- The paper introduces OmniShow, the first end-to-end solution unifying text, reference image, audio, and pose for HOIVG, achieving state-of-the-art performance.
- It employs Unified Channel-wise Conditioning and Gated Local-Context Attention to ensure high reference fidelity and precise audio-video synchronization.
- A decoupled-then-joint training strategy and the novel HOIVG-Bench enable robust multimodal evaluation and emergent zero-shot generalization.
OmniShow: A Unified Multimodal Framework for Human-Object Interaction Video Generation
Introduction and Motivation
Human-Object Interaction Video Generation (HOIVG) represents a complex, highly-constrained subfield of generative modeling, requiring simultaneous conditioning on text, reference images, audio, and pose. This multifaceted input space is crucial for industrial scenarios such as e-commerce, video marketing, and avatar-based interactive entertainment, where fine-grained control and high-fidelity identity preservation are paramount. While text-to-video, reference-to-video, and audio-to-video paradigms have each advanced in isolation, no existing methodology prior to this work afforded true unification of all multimodal signals in one tractable, high-quality framework.
OmniShow (2604.11804) is presented as the first end-to-end HOIVG solution that harmonizes all four modalities. This is accomplished by carefully balancing injection techniques, learning paradigms, and data utilization, while also introducing HOIVG-Bench, a purpose-built benchmark for comprehensive evaluation. The framework achieves superior quantitative and qualitative performance across all key axes: controllability, visual and audio-visual fidelity, and multimodal alignment.

Figure 1: Overview of OmniShow illustrating unified handling of text, reference image, audio, and pose inputs for diverse HOIVG tasks and applications.
Unified Architecture and Multimodal Conditioning
The OmniShow model is constructed atop Waver 1.0, leveraging a 12B parameter Multimodal Diffusion Transformer backbone. The architectural advancements of OmniShow are encapsulated in two core innovations: Unified Channel-wise Conditioning and Gated Local-Context Attention.
Unified Channel-wise Conditioning employs an expanded latent token design, where both pose and reference image information are simultaneously injected into video generation via channel concatenation. Pose is rendered as an RGB video, encoded with a VAE, and concatenated with the noisy video token stream; reference images are injected via additional pseudo-frame tokens, with explicit reference reconstruction loss to preserve semantic identity. This strategy preserves the backbone's pretrained distributional priors and minimizes the adaptation gap relative to the base model.
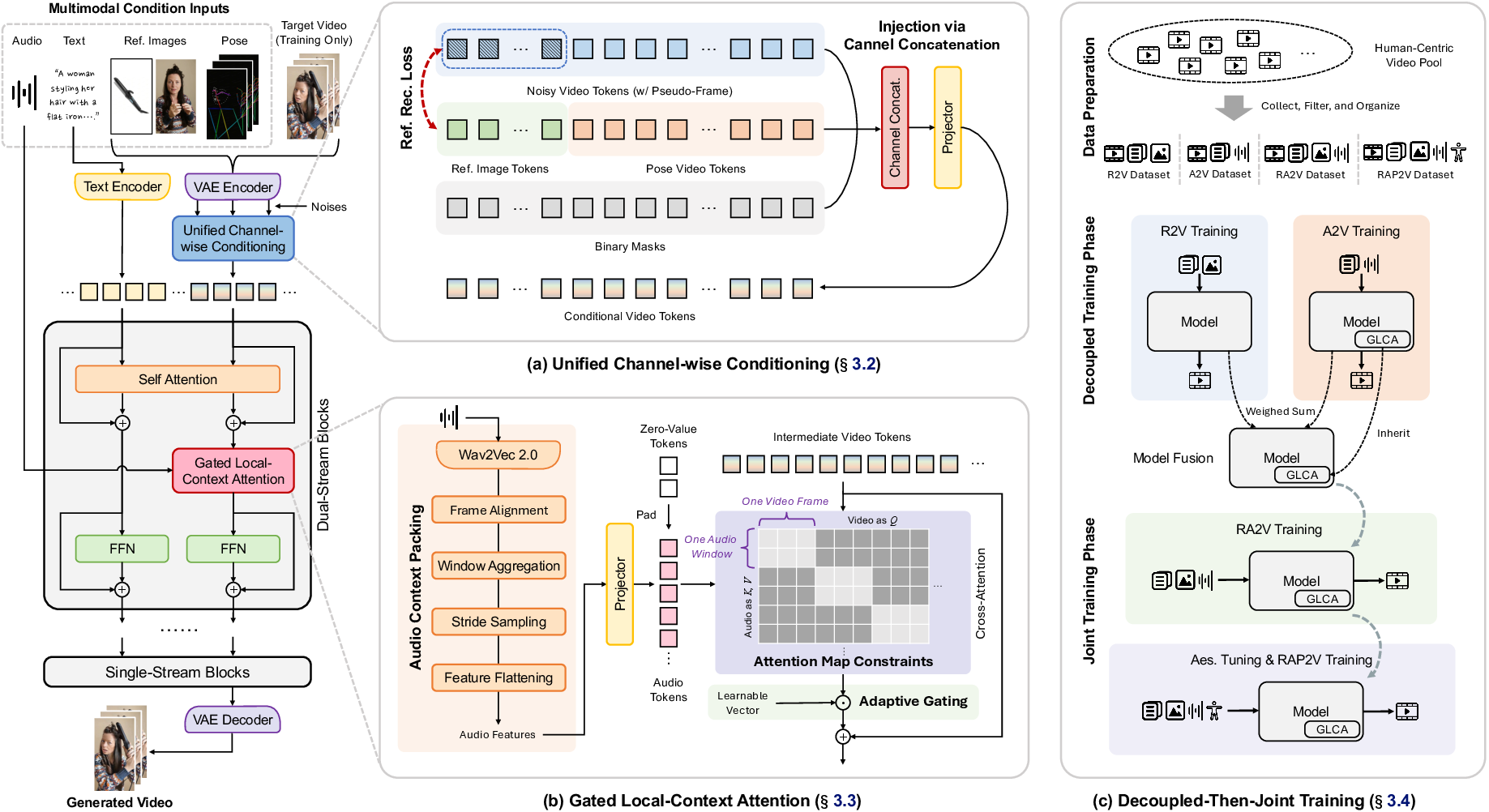
Figure 2: OmniShow pipeline, highlighting channel-wise conditioning, local-context audio attention, and decoupled-then-joint training.
Gated Local-Context Attention introduces an audio injection modality that achieves precise temporal alignment between audio and video frames. Audio features extracted via Wav2Vec 2.0 are packed across a local temporal window, injected through masked cross-attention with a learnable gating mechanism. This not only stabilizes early training but also provides an empirical means to restrict audio injection to parameter-efficient model blocks.
Extensive ablations demonstrate that channel-wise conditioning yields superior reference fidelity and video quality relative to token-level concatenation baselines, and that both local context and masking are necessary for robust lip-sync and audio-driven body control.

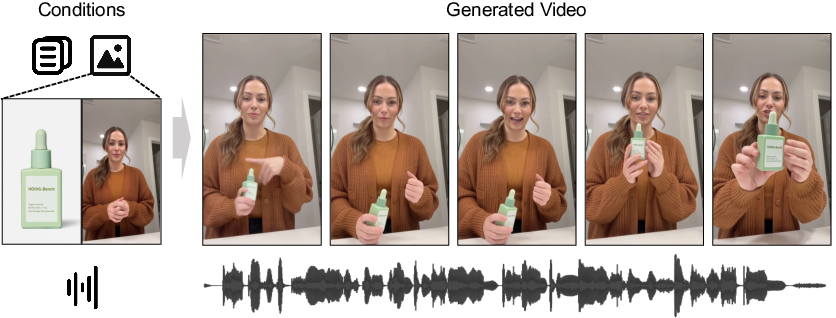
Figure 3: (Left) Ablation of conditioning methods, showing superior reference preservation; (Right) Zero-shot RA2V generation via model merging.
Decoupled-Then-Joint Training and Heterogeneous Data Utilization
OmniShow addresses the data scarcity problem pervasive in HOIVG by proposing a decoupled-then-joint training strategy. The training is initiated with modality-specialized models for A2V and R2V, utilizing large, heterogeneous sub-task datasets. Subsequently, model parameters are merged through principled weight interpolation, followed by joint training on curated datasets encompassing multiple modalities. Importantly, strong pose conditioning is introduced only in the final stage to prevent overfitting and ensure generalization.
The result is robust emergent performance: the merged model demonstrates zero-shot generalization to tasks such as Reference+Audio-to-Video (RA2V) without explicit training, underscoring the effectiveness of the model merging strategy.
HOIVG-Bench: Comprehensive Benchmarking
The lack of standardized benchmarks for multimodal HOIVG is addressed via HOIVG-Bench, comprising 135 high-quality samples constructed with rigorous curation pipelines for text, reference images, objects, pose, and synthesized audio. The evaluation protocol spans metrics for textual alignment, reference consistency (FaceSim, NexusScore), pose accuracy, audio-visual synchronization (Sync-C, Sync-D), and overall video quality (AES, IQA, VQ, MQ).

Figure 4: Example content and statistics from HOIVG-Bench, covering diverse HOI scenarios, motion intensity distribution, and representative multimodal samples.
Experimental Results
Quantitative Comparison
OmniShow achieves strong results across all evaluated tasks and modalities, establishing new state-of-the-art metrics in unified multimodal settings. Notably, in R2V and RA2V scenarios, OmniShow outperforms or matches 14B-17B baselines on reference consistency and video quality, while utilizing fewer parameters (12.3B). The framework is distinguished as the only model supporting RAP2V (Reference+Audio+Pose-to-Video) generation.
Qualitative Evaluation
OmniShow generates videos with high-fidelity subject and object preservation, natural pose variations, and precise audio-visual synchronization. In settings requiring complex spatial human-object interaction, baselines either fail to preserve identity or cannot synchronize modalities, whereas OmniShow demonstrates stable compositional control.

Figure 5: Qualitative comparison of OmniShow and baseline methods across multimodal settings, showing superior naturalness and compositional precision.
Human preference studies further reinforce model superiority, with participants consistently favoring OmniShow for overall quality and condition adherence.
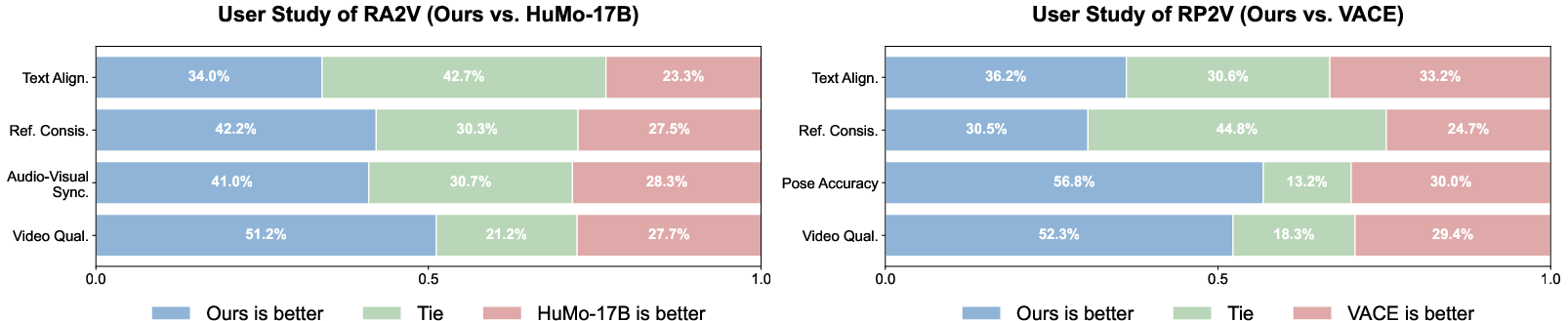
Figure 6: Human evaluation results, highlighting superior alignment with subjective human judgment.
Additional visualization and analysis reveal robustness to challenging multimodal scenarios, including creative applications such as audio-driven avatars, object swapping, and video remixing.
(Figures 9, 10, 11)
Figures 9, 10, 11: Extended qualitative results in diverse HOIVG scenarios, showing the breadth of OmniShow's robust compositional and control capabilities.
Ablation Analysis
Detailed ablations confirm that each architectural and training design is essential:
- Channel-wise conditioning outperforms token-level methods and reference reconstruction loss is critical for identity preservation.
- Adaptive gating and masked local-context audio attention significantly impact audio-video synchronization and video quality.
- The decoupled-then-joint training paradigm unlocks the potential of heterogeneous data that naive single- or multi-stage approaches cannot harness.
Data Curation and Scaling
The data pipeline employs large-scale shot segmentation, multidimensional quality filtering, and specialized sub-task processing to curate datasets at O(1M) scale, forming the backbone for model generalization.
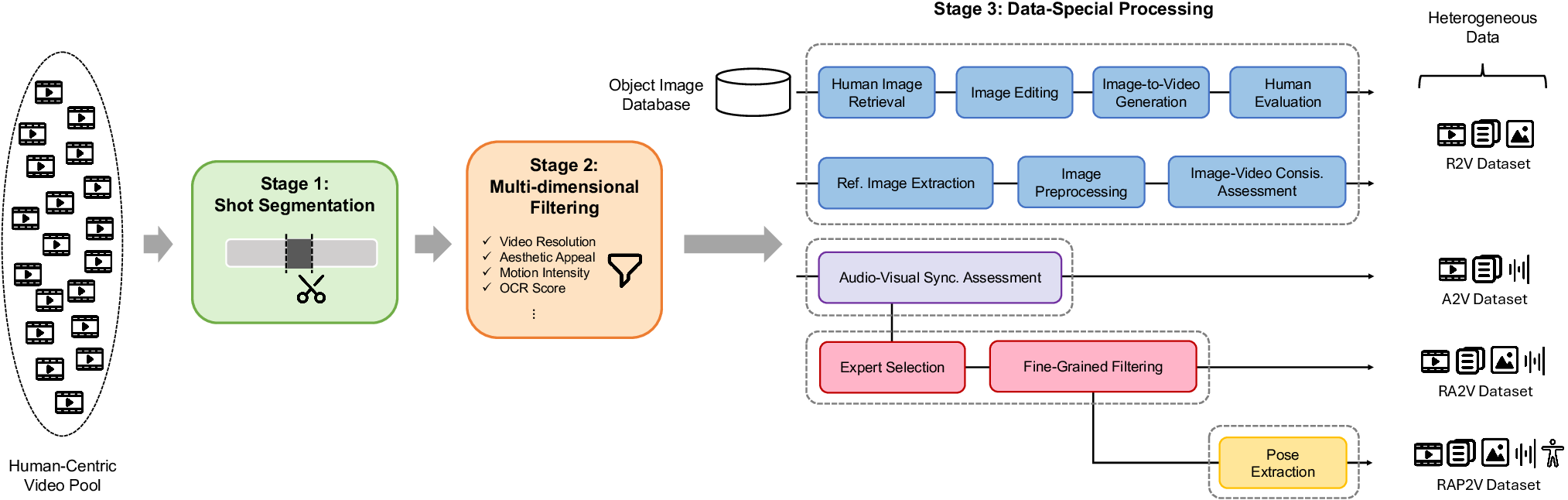
Figure 7: Complete OmniShow data pipeline: segmentation, filtering, and sub-task dataset curation.
Implications and Future Directions
OmniShow sets a rigorous new standard for HOIVG and demonstrates that end-to-end multimodal conditioning can be achieved efficiently and with high fidelity. Practically, the implications are substantial for content automation, digital avatar construction, and interactive storytelling at industry scale. Theoretical implications include empirical evidence that model merging of modality-specialized experts can yield emergent compositional generalization.
Future developments should prioritize reinforcement learning-based post-training to align more closely with human preference and physical plausibility, exploration of broader and richer multimodal inputs, and scalability to longer video sequences and agentic tasks such as interactive, minute-level video synthesis.
Conclusion
OmniShow delivers the first comprehensive, efficient, and high-quality solution to the HOIVG problem, harmonizing text, reference image, audio, and pose modalities. With its unified architecture, parameter-efficient conditioning, emergent multimodal abilities via decoupled-then-joint training, and robust benchmark, OmniShow not only outperforms all contemporaries but establishes a compelling, flexible paradigm for the future of conditional video synthesis (2604.11804).