- The paper introduces a two-stage framework combining an interaction-aware VAE with an autoregressive flow matching model to generate temporally coherent and physically plausible hand-object interactions.
- It achieves state-of-the-art results on GRAB, OakInk, and DexYCB, with high physical plausibility (up to 98.25%) and enhanced contact dynamics compared to previous methods.
- Its design, using latent decoupling and synthetic pre-training, enables robust generalization for both bimanual and single-hand manipulation tasks.
Generalizable Hand-Object Interaction Generation via Latent Flow Matching
Motivation and Problem Statement
The synthesis of realistic 3D hand-object interaction (HOI) motions is a central problem in computer vision and robotics, relevant for animation, VR, and dexterous manipulation. While advances have been made in static grasp pose generation, the temporal, dynamic aspect of HOI generation has remained under-explored due to challenges such as maintaining physical plausibility, temporal coherence, and generalization across unseen actions and objects. Prior generative approaches—diffusion-based or auto-regressive models—either suffered from computational inefficiency or lacked contact-rich, temporally consistent representations, often producing artifacts like floating hands or implausible contacts.
Method: HO-Flow Framework
HO-Flow introduces a two-stage generative framework:
- Interaction-aware Variational Autoencoder (Inter-VAE): The Inter-VAE encodes sequences of hand and object motions into a unified latent manifold, leveraging kinematic-aware object transformation. Object point clouds are projected into local hand joint coordinate systems, capturing rich geometric interaction context essential for modeling contact dynamics. The spatial encoder (PointNet++-based) processes these features, followed by temporal encoding to obtain compact latents for both hand and object.
- Auto-regressive Flow Matching Model:
The generative component employs a masked, auto-regressive transformer to aggregate temporal context and conditionally predict motion latents in continuous space. Flow matching—rather than standard diffusion—provides an efficient, ODE-based generative process, enabling temporally coherent motion synthesis by mapping noise to target latents via learned velocity fields.
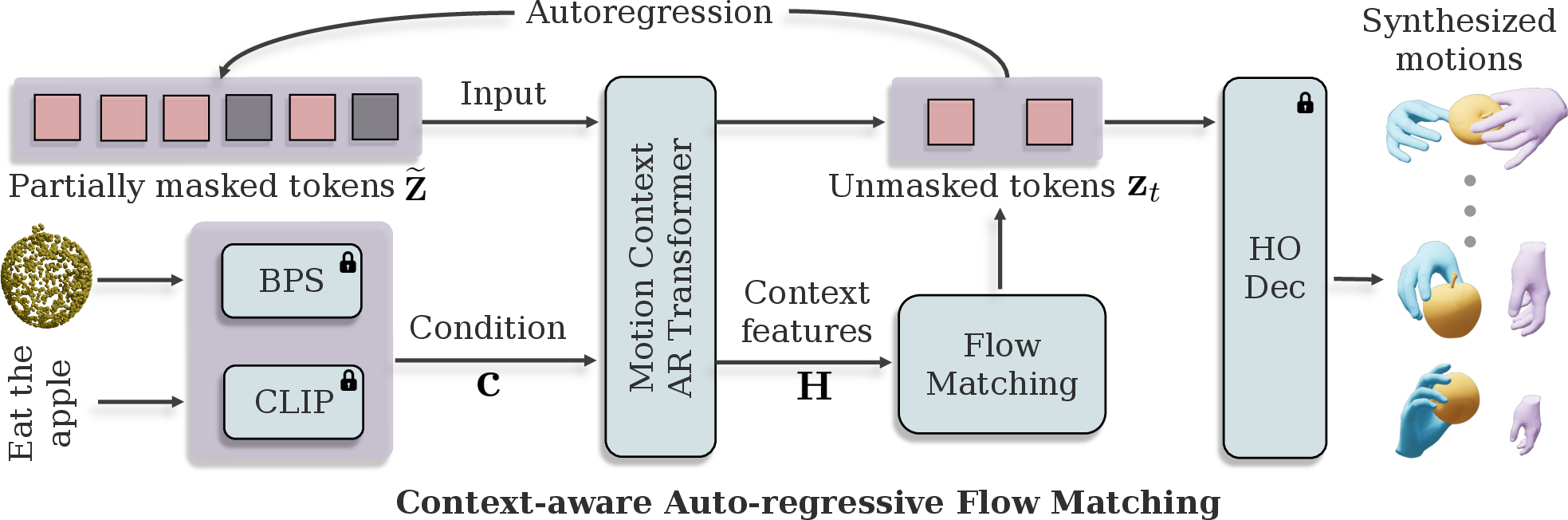
Figure 1: The flow matching model autoregressively predicts motion latents conditioned on object geometry and task description, reducing generative uncertainty and achieving high fidelity.
A critical architectural feature is the prediction of object motion relative to the initial frame, which decouples the model from dataset-specific coordinate conventions and facilitates large-scale pre-training on synthetic data (GraspXL), greatly enhancing generalization to unseen objects.
Empirical Evaluation and Numerical Results
Extensive benchmarking on GRAB, OakInk, and DexYCB datasets substantiates the claims. HO-Flow demonstrates state-of-the-art physical plausibility (Phy) and sample diversity (SD), outperforming LatentHOI, MDM, and other text- and diffusion-based approaches across all activities.
- On GRAB, HO-Flow achieves a Phy of 98.25% and SD of 0.31, surpassing LatentHOI's 96.16% Phy and 0.13 SD.
- On OakInk, HO-Flow generalizes to unseen objects, with Phy 89.76% and SD 0.33, and lowest interpenetration metrics.
- On DexYCB, HO-Flow reaches Phy 95.41% and SD 0.20 for single-hand manipulation, with improved contact ratios and reduced mesh penetrations.
Ablation studies confirm the efficacy of each architectural component:
- The interaction-aware VAE yields lower reconstruction errors.
- Flow matching consistently outperforms diffusion in HOI modeling.
Strong preference in qualitative user studies further reinforces the superior interaction realism and task alignment.

Figure 2: HO-Flow synthesizes realistic and diverse hand-object interactions for various tasks, outperforming prior methods.
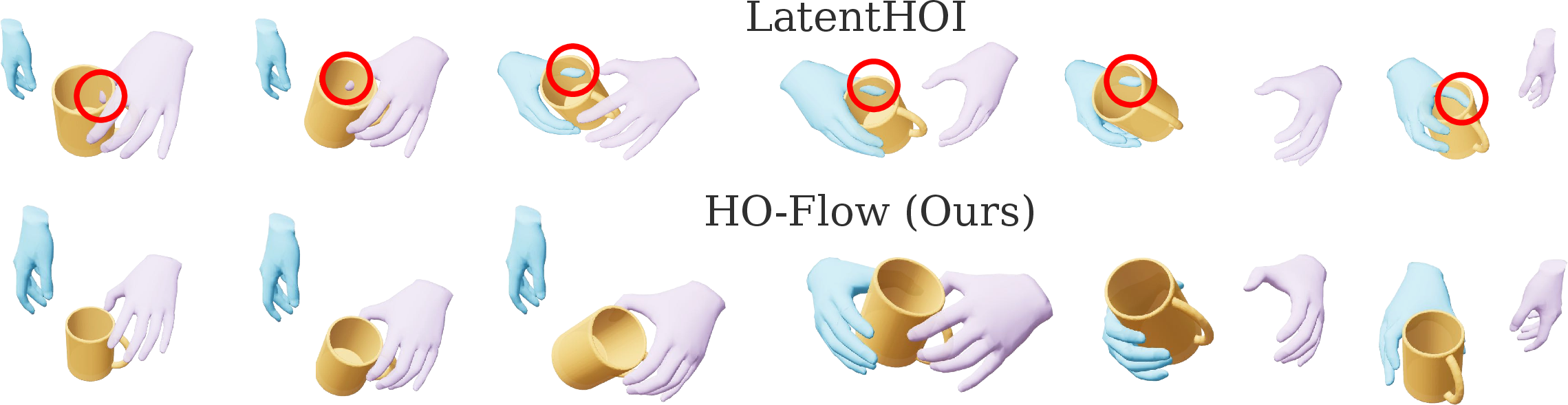
Figure 3: Qualitative comparison—HO-Flow produces more natural contacts and fewer penetrations than LatentHOI.
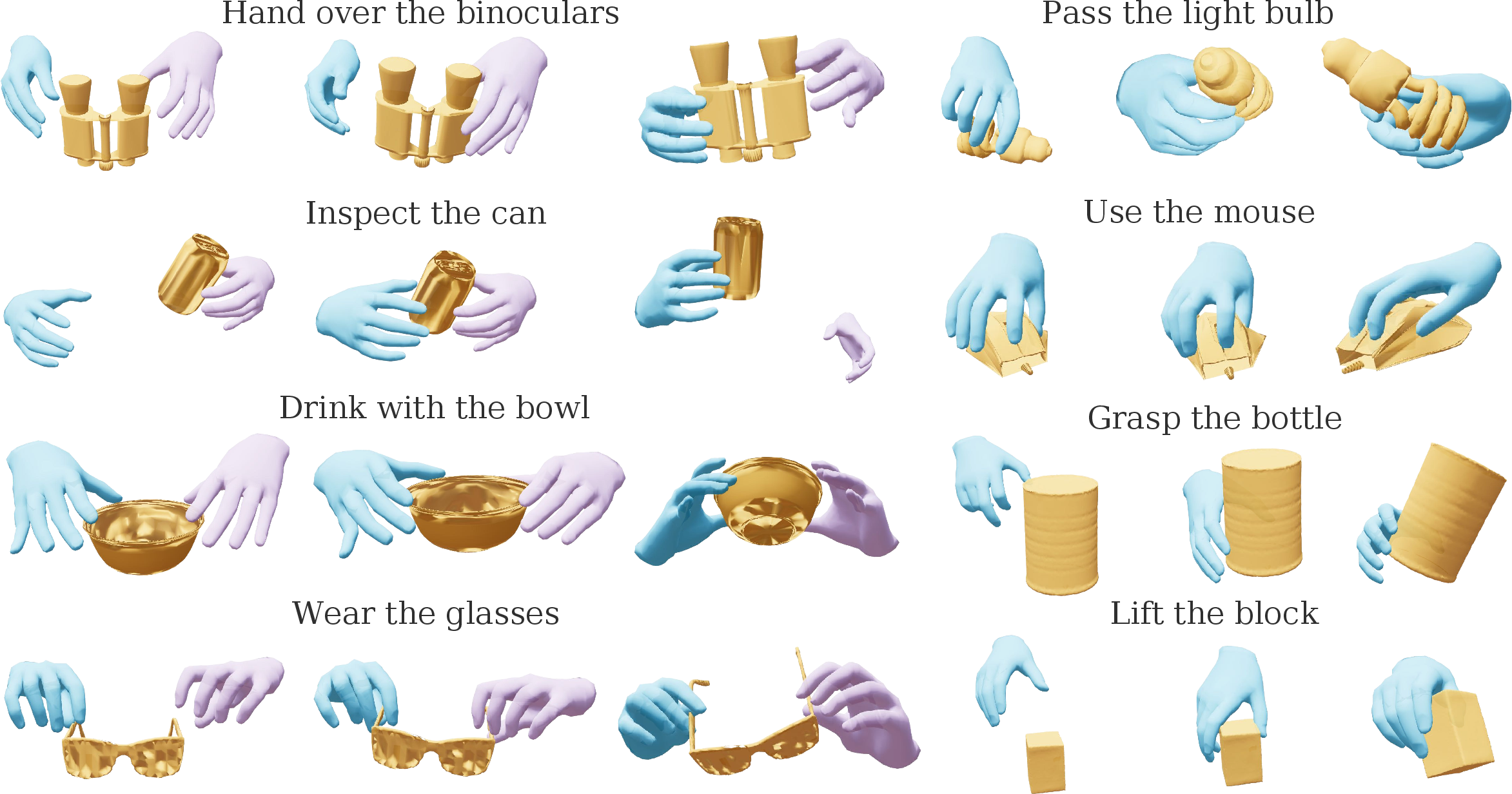
Figure 4: HO-Flow fidelity on OakInk and DexYCB—natural and physically plausible hand-object motion synthesis.
Implications and Limitations
HO-Flow's design addresses critical bottlenecks in HOI generation: robust temporal reasoning, contact-rich representation, and broad generalization enabled by hand-centric object encoding and synthetic data pre-training. Flow matching provides computational efficiency and high sample fidelity. The separation of hand and object latents, along with autoregressive temporal aggregation, enables coherent and plausible motion generation in both bimanual and single-hand domains.
Practically, HO-Flow opens avenues for controllable interaction modeling from text prompts, impacting VR, robotics, and digital content creation workflows. The framework's strong generalizability suggests that similar hand-centric latent encodings and flow-based generative paradigms may further benefit other articulated-object interaction domains.
From a theoretical perspective, this architecture demonstrates the advantages of unified, temporal latent spaces and continuous generation methods over frame-wise or discrete token-based approaches.
However, certain failure cases (see Figure 5)—e.g., misaligned semantic part grasping or incorrect object orientation—highlight limitations. These may be mitigated by scaling instruction diversity and leveraging enriched affordance cues.

Figure 6: Diverse cross-dataset HO-Flow generations—consistent hand-object motion realism.
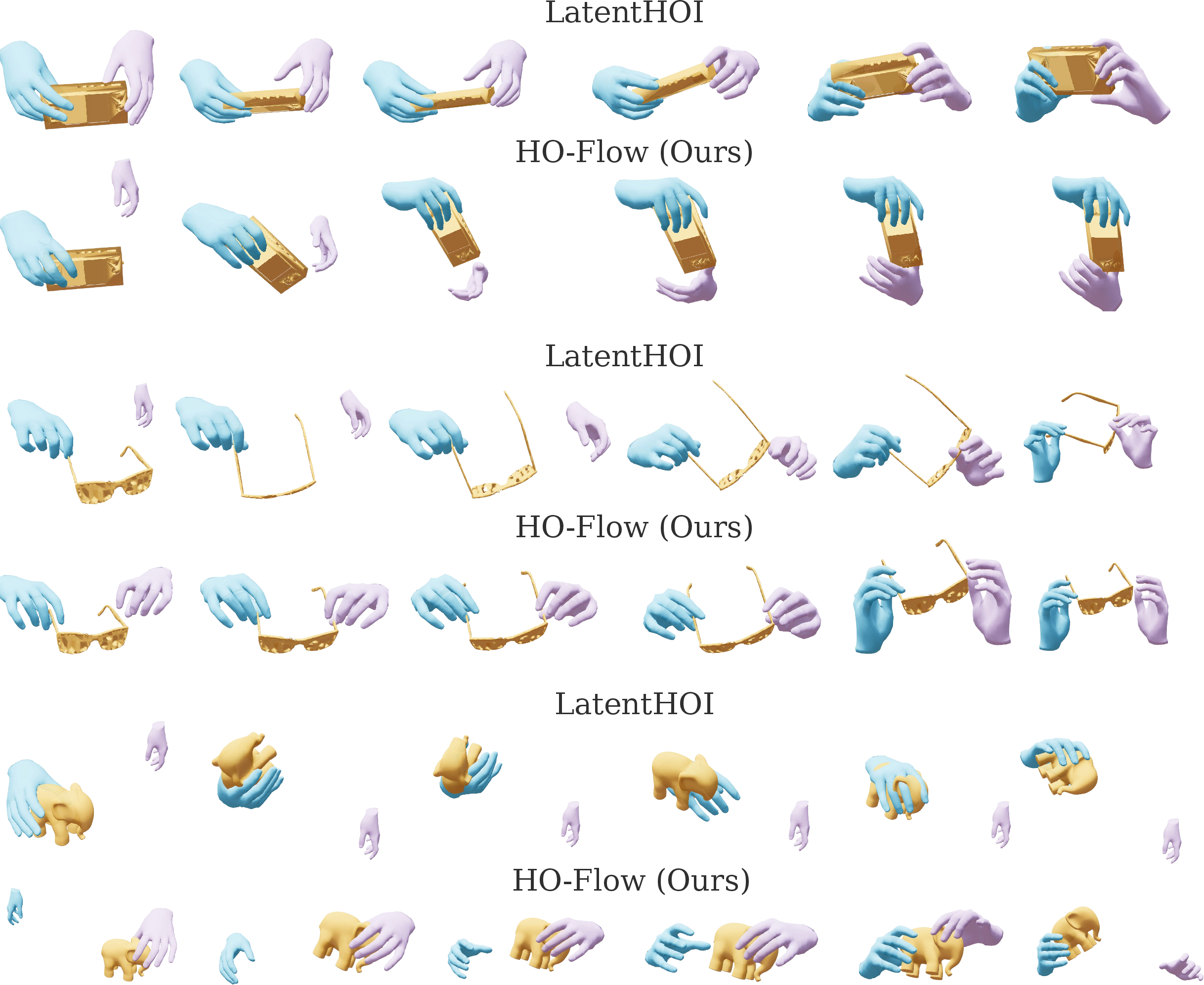
Figure 7: More qualitative comparisons underscoring reduced penetrations and superior contact modeling.

Figure 5: Failure modes—misaligned grasping or orientation underscore challenges in semantic generalization.
Conclusion
HO-Flow represents a technically rigorous advancement in hand-object interaction synthesis, combining interaction-aware temporal latents and flow matching for efficient, generalizable motion generation. Rigorous experiments demonstrate its superiority in physical plausibility, temporal consistency, and diversity over existing models. The flow-based approach, paired with large-scale synthetic pre-training, establishes a foundation for scalable, controllable HOI synthesis. Future research may focus on semantic generalization, affordance modeling, and extending the architecture to broader multi-agent or multi-object domains.

