- The paper introduces a novel Dask-driven framework that parallelizes PQ encoding and inverted indexing, significantly reducing runtime on large datasets.
- It employs a local-to-global centroid merge strategy and multi-threaded execution to maintain reconstruction accuracy comparable to single-process baselines.
- Empirical evaluations reveal orders-of-magnitude improvements in speed, enabling scalable approximate nearest neighbor search on high-dimensional data.
Large-Scale Data Parallelization of Product Quantization and Inverted Indexing Using Dask
Introduction and Motivation
The paper addresses a fundamental limitation in scaling Approximate Nearest Neighbor (ANN) search—specifically Product Quantization (PQ) and inverted index (II)-based retrieval—when operating on large-scale, high-dimensional datasets. Common use cases for similarity search, ubiquitous in domains ranging from autonomous navigation to social media analytics, are impeded by the computational and memory costs inherent to large datasets. Though PQ-based ANN methods are memory-efficient and widely adopted, practical deployment is hampered by run-time bottlenecks and resource constraints. The study leverages Python's Dask distributed computing library to propose a parallelized division and conquest methodology for large-scale PQ and II on commodity hardware.
Methodological Framework
The core approach involves partitioning the dataset row-wise, processing each block in parallel for PQ encoding using Dask, and then merging the results to construct a global model. This design necessitates careful management of centroid scope—local (per-chunk) centroids must be reconciled in a global context to maintain representational consistency and minimize reconstruction error. The system builds upon NanoPQ (pure Python PQ implementation), RII (fast memory-efficient IVFPQ-based ANN with subset search), and Dask's robust parallel scheduling.
Key Algorithmic Insights:
- Local-to-Global Merging: Each parallel PQ task returns decoded centroid representations; a new global PQ is subsequently trained on the aggregate of these centroids, and all original data are re-encoded to ensure accuracy in a unified codebook space.
- Parallel II Construction: Dask is further utilized to construct parallel inverted indices via RII, enabling swift k-NN queries using LSH-encoded PQ codes.
The investigation comprises three execution environments: non-parallelized (single process), single-node multi-threaded Dask, and a multi-node, multi-threaded Dask cluster (up to 440 threads).
Empirical Evaluation and Results
The dataset for empirical evaluation contains 6.7 million rows and 48 columns, sampled from SoilGrids 250m. The performance is analyzed in terms of reconstruction accuracy (RMSE) and execution runtime, emphasizing trade-offs due to parallelization and PQ hyperparameters (subspace count, code size).
Accuracy-Performance Trade-offs:
Increasing the subspace and code size parameters yields higher accuracy (reduced RMSE), but with a clear cost in computation time. Crucially, Dask-driven parallelized implementations closely match the accuracy of single-process baselines, demonstrating that distribution introduces negligible error.
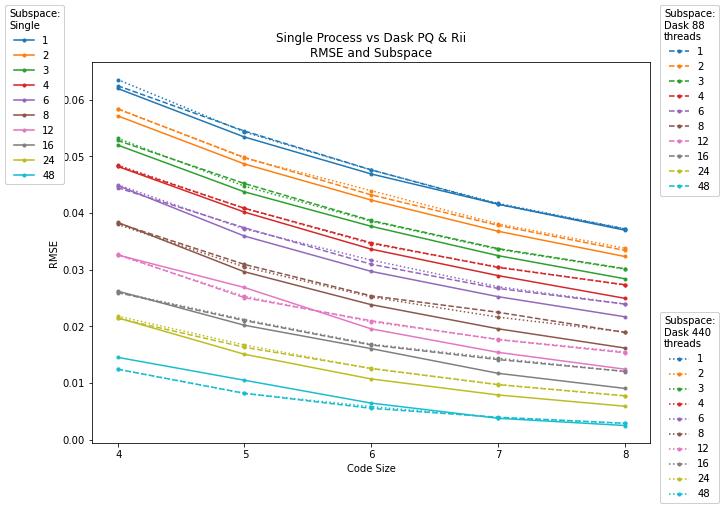
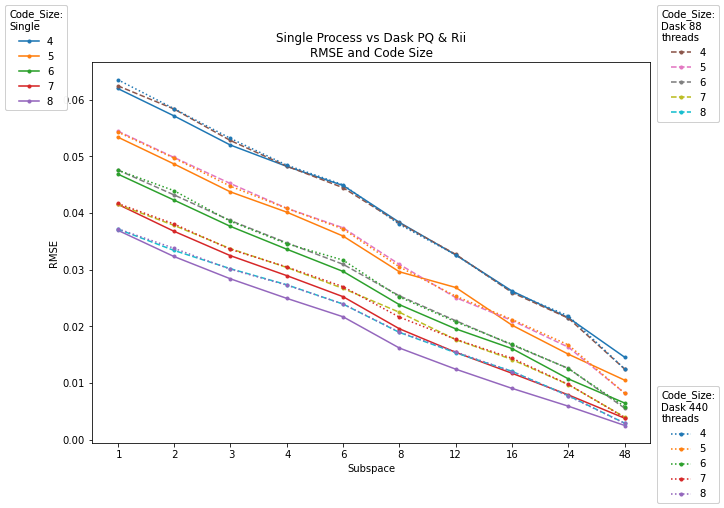
Figure 1: As subspace (top) and code size (bottom) increase, RMSE decreases; parallelization preserves accuracy close to single-process baselines.
Run-Time Gains:
Single-process run time scales poorly with increased subspace and code size, whereas Dask-based parallelism, particularly when applied to both PQ and RII, achieves orders-of-magnitude faster execution on large data. Multi-node, multi-threaded configurations substantially outperform single-node or unthreaded approaches.
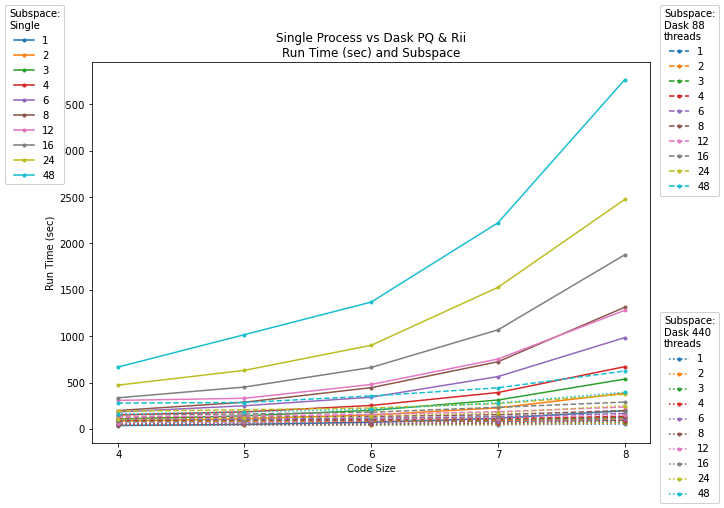
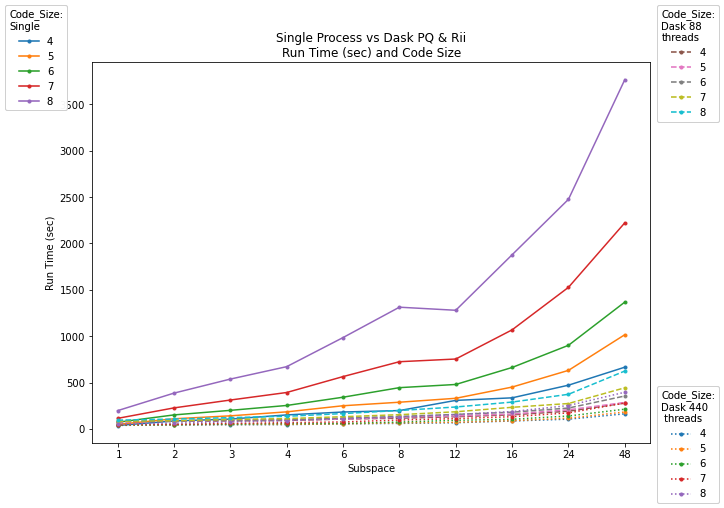
Figure 2: As subspace (top) and code size (bottom) increase, single-process run time rises sharply; Dask-based parallelization, whether for PQ or PQ+RII, is substantially faster.
Scalability:
Parallel PQ and RII, using 88 to 440 Dask threads, sustain accuracy essentially identical to non-parallel methods, while delivering dramatic reductions in runtime—enabling tractable analysis of datasets that would otherwise be infeasible due to memory or computation constraints.
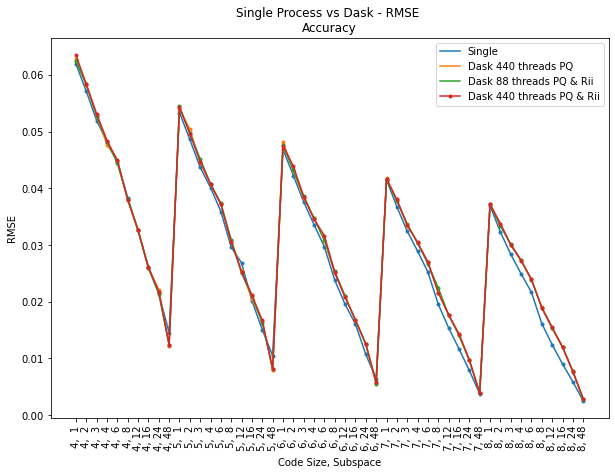
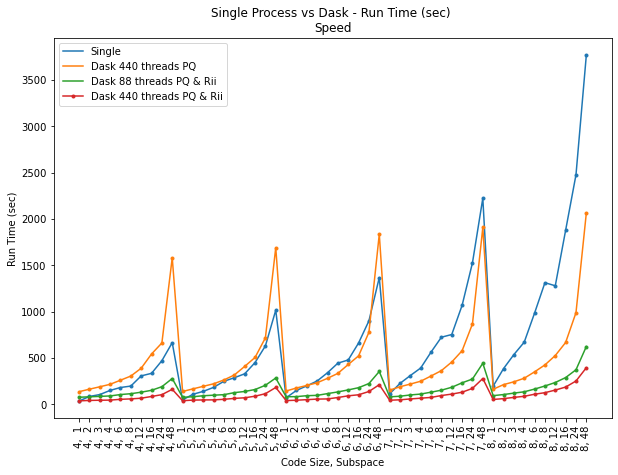
Figure 3: Dask with 88 or 440 threads achieves near-constant accuracy and significant speedups compared to single-process and Dask-PQ-only configurations.
Operational Visualization:
An operational Dask dashboard snapshot substantiates the effective scaling (to 440 threads), providing real-time visibility into work-stealing and resource utilization during large-scale PQ and RII tasks.
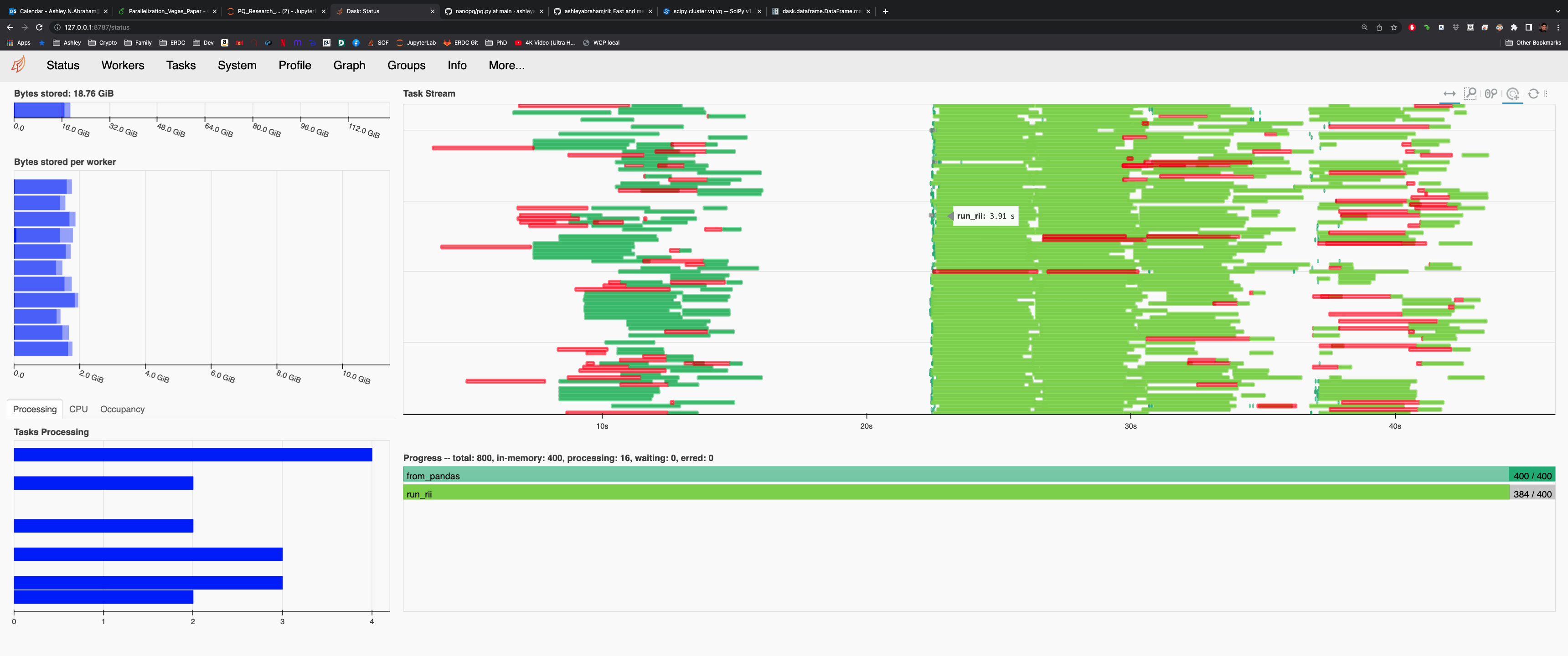
Figure 4: Dask dashboard visualizing 440 threads managing PQ and RII parallel tasks.
Practical Implications and Theoretical Impact
The study demonstrates that parallelization via Dask allows scaling ANN search pipelines to multi-million-point, high-dimensional datasets on cost-effective hardware while preserving accuracy. This is vital for real-world deployments where latency and memory are critical constraints. Notably, the results caution against indiscriminate parallelization: overhead may outweigh benefits on small and medium datasets. The global merge strategy is crucial for preserving global consistency after local, parallel PQ encodings, addressing a frequent pitfall in embarrassingly parallel learning regimes.
On a theoretical level, this work positions Dask-enabled distributed PQ as a practical alternative to GPU-centric or hardware-optimized libraries (e.g., FAISS), suggesting a new avenue for scalable similarity search using widely accessible Python data science ecosystems.
Prospects and Future Directions
The current implementation focuses on row-wise partitioning. Further investigation into column-wise or combined (row/column) partitioning, possibly integrating Dask Dataframes and more sophisticated communication patterns, presents opportunities to push scalability limits. Comparative analyses against alternative parallelization tools (Apache Spark, SCOOP), or hardware-optimized solutions, would help quantify trade-offs between throughput, setup complexity, and generalizability across domains. Expanding to HPC clusters or applying these techniques to truly massive-scale geospatial datasets (billions of points) remains an open challenge.
Potential research can also explore PQ and RII chunk optimization, memory management strategies for distributed settings, and hybrid pipelines leveraging both CPU-parallel and GPU-accelerated primitives.
Conclusion
This paper establishes that Dask-driven distributed parallelization of PQ and inverted indexing, using a pure Python stack, enables accurate and memory-efficient approximate k-NN search for large-scale, high-dimensional datasets. Significant run-time improvements are achievable without accuracy degradation when appropriately scaled to dataset size and compute resources. The method offers a compelling, accessible option for practitioners needing scalable similarity search without recourse to specialized hardware or vendor-locked libraries, and suggests several avenues for continued methodological and empirical refinement.
Citation: "Large-Scale Data Parallelization of Product Quantization and Inverted Indexing Using Dask" (2604.21645).

