- The paper demonstrates that SAM3's PCS struggles with specialized histopathology terms, yielding low mIoU in zero-shot settings.
- The study evaluates SAM3 under zero-shot, few-shot, and fully supervised regimes, showing that high-quality visual prompts and adapters improve segmentation accuracy.
- The work highlights a persistent gap between SAM3 and pathology-specific models, underscoring the need for domain-specific adaptation.
Systematic Evaluation of SAM3 for Pathology Segmentation
Introduction
This essay presents an authoritative overview of "Is SAM3 ready for pathology segmentation?" (2604.18225), which rigorously investigates the applicability of Segment Anything Model 3 (SAM3) to intricate digital pathology segmentation tasks. The paper scrutinizes SAM3's Promptable Concept Segmentation (PCS) feature across nuclei-level and tissue-level benchmarks, mapping the model's operational and conceptual boundaries with respect to prompt-based and supervised protocols. Given the complexities of histopathological data—dense nuclei, specialized terminology, and domain shifts—the study benchmarks SAM3 in zero-shot, few-shot, and fully supervised regimes, deploying both visual and textual prompting strategies.
Domain Challenges and Motivation
Pathology image segmentation is central to computational histopathology but is impeded by annotation scarcity and domain-specific visual semantics. The SAM family [kirillov2023segment, carion2025sam]—originating from large-scale pretraining on natural images—offers unified prompting interfaces that substantially reduce annotation requirements. However, the transferability of such models, particularly SAM3 with PCS, to histopathological domains remains questionable due to:
- Fundamental morphological dissimilarity between natural and medical images
- Specialized biomedical vocabularies not represented in pretraining datasets
- Requirements for precise mask delineation at micro (nuclei) and macro (tissue) levels
The study frames the evaluation around whether SAM3’s semantic and spatial prompt mechanisms suffice to overcome these domain-specific hurdles, or whether targeted adaptation remains indispensable.
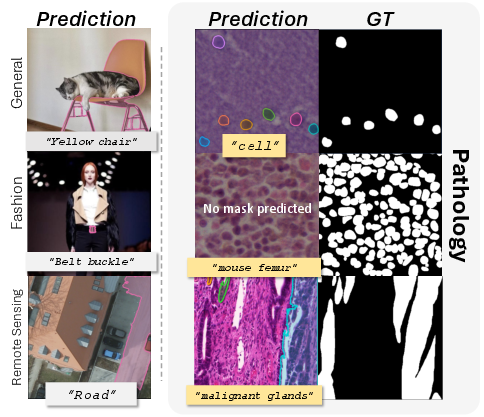
Figure 1: SAM3 mask predictions with diverse prompt concepts on natural versus histopathological images, highlighting successful generic activation but frequent failures with specialized medical terms.
Evaluation Protocol and Methodology
SAM3's performance is dissected under three distinct supervision regimes:
- Zero-shot: SAM3 is frozen and prompted on the test image via textual (PCS) or visual (points/boxes) cues.
- Few-shot (Training-free): Visual prompts are generated from a limited annotated support set, mimicking realistic low-supervision deployment scenarios.
- Fully supervised: SAM3 is adapted using lightweight adapters (SAM3-Adapter [SAM3-Adapter]) trained on domain data, serving as a reference for upper-bound performance.
Experiments span NuInsSeg (nuclei segmentation), PanNuke (multi-class nuclei), and GlaS (tissue segmentation), reporting mIoU and Dice scores. The evaluation maintains architectural and inference consistency across SAM1, SAM2, and SAM3 for comparability [SAM_2023, SAM_2_2024, SAM_3_2025].
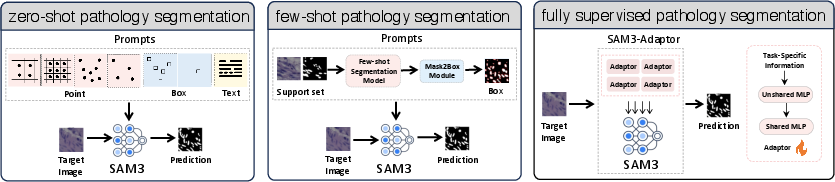
Figure 2: Experimental framework illustrating prompt construction and supervision regimes for SAM3 segmentation studies.
Zero-shot Text Prompts: Semantic Fragility
Textual prompts activate PCS for semantic mask generation. The empirical findings reveal striking fragility:
- Specialized terminology commonly fails to trigger segmentation (e.g., “mouse femur”), yielding mIoU<10% on NuInsSeg and PanNuke.
- Generic terms such as “cell” afford markedly higher activation in NuInsSeg (68.15%) but break down in multi-class or complex scenes (PanNuke: 6.22%).
- LLM-generated vocabulary marginally improves activation probabilities, outperforming strict medical terminology by up to 6.43% mIoU.
These results underscore that while SAM3's PCS aligns well with broad biomedical concepts, it does not reliably link specialized pathology semantics to target visual patterns.
Figure 1: Failure modes of SAM3 PCS in histopathology include both activation and reliability failures, particularly for domain-specific terminology.
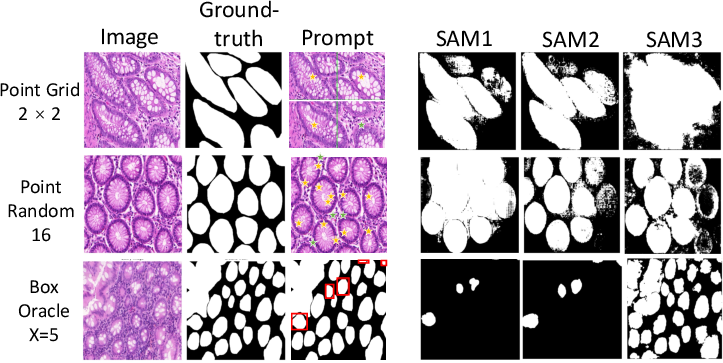
Zero-shot Visual Prompts: Spatial Leverage and Limitation
Visual prompts (points/boxes) represent spatial guidance mechanisms. Detailed analysis reveals:
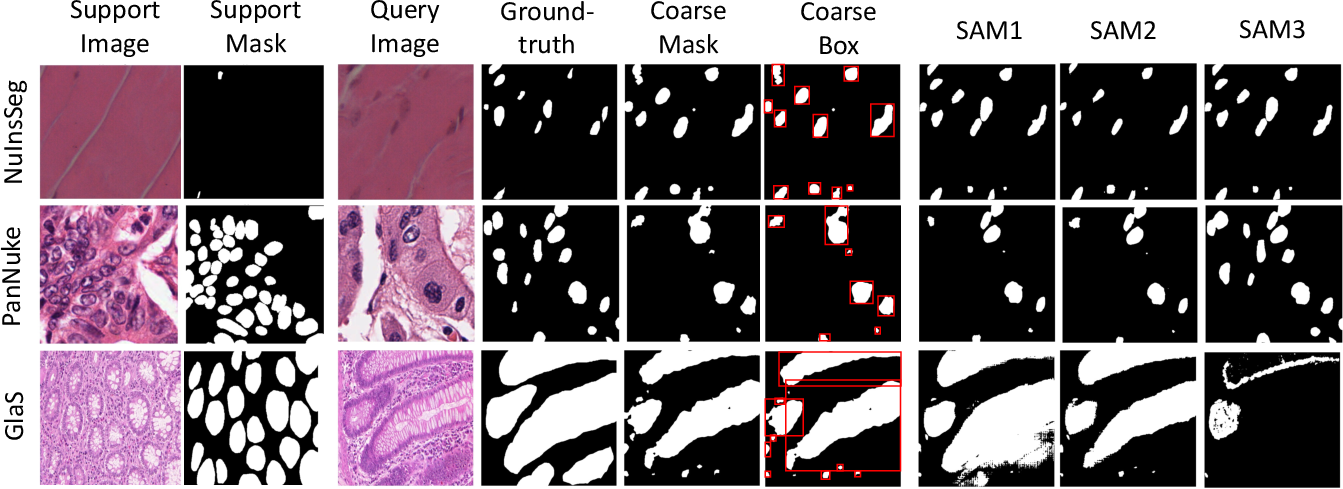
Few-shot and Training-free Regimes: Prompt Quality Sensitivity
The study explores contextual prior generation via prototype-based few-shot segmentation (FSS) to supply visual prompts. Key observations include:
Supervised Adaptation: Reference Gap to Domain-Specific Methods
Adapter-based fine-tuning delivers substantial performance enhancement, achieving Dice scores up to 80.14% on NuInsSeg. However, the following discrepancy persists:
- Even with full adaptation, SAM3-Adapter underperforms state-of-the-art supervised pathology segmentation (e.g., NuInsSeg: 81.4% Dice; GlaS: 86.84% mIoU [mahbod2024nuinsseg, li2022online]).
- The gap between zero-shot/few-shot prompting and supervised adaptation is pronounced, confirming the significant benefit of domain-specific parameter updates.
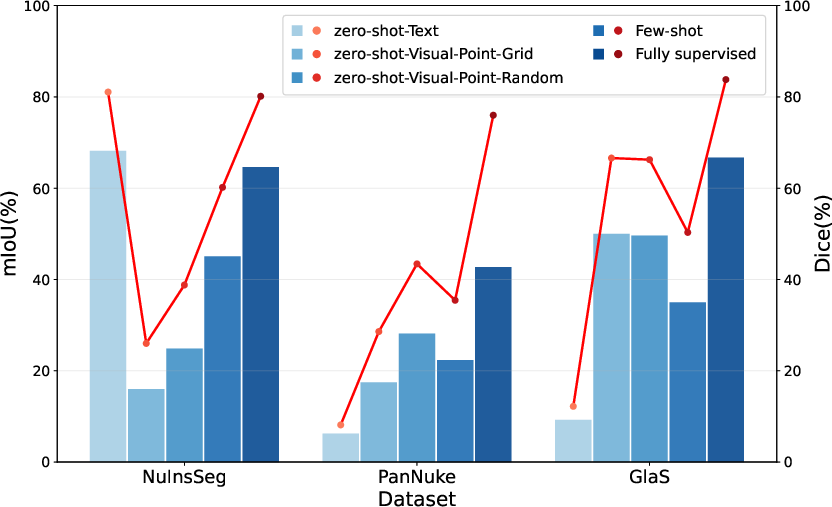
Figure 5: Comparative performance of SAM3, SAM3-Adapter, and pathology-specific models under fully supervised regimes, illustrating persistent shortfall of generic adaptation.
Theoretical and Practical Implications
The systematic evaluation leads to several practical recommendations and theoretical insights:
- Prompt diversity and quality are essential—box prompts are recommended over point prompts, and increasing box budgets enhances segmentation, especially for nuclei-rich scenes.
- Expanding textual prompt vocabulary with LLM-generated variants improves robustness, but does not compensate for the semantic gap.
- In low-supervision scenarios, deriving prompts from contextual priors (few-shot segmentation) offers practical utility, albeit with sensitivity to mask noise.
- Full domain-specific adaptation (e.g., via adapters) is necessary for competitive performance, but even this does not entirely bridge the gap to models designed or extensively trained for pathology.
- The findings delineate clear boundaries of SAM3 as a general-purpose segmentation tool: PCS remains unreliable for specialized pathology concepts without substantial domain adaptation.
Speculation on Future Directions
Advancements in joint vision-language pretraining over domain-specific (medical/pathology) corpora may enhance semantic alignment and reduce the activation failures observed. Integration of dataset-scale pathology image-text resources [ikezogwo2023quilt], improved prompt engineering, and cross-modal hybridization (SAM+VLM) [OVSAM2024], as well as task-adaptive architectures (e.g., MedSAM [MedSAM2024], CellSAM [israel2025cellsam]), may further narrow the transferability gap. Additionally, parameter-efficient adaptation strategies (LoRA, adapters, diffusion-based prompt generation) are expected to become crucial for practical deployment of foundation models in digital pathology.
Conclusion
SAM3's Promptable Concept Segmentation affords novel interface opportunities but remains semantically unreliable and spatially limited in histopathology segmentation. Strong visual prompts improve performance, and adapter-based supervision provides practical gains, yet there is a substantial gap to the capabilities of pathology-specialized, fully supervised methods. Deploying SAM3 in digital pathology thus necessitates domain-specific adaptation and careful prompt selection. The findings serve as a guide for further research into foundation models’ transferability and highlight the enduring importance of data-centric adaptation in medical imaging.