarks (e.g., re-implementation under peer review, open-ended discovery) was not quantified.
- Scaling laws for epistemic behavior: The dependence of evidence uptake, refutation rate, and convergence motifs on model size, training data composition, or instruction/process-supervision intensity is not mapped.
- Cross-domain transfer: Whether improvements in epistemic behavior in one domain transfer to others (e.g., from circuits to spectroscopy) is untested.
- Robustness to prompt variations: Sensitivity of epistemic behavior to small changes in task prompts, instructions about scientific norms, or meta-prompts enforcing falsification was not systematically measured.
- Heteroscedastic cost–information tradeoffs: While some tasks include costful tests (e.g., HSQC), agents’ ability to plan under heterogeneous costs/uncertainties and to compute value of information remains unquantified.
- Comparison to symbolic/explicit pipelines: Baselines like expert systems (e.g., DENDRAL-like rule engines) or programmatic planners were not included for direct process-level comparison.
- Negative evidence handling: Beyond “non-uptake,” detailed characterization of how agents treat negative or contradictory results (e.g., weighting, dismissal, re-testing) is missing.
- Failure taxonomy granularity: Epistemic “anti-patterns” were tallied, but fine-grained causal chains (e.g., misinterpretation → wrong test → failure to update) and their relative frequencies were not distilled to guide targeted fixes.
- Tool-choice optimization: Exploration vs exploitation and test selection policies (e.g., adaptive experiment design/value-of-information heuristics) were not benchmarked against agent strategies.
- Open-ended science tasks: The environments are goal-directed with clear scoring; whether agents can sustain epistemically disciplined open-ended exploration (e.g., hypothesis generation without a known ground truth) remains an open frontier.
Practical Applications
Below is a concise synthesis of practical applications derived from the paper’s findings and tools. Applications are grouped by deployment horizon and annotated with sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
- Industry (R&D, materials, chemistry, biotech): Pre-deployment epistemic audits of AI agents
- What to do: Use the paper’s Corral framework and environments to evaluate agents not only on task success but on epistemic behavior (evidence uptake, hypothesis testing, belief revision).
- Tools/workflows: Corral environments (spectroscopy, qualitative analysis, retrosynthesis, molecular simulation), automated trace-annotation to tag H/E/T/J/U/C operations, pass@5 plus reasoning-pattern metrics.
- Assumptions/dependencies: Access to model APIs; ability to log and store full traces; some environments require backends (e.g., LAMMPS, AFM).
- Software/ML Platforms: Add epistemic metrics to agent platforms
- What to do: Integrate logging that extracts and graphs epistemic operations; compute rates of evidence non-uptake, untested claims, refutation-driven updates; alert on anti-patterns.
- Tools/products: “Reasoning dashboards,” annotation pipelines, topology-based motif detectors.
- Assumptions/dependencies: Token- and step-level logs; consistent tool schemas; API support for structured tool calls.
- Procurement & Vendor Selection (all sectors using AI agents): Prioritize base model choice over scaffolds
- What to do: Evaluate multiple base models in the same scaffold; select by domain-specific IRT-derived reasoning/knowledge scores rather than scaffold features.
- Tools/workflows: IRT-based capability profiling; controlled A/B tests with identical tools and prompts.
- Assumptions/dependencies: Comparable access/pricing across base models; reproducible runs.
- MLOps/AI Governance (cross-industry): Human-in-the-loop gating by epistemic risk
- What to do: Route hypothesis-driven tasks to human review when log-probabilities fall below thresholds and/or when anti-patterns are detected; rely on agents mainly for workflow execution tasks where performance approaches ceiling.
- Tools/workflows: Risk policies tied to token-level logprobs, anti-pattern scores, and “P(all k trials succeed)” reliability curves.
- Assumptions/dependencies: APIs exposing logprob or proxy confidence; operational SLAs for human escalation.
- Scientific Publishing & Peer Review (academia, publishers): Require process evidence for AI-generated results
- What to do: Ask for reasoning traces and epistemic graphs as supplementary materials; include checklists for evidence integration and belief revision.
- Tools/workflows: Submission portals accepting annotated traces; reviewer guidelines for epistemic checks.
- Assumptions/dependencies: Journal policy changes; data-privacy handling for logs.
- Funding & Institutional Policy (research agencies, labs): Outcome-plus-process evaluation in grants and audits
- What to do: Mandate process-based reporting for AI-assisted studies; define minimum thresholds for productive motifs (e.g., refutation-driven updates) in agent-supported work.
- Tools/workflows: Standardized reporting templates; environment-based validations.
- Assumptions/dependencies: Consensus on metrics; compliance monitoring.
- Education (chemistry, materials, EE): Teach scientific reasoning explicitly with agent failure cases
- What to do: Use the spectroscopy, qualitative analysis, and circuit inference environments to demonstrate abductive vs. Popperian cycles; assign labs where students correct agent reasoning.
- Tools/workflows: Classroom instances of Corral; student-facing dashboards that highlight non-uptake and untested claims.
- Assumptions/dependencies: Instructor familiarity; compute access; simplified tool verbosity for classrooms.
- Autonomy Limits in Labs (safety, QA): Restrict agent autonomy in hypothesis-driven tasks
- What to do: Allow agents to execute well-defined workflows (e.g., parameterized MD runs) but require human approval for hypothesis formation, experimental design, and final claims.
- Tools/workflows: Role-based permissions; sign-off checkpoints driven by epistemic metrics.
- Assumptions/dependencies: Lab SOP updates; training staff to interpret metrics.
- Benchmarking & Model Cards (AI developers): Add epistemic behavior profiles to model documentation
- What to do: Report domain-wise rates of evidence uptake, belief revision, and convergent evidence alongside task performance.
- Tools/products: “Epistemic model cards” derived from Corral runs and IRT profiles.
- Assumptions/dependencies: Shared benchmarks; willingness to publish process metrics.
- Reliability Engineering (all sectors using agents): Plan around reliability decay
- What to do: Use the paper’s P(all k trials succeed) curves to set retry policies; avoid naive “try more times” strategies on hypothesis-driven tasks.
- Tools/workflows: Reliability calculators tied to task class; budgeted trial counts with human intervention thresholds.
- Assumptions/dependencies: Accurate baseline curves from internal evaluations.
- Tooling & DevEx (agent frameworks): Implement tool-verbosity ablations
- What to do: Systematically vary tool docstring verbosity (brief/workflow/comprehensive) to understand information dependency of agent behavior and reduce prompt overfitting.
- Tools/workflows: Tagged docstrings; automated ablation harness.
- Assumptions/dependencies: Tooling discipline; shared schemas.
- Daily Practice (students, researchers): Use checklists for AI-assisted reasoning
- What to do: Enforce steps—state hypothesis, design discriminating test, collect evidence, update beliefs, seek convergent evidence; treat agent-generated “answers” as provisional.
- Tools/workflows: Printable or embedded checklists, small N-of-1 trace audits before accepting outputs.
- Assumptions/dependencies: Time and skills to audit; willingness to challenge outputs.
Long-Term Applications
- Base-Model Training with Epistemic Objectives (AI developers, academia)
- What to do: Make reasoning a training target—reinforcement learning or supervised objectives that reward refutation-driven updates, evidence uptake, and convergent multi-test support.
- Tools/products: Datasets of annotated traces and motif labels; reward models for epistemic structure; synthetic curricula from Corral.
- Assumptions/dependencies: Scalable annotation; stable APIs; compute budgets; community consensus on epistemic targets.
- Standards & Certification (policy, regulators, industry consortia)
- What to do: Develop ISO-like standards for “AI scientific agents,” requiring minimum rates of productive motifs and process logging; certification for regulated domains (e.g., pharma).
- Tools/workflows: Compliance test suites derived from Corral; third-party audit services.
- Assumptions/dependencies: Multistakeholder buy-in; legal frameworks; versioning of standards.
- Healthcare Decision Support (healthcare, medtech): Evidence-led AI governance
- What to do: Apply epistemic behavior metrics to clinical-support agents; require convergent evidence and explicit belief revision before recommendations; gate to human review otherwise.
- Tools/workflows: Clinical “epistemic dashboards” integrated with CDSS; logging of H/E/T/J/U/C graphs.
- Assumptions/dependencies: Regulatory acceptance (FDA/EMA); HIPAA/GDPR-compliant logging; domain validation.
- Autonomous Discovery Platforms (materials, energy, biotech): Epistemically disciplined closed-loop labs
- What to do: Orchestrate active-learning loops that enforce hypothesis-test-update cycles and penalize non-uptake; choose next experiments based on refutation potential.
- Tools/workflows: Experiment planners with Popperian-cycle controllers; multi-modal evidence integrators.
- Assumptions/dependencies: Robotics/instrument control; robust simulators; sufficient throughput for iterative testing.
- Finance & Economics Research Automation (finance, econ research): Anti-overfitting guards
- What to do: Require convergent tests and belief updates before deploying AI-discovered strategies; ban “untested claims” in research pipelines.
- Tools/workflows: Epistemic linting in research notebooks; pre-trade validation harnesses.
- Assumptions/dependencies: Historical data access; latency budgets; cultural change in research workflows.
- “Epistemic Audit” SaaS (software, compliance): Productize auditing and dashboards
- What to build: Managed platforms offering trace capture, automated epistemic labeling, motif analytics, and compliance reporting; “Corral-as-a-service.”
- Assumptions/dependencies: Market adoption; integrations with major agent frameworks; security certifications.
- IDE-Level “Reasoning Linting” (developer tools): Pre-flight checks on agent plans
- What to build: Static/dynamic analyzers that flag missing tests, lack of belief revision, and single-line-of-evidence conclusions in agent plans before execution.
- Assumptions/dependencies: Access to intermediate plans; plugin ecosystem for LLM IDEs/notebooks.
- Model Distillation for Epistemics (AI research): Transfer disciplined reasoning to smaller models
- What to do: Distill from models trained with epistemic targets into compact models optimized for specific scientific domains.
- Tools/workflows: Knowledge+reasoning distillation objectives; domain-focused datasets.
- Assumptions/dependencies: Teacher models with strong epistemic behavior; domain coverage.
- Expanded Benchmarks & Community Repositories (academia/industry consortia)
- What to do: Add new domains (e.g., synthetic biology design, geoscience inversion), instruments, and scoring functions; maintain longitudinal leaderboards for epistemic metrics.
- Assumptions/dependencies: Community curation; data/IP licensing; sustained funding.
- Reliability Guarantees & Scheduling (operations research)
- What to do: Formalize run-scheduling that optimizes for P(all k trials succeed) under cost/time constraints; combine with human checkpoints to meet SLAs.
- Tools/workflows: Reliability models integrated with orchestration; Bayesian updating of success rates over time.
- Assumptions/dependencies: Stable distributions across tasks; monitoring infrastructure.
- Education & Pedagogy Research (education sector)
- What to do: Use agent traces to study how epistemic norms can be taught; develop curricula that shift students from outcome-centric to process-centric evaluation.
- Tools/workflows: Courseware built on Corral; controlled studies on learning outcomes.
- Assumptions/dependencies: IRB approvals for studies; faculty adoption.
- Regulatory Reporting & Traceability (regulated science)
- What to do: Establish retention policies and formats for AI reasoning traces to support audits, recalls, or post-market surveillance when AI contributes to scientific claims.
- Tools/workflows: Secure trace stores; redaction pipelines; provenance tracking.
- Assumptions/dependencies: Storage/compliance budgets; legal clarity on AI logs as records.
- Domain-Specific Reasoning Adapters (AI engineering)
- What to build: Layered adapters or control policies that bias agents toward domain-appropriate reasoning modes (e.g., combinatorial tree search for retrosynthesis; simulate–validate loops for MD).
- Assumptions/dependencies: Clear domain taxonomies; controllable interfaces; evaluation harnesses to verify adaptation.
Notes on feasibility and dependencies
- The paper’s key dependency is access to and integration with the Corral framework, standardized tools, and domain backends; some instruments (e.g., AFM) and simulators (LAMMPS) may be costly or require expertise.
- Many immediate applications rely on APIs that expose token-level log probabilities and structured tool call interfaces (not universally available).
- Long-term advances depend on community-wide standards, shared datasets of annotated traces, and willingness of model providers to optimize for epistemic criteria rather than only task accuracy.
Glossary
Agent scaffold: A framework that wraps a base model in a loop, governing prompts, tool routing, memory management, and logic by appending observations to the conversation history. Example in paper: "Common implementations include ReAct and structured tool-calling interfaces."
Dialectical reasoning: A reasoning style involving generating, testing, and refuting hypotheses in a process of disciplined inquiry. Example in paper: "Retrosynthetic planning requires multi-step planning under constraints, and hypothesis-driven inquiry requires generating, testing, and revising competing hypotheses."
Epistemic norms: Standards that dictate the reasoning processes adherent to scientific inquiry, ensuring self-correction and reliability. Example in paper: "Yet whether their reasoning adheres to the epistemic norms that make scientific inquiry self-correcting is poorly understood."
LDP (language decision process): A framework for representing observations and actions in text as part of a decision-making process, commonly used with LLMs. Example in paper: "We adopt the language decision process (LDP) framework, a partially observable Markov decision process in which observations and actions are represented in text."
LLM-based scientific agents: AI systems utilizing LLMs to autonomously conduct scientific research, including hypothesis generation and experimentation. Example in paper: "A growing number of LLM-based agents are now designed to conduct scientific research autonomously."
Reasoning breakdown: Occurs when an agent's reasoning process fails to adhere to disciplinary scientific inquiry, such as ignoring evidence or failing to update beliefs. Example in paper: "Reasoning breakdowns dominate across all domain groups, with evidence non-uptake occurring in 68% of traces."
Scaffold engineering: The process of developing and optimizing the structural framework that wraps around LLMs to improve task execution. Example in paper: "Much current engineering effort focuses on scaffolding, but the reasoning patterns persist across scaffold conditions."
Systematic performance evaluation: A methodical assessment of an agent's performance that decomposes the contributions of the model and scaffold elements. Example in paper: "The first is a systematic performance evaluation across controlled environments...to separate the contributions of the base model from the agent scaffold."
Collections
Sign up for free to add this paper to one or more collections.