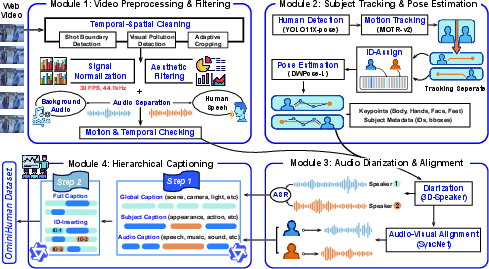
- The paper introduces OmniHuman, a dataset with 1M videos, 1800 hours, and 80K identities that addresses gaps in scene diversity, interaction, and attribute alignment.
- It details a fully automated hierarchical annotation pipeline using advanced detectors and pose estimation to ensure high spatial-temporal quality.
- The study evaluates multiple generative models on OHBench, showing significant performance gains in audio-video synchronization and interaction realism through fine-tuning.
OmniHuman: Dataset and Benchmarking for Human-Centric Video Generation
Motivation and Dataset Deficiencies in Human-Centric Video Generation
Recent progress in audio-video joint generation models has yielded advances in content creation, yet human-centric video generation in complex, physical scenes remains problematic. Existing datasets are structurally limited along three axes: (i) global scene and camera diversity, (ii) sparse interaction modeling (person-person and person-object), and (iii) insufficient individual attribute alignment. These constraints fundamentally inhibit generalization and perceptual fidelity in systems targeting real-world scenarios, causing semantic mismatches and unstable generation artifacts.
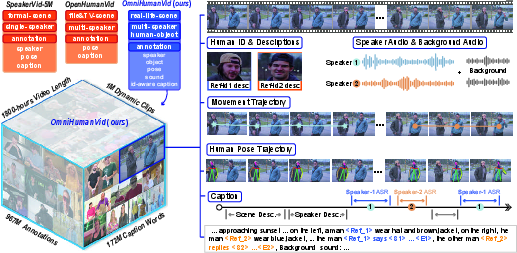
Figure 1: OmniHuman: a 1M-video, 1800 hours, 80K-identity dataset with hierarchical annotations covering diverse natural scenes and social interactions.
OmniHuman: Hierarchical Dataset Construction and Annotation Pipeline
OmniHuman addresses these structural gaps by introducing a large-scale, richly annotated dataset with hierarchical labeling capable of supporting fine-grained human modeling at video, frame, and individual levels. The dataset spans 1 million videos, 1,800 hours, and 80,000 distinct identities, emphasizing multi-scene coverage and high-definition content. The fully automated data curation pipeline involves:
Rich statistical analysis reveals comprehensive scenario, content-type, resolution, and duration distributions, validating the dataset’s extensive domain coverage.
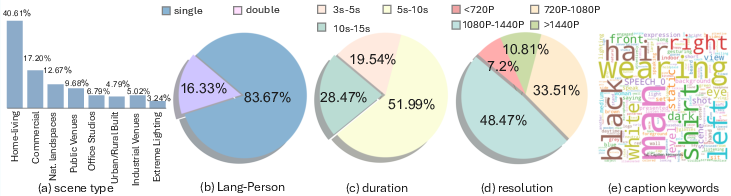
Figure 3: Statistical analysis of the OmniHuman dataset composition.
OHBench: Perception-Aligned Benchmarking for Audio-Video Generation
OmniHuman is complemented by OHBench, a benchmark suite designed for scientific diagnosis of human-centric audio-video synthesis. The benchmark is stratified into three evaluation levels—global, interactional, and individual—across seven diagnostic dimensions:
- Global Level: Video quality (imaging quality, motion intensity, background plausibility), audio quality (Audiobox-derived aesthetics, distributional metrics), and multi-modal synchronization.
- Interaction Level: Evaluation of person-person and person-object interactions, including social naturalness, audio-visual assignment accuracy, identity drift, object consistency, and contact realism.
- Individual Level: Assessment of subject-video attributes (ID fidelity, attribute consistency, lip sync) and subject-audio attributes (pronunciation accuracy via WER, perceptual speech quality via DNSMOS OVRL).
OHBench samples from OmniHuman while maintaining domain gaps, ensuring robust evaluation for high-level audio-visual tasks, speech-to-video generation, controllable editing, and downstream speech synthesis.
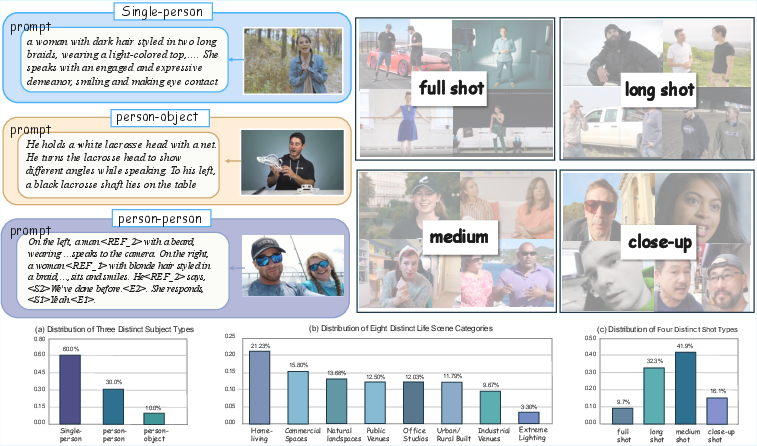
Figure 4: Distribution of subject categories, scene types, and shot types in OHBench.
Systematic evaluation on OHBench involves both open-source (Universe-1, UniAVGen, Ovi, LTX-2, MOVA) and closed-source (Veo3.1, Wan2.5, Sora2, kling2.6, SeedDance1.5-pro) models. Results demonstrate:
- Closed-source models dominate in video quality, interaction rationality, and individual-level attributes, attributable to massive training datasets and post-training alignment paradigms.
- Ovi exhibits strong cross-modal consistency and lip sync but lacks robust interaction modeling owing to limited training samples.
- LTX-2 surpasses other open-source models in dyadic interaction and listener realism, with performance improvements after fine-tuning on OmniHuman data driving substantial gains in audio quality (+25.9% KL, +12.3% FD, +11.9% AbS), multi-modal alignment (+25.0% T-A, +11.1% V-A), dynamic degree (+10.7%), and identity consistency (+6.1% IC, +4.8% IC*).
- Open-source models show more balanced performance distributions and are less prone to domain artifacts, especially in global quality metrics.
Fine-tuning LTX-2 with only 20% of OmniHuman data demonstrates marked improvements across all evaluation axes, evidencing the dataset’s value in enhancing open-source capabilities for complex human-centric audio-video generation.
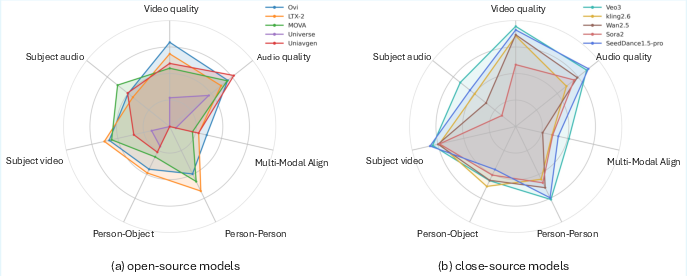
Figure 5: Performance distribution of 10 models across seven dimensions on OHBench for audio-video joint generation task.
Practical and Theoretical Implications
OmniHuman and OHBench collectively offer:
- A scalable blueprint for human-centric video generation, bridging structural data gaps and providing robust perceptual alignment for benchmarking and evaluation.
- Empirical evidence supporting transfer learning and fine-tuning of generative models on high-quality, domain-diverse annotated datasets.
- The potential for advancing multimodal generation systems beyond single-subject, controlled settings to complex social and physical scenarios, with implications for downstream applications in interactive media, synthetic film, and embodied AI.
- The benchmark’s perceptual metrics and hierarchical evaluation framework are poised for adoption in rigorous ablation studies, generalization tests, and systematic model comparison.
Ongoing development is anticipated in expanding scenario diversity, improving modeling of distant views and multi-agent interactions, and enhancing perceptual alignment via crowd-sourcing or expert evaluation.
Conclusion
OmniHuman, paired with OHBench, marks a significant advance in the systematic modeling and evaluation of human-centric video generation. Its hierarchical annotation, automated curation, and perception-aligned metrics facilitate comprehensive diagnosis and reliably boost model performance with minimal fine-tuning. The methodologies and findings set a foundation for future multimodal generative research, promising robust generalization in real-world, interaction-rich scenarios (2604.18326).