- The paper introduces multi-strategy modeling that allows a single support utterance to incorporate multiple support strategies, addressing limitations of single-strategy approaches.
- It details two generation paradigms—All-in-One and One-by-One—augmented with cognitive reasoning and reinforcement learning to refine strategy accuracy and structural coherence.
- Experimental results demonstrate superior performance in emotional relief, dialogue efficiency, and human-perceived support quality compared to conventional methods.
Modeling Multi-Strategy Support in Emotional Support Conversations
Emotional Support Conversation (ESC) systems are designed to provide empathy, validation, and actionable guidance to individuals in distress, typically by modeling dialogues between a supporter and a seeker. Current ESC modeling paradigms, particularly those built on the ESConv dataset, have imposed a simplifying assumption: each supporter utterance corresponds to a single support strategy (e.g., Affirmation, Providing Suggestions). However, empirical analysis of the ESConv dataset demonstrates that 17.7% of supporter utterances naturally integrate two or more distinct support strategies, underlining the limitation of this assumption and motivating a reformulation of the task.
This work proposes to model multi-strategy utterances, allowing a single supporter turn to comprise multiple, coherently sequenced strategy-response pairs. An example from ESConv illustrates the typical qualitative structure observed—supporters may combine Self-disclosure, followed by Affirmation, with supplementary Question-type elements in a single utterance.
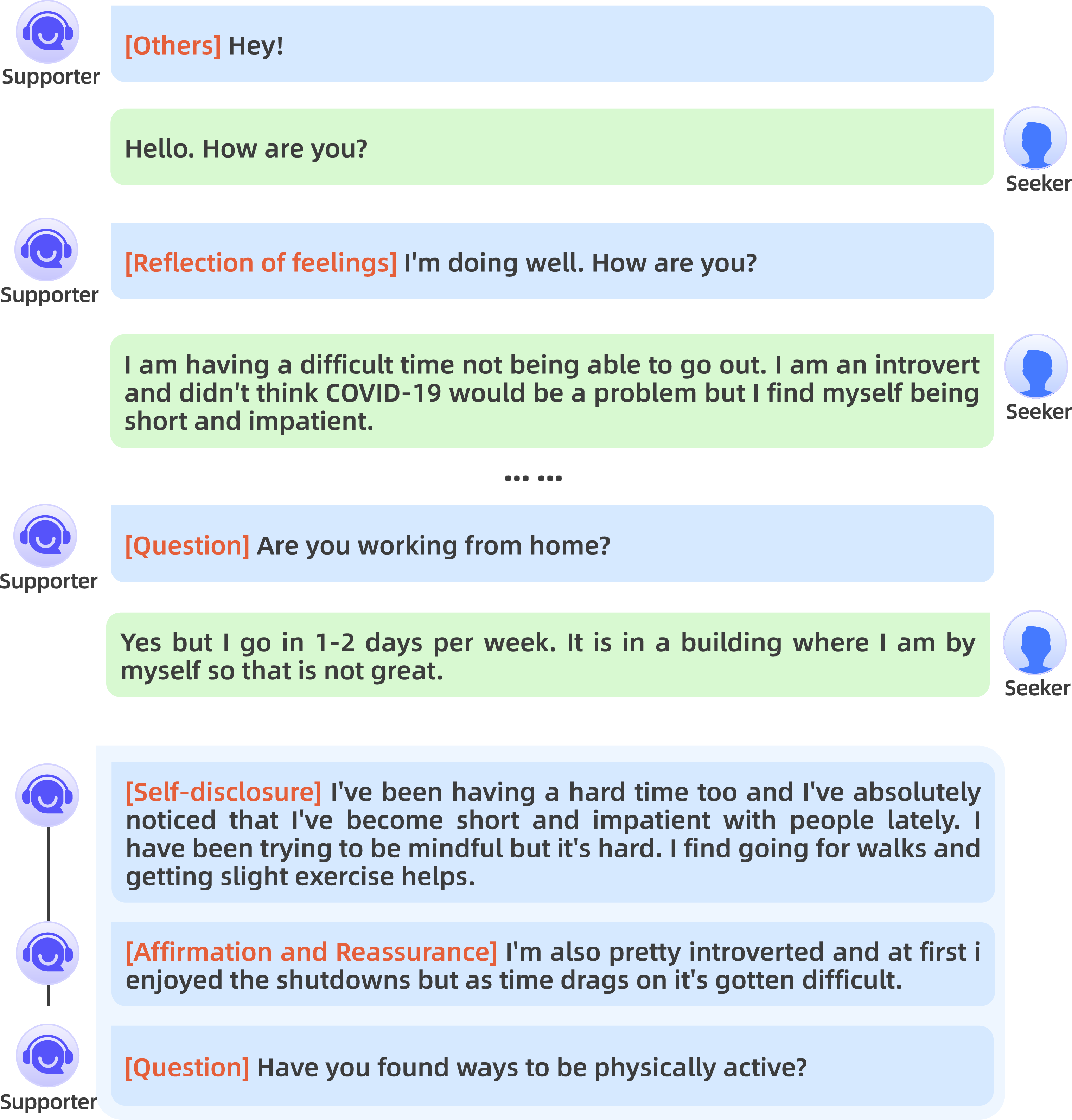
Figure 1: Example from ESConv illustrating a supporter using multiple strategies within a single utterance.
Proposed Methods
Two generation paradigms are introduced for multi-strategy utterance modeling:
- All-in-One Method: This method predicts the complete set of strategy-response pairs in a single decoding pass, concatenating all strategies and their associated responses into a single structured output sequence.
- One-by-One Method: Here, generation is an iterative process, predicting one strategy-response pair at each step, accompanied by a binary termination indicator specifying whether generation should continue. Iteration halts once either a completion signal is produced or a maximum number of strategies per utterance is reached.
Both paradigms are further augmented with cognitive reasoning mechanisms and reinforcement learning to enhance strategy deliberation, response quality, and structural precision in multi-strategy outputs.
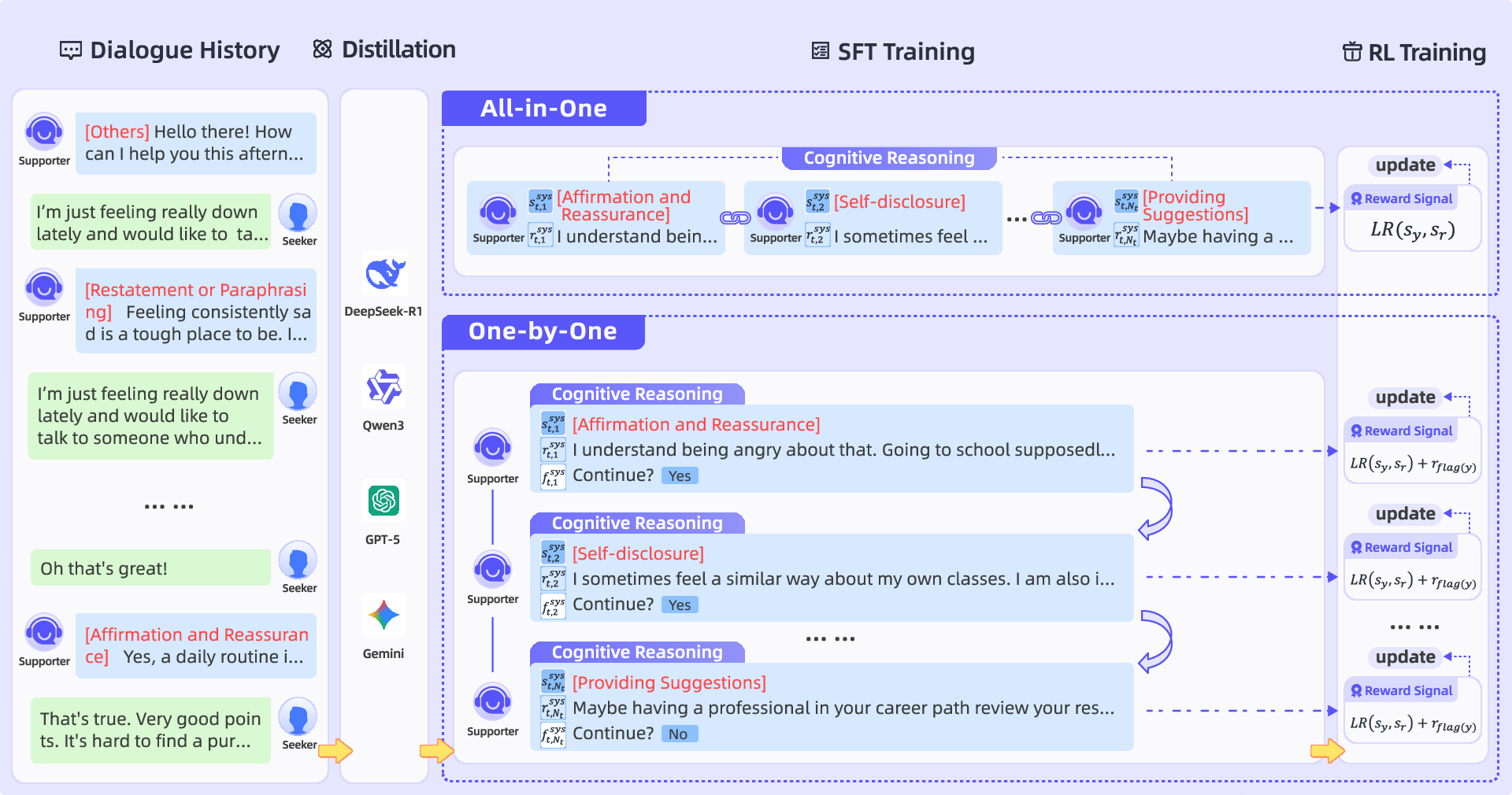
Figure 2: Illustration of the All-in-One and One-by-One methods for generating multi-strategy supportive utterances.
Cognitive Reasoning and Distillation
Structured cognitive reasoning is incorporated as a chain of four interpretable nodes—Context, Cognition, Emotion, Support Plan—prior to response generation. Reasoning supervision is distilled from a set of strong LLMs (DeepSeek-R1, Qwen3-235B-Instruct, GPT-5, Gemini-2.5-Flash), with the aggregation of diverse teacher outputs shown to enhance generalization and robustness of the student model.
Reinforcement Learning
Policy optimization adopts Group Relative Policy Optimization (GRPO), with custom reward functions guided by:
- Structural validity (format reward)
- Accuracy of the predicted sequence of strategies (measured by Levenshtein Ratio [LR])
- Correct flagging of utterance completion (for One-by-One)
Rewards are adjusted to balance class imbalance (multi-strategy vs. single-strategy) and promote both strategy accuracy and structural completeness.
Experimental Results
Utterance-Level Evaluation
Evaluation is conducted on the ESConv test set, using standard text generation metrics (BLEU, ROUGE, BERTScore) and two specific metrics for strategy prediction: EMR (Exact Match Rate) and LR (Levenshtein Ratio). The All-in-One and One-by-One models, both with and without cognitive reasoning and reinforcement learning, are benchmarked against single-strategy baselines and several strong instruction-following LLMs.
Key findings:
- The One-by-One method with cognitive reasoning and RL achieves the best overall performance across metrics, surpassing both All-in-One and the Single-Strategy baseline, especially in EMR and LR, indicating superior multi-strategy modeling capability.
- Augmenting with cognitive reasoning consistently yields strong improvements, and distillation from multiple teacher LLMs further enhances all evaluated objectives.
- Reinforcement learning robustly improves strategy modeling; its impact is pronounced in multi-strategy utterances, while surface-level metrics (BLEU) may be less sensitive.
Notably, both multi-strategy methods demonstrate significant gains on multi-strategy utterances, where the Single-Strategy baseline fails entirely (e.g., EMR near 0%). The addition of cognitive chains and RL substantially closes the performance gap between model output and human multi-strategy annotation rates.
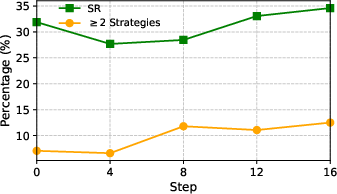
Dialogue-Level Evaluation
A self-play evaluation protocol with GPT-5 simulating the seeker and acting as a reward model assesses dialog success (Success Rate, SR), dialog efficiency (Average Turn, AT), and strategy diversity (Average Strategy, AS).
Human Evaluation
Human annotators rank generated dialogues along Identification, Comforting, Suggestion, and Overall dimensions. Multi-strategy models consistently receive superior average ranks, indicating that combinations of strategies in a single utterance improve perceived support quality, empathy, and practical utility.
Analysis and Implications
- Strategy Coverage: Despite modeling improvements, the absolute proportion of generated utterances with multiple strategies remains lower than in human references, suggesting further potential in balancing between one- and multi-strategy output distributions.
- Modeling Complexity: While multi-strategy modeling increases complexity (potential for noise in single-strategy cases), cognitive chains and RL demonstrably mitigate this, supporting robust generalization.
- Reasoning Distillation: No single teacher LLM's reasoning dominates; aggregating teacher signals attains the best performance, indicating the complementary strengths of LLM ensembles for cognitive supervision.
Practically, this work provides evidence supporting the adoption of multi-strategy modeling in ESC systems, aligning model behavior with human supportive conversational patterns. Such advances improve both the naturalness and efficacy of machine-mediated emotional support.
Future Directions
Areas for future exploration include:
- Addressing data imbalance to further encourage multi-strategy generation.
- Integrating richer simulation environments or real-world deployment to validate efficacy beyond ESConv-style settings.
- Expanding evaluation to cover more nuanced and longitudinal aspects of emotional relief, as well as safety and alignment in clinical or high-stakes applications.
Conclusion
Modeling emotional support as a multi-strategy utterance generation task more accurately reflects the dynamics of real-world supportive communication. Both All-in-One and One-by-One paradigms, when augmented with structured cognitive reasoning and reinforcement learning, demonstrate strong empirical improvements at both utterance and dialogue levels, substantiating the practical feasibility and benefit of multi-strategy ESC modeling. These findings motivate further investigation into flexible, context-sensitive strategy composition for next-generation conversational support agents.