- The paper presents a hybrid FHE/TEE approach that encrypts both data and codebooks to ensure holistic privacy in ANN search.
- It optimizes product quantization with four novel data packing techniques and a fast slot-summation algorithm to dramatically reduce FHE operations.
- Empirical results show high recall (over 0.9) and significant rotation savings, making the framework suitable for large-scale, privacy-critical applications.
Robust Hybrid FHE/TEE Product-Quantized Privacy-Preserving ANN Framework
Motivation and Security Landscape
The evolution of high-performing retrieval systems with LLMs and VLMs has intensified reliance on large-scale nearest neighbor search, where embedding vectors often encode semantically rich and sensitive information. Such vectors are susceptible to embedding inversion, membership inference, and attribute inference attacks, which can facilitate unauthorized reconstruction or leakage of original data (2604.17816). Traditional privacy-preserving ANN methods, using MPC, TEE, or FHE, cannot jointly optimize for cryptographic integrity, system performance, and scalability. TEEs are subject to hardware vulnerabilities and access pattern leakage [TEESurvey], FHE-only solutions are computationally prohibitive for large-scale search [SANNS], and prior solutions focus on the search phase rather than holistic privacy-preserving database generation.
This work introduces a Privacy-Preserving Product-Quantization Approximate Nearest Neighbor (PPPQ-ANN) search framework with system-wide multi-layered privacy guarantees. The proposed scheme leverages a hybrid of CKKS-based FHE and TEE environments to protect vector data throughout all phases—database generation, encoding, indexing, and search—without sacrificing practical throughput or recall.
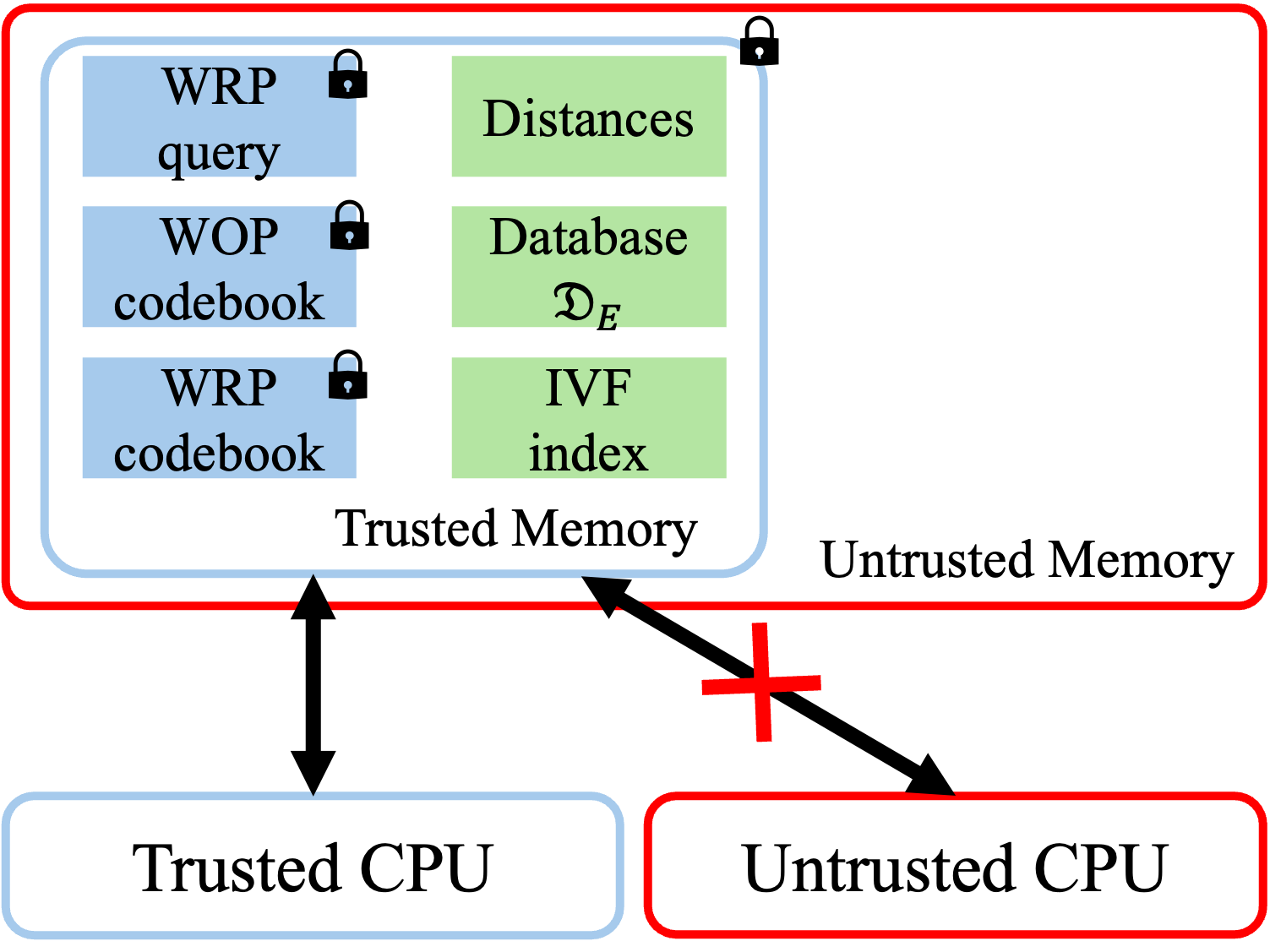
Figure 1: Server memory structure of PPPQ-ANN, demonstrating encrypted RAM (blue: CKKS ciphertext; green: plaintext) and layered FHE/TEE protection for codebooks, queries, and database.
System Architecture and Data Packing
PPPQ-ANN executes all operations inside TEEs, but for heightened privacy, the original database, codebooks, and queries themselves are encrypted with CKKS-based FHE even within TEE. The threat model is honest-but-curious, securing against most adversarial leakage paths.
The core innovation is optimized PQ-aware data packing for CKKS. Four packing modalities are developed: Subdimension-wise Order Packing (SDOP), Subdimension-wise Repeated Packing (SDRP), Whole Order Packing (WOP), and Whole Repeated Packing (WRP). These allow packing either data or codebooks into ciphertexts, enabling reduced network traffic and computational overhead. Packing is aligned to PQ subspaces; use of a large number of subspaces with small codebook size minimizes the number of computationally expensive ciphertext operations.
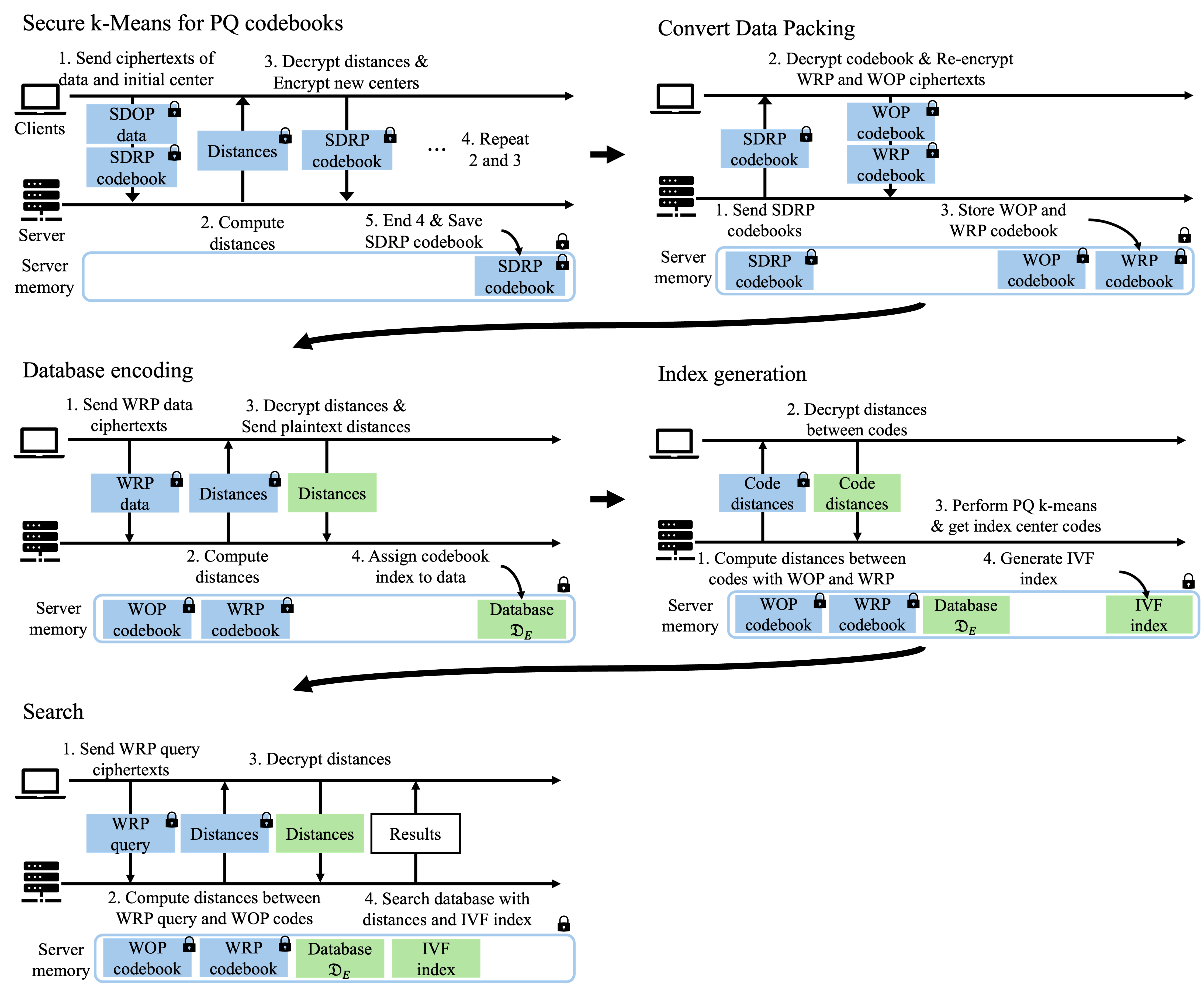
Figure 2: PPPQ-ANN processing flow, illustrating client-server communication and four principal operations: codebook generation, encoding, indexing, and search, all with encrypted memory.
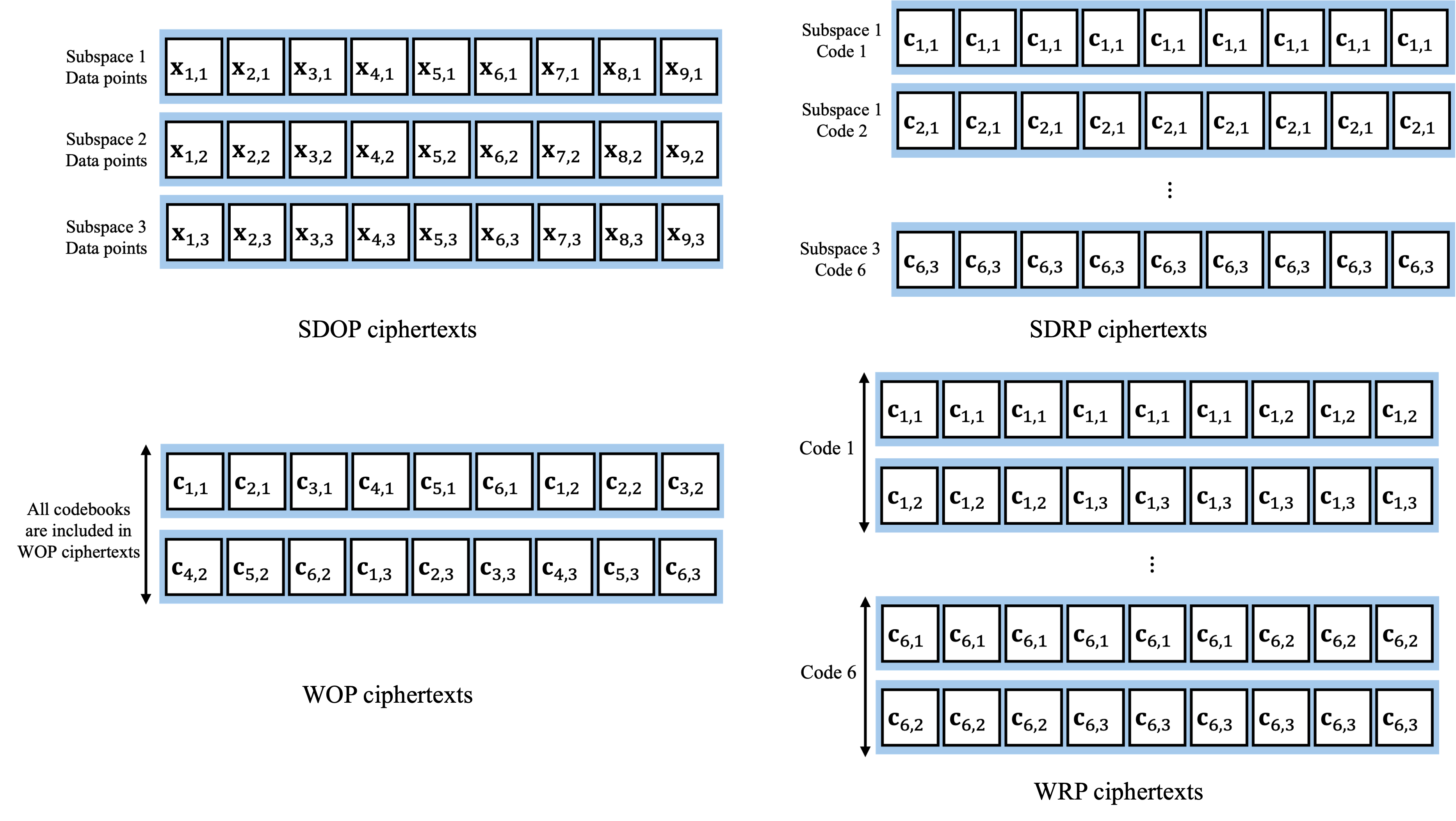
Figure 3: Examples of four data packing types. Packing efficiency dramatically reduces ciphertext counts in search and encoding.
Algorithmic Design and Accelerated Distance Computation
PPPQ-ANN proposes an improved slot-summation algorithm for distance computations between packed ciphertexts. Conventional algorithms, e.g., [SecurekMeans], require O(log2ds+ds−2⌊log2ds⌋) ciphertext rotations, inefficient for arbitrary subspace sizes. The new algorithm memorizes intermediate rotations to provide O(2log2ds) complexity, independent of powers of two. Empirically, this yields an order-of-magnitude reduction in FHE computation latency.
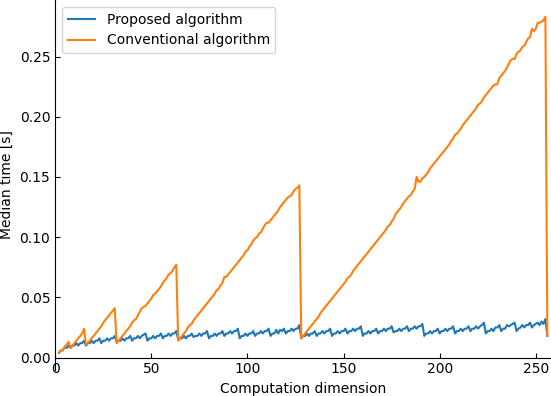
Figure 4: Performance comparison of CKKS-based Euclidean distance computation; the proposed algorithm increases only logarithmically with data dimension, outperforming conventional methods on Apple M2 Max.
Holistic Database Generation, Encoding, and Indexing
PPPQ-ANN systematically addresses database generation, not just search, for the privacy-preserving ANN pipeline:
- Codebook Generation: Secure (homomorphic) k-means with random sampling or k-MCMC initializes PQ codebooks, using SDOP/SDRP data packing and avoiding polynomial depth approximations that inflate ciphertext size and traffic.
- Database Encoding: WRP-packed data are matched to WOP-packed codebooks. Distances and assignments occur only between O(NWOP) pairs, dramatically minimizing ciphertext exchanges. Encoded databases retain only PQ code indexes; codebooks themselves are protected by CKKS.
- Database Indexing: Utilizes PQk-means for clustering encoded PQ codes, producing IVF structures with minimal FHE computation and low communication costs.
Search Protocol, Scalability, and Multi-Client Extensions
The search protocol computes distances between encrypted queries and codebooks, then retrieves candidates from the IVF structure using ADC. Both database encoding and search scale in parallel, requiring only the WOP codebook per client; Proxy Re-Encryption (PRE) is suggested for onboarding new clients without re-keying the server. Noise addition and ciphertext rotation strategies are advised to mitigate codebook leakage during query processing.
Computational Efficiency and Empirical Evaluation
PPPQ-ANN was evaluated on SIFT-1M, GIST-1M, and multiple GloVe dimensions, using CKKS/OpenFHE on multicore TEEs (AMD-SEV-SNP):
- Database Generation: Less than 2 hours for million-scale datasets.
- Query Throughput: Over 50 QPS in sequential search.
- Accuracy: Recall@10 consistently exceeded 0.9 across datasets.
- Packing Efficiency: Combinations with large ns (number of PQ subspaces) and small NC (codebook size) yielded dramatically lower server processing time, minimal FHE operations, and higher retrieval accuracy.
- Rotation Savings: The improved summation algorithm reduced the number of rotations from 42 to 8 for ds=100.
Security and Practical Implications
PPPQ-ANN realizes strong privacy for vector search and database generation, suitable for applications in medical and financial domains where multi-layered confidentiality is mandatory. The hybrid FHE/TEE structure, optimized data packing, and efficient summations together resolve the cryptographic-performance trade-off that has historically undermined practical adoption for ANN search at scale.
Potential threats, such as codebook leakage from client-side memorization, can be mediated by introducing noise and rotation. The framework does not, however, address access-pattern leakage during search; this remains an open challenge.
Theoretical Implications and Future Directions
PPPQ-ANN offers a template for combining cryptographic primitives and hardware security to construct scalable privacy-preserving machine learning systems. Its multi-layered defense model extends beyond ANN search and could be generalized to other retrieval, clustering, and inference tasks over confidential data. Future research should investigate formal modeling and mitigation of access-pattern leakage, integration with PQC primitives, and methods for efficient handling of multi-client and federated setups.
Conclusion
PPPQ-ANN establishes a highly efficient, privacy-preserving ANN framework via a hybridization of CKKS-based FHE and TEE. By introducing PQ-aware optimized packing, fast summation, and holistic encrypted database generation, the framework achieves practical query rate, high recall, and robust confidentiality. Its design principles—minimizing encrypted computations, leveraging hardware isolation, and orchestrating cryptographic defenses—are readily extensible to other privacy-critical AI workloads. Ongoing work should focus on bolstering resistance to access pattern attacks and refining multi-client protocols.

