Agent-as-a-Judge
Abstract: LLM-as-a-Judge has revolutionized AI evaluation by leveraging LLMs for scalable assessments. However, as evaluands become increasingly complex, specialized, and multi-step, the reliability of LLM-as-a-Judge has become constrained by inherent biases, shallow single-pass reasoning, and the inability to verify assessments against real-world observations. This has catalyzed the transition to Agent-as-a-Judge, where agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory to enable more robust, verifiable, and nuanced evaluations. Despite the rapid proliferation of agentic evaluation systems, the field lacks a unified framework to navigate this shifting landscape. To bridge this gap, we present the first comprehensive survey tracing this evolution. Specifically, we identify key dimensions that characterize this paradigm shift and establish a developmental taxonomy. We organize core methodologies and survey applications across general and professional domains. Furthermore, we analyze frontier challenges and identify promising research directions, ultimately providing a clear roadmap for the next generation of agentic evaluation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is a big-picture guide (a “survey”) about a new way to let AI systems grade or judge other AIs’ work. Older systems asked a single LLM to be the judge, like having one smart person read an answer and score it in one go. The new idea—called “Agent-as-a-Judge”—treats the judge like a small team of smart helpers (agents) that can plan, use tools (like search engines or code runners), double-check facts, collaborate, and remember what they’ve learned. The paper explains why this shift is happening, how these agent judges work, where they’re used, what’s hard about them, and where the field is headed.
Key objectives and questions
The paper set out to answer simple but important questions:
- Why isn’t a single LLM judge (one-shot grading) good enough anymore?
- What makes an “agentic” judge different and better?
- How do these agent judges plan, use tools, work together, and remember things?
- Where are agent judges already being used (like in math, coding, medicine, and law)?
- What are the main challenges (like cost, speed, safety, and privacy), and what should researchers try next?
How they studied it (in everyday language)
This is a survey paper, which means the authors didn’t run one big experiment. Instead, they:
- Collected and read many research papers about AI judges.
- Compared the designs, abilities, and uses of these systems.
- Organized what they found into a clear map (a taxonomy) of methods and applications.
- Pointed out common problems and promising ideas for the future.
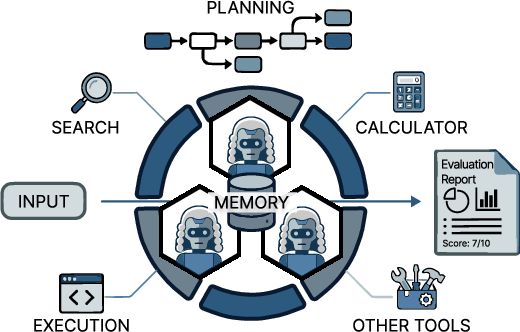
To explain the technical ideas, here are the key parts of an agent judge, with simple analogies:
- Planning: Like a coach making a game plan. The judge breaks a big grading job into smaller steps (e.g., “check facts,” “evaluate logic,” “score clarity”) and adjusts the plan as it learns more.
- Tool use: Like a detective using a calculator, web search, or a microscope. The judge can run code, look things up, or inspect images to verify claims instead of guessing.
- Multi-agent collaboration: Like a debate team or a panel of experts. Different agents take on roles (fact-checker, critic, final arbiter) and discuss to reduce bias and catch mistakes.
- Memory and personalization: Like keeping a notebook. The judge remembers past steps, user preferences, and lessons learned so it stays consistent and can adapt to different users or tasks.
- Optimization: Like training and practice. Some improvements happen by “training” the judge (changing its internal parameters), and some happen at “inference time” (following better prompts, workflows, or team structures without retraining).
The paper also describes three stages of evolution:
- Procedural: Follows a fixed recipe. Useful, but not very flexible.
- Reactive: Chooses different paths depending on what it finds (e.g., calls a tool when needed).
- Self-evolving: Can improve its own rubrics and strategies over time, like a judge that learns how to judge better while working.
Main findings and why they matter
What the authors found (by organizing the field):
- Single-pass LLM judges have limits. They can be biased (e.g., rewarding longer answers), they can’t check the real world, and they struggle with complex, multi-step tasks.
- Agent-as-a-Judge fixes many of these issues:
- Better verification: Agents don’t just “think it looks right”—they run code, search sources, or prove steps to confirm correctness.
- Finer-grained feedback: Instead of one vague score, agents evaluate different parts (facts, logic, style) and explain why.
- Less bias and more robustness: Teams of agents with different roles can challenge each other and avoid one model’s quirks.
- Memory and personalization: Judges stay consistent and can align with user or domain needs (like a teacher who knows a student’s goals).
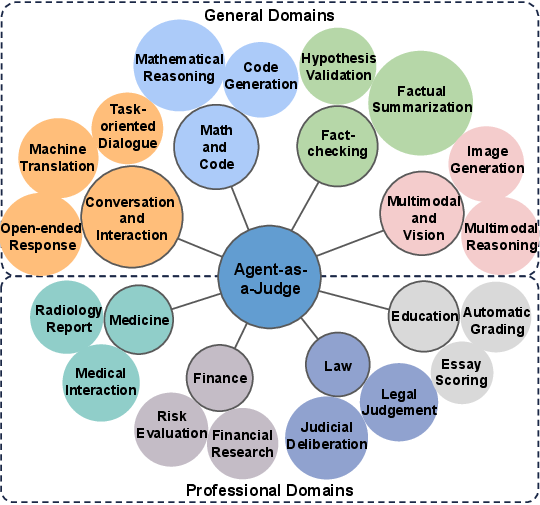
- This approach already works across many areas:
- General domains: math and coding (checking proofs and programs), fact-checking, conversations (multi-turn judging), and images/video (visual inspections).
- Professional domains: medicine (clinical safety and accuracy), law (courtroom-like debates), finance (risk-aware analysis), and education (rubric-based grading).
- There are real challenges:
- Computational cost and latency: Multi-step judging, tool calls, and agent debates take more time and money.
- Safety: Tool use and multi-agent setups can be attacked or misused if not designed carefully.
- Privacy: Long-term memory and personalization must protect user data.
Why it matters:
- As AI systems do more complex, real-world tasks, we need judges that can truly verify results, not just estimate them. Agent judges make AI evaluation more trustworthy, precise, and useful for improving future models.
What this means for the future
The authors suggest four big directions:
- Personalization: Judges that actively manage memory—keeping, updating, or forgetting preferences—so scoring matches different users and contexts.
- Generalization: Judges that invent or adapt rubrics on the fly, scaling from simple checks to deep, multi-part evaluations as needed.
- Interactivity: Judges that probe and test, not just observe—like stress-testing a system to find edge cases—and collaborate with humans to resolve tricky, subjective cases.
- Optimization: Move beyond clever prompting—train agent judges (including teams of agents) to plan, use tools, and coordinate effectively.
In short: The future judge won’t just read and score. It will plan, investigate, verify, discuss, remember, and learn—bringing AI evaluation closer to how careful, expert humans assess complex work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and open questions the paper leaves unresolved, aimed at guiding actionable future research.
- Formalizing agency levels: precise, operational definitions and measurable indicators for “Procedural,” “Reactive,” and “Self-Evolving” judges; criteria and tests for transitions between levels.
- Unified benchmarking: cross-domain, reproducible benchmarks for agentic judges with standardized datasets, tasks, and evaluation protocols that measure verifiability, calibration, bias mitigation, granularity, and latency/cost—not just accuracy.
- Meta-evaluation of judges: methods to validate a judge’s correctness and fairness (human agreement baselines, inter-rater reliability, scale anchoring, score calibration) and to compare against expert outcomes.
- Component ablations: systematic quantification of the added value of planning, memory, tool use, and multi-agent collaboration (including cost–quality–latency curves and energy footprints).
- Tool security and safety: comprehensive threat models, sandboxing/permissioning strategies, provenance tracking, defenses against prompt injection/misuse, and red-teaming protocols tailored to tool-augmented judges.
- Evidence provenance: standardized, auditable decision trails that link every judgment to verifiable evidence (e.g., cryptographically signed citations, executable verification scripts).
- Stability of self-evolution: guarantees and monitoring for safe self-modification of rubrics, memory, and policies (rollback/versioning, degradation detection, reward-hacking resistance, formal analyses).
- Memory governance: principled policies for retention, update, and forgetting; privacy-preserving personalization (differential privacy, data minimization, consent management) and leak auditing.
- Personalization evaluation: datasets and protocols to quantify benefits and fairness impacts of personalized judging (cross-demographic equity, handling conflicting user preferences).
- Multi-agent coordination theory: formal models of consensus/debate/decomposition with convergence guarantees, robustness to adversarial agents, and mitigation of collusion/groupthink.
- Validating rubric discovery: methods to assess automatically discovered rubrics against expert standards (rubric quality metrics, transferability tests, lifecycle/version control).
- Cross-lingual and cross-cultural generalization: rigorous evaluation in non-English and diverse socio-cultural contexts, with localized tools/knowledge sources and bias detection.
- Multimodal coverage gaps: standardized evaluation for audio, video, 3D, and interactive/streaming environments; toolkits for perceptual checks beyond images.
- Real-world deployment studies: end-to-end evidence from production pipelines (moderation, RL training, education, medicine) under operational constraints, including incident analyses and postmortems.
- Economic/latency trade-offs: cost-aware planning strategies (early-exit policies, caching, anytime algorithms, budgeted tool calls) and their impact on judgment quality.
- Reward design for RL-trained judges: reliable reward functions balancing preference and correctness, avoiding circularity when judges train models they later evaluate; curated offline datasets and credit assignment strategies.
- Robustness under adversarial conditions: stress tests with deceptive outputs, poisoned tools, noisy/ambiguous evidence, domain shifts, and uncertainty-aware scoring.
- Standardized APIs/interfaces: interoperable schemas for tool use, evidence, claims, rubrics, and judgments; community repositories and reproducibility checklists.
- Interpretability and attribution: techniques to expose reasoning steps, role contributions in multi-agent settings, and the impact of specific tools; counterfactual analyses and error attribution.
- Ethical and legal governance: deployment guidelines in high-stakes domains (accountability, auditability, liability), compliance with data protection and sector regulations.
- Cross-domain score calibration: methods to align score scales across tasks so decisions are comparable and map to real-world outcomes (pass/fail thresholds, risk tiers).
- Long-horizon evaluation: frameworks for judging multi-step processes with delayed outcomes, including temporal consistency and credit assignment to intermediate actions.
- Open-source baselines: reference implementations with transparent components, shared datasets, and leaderboards to enable reproducible comparisons across agentic judges.
- Failure taxonomies: systematic documentation of where agentic judges underperform relative to simple LLM judges (known failure modes, negative results, error propagation in multi-agent setups).
- Governance of rubric updates: control frameworks for who/what can change rubrics in deployed systems (approval workflows, audit logs, rollback procedures).
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with today’s Agent-as-a-Judge methods (planning, tools, multi-agent debate, memory), many of which are cited in the survey’s application sections.
- Software CI/CD quality gates for AI-generated code (Software)
- What: Use agentic judges to verify code edits and AI-generated patches via execution traces, unit tests, static analysis, and sandboxed runs.
- How: Integrate CodeVisionary- or Agent-as-a-Judge–style toolchains (linters, test runners, containerized execution, diff-aware checklists) as GitHub/GitLab Actions.
- Product/workflow: “Eval Gate” in CI to block merges that fail tool-verified checks; triage reports with root-cause evidence.
- Assumptions/dependencies: Reliable test coverage and sandboxing; latency budget in CI; safe handling of secrets and build artifacts.
- Agentic reward modeling for post-training (Software, Foundation models)
- What: Replace single-pass preference models with tool-grounded, multi-step judges to produce more reliable rewards for RLHF/RLAIF.
- How: Agentic RM pipelines combining retrieval, Python execution, theorem provers (e.g., HERMES, VerifiAgent).
- Product/workflow: “Reward-as-a-Service” modules for training loops; plug-in verification skills (math, facts, tool-use correctness).
- Assumptions/dependencies: Compute cost; high-quality tools/APIs; reward-model calibration against human gold standards.
- Content moderation and factuality checks (Media, Platforms)
- What: Agent judges retrieve evidence, cross-check claims, and score narratives for truthfulness, consistency, and justification quality.
- How: FACT-AUDIT-style agent loops; multilingual retrieval and evidence boosting for low-resource contexts.
- Product/workflow: Moderation queues enriched with citations, contradiction flags, and “confidence with evidence” rationales.
- Assumptions/dependencies: Search/retrieval reliability; live web access governance; audit logs for explainability.
- Conversation QA and coaching for support agents (Customer service, BPO)
- What: Evaluate and improve multi-turn dialogues for goal completion, empathy, safety, and policy adherence.
- How: Multi-agent role-play (reviewer personas, debate) with targeted rubrics; selective tool calls for policy lookup.
- Product/workflow: “Conversation Coach” dashboards that annotate transcripts, highlight violations, and suggest rewrites.
- Assumptions/dependencies: PII/privacy controls; latency acceptable for batch QA; localized policy/rubric variants.
- Rubric-driven, tool-grounded grading assistants (Education)
- What: Stage-based grading (rubric construction, evidence recognition, cross-review) with consistent, explainable scoring.
- How: Grade-Like-a-Human and AutoSCORE workflows; multi-agent cross-checks; calibration on teacher exemplars.
- Product/workflow: LMS plug-ins generating scorecards, rubric-aligned feedback, and discrepancy reports.
- Assumptions/dependencies: Human oversight; fairness auditing; accommodation for diverse curricula and languages.
- Internal validation of clinical LLM outputs (Healthcare)
- What: Evaluate draft clinical responses, discharge summaries, and patient-education materials before any clinical use.
- How: Multi-agent evaluators (MAJ-Eval, GEMA-Score) with medical ontology checks, uncertainty scoring, and citation verification.
- Product/workflow: “Clinical Eval Bench” for internal model gating; error taxonomies and risk heatmaps.
- Assumptions/dependencies: PHI-safe infrastructure; curated medical knowledge bases; strict non-deployment for patient care without approvals.
- Legal document review and argument stress-testing (Law)
- What: Simulate adversarial arguments and bench deliberation to test briefs, memos, and contract clauses.
- How: AgentsCourt-style role-play (prosecution/defense/judge), consensus modeling (SAMVAD, AgentsBench), citation validation.
- Product/workflow: “Argument Auditor” producing risk scenarios, likely counter-arguments, and clause-level vulnerability maps.
- Assumptions/dependencies: Confidentiality; jurisdiction-specific rubrics; careful scope to avoid unauthorized legal advice.
- Research-report auditing and risk checks (Finance)
- What: Extract logic trees and verify claims for temporal staleness and hallucinations in analyst-like outputs.
- How: FinResearchBench logic extraction; SAEA/M-SAEA trajectory audits for multi-agent workflows.
- Product/workflow: “Research QA” with timestamped evidence, delta-to-market data checks, and misalignment alerts.
- Assumptions/dependencies: Licensed data feeds; compliance review; strict separation from execution/trading decisions.
- Multimodal generation QA (Design tools, Creative platforms)
- What: Check instruction adherence, subject consistency, and visual truthfulness of generated images/videos.
- How: CIGEval-style control probes; Evaluation Agent multi-round checks; selective visual tool invocation (crop/zoom, alignment).
- Product/workflow: Asset “fitness reports” with actionable fixes (prompt edits, seed changes, negative prompts).
- Assumptions/dependencies: Access to auxiliary vision models; IP/copyright policies; domain-specific visual rubrics.
- A/B testing and model selection with agentic judges (Software, Product)
- What: Replace brittle automatic metrics with rubric-driven, tool-verified comparative judgments for launches.
- How: Multi-agent consensus, adaptive routing (AGENT-X), and tool-backed verification where relevant.
- Product/workflow: Centralized evaluation harness that logs rubrics, evidence, and verdict rationales for product councils.
- Assumptions/dependencies: Human calibration sets; reproducible testbeds; cost/latency management.
- Synthetic dataset curation and label QA (ML Ops, Data vendors)
- What: Filter and rank synthetic or human-labeled data using multi-perspective, tool-verified judgments.
- How: Debate + “judge the judge” supervision (SAGEval); falsification-oriented sampling (Popper).
- Product/workflow: Data refinery pipelines that output provenance, error tags, and uncertainty scores.
- Assumptions/dependencies: Clear acceptance criteria; budget for iterative verification; distributional monitoring.
- Policy/compliance checks on generated content (Enterprise governance)
- What: Evaluate outputs for regulated domains (PII leakage, safety, DEI, brand tone) with external policy references.
- How: Tool calls to policy KBs; multi-agent checklists and escalation when rules conflict.
- Product/workflow: “Compliance Guardrail” gating content publication, storing explainable decision trails.
- Assumptions/dependencies: Up-to-date policy codification; audit requirements; alignment with legal counsel.
- Prompt robustness and red-teaming evaluation (Security)
- What: Probe models/agents for prompt-injection susceptibility and tool-misuse risks.
- How: Agentic adversaries generate targeted attacks; judges verify exploitability and impact with tool simulations.
- Product/workflow: Continuous “Red Team Evals” with scenario libraries and regression tracking.
- Assumptions/dependencies: Safe sandboxes; curated attack corpora; coordinated disclosure processes.
- Academic manuscript and artifact checks (Academia, Publishing)
- What: Verify math/stat claims, reproduce code snippets, and fact-check citations.
- How: Theorem provers, code execution sandboxes, retrieval of cited sources; multi-agent inconsistency detection.
- Product/workflow: Preprint screening bots and reviewer co-pilots producing structured verification reports.
- Assumptions/dependencies: Access to data/code; risk of false positives; clear handoff to human reviewers.
- Personalized preference-aware evaluation (Recommenders, UX)
- What: Judge outputs against user-specific preferences/personas while maintaining consistency over time.
- How: Memory modules (PersRM-R1, RLPA) that persist and update preference profiles; few-shot preference conditioning.
- Product/workflow: “Preference Evals” in online experiments to pick responses/models per cohort or user segment.
- Assumptions/dependencies: Consent/PII governance; drift detection; opt-out and transparency mechanisms.
Long-Term Applications
These use cases likely require further research, scaling, standardization, or regulatory alignment (e.g., self-evolving judges, deeper tool-integration, formal guarantees).
- Self-evolving evaluators for robotics and embodied agents (Robotics)
- What: Judges that verify task completion via simulators/sensors, adapt rubrics online, and discover failure modes autonomously.
- How: Closed-loop execution verification in high-fidelity simulators; policy-aware rubric discovery.
- Dependencies: Accurate simulators; safe real-world validation; formal safety overlays.
- Third-party, standardized AI audits with agentic judges (Policy, Governance)
- What: Certifiable evaluators that dynamically discover criteria, verify evidence, and generate explainable audit trails across domains.
- How: Online rubric synthesis (EvalAgents, OnlineRubrics), multi-agent consensus, provenance-tracked tools.
- Dependencies: Regulator acceptance; transparency standards; benchmarking and liability frameworks.
- Continuous clinical oversight with tool-verified judgment (Healthcare)
- What: Live monitoring of clinical AI outputs with uncertainty, citation, and contraindication checks; human-in-the-loop escalation.
- How: Hospital-grade data connectors, medical KBs, multi-agent validators; risk-tiered workflows.
- Dependencies: EHR integration; HIPAA/GDPR compliance; clinical trials and post-market surveillance.
- Bench deliberation simulators for judicial reasoning support (Law)
- What: Simulate concurring/dissenting opinions to analyze case law robustness and policy impacts.
- How: Multi-agent deliberation with jurisdiction-aware rubrics; longitudinal precedent tracking.
- Dependencies: Legal acceptance; rigorous explainability; bias/fairness auditing.
- Compliance copilots for financial agents at deployment (Finance)
- What: Real-time auditing of advisor/agent trajectories for staleness, hallucinations, and regulatory breaches.
- How: M-SAEA-like multi-agent trajectory tracing; time-aware data checks; anomaly detection.
- Dependencies: Broker/dealer integration; model-risk management; supervisory review.
- Lifelong, personalized assessment copilots (Education)
- What: Longitudinal evaluators that adapt rubrics to evolving learner profiles and generate mastery pathways.
- How: Persistent memory with active lifecycle management; dynamic multi-granularity rubric planning.
- Dependencies: Data governance for minors; bias mitigation; interoperability with LMS/LRS standards.
- Reproducible science and agentic peer review at scale (Academia, R&D)
- What: Judges that re-run experiments, verify statistical assumptions, and auto-audit research pipelines.
- How: Artifact standards; code/data execution sandboxes; domain-specific verification tools.
- Dependencies: Community norms; reproducibility incentives; compute credits and secure sandboxes.
- Cross-model oversight networks (AI ecosystems)
- What: Heterogeneous, multi-agent oversight layers that monitor production model swarms and coordinate alarms.
- How: Decentralized consensus among specialized judge agents; standardized telemetry and rubrics.
- Dependencies: Cross-vendor interoperability; secure logging; incident response protocols.
- Auto-generated, domain-robust benchmarks (All sectors)
- What: Self-evolving benchmark generators that discover edge cases, synthesize tasks, and align rubrics to deployment contexts.
- How: Planning + tool-verified synthesis; falsification-oriented sampling; human-in-the-loop validation.
- Dependencies: Coverage guarantees; versioning; community acceptance.
- On-device/offline agent judges (Edge, Privacy)
- What: Lightweight evaluators for private or low-connectivity settings (e.g., mobile health, field engineering).
- How: Distilled judge models; compact toolkits; deferred sync for provenance.
- Dependencies: Model compression; local tool substitutes; energy constraints.
- Energy and infrastructure forecasting audits (Energy, Utilities)
- What: Verify LLM forecasts against live telemetry, grid constraints, and historical baselines; flag brittle plans.
- How: Time-series tools, constraint solvers, retrieval of regulatory/market data; scenario probing.
- Dependencies: Data access; domain-specific constraints; robust backtesting.
- Safety controllers for tool-using agent chains (Safety, Autonomy)
- What: Formal-methods–augmented judges that gate high-impact tool calls (code execution, transactions, actuators).
- How: Program analysis, type/contract checking, simulation-before-commit; multi-agent “court” for appeals.
- Dependencies: Usable formal specs; acceptable latency; governance for overrides.
- Reality-checkers for AR/VR/XR content (Immersive media)
- What: Evaluate geometric consistency, physics plausibility, and user-safety constraints of generated scenes.
- How: Sensor fusion, physics engines, spatial semantics checkers; user-intent rubrics.
- Dependencies: Standardized scene graphs; device APIs; safety certifications.
- Fairness/bias auditing via diverse persona panels (Policy, HR Tech)
- What: Multi-agent panels reflecting demographic and value diversity to evaluate disparate impacts and harms.
- How: Persona-conditioned judging with counterfactual probing and debate; causal error analysis.
- Dependencies: Ethical data use; representativeness; stakeholder governance.
Notes across applications (assumptions/dependencies that affect feasibility)
- Cost and latency: Agentic evaluation is multi-step and tool-heavy; budget and SLOs must be set per use case.
- Safety and privacy: Tool calls and memory introduce attack surfaces and PII risk; sandboxing, RBAC, and red-team evals are required.
- Calibration and trust: Align judges to human gold standards; monitor for bias, position effects, and overfitting to rubrics.
- Tool reliability and provenance: Maintain verifiable logs, source citations, and deterministic re-runs where possible.
- Domain adaptation: Many applications need domain-specific rubrics, knowledge bases, and localized policies to be effective.
Glossary
- Adaptive Router: A specialized agent component that dynamically selects evaluation paths or criteria based on context. "AGENT-X~\cite{li2025AGENT-X} uses an Adaptive Router to infer domain context and plan bespoke detection guidelines."
- Adversarial debate frameworks: Multi-agent setups that simulate opposing legal roles to stress-test and improve judgment robustness. "AgentsCourt~\cite{he2024agentscourt} introduces adversarial debate frameworks where agents role-play as prosecutors, defense attorneys, and judges, exposing the evaluating agent to conflicting arguments to improve verdict robustness."
- Agent-as-a-Judge: A paradigm where autonomous agents perform evaluations using planning, tools, memory, and collaboration. "Agent-as-a-Judge, where agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory to enable more robust, verifiable, and nuanced evaluations."
- Agentic judges: Evaluator agents endowed with capabilities like planning, tool use, memory, and collaboration. "agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory"
- Agentic loop: An iterative evaluation process where agents gather evidence and refine verdicts over multiple steps. "FACT-AUDIT~\cite{lin-etal-2025-fact} models fact-checking as an agentic loop with multi-agent collaboration"
- Agentic Reward Modeling: An approach that combines preference signals with verifiable checks to produce reliable evaluation rewards. "Agentic Reward Modeling~\cite{peng2025AgenticRM} further integrates correctness verification by combining fact-checking tools and programmatic validators to produce structured correctness signals that inform the final evaluation."
- Autonomous termination: A planning feature where an agent decides when to stop based on sufficient evidence. "This system further optimizes efficiency through autonomous termination, allowing the agent to self-monitor information gain and proactively halt execution once sufficient evidence is gathered."
- Bench deliberation processes: Simulations of judicial panel discussions to capture consensus and dissent in legal judgments. "SAMVAD~\cite{devadiga2025samvad} and AgentsBench~\cite{jiang2025agentsbench} model judicial consensus by simulating bench deliberation processes, capturing interactions between concurring and dissenting opinions to enhance legal judgment prediction."
- Chain-of-thought prompting: Prompting that elicits step-by-step reasoning to improve evaluation alignment. "G-Eval \citep{liu2023G-Eval} leveraged chain-of-thought prompting for better alignment in natural language generation (NLG)"
- Cognitive overload: The inability of single-pass judges to comprehensively assess many criteria at once. "traditional LLM judges experience cognitive overload when attempting to evaluate all dimensions comprehensively within a single inference step"
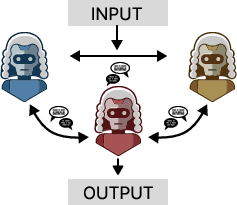
- Collective Consensus: A multi-agent topology where diverse agents debate to reach an aggregated judgment. "Multi-agent evaluation frameworks adopt two main topologies: Collective Consensus and Task Decomposition."
- Conditional routing: Reactive decision-making that selects next steps based on intermediate feedback within fixed spaces. "such reactivity remains confined to conditional routing within fixed decision spaces"
- Controlled falsification: An evaluation strategy that tries to refute claims using formal or statistical tests. "Popper~\cite{huang2025popper} formulates judgment as controlled falsification, using statistical tests to validate free-form claims."
- Correctness verification: Tool-based checks ensuring that outputs or reasoning satisfy explicit logical or factual constraints. "tool-augmented evidence collection and correctness verification"
- Courtroom-inspired discussion mechanism: A structured multi-agent debate protocol with roles mirroring court proceedings. "ChatEval~\cite{chan2024ChatEval} pioneered this with a courtroom-inspired discussion mechanism where agents debate as equals following predefined protocols."
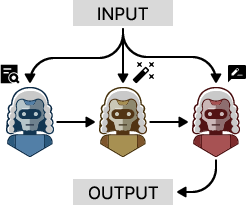
- Divide and Conquer: A strategy that splits complex evaluations into specialized sub-tasks handled by different agents. "Task Decomposition employs a 'Divide and Conquer' strategy, delegating distinct subtasks to specialized agents for systematic evaluation, illustrated in Figure~\ref{fig:multiagent-topologies}."
- Equivalence checking: Assessment of whether different mathematical or logical expressions represent the same solution. "CompassVerifier~\cite{liu-etal-2025-compassverifier} and xVerify~\cite{chen2025xverify} focus on mathematical and logical outputs, addressing equivalence checking under diverse surface forms."
- Fine-grained feedback: Detailed, aspect-level evaluation comments pinpointing specific strengths or flaws. "providing fine-grained feedback on each aspect~\cite{li2025AGENT-X}"
- Formal theorem proving: The use of automated proof systems to validate mathematical reasoning. "HERMES~\cite{ospanov2025HERMES} verifies mathematical reasoning through formal theorem proving"
- Hallucinated correctness: Judgments that deem outputs correct based on plausible language rather than verified facts. "leading to \"hallucinated correctness\" in complex tasks~\cite{peng2025AgenticRM}."
- Hierarchical reasoning: Multi-level, structured analysis that decomposes evaluation into progressively refined steps. "Agent-as-a-Judge addresses this by transforming evaluation from a single-pass inference into autonomous, hierarchical reasoning"
- Logic trees: Extracted structured representations of argument or report logic used to assess reasoning quality. "FinResearchBench~\cite{sun2025finresearchbench} extracts logic trees from reports as intermediate structures for comprehensive assessment"
- Long-context factual consistency: The property of maintaining accurate facts across lengthy narratives or dialogues. "NarrativeFastScore~\cite{jeong-etal-2025-agent} addresses long-context factual consistency by constructing character-level knowledge representations"
- Meta-evaluator: A higher-level judge that critiques and corrects other judges’ decisions. "SAGEval~\cite{ghosh2024SAGEval} introduces supervision via a \"Judge the Judge\" meta-evaluator that reviews previous agents' decisions"
- Monolithic LLM judges: Single-model evaluators prone to uniform biases and limited adaptability. "To mitigate the inherent parametric biases of monolithic LLM judges—such as the tendency to favor verbosity or their own output patterns—Agent-as-a-Judge paradigms employ specialized, decentralized agents"
- Multi-agent collaboration: Coordinated evaluation by multiple agents to reduce bias and improve robustness. "multi-agent collaboration"
- Multi-agent deliberation: Structured debate among agents to audit biases and reach a more reliable collective judgment. "Furthermore, multi-agent deliberation ensures collective robustness; distinct roles can isolate specific information points to neutralize bias, while debate and self-reflection allow agents to audit their own cognitive shortcuts"
- Multi-round planning: Iterative planning that updates evaluation strategies over several rounds based on feedback. "Evaluation Agent~\cite{zhang2025EvaluationAgent} introduces dynamic multi-round planning, where agents adjust strategies based on intermediate feedback."
- Persistent memory: Long-lived storage of information across evaluations to support consistency and personalization. "persistent memory"
- Procedural Agent-as-a-Judge: Systems with predefined workflows or fixed agent roles that cannot adapt to novel scenarios. "Procedural Agent-as-a-Judge decouples monolithic inference into agentic predefined workflows"
- Query Generator: A component that plans targeted searches to discover or refine evaluation rubrics. "EvalAgents~\cite{wadhwa2025EvalAgents} exemplifies this by employing a Query Generator that plans web searches to discover implicit rubrics"
- Reactive Agent-as-a-Judge: Agents that adapt execution paths and tool calls based on intermediate feedback. "Reactive Agent-as-a-Judge enables adaptive decision-making by routing execution paths"
- Reality gap: The discrepancy between plausible language judgments and verifiable real-world correctness. "Agent-as-a-Judge bridges this reality gap by replacing intuition with execution."
- Reinforcement learning: Optimization approach where judges learn evaluation actions via reward signals over trajectories. "LLM judges can provide reward signals for reinforcement learning~\citep{lee2024RLAIF-vs-RLHF}"
- Reward hacking: Exploiting flaws in evaluation criteria to achieve high scores without genuine correctness. "OnlineRubrics~\cite{rezaei2025OnlineRubrics} integrates planning into reinforcement learning, evolving rubrics alongside policy optimization to detect reward hacking."
- Rubric Discovery: The agent capability to autonomously formulate and refine evaluation criteria. "Rubric Discovery."
- Self-Evolving Agent-as-a-Judge: Highly autonomous systems that refine rubrics and memory during operation. "Self-Evolving Agent-as-a-Judge represents the cutting edge of the field, characterized by high autonomy and the ability to refine internal components during operation—synthesizing evaluation rubrics on-the-fly"
- Structured correctness signals: Formalized verification outputs (e.g., program checks, facts) used to inform final judgments. "produce structured correctness signals that inform the final evaluation."
- Task Decomposition: Dividing evaluation into specialized sub-components handled by different agents or stages. "Task Decomposition employs a 'Divide and Conquer' strategy, delegating distinct subtasks to specialized agents for systematic evaluation"
- Tool-augmented verification: Using external tools (search, interpreters, provers) to validate claims and reasoning. "tool-augmented verification"
- Workflow orchestration: Designing and managing the sequence of evaluation steps, from static pipelines to adaptive flows. "Workflow orchestration in Agent-as-a-Judge systems spans from static frameworks to dynamic agency"
Collections
Sign up for free to add this paper to one or more collections.