MedSAM3: Delving into Segment Anything with Medical Concepts
Abstract: Medical image segmentation is fundamental for biomedical discovery. Existing methods lack generalizability and demand extensive, time-consuming manual annotation for new clinical application. Here, we propose MedSAM-3, a text promptable medical segmentation model for medical image and video segmentation. By fine-tuning the Segment Anything Model (SAM) 3 architecture on medical images paired with semantic conceptual labels, our MedSAM-3 enables medical Promptable Concept Segmentation (PCS), allowing precise targeting of anatomical structures via open-vocabulary text descriptions rather than solely geometric prompts. We further introduce the MedSAM-3 Agent, a framework that integrates Multimodal LLMs (MLLMs) to perform complex reasoning and iterative refinement in an agent-in-the-loop workflow. Comprehensive experiments across diverse medical imaging modalities, including X-ray, MRI, Ultrasound, CT, and video, demonstrate that our approach significantly outperforms existing specialist and foundation models. We will release our code and model at https://github.com/Joey-S-Liu/MedSAM3.
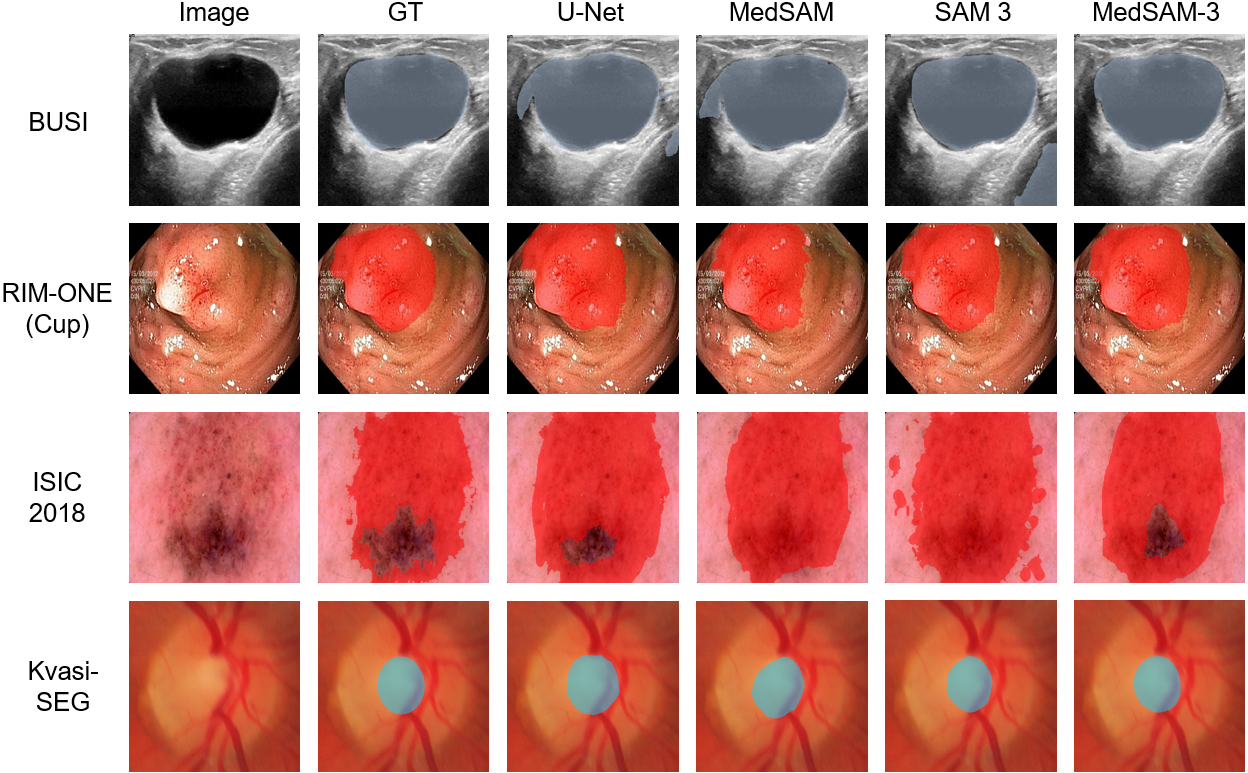
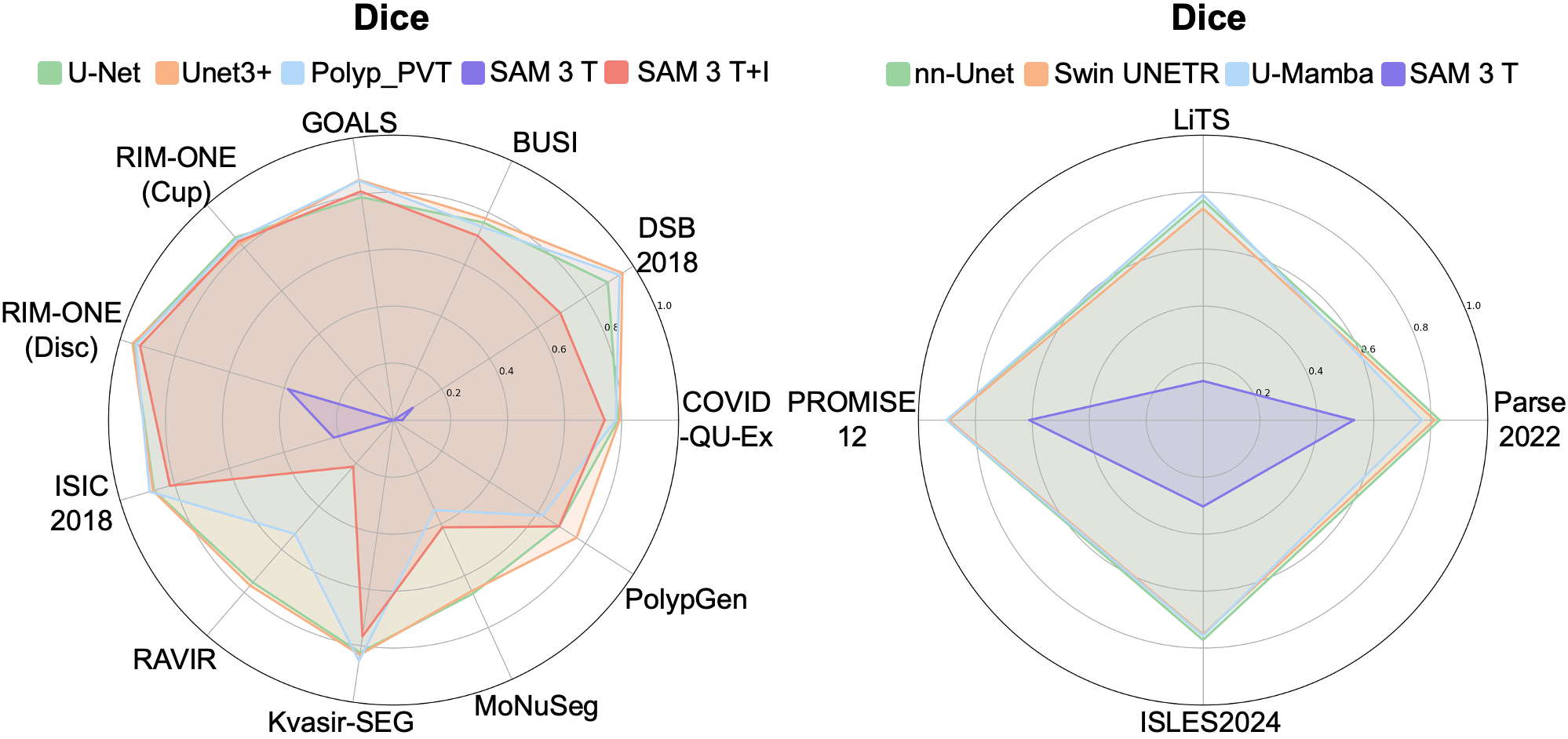
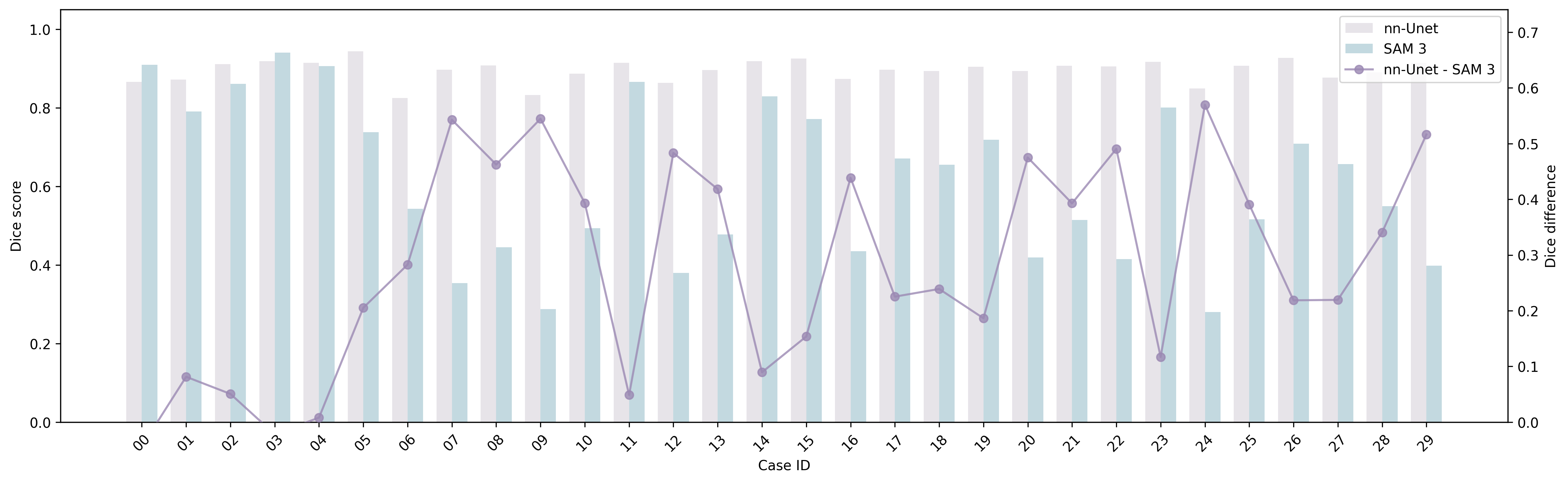
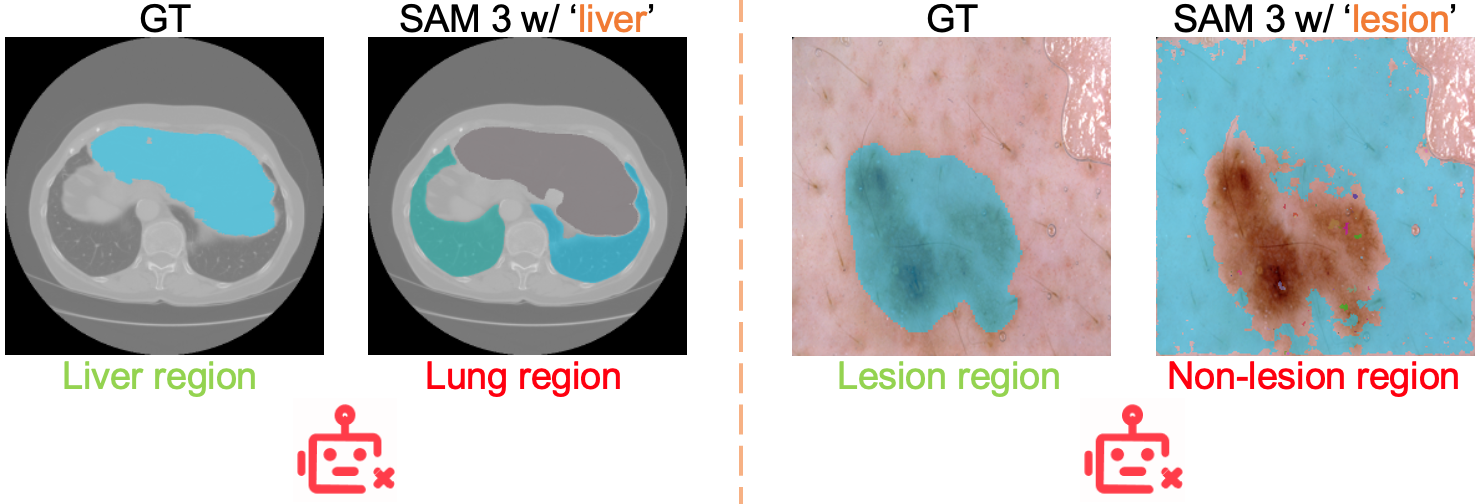
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a powerful AI tool to “find and color” important parts in medical pictures (like X-rays, MRIs, ultrasounds, and CT scans). The tool is called MedSAM-3. It lets doctors ask for what they want using short text, like “segment the liver tumor,” instead of carefully clicking points or drawing boxes by hand. The paper also introduces an “agent” that acts like a smart helper, using a LLM to plan, check, and refine the results step by step.
What are the researchers trying to do?
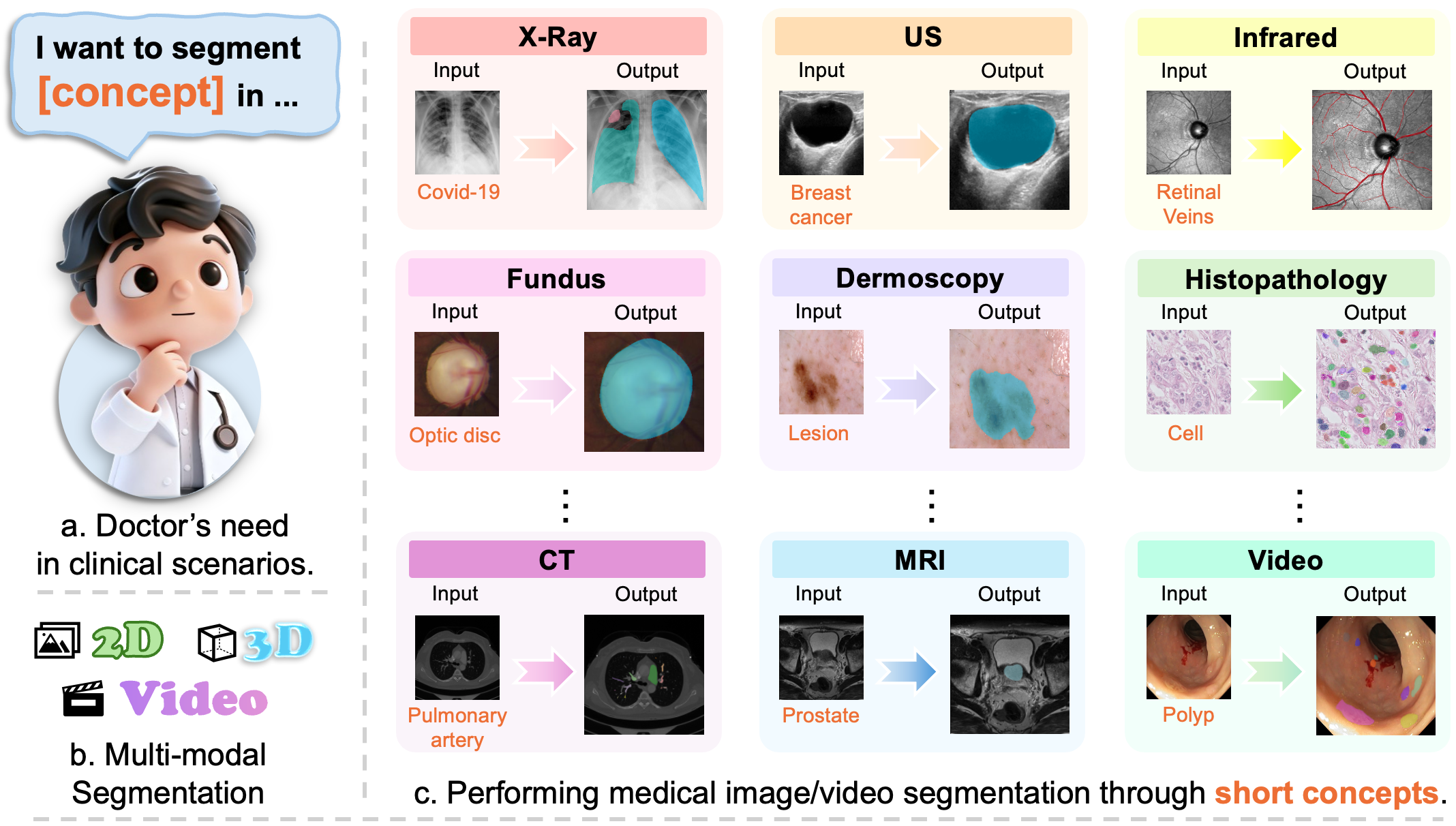
- Build a general tool that can segment medical images using simple, concept-based text prompts (for example, “optic disc,” “polyp,” or “stroke lesion”), not just shapes like points or boxes.
- Make the tool work well across different types of medical images (X-ray, MRI, ultrasound, CT, and video) without training a new model for every single task.
- Add a smart assistant that can understand longer, more complex instructions, and improve results by iteratively checking and correcting them.
How did they do it?
Think of medical image segmentation like a coloring book: the goal is to color only the correct shape (the organ or lesion) without spilling into other parts.
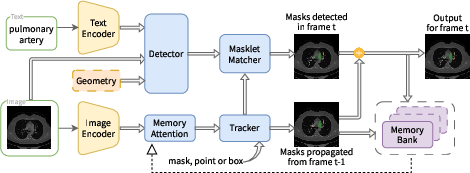
- The base tool, called SAM 3, is good at segmenting things in everyday photos. It can follow “prompts,” which are instructions that guide what to color. There are two kinds:
- Promptable Visual Segmentation (PVS): you show it where to look using visual hints like a box around the area.
- Promptable Concept Segmentation (PCS): you tell it what to color using short text, like “polyp” or “breast tumor.”
- The researchers found that “raw” SAM 3 didn’t understand medical concepts very well. So they “fine-tuned” it—like teaching a general student specialized medical vocabulary—using curated medical images paired with short, precise phrases (no more than three words).
- During fine-tuning, they kept the image and text encoders fixed (to preserve general knowledge) and improved the detector/tracker parts (the modules that actually find and color the requested object).
- They tested two training and usage styles:
- Text-only: just a short medical phrase (e.g., “optic cup”).
- Text + bounding box: the phrase plus a simple rectangle that roughly points to the right area.
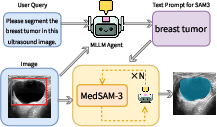
- They also built the MedSAM-3 Agent. This is a pipeline that uses a multimodal LLM (an MLLM) as a planner. The agent:
- Reads the user’s request and looks at the image.
- Creates a step-by-step plan and asks MedSAM-3 to segment.
- Reviews the result and iteratively refines prompts or steps until the mask looks right.
What did they find, and why does it matter?
- Raw SAM 3 struggled with medical images:
- It often misunderstood medical terms (for example, “liver” could produce masks of lungs).
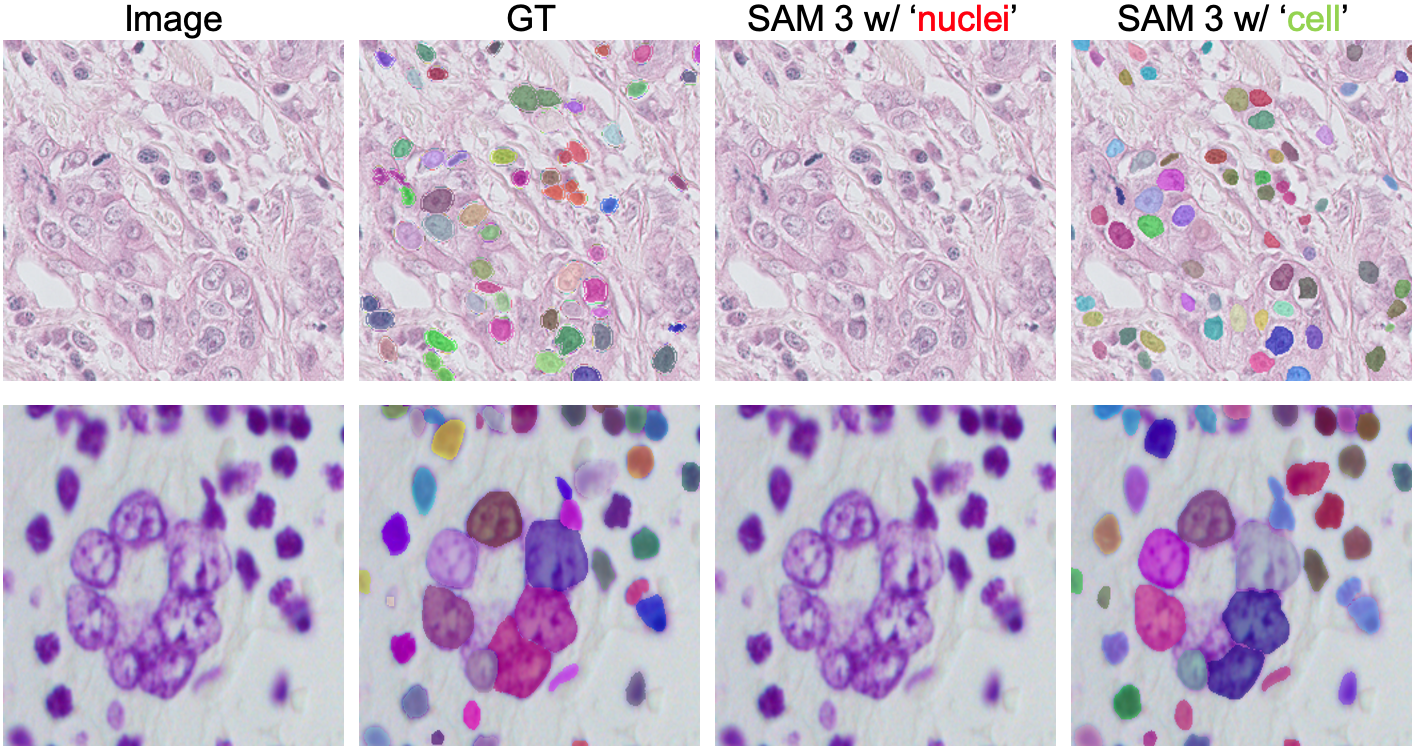
- It had trouble with fine-grained words like “nucleus” vs. “cell.”
- It did much better when given a simple box to guide it, showing that geometric hints help.
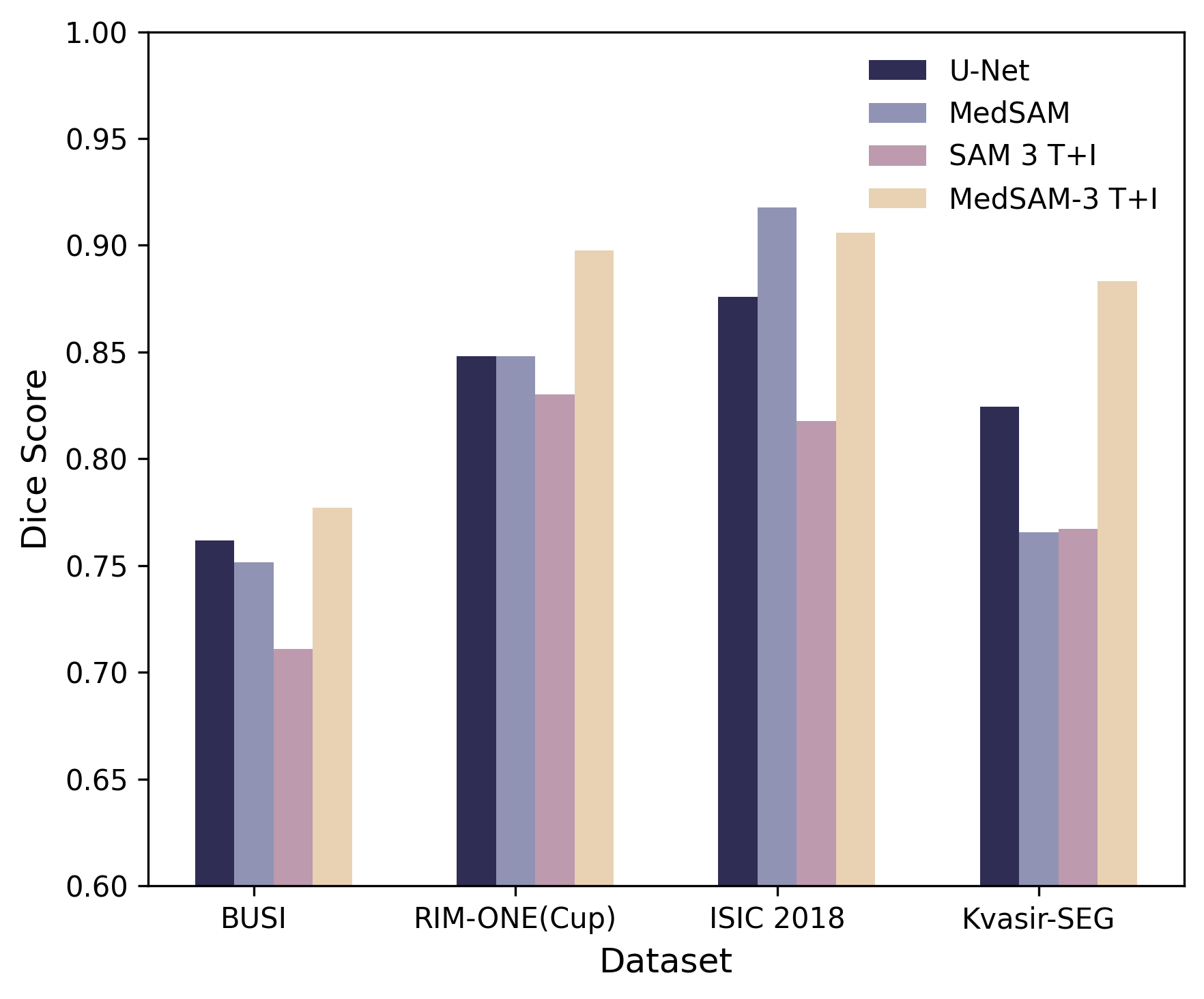
- MedSAM-3 (the fine-tuned version) performed much better:
- Using text alone helped, but text + bounding box worked best.
- It beat or matched strong specialist models on several datasets and image types.
- It needed only a small amount of medical fine-tuning data to improve a lot.
- The MedSAM-3 Agent improved results even further:
- On a breast ultrasound dataset (BUSI), adding the agent increased the Dice score from about 0.777 to about 0.806, showing that planning and iterative feedback can raise accuracy.
- Why this matters:
- Doctors can use short, natural phrases to target what they want, which is faster and less tiring than manually marking images.
- The tool is more general and flexible, so hospitals don’t need separate models for each organ or disease.
- It supports videos and 3D scans, helping with time-based or slice-by-slice analysis.
What is the impact?
MedSAM-3 makes medical image segmentation more natural, using the same kinds of words doctors use every day. This can reduce the time spent on manual drawing, speed up diagnosis and treatment planning, and help standardize workflows across different hospitals and imaging devices. The agent adds a safety layer—planning, checking, and fixing mistakes—which is important in healthcare.
Looking ahead, the authors aim to scale up training with richer medical language and more diverse data, improve text–image alignment, and release code and models to help the community. If developed further and tested carefully in real clinical settings, tools like MedSAM-3 could become everyday assistants for radiologists and clinicians, making medical imaging faster, more accurate, and easier to use.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Limited fine-tuning scope: MedSAM-3 is only fine-tuned on four 2D datasets from a few modalities; no fine-tuning or results are provided for 3D volumetric data or videos, despite claims of broad multimodal applicability.
- Unrealistic evaluation with geometric prompts: The “text+image” setting uses bounding boxes derived from ground-truth masks (largest connected component), which is unavailable at inference time; a realistic evaluation with user-specified boxes or agent-proposed boxes is missing.
- Text-only performance remains weak: MedSAM-3 T (text-only) remains substantially underperforming; concrete strategies to improve concept-only grounding (e.g., unfreezing/fine-tuning the text encoder, training with richer medical text corpora, contrastive learning) are not explored or ablated.
- Frozen encoders without ablation: The image and text encoders are frozen during adaptation; the impact of unfreezing, partial fine-tuning, adapters/LoRA, or selective layer tuning on medical concept grounding is not studied.
- Concept prompt design constraints: Prompts are restricted to ≤3 words and curated from dataset descriptions; robustness to realistic clinical language (long-form instructions, synonyms, abbreviations, negations, compositional queries) and cross-lingual prompts is untested.
- Open-vocabulary generalization remains unvalidated: There is no systematic evaluation of zero-shot segmentation on unseen medical concepts, synonym sets, or compositional instructions that reflect clinical practice (e.g., “segment tumor and surrounding edema,” “all enlarged lymph nodes”).
- 3D handling and volumetric context: 3D datasets are converted to frame sequences and evaluated with text-only prompts; the method’s ability to leverage volumetric continuity (true 3D prompts, 3D memory/tracking, volumetric decoders) is not investigated.
- Video segmentation claims lack evidence: While the architecture and tracker/memory are described, MedSAM-3 is not evaluated on video datasets (temporal stability, drift, identity preservation), nor are video-specific metrics reported.
- Metrics are narrow and task-mismatched: Evaluations rely mainly on Dice; boundary metrics (e.g., HD95), instance-level metrics (AP, PQ) for nuclei datasets, and temporal consistency metrics for videos are missing, limiting clinical relevance and comparability.
- Instance-level vs. semantic segmentation: DSB 2018 and MoNuSeg are instance segmentation problems; treating them as semantic segmentation without instance metrics obscures performance on clinically relevant counting/detection tasks.
- Inconsistency between claims and results: The paper states MedSAM-3 achieves best results on all four benchmarks, yet Table shows it underperforms MedSAM on ISIC 2018; statistical significance, confidence intervals, multiple seeds, and cross-validation are absent.
- Agent evaluation is minimal: The MedSAM-3 Agent is only assessed on the BUSI dataset with Gemini 3 Pro; ablations on number of refinement rounds, agent policies, alternative MLLMs, and generalization across modalities/tasks are missing.
- Agent reliability and “confidence” criteria: The mechanism by which the agent decides task completion or “no valid mask exists,” its calibration, and guardrails against erroneous actions are unspecified; no uncertainty quantification or failure-mode analysis is provided.
- Cost, latency, and reproducibility of agentic workflow: Computational overhead, inference latency, and resource requirements for the agent loop (and MLLM calls) are not measured; reliance on a closed-source model (Gemini 3 Pro) impedes reproducibility and on-prem clinical deployment.
- Human-in-the-loop and annotation efficiency: Claims of streamlined workflows lack quantitative user studies comparing concept prompts vs. geometric prompts (time-to-label, clicks, correction effort) with clinicians or trained annotators.
- Data bias and domain shift: There is no analysis of generalization across institutions, scanner vendors, acquisition protocols, patient demographics, or disease prevalence; potential overlap with SAM 3 pretraining data and its effect on transferability is not addressed.
- Concept ambiguity and disambiguation: Observed misalignment (e.g., “liver” segmenting lungs, “lesion” segmenting non-lesion areas) is documented but not systematically addressed; methods for disambiguation (contextual prompts, ontology grounding, concept normalization) need exploration.
- Language encoder medical grounding: The text encoder’s medical understanding is not improved (e.g., via biomedical corpora or ontologies like SNOMED/UMLS); robustness to typos, abbreviations (e.g., GCIPL), and multilingual inputs is untested.
- Multi-class and relational instructions: No evaluation of multi-target, hierarchical, or relational segmentation (e.g., “disc and cup,” “tumor plus peritumoral edema”) that aligns with clinical instructions and SAM 3’s PCS ambitions.
- Prompt-type trade-offs: The comparative effectiveness of points, boxes, and masks across modalities, lesion sizes, and contrast conditions is not systematically benchmarked to provide guidance on optimal prompt selection in practice.
- Training and reproducibility details: Hyperparameters, data augmentations, number of epochs, optimizer settings, and fine-tuning schedules are not reported; the curated concept–image pairs and their release status are unclear, hindering reproducibility.
- Uncertainty and calibration: No measures of prediction confidence, aleatoric/epistemic uncertainty, or post-hoc calibration are provided—critical for clinical decision-making and agentic stopping criteria.
- Safety, ethics, and regulatory considerations: There is no discussion of PHI handling, auditability, failure reporting, or regulatory pathways for deployment; automation bias and clinician oversight are not addressed.
- Hardware feasibility: Experiments require A100 80GB GPUs; feasibility on typical hospital hardware (e.g., smaller GPUs/CPUs) and model compression/distillation strategies are not evaluated.
- Robustness to imaging artifacts: Sensitivity to noise, motion, low contrast, slice thickness variability, and annotation quality (inter-rater variability) is not analyzed; no stress testing under realistic clinical artifacts.
- Ontology and knowledge integration: The agent/model does not leverage medical ontologies or structured knowledge to resolve fine-grained terminology (e.g., nucleus vs. cell); evaluating ontology-grounded PCS could improve semantic precision.
Glossary
- Adapter layers: Lightweight modules added to pretrained networks to adapt them to new domains or tasks without retraining the entire model; "adapted SAM via fine-tuning or adapter layers to handle medical modalities."
- Agent-in-the-loop: An interactive workflow where an AI agent iteratively refines outputs using planning and feedback; "agent-in-the-loop workflow."
- Agentic architectures: AI system designs that enable autonomous reasoning, planning, and iterative actions; "necessitating a shift towards more agentic architectures."
- Agentic ecosystem: A coordinated environment of AI agents and tools connected via LLMs for complex tasks; "agentic ecosystem supported by multimodal LLMs."
- Agentic framework: A structured agent-based system that reasons, plans, and executes multi-step workflows; "an agentic framework that dynamically reasons, plans, and executes multistep medical segmentation workflows."
- Atomic prompts: Short, minimal text cues intended to specify a target concept precisely; "concise atomic prompts."
- BBX (Bounding Box): A rectangular spatial cue used to localize objects for segmentation; "Text + BBX."
- Cross-attention: Transformer mechanism that aligns features from different sources (e.g., current frame with memory); "cross-attention mechanisms."
- Dice score: A segmentation accuracy metric measuring overlap between predicted and ground-truth masks; "Dice score improved from 0.7772 to 0.8064."
- Domain adaptation: Tailoring a model to a specific application area through targeted training or fine-tuning; "coupling domain adaptation with agentic workflows."
- Dual encoder-decoder transformer: An architecture with paired encoders/decoders (e.g., detector and tracker) for images and videos; "dual encoder-decoder transformer design."
- Edema: Abnormal fluid accumulation in tissues, often adjacent to tumors in medical imaging; "segment the tumor and surrounding edema."
- Foundation models: Large pretrained models intended to generalize across many tasks and domains; "large-scale foundation models."
- Geometric cues: Spatial signals (points, boxes, masks) used to guide segmentation; "methods reliant on geometric cues."
- Geometric prompts: Explicit spatial inputs that indicate the target region to segment; "primarily rely on geometric prompts."
- Histopathology: Microscopic examination of tissue to study disease, used as an imaging modality; "histopathology, nuclear imaging, infrared, endoscopy, and CT."
- Infrared reflectance imaging (IR): An imaging modality capturing tissue reflectance in the infrared spectrum; "infrared reflectance (IR) images."
- Iterative refinement: Repeated improvement of segmentation through feedback and multi-step reasoning; "iterative refinement."
- Largest connected component: The biggest contiguous region in a mask used as a reliable spatial reference; "bounding box enclosing the largest connected component of the target."
- LLMs: Text-based models capable of reasoning and planning over instructions; "LLMs."
- Multimodal LLMs (MLLMs): LLMs that process and integrate multiple modalities (e.g., text and images); "Multimodal LLMs (MLLMs)."
- Nuclei: Cell cores targeted in biomedical segmentation tasks; "segmented nuclei images."
- OCT (Optical Coherence Tomography): A high-resolution retinal imaging modality; "Glaucoma OCT Analysis and Layer Segmentation (GOALS)."
- Open-vocabulary conceptual prompts: Text descriptions not limited to a predefined label set; "open-vocabulary conceptual prompts."
- Optic cup: A depression in the optic disc region, relevant to glaucoma analysis; "optic cup."
- Optic disc: The retinal area where the optic nerve exits, a key anatomical landmark; "optic disc."
- Perception Encoder (PE): A shared backbone that aligns vision-language inputs for detector and tracker; "Perception Encoder (PE) backbone."
- Promptable Concept Segmentation (PCS): Segmentation driven by semantic text prompts rather than just geometry; "Promptable Concept Segmentation (PCS)."
- Promptable Visual Segmentation (PVS): Segmentation guided by visual prompts such as points, boxes, or masks; "Promptable Visual Segmentation (PVS)."
- Reasoning Segmentation: A paradigm where the model interprets implicit, high-level queries before segmenting; "Reasoning Segmentation."
- Retinal nerve fiber layer (RNFL): A retinal layer often segmented in ophthalmic imaging; "retinal nerve fiber layer, ganglion cell layer, and choroid layer."
- Self-attention: Transformer mechanism for relating elements within the same feature set; "self-attention and cross-attention mechanisms."
- Semantic conceptual labels: Text labels describing medical concepts used to align segmentation with clinical meaning; "semantic conceptual labels."
- Streaming memory bank: A dynamic feature store enabling temporal conditioning across video frames; "streaming memory bank."
- Temporal consistency: Stability of segmentation across time or frames in video/3D data; "temporal or spatial consistency."
- Vision Transformers: Transformer-based architectures applied to image understanding; "Vision Transformers."
- Vision-LLM (VLM): Models that jointly process visual and textual inputs for tasks like segmentation; "medical vision-LLM (VLM)."
- Visual exemplars: Example images used to specify a target concept for segmentation; "visual exemplars."
- Volumetric data (3D): Three-dimensional imaging data requiring volume-wise segmentation; "3D volumetric data."
- Working memory: An agent’s internal state for tracking context and refining outputs iteratively; "maintaining a working memory."
- Zero-shot generalization: Performance on unseen tasks without task-specific training; "zero-shot generalization."
Practical Applications
Immediate Applications
Below are deployable use cases that can be implemented with the current MedSAM-3 and MedSAM-3 Agent capabilities (especially text+bounding box prompting and agent-in-the-loop refinement), along with sectors, potential tools/workflows, and feasibility notes.
- Healthcare (Radiology, Ophthalmology, Dermatology, Gastroenterology): concept-driven, semi-automated segmentation within existing PACS/viewers
- Use cases: “segment breast tumor,” “segment optic cup/disc,” “segment skin lesion,” “segment colon polyp,” “segment lung infection.”
- Tools/workflows: PACS plugin or desktop viewer extension that accepts short noun phrases + optional bounding boxes; measurement and volume extraction; snapshot-to-report workflow.
- Assumptions/dependencies: best performance with short phrases and box guidance; image modality and acquisition quality must be close to fine-tuned data; human-in-the-loop verification is required.
- Clinical annotation acceleration and dataset curation
- Use cases: pre-labeling for new studies across BUSI, RIM-ONE (Cup/Disc), ISIC 2018, Kvasir-SEG; rapid GT creation for small-to-medium 2D datasets; triaging frames in endoscopy videos (PolypGen).
- Tools/workflows: “MedSAM-3 Label-Assist” for CVAT/Label Studio; batch inference with manual refine; prompt libraries per dataset; export masks to standard formats.
- Assumptions/dependencies: annotator oversight; concept vocabulary harmonization to avoid synonym drift; consistent bounding box guidance improves quality.
- Clinical trial imaging endpoints (oncology, stroke)
- Use cases: standardized segmentation for lesion burden, response assessment, and biomarkers (e.g., skin lesion area, polyp counts).
- Tools/workflows: trial imaging core lab pipeline where MedSAM-3 generates draft masks; QC via MedSAM-3 Agent with iterative review; audit logs for traceability.
- Assumptions/dependencies: protocol-specific concept phrase lists; inter-site variability; regulatory compliance for trial data handling.
- Imaging QA and safety checks via agent-in-the-loop
- Use cases: the MedSAM-3 Agent flags suspect masks, proposes re-prompts, and requests additional bounding boxes; escalates uncertain cases to clinicians.
- Tools/workflows: QA dashboard; three-round refinement loop (as demonstrated with Gemini 3 Pro); uncertainty scoring and case routing.
- Assumptions/dependencies: MLLM reliability and institutional permissions; transparent logs for audit; guardrails to prevent overconfident outputs.
- Medical education and training
- Use cases: interactive learning where students type “RNFL,” “optic cup,” “polyp,” “nucleus/cell” to visualize structures; compare outputs across modalities.
- Tools/workflows: training viewer with prompt suggestions; challenge sets and immediate feedback; embed into residency curricula.
- Assumptions/dependencies: curated prompt dictionaries; misalignment across near-synonyms (e.g., “nuclei” vs “cell”) should be highlighted as teachable moments.
- Telemedicine triage (pre-diagnostic screening)
- Use cases: remote review support for ultrasound and endoscopy frames to prioritize cases with suspicious segments (e.g., polyps, masses).
- Tools/workflows: cloud inference pipeline; clinician dashboard for triage queues; patient privacy-preserving data transfer.
- Assumptions/dependencies: not a standalone diagnostic; variable image quality; local regulations on AI-assisted triage.
- Academic research reproducibility and benchmarking
- Use cases: rapid prototyping of concept-guided segmentation experiments across diverse modalities; stress-testing text prompts; documenting failure patterns (e.g., “liver” → lungs misalignment in raw SAM 3).
- Tools/workflows: open code/model release; standardized prompt libraries per dataset; benchmarking scripts with Dice/IoU and agent vs. non-agent comparisons.
- Assumptions/dependencies: consistent splits; transparent reporting of prompt phrasing; public access to datasets where permissible.
- Software and ML tooling
- Use cases: SDK/API for concept prompts + box inputs; batch inference services in clinical IT; integration with MLLMs for multi-step segmentation.
- Tools/workflows: “MedSAM-3 SDK,” “MedSAM-3 Agent Console,” deployment on on-prem GPUs; prompt ontology manager.
- Assumptions/dependencies: GPU availability; secure integration with hospital networks; maintenance of concept vocabularies and versioning.
Long-Term Applications
Below are strategic use cases that require further research, scaling, regulatory approval, or expanded datasets (especially true volumetric 3D support and robust text-concept grounding).
- Healthcare (Radiation therapy planning, surgical navigation, neuroradiology): concept-driven 3D volumetric segmentation
- Use cases: “segment liver and liver tumor,” “segment pulmonary arteries,” “segment ischemic stroke lesions” in full volumetric CT/MRI for planning and navigation.
- Tools/workflows: true 3D detectors/trackers beyond frame-sequenced 2D; integration with treatment planning systems; spatial consistency checks via agent memory.
- Assumptions/dependencies: improved volumetric modeling; large-scale, high-quality 3D concept-labeled datasets; clinical validation and regulatory clearance.
- Fully agentic radiology assistant
- Use cases: end-to-end orchestration—interprets clinical instructions, selects concepts, performs iterative segmentation, computes measurements, drafts report sections, and tracks longitudinal changes.
- Tools/workflows: RIS/PACS integration; agent memory for follow-up comparisons; structured reporting templates with auto-filled quantitative fields.
- Assumptions/dependencies: robust multimodal reasoning; safety guardrails; liability and credentialing frameworks; human supervision.
- Cross-institutional semantic search in imaging archives
- Use cases: concept-based search (e.g., “enlarged lymph nodes,” “peritumoral edema”) to support epidemiology, cohort discovery, and retrospective studies.
- Tools/workflows: segmentation-indexed archives; privacy-preserving federated search; harmonized ontologies across sites.
- Assumptions/dependencies: standardized concept dictionaries; de-identification; governance for cross-site data sharing.
- Real-time intra-procedural guidance (ultrasound, endoscopy, laparoscopy)
- Use cases: on-device inference to highlight organs, vessels, and lesions in real time; assist trainees; warning prompts for instrument proximity.
- Tools/workflows: optimized edge inference on carts/scopes; robust temporal tracking; integration with visualization hardware.
- Assumptions/dependencies: low-latency models; power and compute constraints; device vendor partnerships; clinical safety studies.
- Surgical robotics and smart instrumentation
- Use cases: concept prompts like “inferior vena cava,” “ureter,” “tumor margins” to guide robotic assistance and automated safety checks.
- Tools/workflows: ROS-compatible segmentation modules; fail-safe human override; multimodal fusion (imaging + kinematics).
- Assumptions/dependencies: extremely high reliability; certification for safety-critical use; domain-specific fine-tuning per procedure.
- Automated registries and public health surveillance
- Use cases: aggregate segmentation-derived biomarkers (e.g., organ volumes, lesion counts) to monitor disease prevalence and outcomes.
- Tools/workflows: pipeline for standardized extraction and aggregation; dashboards for health authorities; bias and equity audits.
- Assumptions/dependencies: population-level validation; robust data governance; transparent methodologies to avoid systemic bias.
- Patient-facing monitoring (daily life)
- Use cases: consumer apps for mole/skin lesion tracking (trend analysis, not diagnosis); visual explanations to encourage timely clinical visits.
- Tools/workflows: mobile capture guidance; periodic segmentation and change detection; referral triggers.
- Assumptions/dependencies: domain shift from dermoscopy to smartphone photos; clear disclaimers; privacy-preserving local inference; regulatory constraints on medical claims.
- Multimodal clinical decision support
- Use cases: fuse EHR text, labs, and imaging prompts—agent selects relevant concepts to segment and surfaces quantitative evidence for decisions (e.g., edema extent, organ enlargement).
- Tools/workflows: EHR-integrated agents; concept-driven segmentation tied to guideline-based rules; longitudinal tracking.
- Assumptions/dependencies: reliable text-image grounding; interoperability (HL7/FHIR); rigorous clinical validation; fairness across demographics.
Cross-cutting assumptions and dependencies
- Short, unambiguous medical noun phrases and prompt libraries significantly impact performance; synonyms and fine-grained terms may cause misalignment without domain adaptation.
- Bounding box guidance consistently boosts reliability; text-only prompting remains limited for many medical tasks.
- Robustness depends on modality/domain match to fine-tuning data; out-of-distribution cases require additional adaptation.
- Agentic gains rely on high-quality base segmentation; MLLM governance, auditability, and human oversight are essential.
- Compute and integration constraints (GPU availability, on-prem deployment, secure networking) must be addressed.
- Regulatory and ethical considerations (privacy, bias, safety) are prerequisites for clinical deployment and population-level use.
Collections
Sign up for free to add this paper to one or more collections.

