- The paper proposes a novel architecture that integrates object-aware temporal foresight within a unified semantic latent space to enhance anticipatory robotic control.
- It employs a Diffusion Transformer with autoregressive flow matching in the DINOv2 feature space, achieving a 96.6% success rate on the LIBERO benchmark.
- Hierarchical unsupervised clustering generates object-centric prototypes that significantly improve robustness and adaptability under scene dynamics and distribution shifts.
Object-Aware Temporal Flow Matching for Robust Robotic Manipulation: An Expert Analysis of OFlow
Introduction
"OFlow: Injecting Object-Aware Temporal Flow Matching for Robust Robotic Manipulation" (2604.17876) introduces a principled architectural enhancement to vision-language-action (VLA) policies by integrating object-aware temporal foresight within a unified semantic latent space. The framework addresses two chronic deficiencies in state-of-the-art VLAs for embodied control: (i) reactive policies that lack anticipation of future scene states, and (ii) disjoint pipelines for object reasoning and temporal prediction. The manuscript proposes an architecture that jointly predicts temporally coherent, object-centric semantic latents, enabling action policies to generalize robustly under dynamic scene evolution and visual/physical perturbations.
Unified Semantic Foresight with Object-Centric Factorization
OFlow mediates multimodal perception using a vision-LLM (Eagle-2.5) and couples it with a semantic foresight module that operates in the DINOv2 feature space. The method predicts trajectories of semantic latents using an autoregressive flow matching transformer, thus preserving temporal causality and intra-frame spatial coherence beyond what token-level autoregressive models can achieve.
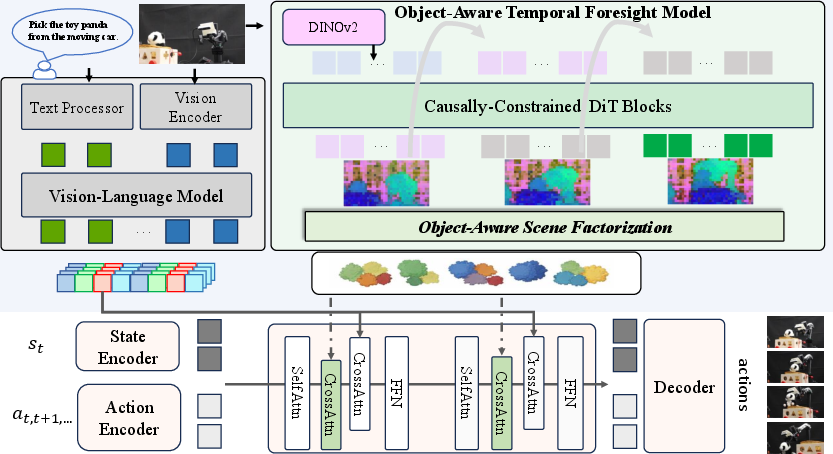
Figure 1: The OFlow framework unifies multimodal perception, object-aware foresight, and robust action generation in a shared pipeline.
A core novelty is the hierarchical factorization of scene-level features into a set of object-centric prototypes using unsupervised clustering, directly leveraging the emergent structure of DINOv2 representations. This yields multi-granular, semantically structured tokens that function as inductive biases for subsequent planning and control, obviating the need for segmentation supervision or region proposals.
Autoregressive Flow Matching in DINOv2 Latent Space
For temporal prediction, OFlow eschews pixel-space generation and instead operates on high-level feature trajectories:
- Causal Transformer Design: The foresight module employs a Diffusion Transformer (DiT) backbone with causal inter-frame and dense intra-frame attention to enforce temporal causality and maintain spatial awareness (Figure 2).
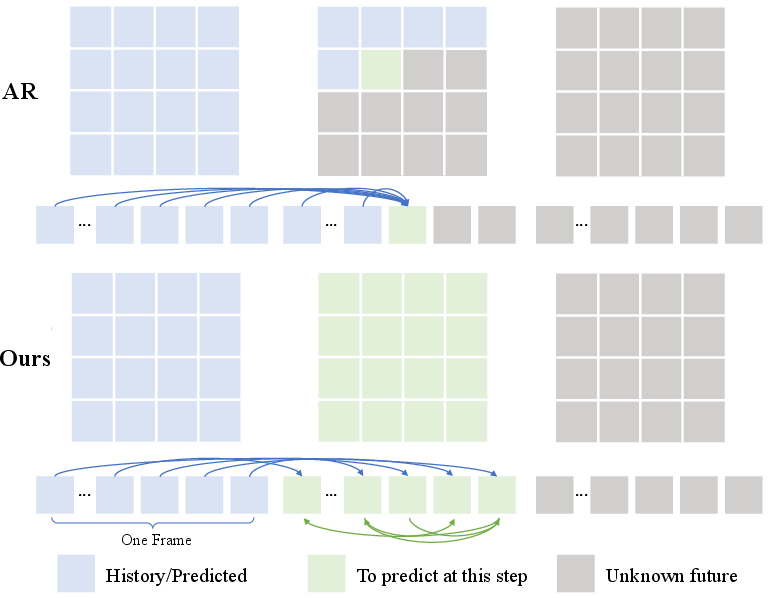
Figure 2: Frame-level autoregressive flow matching enables conditioning on both past frames and spatial structure, in contrast to conventional token-level models.
- Flow Matching Objective: At each autoregressive step, the module optimizes a flow-matching loss, iteratively generating the trajectory of semantic latents over a fixed prediction horizon.
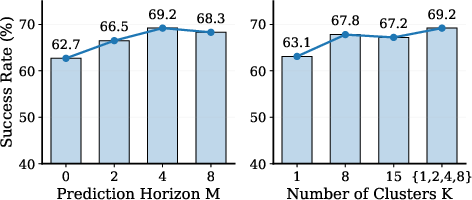
- Object-Aware Scene Factorization: Following feature synthesis, the K-means algorithm is applied hierarchically across a range of cluster counts (K=2,4,6,8,12), structuring future latents into semantically meaningful prototypes (Figure 3).

Figure 3: Visualization of object-aware semantic decomposition; each color corresponds to a discovered prototype across hierarchical granularities, reflecting emergent scene structure.
This results in action-relevant scene summaries that are robust to spurious pixel variations and viewpoint changes.
Integration with Visuomotor Policy Generation
For control, these multi-scale object-aware futures modulate a chunked continuous action policy via cross-attention. The policy backbone is again a DiT, with a ControlNet-style injection enabling seamless conditioning on both vision-language and object-centric semantic cues. Zero-initialized projections ensure compatibility with frozen pretrained backbone weights and facilitate efficient downstream finetuning.
Experimental Validation
Comprehensive simulation and hardware experiments corroborate the efficacy of OFlow against modern VLA baselines. Key experimental results include:
- Quantitative Success: OFlow delivers a 96.6% overall success rate on the LIBERO benchmark, outperforming state-of-the-art baselines including GR00T-N1.5 and π0 (Table 1 in the paper). Particularly, the 94.5% success on LIBERO-Long demonstrates competitive long-horizon temporal reasoning.
- Robustness to Distribution Shift: On LIBERO-Plus, OFlow achieves 72.3% average success, with absolute improvements of +4.2% to +5.9% over GR00T-N1.5 across various perturbation classes (Figure 4), including camera, object layout, and sensor noise.
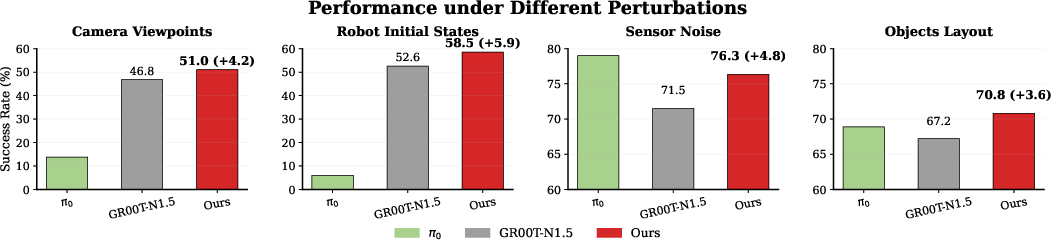
Figure 4: OFlow consistently outperforms strong baselines under multiple representative environmental perturbations, quantifying its enhanced robustness.
- Scene Compositionality and Temporal Coherence: Qualitative prediction trajectories (Figure 5) confirm that the foresight module produces temporally smooth and semantically decodable representations that align with ground truth scene evolution, as evidenced by both PCA projections and RAE-based reconstructions.
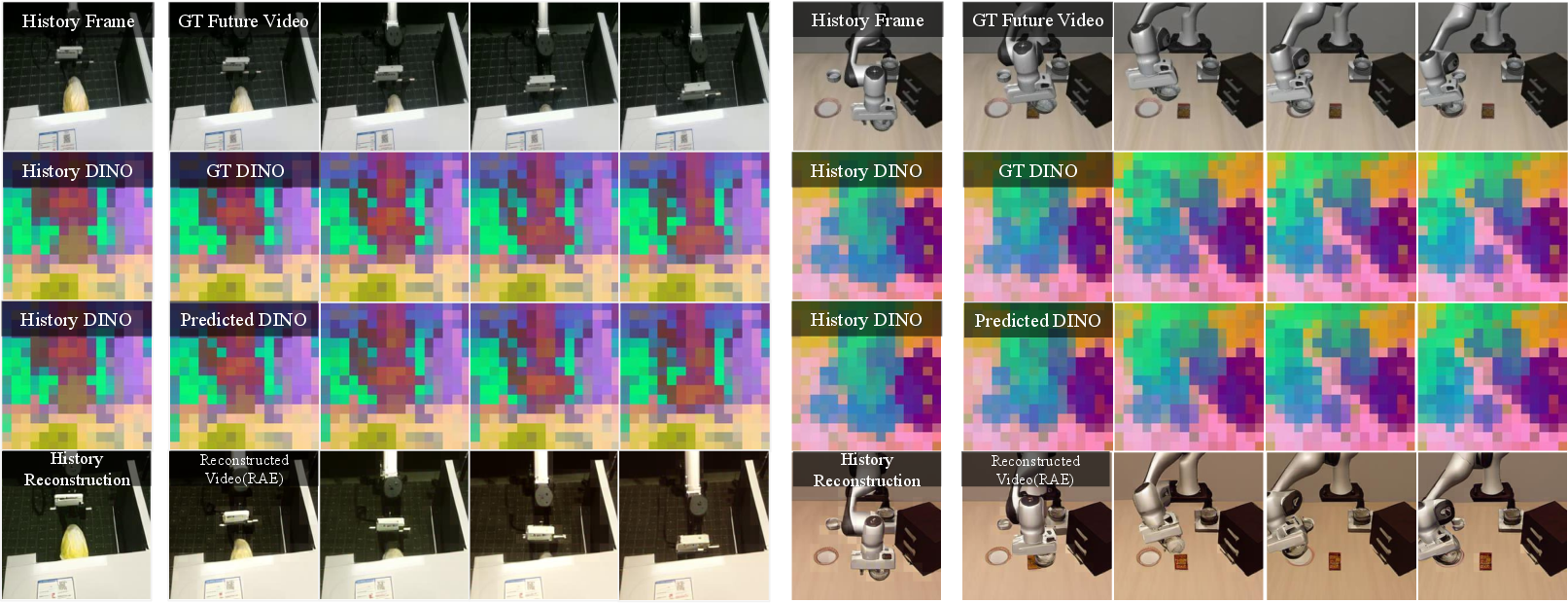
Figure 5: Predicted DINOv2 features and reconstructed frames are temporally aligned with ground truth, indicating faithful semantic prediction rather than brittle pixel-level imitation.
- Physical Benchmarks: On SimplerEnv and MetaWorld MT50, OFlow consistently surpasses strong tokenization (FAST, GR00T-N1.5) and generative foresight (TriVLA, DreamVLA) baselines, especially on manipulation tasks that require extended temporal credit assignment and dynamic object tracking.
- Real-World Deployment: In real-world settings with dynamic objects, deformable manipulation, and human-robot interaction, OFlow yields a +28% increase in average success rate over π0, underscoring the practical benefit of object-aware temporal modeling (Figures 7–13 further illustrate robust closed-loop execution across these scenarios).
Ablation Analyses
Critical ablations demonstrate that:
Theoretical and Practical Implications
The integration of temporal semantic foresight and object-aware decomposition into the control pipeline elevates the abstraction level at which embodied agents reason. By moving feature generation and action selection to the semantic prototype level, OFlow delivers policies that are robust, data efficient, and more interpretable. This architectural blueprint provides a bridge between recent advances in object-centric visual representations and generative modeling with practical robotic manipulation.
On the theoretical axis, OFlow supports the growing position that abstraction and compositionality—rather than pure data scaling or pixel-level prediction—are crucial for closing the gap between simulated and real-world robotic intelligence. Hierarchical prototypes and condensed semantic context facilitate efficient task transfer and robustness under compound perturbations.
Future Directions
Potential research extensions include:
- Adaptive online clustering and grounding for object-aware prototypes, further minimizing the annotation and human-in-the-loop requirements.
- Incorporation of multimodal sensory input (e.g., tactile, force, audio) to augment the temporal foresight module.
- End-to-end training regimes where both foresight and base VLMs are updated jointly, potentially leveraging cross-modal self-supervision.
Scaling OFlow's architectural principles to bimanual and multi-agent domains as well as integration with hierarchical RL paradigms presents additional avenues for theoretical deepening and empirical expansion.
Conclusion
OFlow demonstrates that robust, generalizable, and anticipatory robotic control policies can be realized by injecting object-aware temporal flow matching into vision-language-action architectures. Structured semantic foresight, underpinned by hierarchical object-centric features, yields robust manipulation strategies under diverse environmental dynamics, serving as a salient direction for the synthesis of expressive scene understanding and flexible embodied action (2604.17876).