- The paper demonstrates that context-aware evaluation via the CARE protocol significantly improves multi-hop RAG performance, achieving up to 16% F1 gains over indirect and direct methods.
- It rigorously compares three LLM-based retriever evaluation strategies across datasets like HotPotQA, MuSiQue, and SQuAD 2.0, highlighting CARE's ability to integrate interdependent evidence.
- Findings suggest that while context-aware evaluation boosts multi-hop reasoning, direct evaluation suffices for single-hop queries and resource-limited scenarios.
Evaluating Multi-Hop Reasoning in RAG Systems: A Critical Assessment of LLM-Based Retriever Evaluation Strategies
Introduction
Retrieval-Augmented Generation (RAG) has become a canonical architecture for mitigating factuality limitations and hallucinations in LLM-based QA by using external knowledge sources. Despite substantial innovation in effective prompting, retriever models, and generation protocols, the evaluation of RAG—in particular retriever evaluation—remains underdeveloped, especially for multi-hop queries where correct answers depend on reasoning over multiple, potentially individually "irrelevant," documents. This work systematically explores three LLM-based, reference-free retriever evaluation strategies with a concentration on multi-hop context dependencies. The centerpiece is the introduction of the Context-Aware Retriever Evaluation (CARE) protocol, whose design and empirical analysis contribute a quantitative and qualitative lens for RAG system assessment on prominent datasets using commercial and open-source LLMs.
Background: Limitations of Existing Retriever Evaluation Protocols
Standard RAG evaluation approaches primarily classify into labeled and unlabeled paradigms. Labeled strategies use datasets with pre-annotated relevant contexts, but in practice suffer from chunking inconsistencies, missing negative samples, and labeling ambiguity. Unlabeled strategies, increasingly dominant due to their adaptability, leverage only the input query and its answer for context relevance assessment, often employing an LLM-as-judge methodology.
Most prior approaches evaluate each retrieved context independently (via either direct judgment or generation/answer matching). Such independence assumptions break under multi-hop QA regimes, where the answer typically emerges only from collectively integrating evidence across document subsets. Prior methods—such as ARES (Saad-Falcon et al., 2023) (direct) and eRAG (Salemi et al., 2024) (indirect)—lack explicit modeling of such combinatorial dependencies, limiting their utility for realistic RAG deployments targeting non-trivial, compositional question answering.
Core Evaluation Strategies Compared
Three main evaluation methods are considered:
- Indirect Approach: An LLM attempts to answer the query with each context in isolation, labeling relevant only those contexts where the answer matches the ground truth.
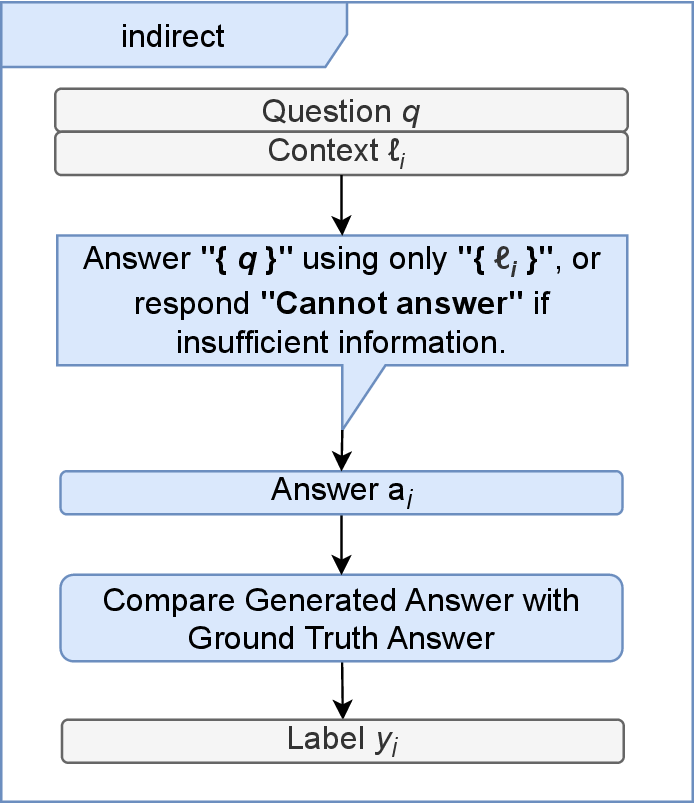
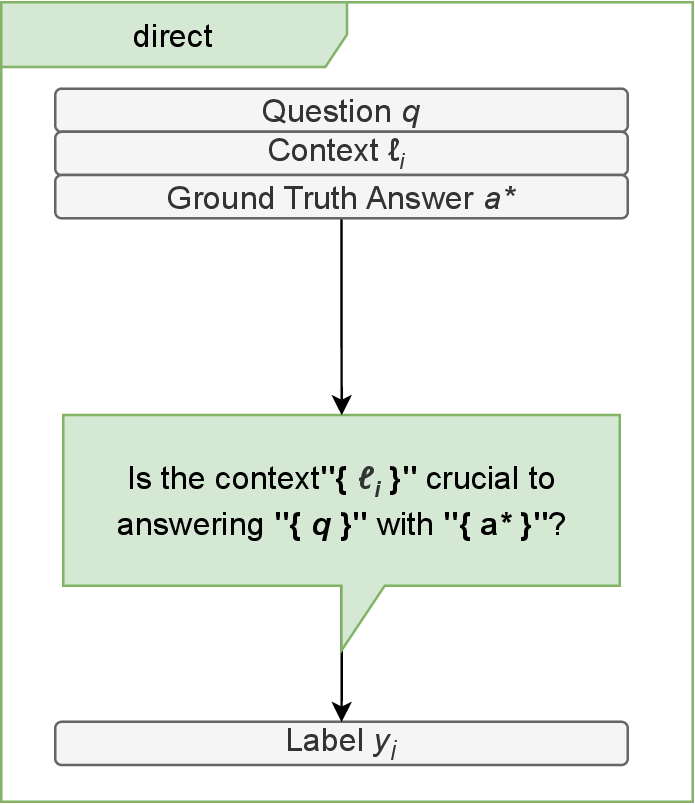
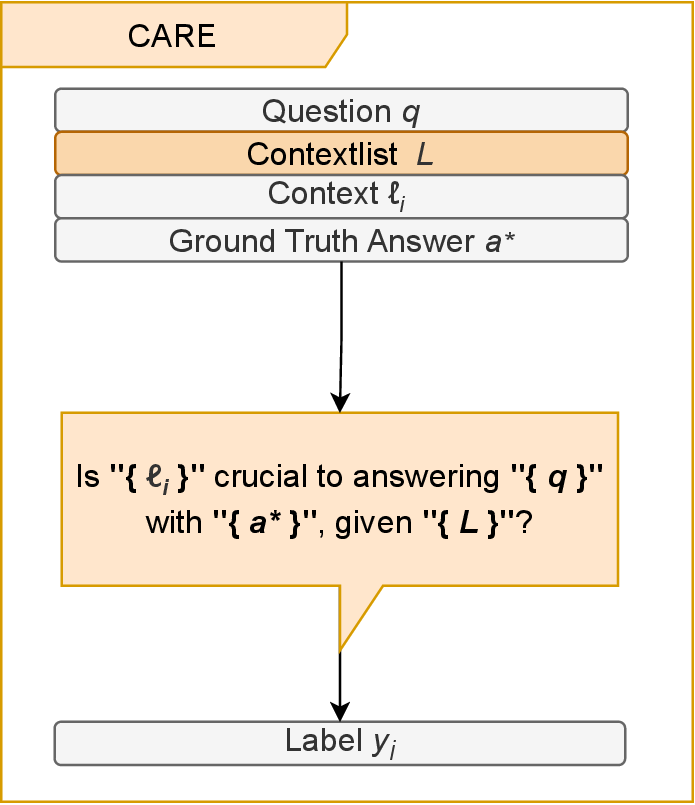
Figure 1: Overview of the indirect approach, in which context relevance is inferred by attempting answer generation with individual contexts.
- Direct Approach: The LLM is prompted to label each context as relevant or not, provided with the query, context, and ground-truth answer. This is agnostic to the interaction amongst other contexts.
- Context-Aware Retriever Evaluation (CARE): The main innovation, CARE, extends the direct approach by supplying the full set of retrieved contexts in the LLM prompt, enabling reasoning about context interdependencies, especially relevant for multi-hop questions.
Experimental Setup and Metrics
The three strategies are evaluated in a synthetic RAG setup using HotPotQA (Yang et al., 2018), MuSiQue [trivedi2021musique], and SQuAD 2.0 (Rajpurkar et al., 2018), covering both multi-hop and single-hop regimes. Multiple LLMs (different parameter scales; OpenAI, Google Gemini, Meta LLaMa) are benchmarked to rigorously assess the effect of model size and context window length. The primary metrics are accuracy, F1, recall, and precision, with bootstrapped CIs and permutation tests for robustness.
Empirical Results
CARE consistently yields the highest accuracy, F1, and recall on multi-hop datasets, with F1 improvements up to approximately 16% over direct and 34% over indirect methods across datasets and LLMs. The precision of all systems remains high, but the recall of indirect and direct methods collapses in more complex settings—highlighting the inability to identify all jointly relevant supporting contexts when evaluated independently. The advantage of CARE is especially evident on bridge and comparison question types, and on more difficult examples (as classified in HotPotQA).
Model Size and Context Window Analysis
Performance gains from CARE are modulated by both LLM parameter count and context length capability. Smaller models and those with shorter context windows show performance degradation in CARE—occasionally reversing the improvement compared to baselines. The result confirms that context-aware evaluation places additional reasoning and memory demands on the underlying LLM judge.
Prompting Strategies and Operational Trade-Offs
Prompting design has marked impact: concise (short) and role-based prompts elevated F1 and recall, while chain-of-thought prompting systematically reduced CARE accuracy—primarily due to increased hallucinations and difficulty tracking complex context dependencies. CARE's prompt is substantially longer (on average over 4x the direct/indirect lengths), raising requirements and latency considerations.
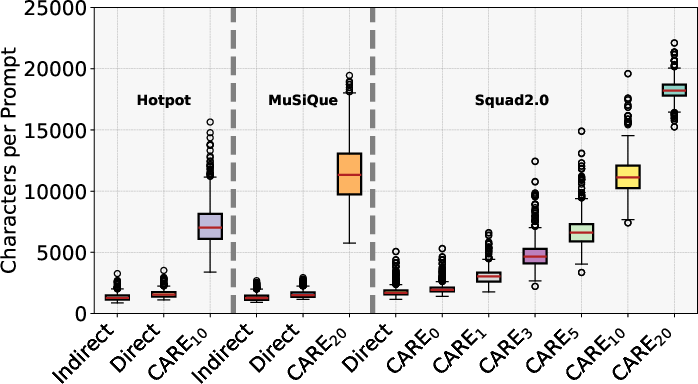
Figure 2: Average prompt length by evaluation approach, with CARE prompts significantly increasing token usage in multi-hop settings.
Ablation: Single-Hop Scenarios and Context List Size
In single-hop (SQuAD 2.0) cases, direct evaluation outperforms CARE, and the latter’s performance declines as context list size increases, underscoring that context-aware strategies confer no benefit, and may even introduce extraneous complexity, when only one supporting document is actually relevant.
Theoretical and Practical Implications
The comprehensive analysis demonstrates that the CARE protocol’s modeling of cross-context dependencies is critical for reliable retriever evaluation in genuinely compositional QA scenarios. This highlights the necessity of future RAG evaluation benchmarks and methods to explicitly address context joint relevance and compositionality, as argued in recent works in RAGBench (Friel et al., 2024), MultiHop-RAG (Tang et al., 2024), and CoFE-RAG (Liu et al., 2024).
From a deployment perspective, practitioners should use context-aware evaluation for any RAG configuration serving multi-hop or multi-fact queries. For single-hop or resource-constrained environments, direct methods remain suitable. Notably, the results here suggest that high-cost, high-parameter LLM “judges” are not strictly necessary for effective evaluation as long as context length and baseline reasoning capacity suffice, but caution is required with the smallest models. The demonstrated resilience to missing ground-truth answers also renders CARE valuable for live monitoring without curated QA datasets.
Limitations and Future Research
The main limitation lies in exclusive use of well-structured, “clean” text-only datasets. Evaluation in the open—where retrieval includes noisy, unstructured, or multimodal data streams—remains largely unexplored. Further granular ablation is warranted regarding context count, support context difficulty, and potential for spurious correlation between LLM size and effective context integration in multi-hop settings. Careful study is also needed on prompt scaling and budget constraints in production RAG evaluation cycles.
Conclusion
This work provides a rigorous comparison of LLM-based, reference-free retriever evaluation methods for RAG, demonstrating definitively that context-aware judgment is essential for robust multi-hop performance. The findings support a paradigm shift in RAG evaluation, establishing that compositionality-aware metrics should be standard for contemporary QA evaluation. Continued investigation is needed into the scaling properties of such protocols and their generalization to multimodal and low-resource domains.