- The paper presents a novel integration of RLWE-based fully homomorphic encryption into Llama-3’s attention layers.
- It utilizes 2-bit quantization and programmable bootstrapping to perform encrypted matrix operations while maintaining up to 98% generation accuracy.
- Experimental results highlight practical tradeoffs between latency, throughput, and encryption overhead in secure LLM inference.
Fully Homomorphic Encryption for Privacy-Preserving Llama-3 Inference
Introduction
The intersection of LLMs with security-critical fields such as healthcare and finance amplifies concerns regarding the inadvertent exposure of sensitive data during model inference. The work "Fully Homomorphic Encryption on Llama 3 model for privacy preserving LLM inference" (2604.12168) addresses these concerns by integrating post-quantum, RLWE-based FHE operations into the Llama-3 transformer inference pipeline, enabling inference over encrypted data without releasing plaintexts to potentially untrusted servers. The presented methodology leverages integer quantization and programmable bootstrapping to minimize inference degradation, all within performance boundaries typical of modern CPUs.
Llama-3 Architecture and Targets for FHE Integration
The baseline Llama-3 follows a decoder-only transformer architecture with RMSNorm, RoPE positional encoding, Grouped Multi-Query Attention (GQA), and SwiGLU activations. The authors selectively target attention layers—the principal locus of contextual reasoning and sensitivity to inputs/weights—for FHE integration.
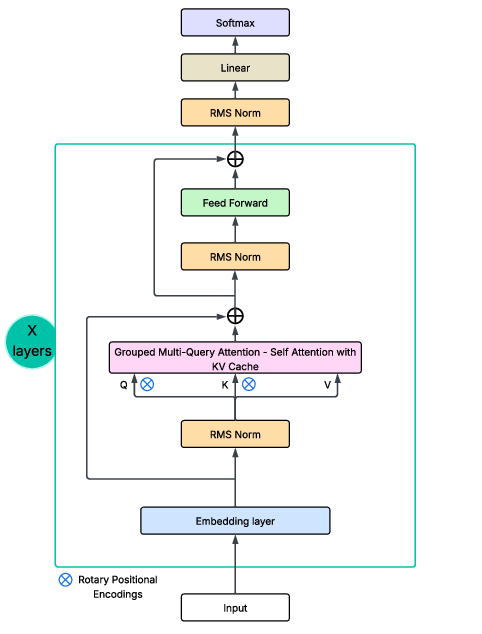
Figure 1: The Llama-3 main architecture.
To manage the tension between security and efficiency, they define two architectural modifications:
- SingleHead FHE Model: Only the first decoder layer's attention is executed under FHE, the remainder in plaintext, providing a partial encryption scenario.
- MultiHead FHE Model: All attention heads in all layers are homomorphically encrypted, realizing the fully secured variant.
This fine granularity allows practitioners to trade off between privacy guarantees and computational cost as dictated by deployment constraints.
Implementation of FHE-Enabled Attention
Realizing FHE in transformers is non-trivial due to unsupported floating-point arithmetic and polynomial non-linearities in current FHE libraries. The approach proceeds as follows:
- All matrix multiplications for attention computation (QKT, etc.) are quantized to 2-bit integer representations, compatible with the concrete-ml library's FHE backend.
- Softmax and other activation functions are replaced by polynomial or lookup-table approximations, evaluated over ciphertexts.
- Ciphertext packing and programmable bootstrapping circuits are inserted to control RLWE noise growth after nonlinearities and multiplications.
The key integration replaces standard attention heads with two core classes:
- QLlamaSingleHeadAttention: Implements grouped multi-query single-head operations under FHE.
Figure 2: QLlamaSingleHeadAttention—single homomorphically encrypted grouped multi-query attention head.
- QLlama3MultiHeadsAttention: Concatenates multiple FHE-encrypted attention heads for the multi-head scenario.
Figure 3: QLlama3MultiHeadsAttention—multi-head homomorphically encrypted grouped multi-query attention heads.
These are integrated into the original Llama-3 class hierarchy.
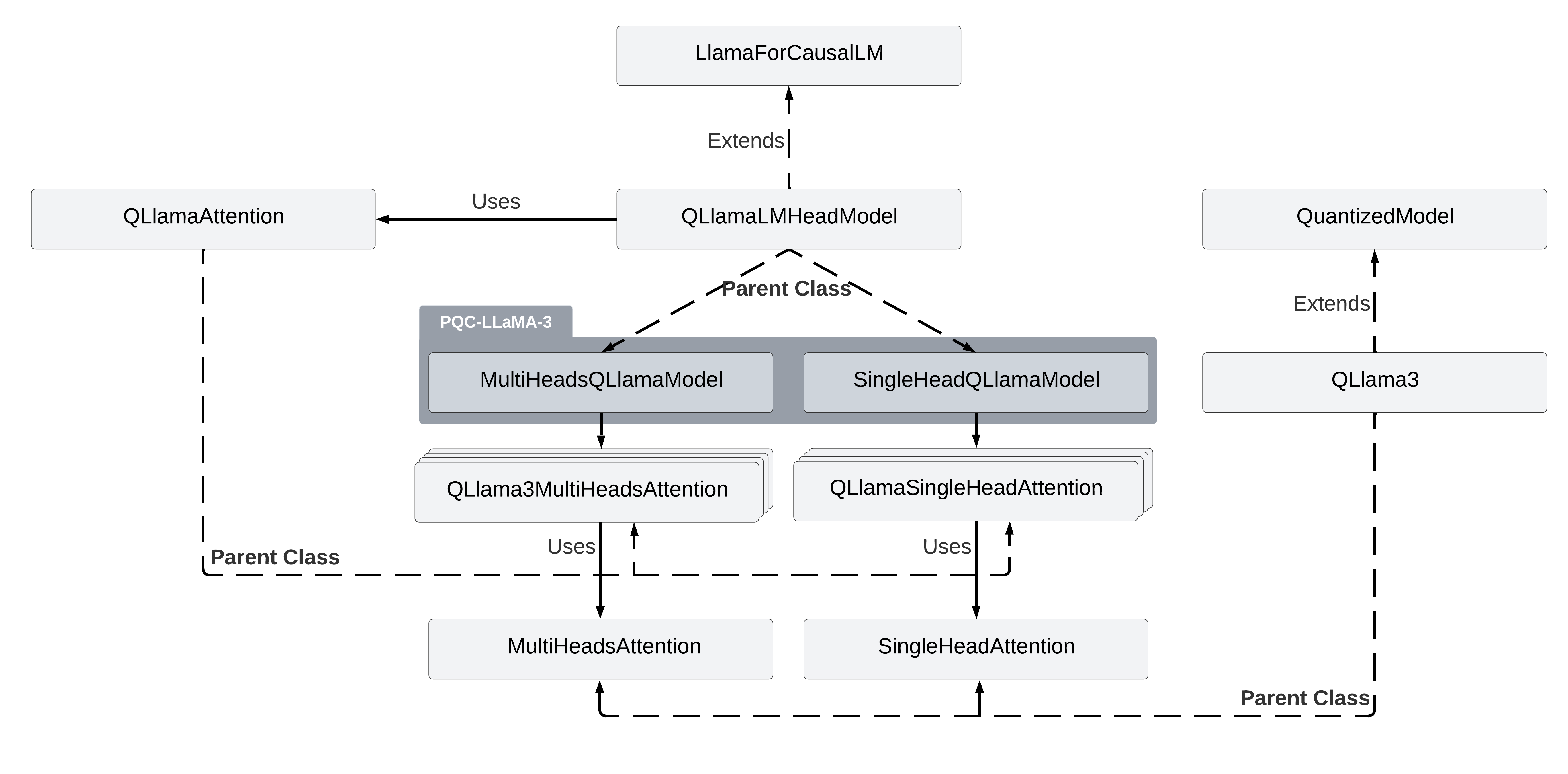
Figure 4: Class hierarchy of the proposed FHE-enabled QLLaMA-3 models.
Quantization calibration is performed via a plaintext pass before generating the FHE circuit, ensuring numerical consistency, followed by full compilation to a programmable bootstrapping-enriched inference graph.
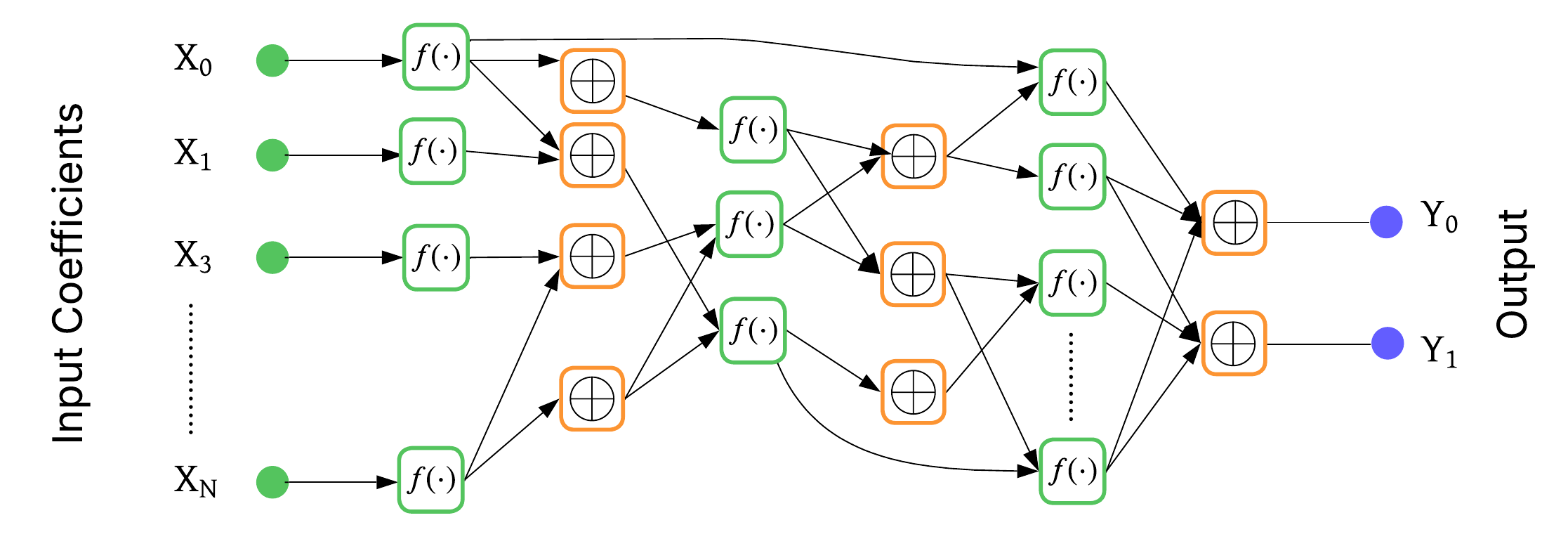
Figure 5: Programmable Bootstrapping Evaluation Circuit—noise reduction via bootstrapping per function.
Inference proceeds in a hybrid client-server configuration: the client encrypts input embeddings, the server runs FHE attention, and the client performs final decryption/postprocessing.
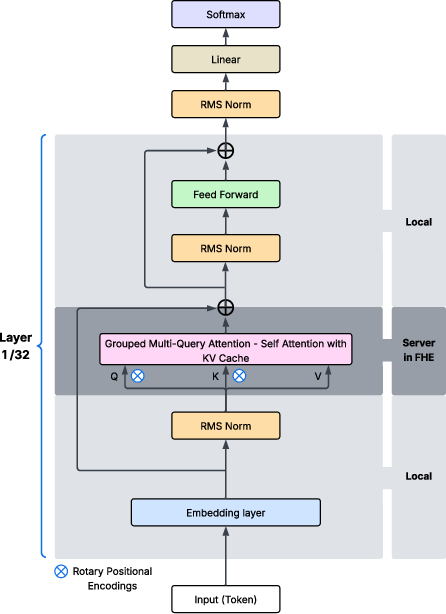
Figure 6: PQC-LLaMA-3 inference: client encrypts and decrypts; server runs attention fully homomorphically.
Experimental Results
Text generation tasks are benchmarked for both short context (1–10 tokens) and long context (70–500 tokens) to evaluate per-token degradation versus noise accumulation effects.
- Accuracy: At 2-bit quantization and FHE execution, generation accuracy reaches up to 81.7% (short context, k=10) and 98.2% (long context, k=500) in the single-head variant, with multi-head models achieving 87.4% and 97.7% in the respective regimes.
- Latency/Throughput: On an Intel i9-14900K, the SingleHead FHE model achieves 0.236s/token, up to 80 tokens/s, with MultiHead FHE at 0.825–1.26s/token.
- FHE Overhead: Metric analysis shows average programmable bootstrapping costs of ∼138 per token (single head), rising to over 13,000 per token for multihead; memory utilization achieves 2 kB/token (single head) and 1.1 kB/token (multihead).
- Cache Efficiency: Despite the ciphertext expansion, cache memory miss rates remain relatively controlled due to pronounced temporal and spatial locality (KV-caching, SIMD-packing).
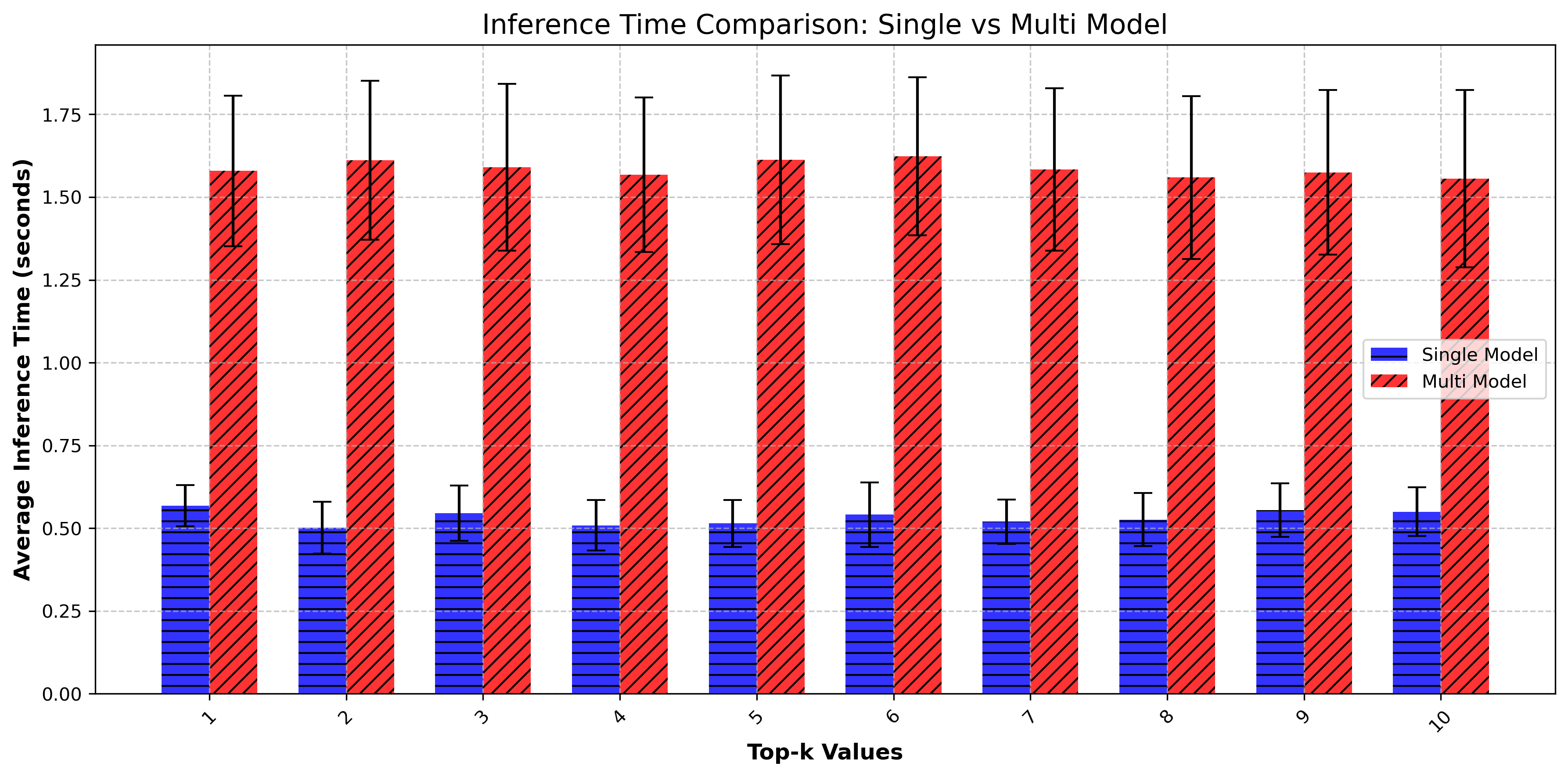
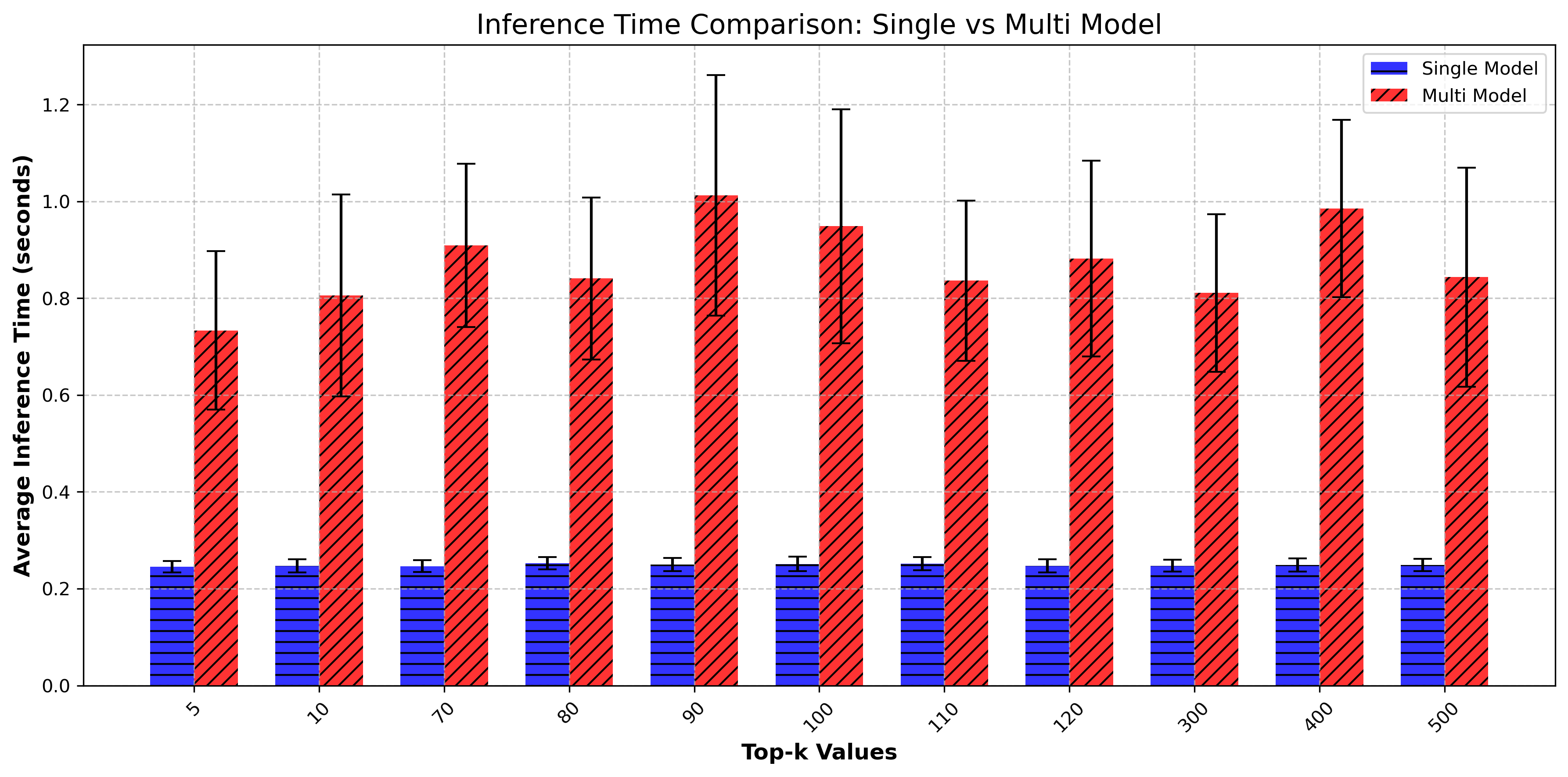
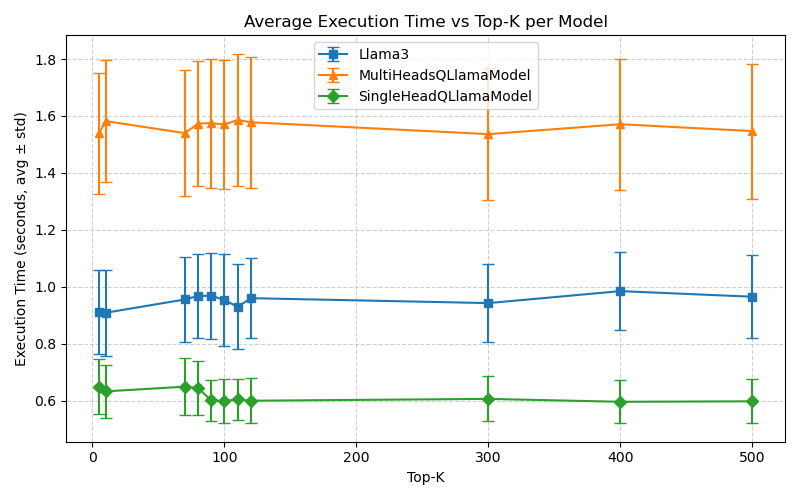
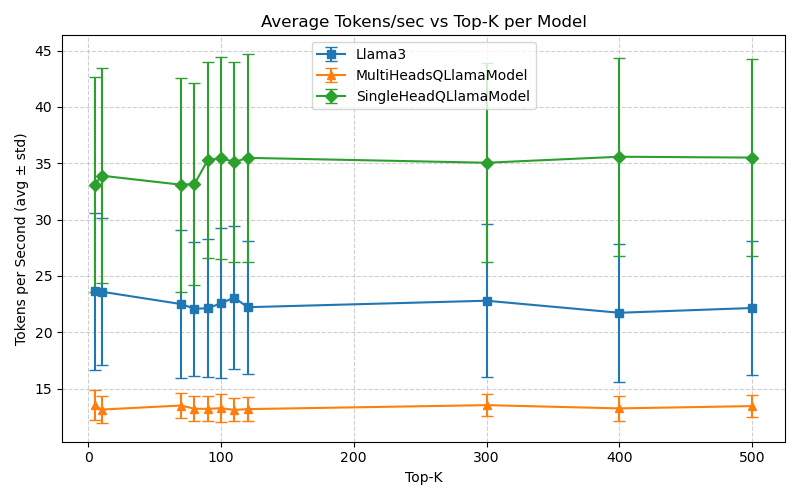
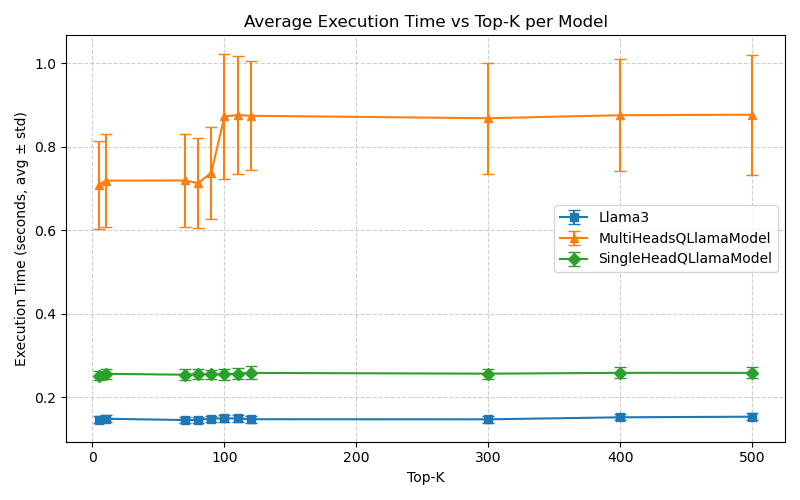
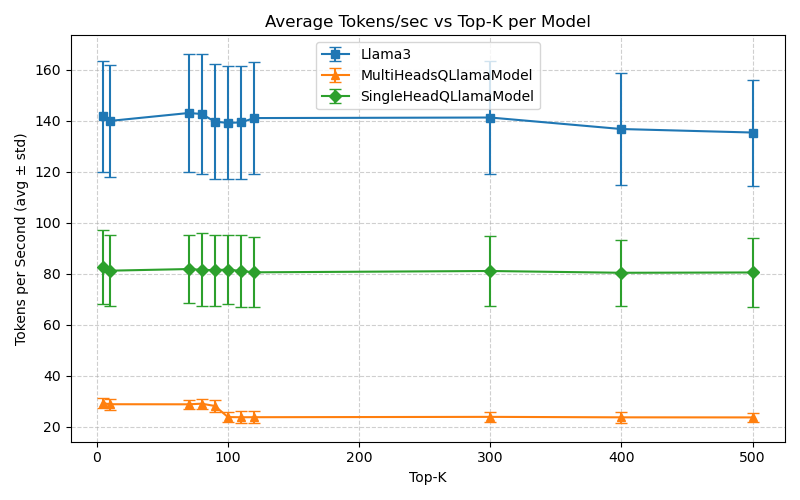
Figure 7: Inference times on Machine M1 under the FHE mode.
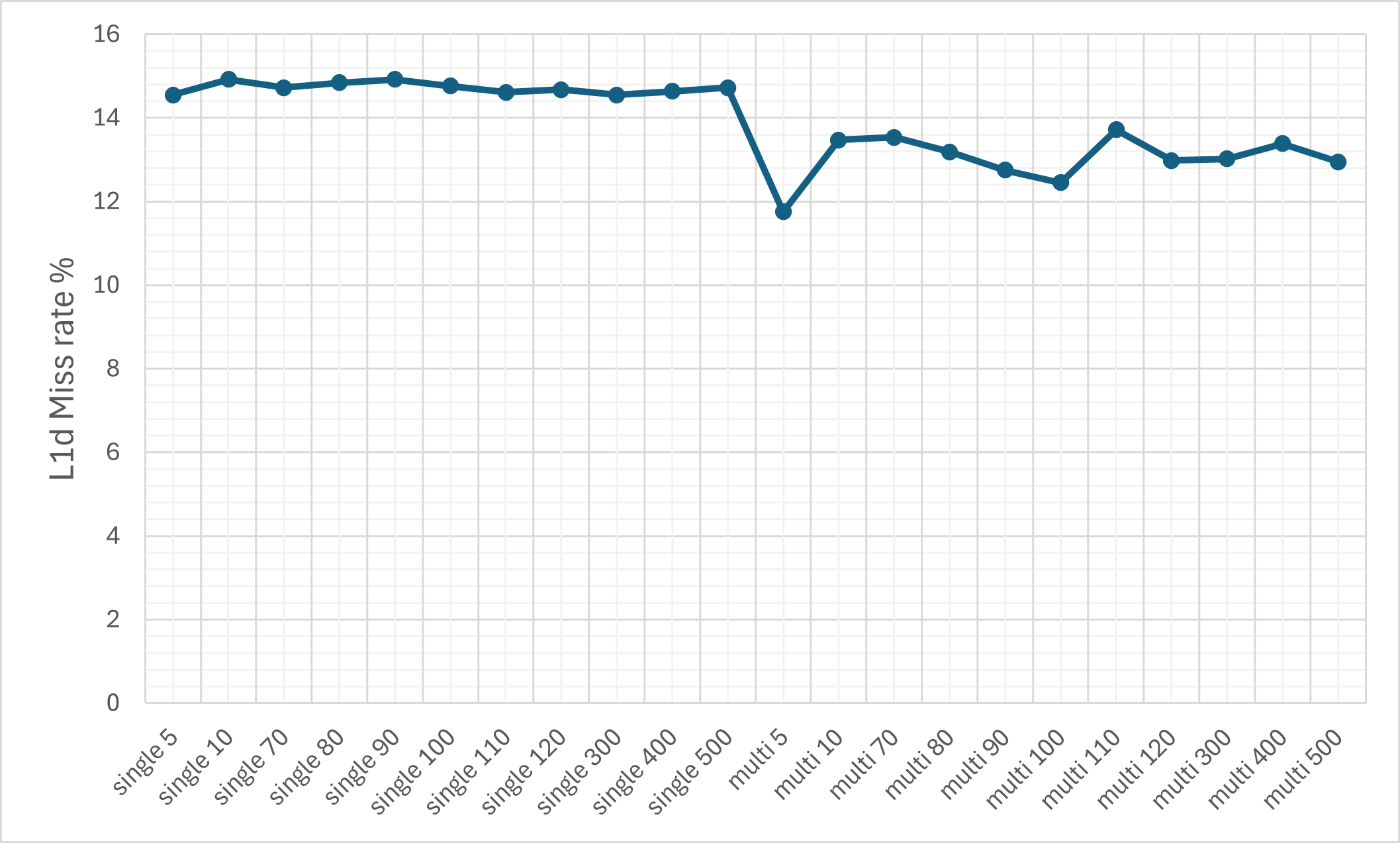
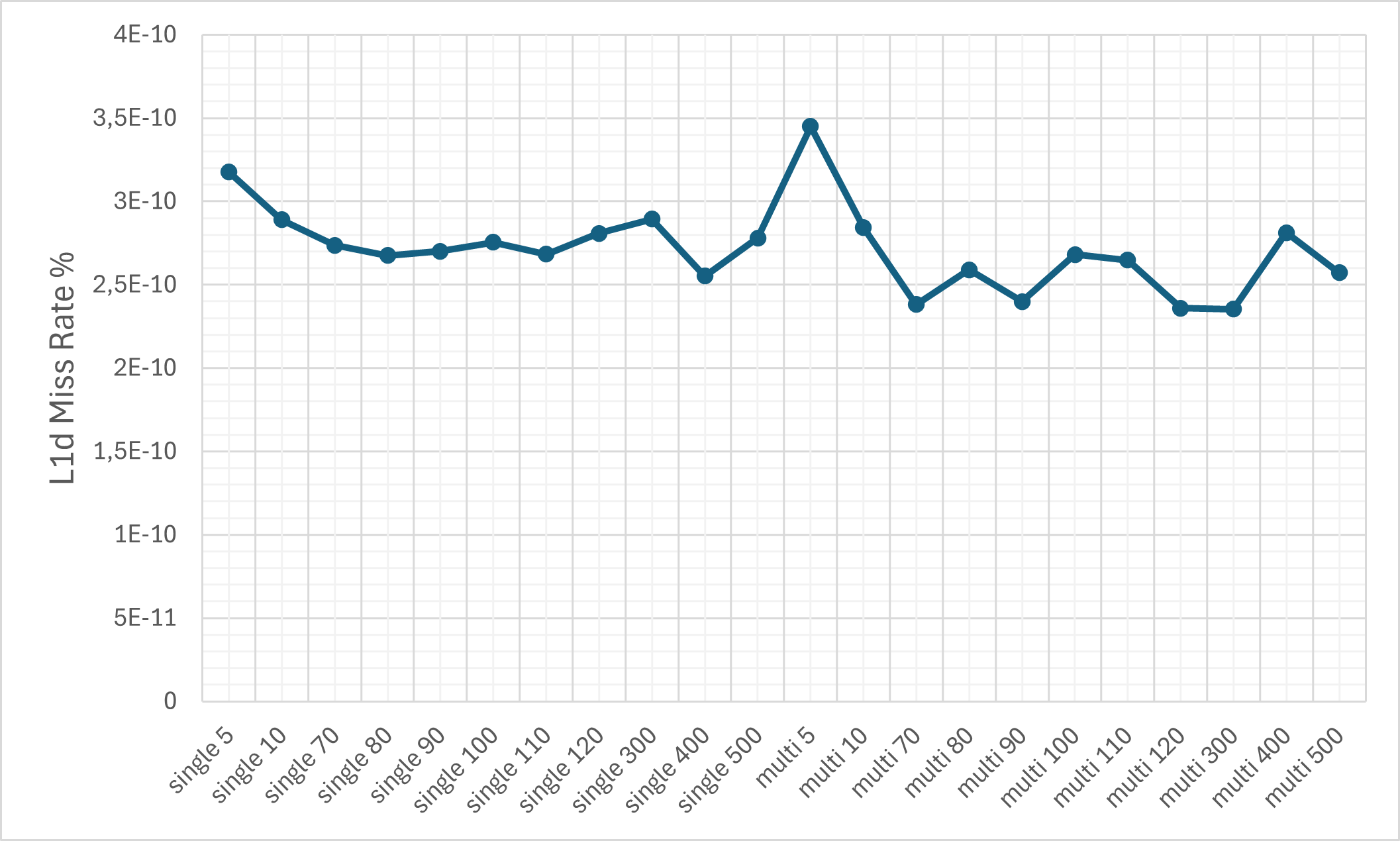
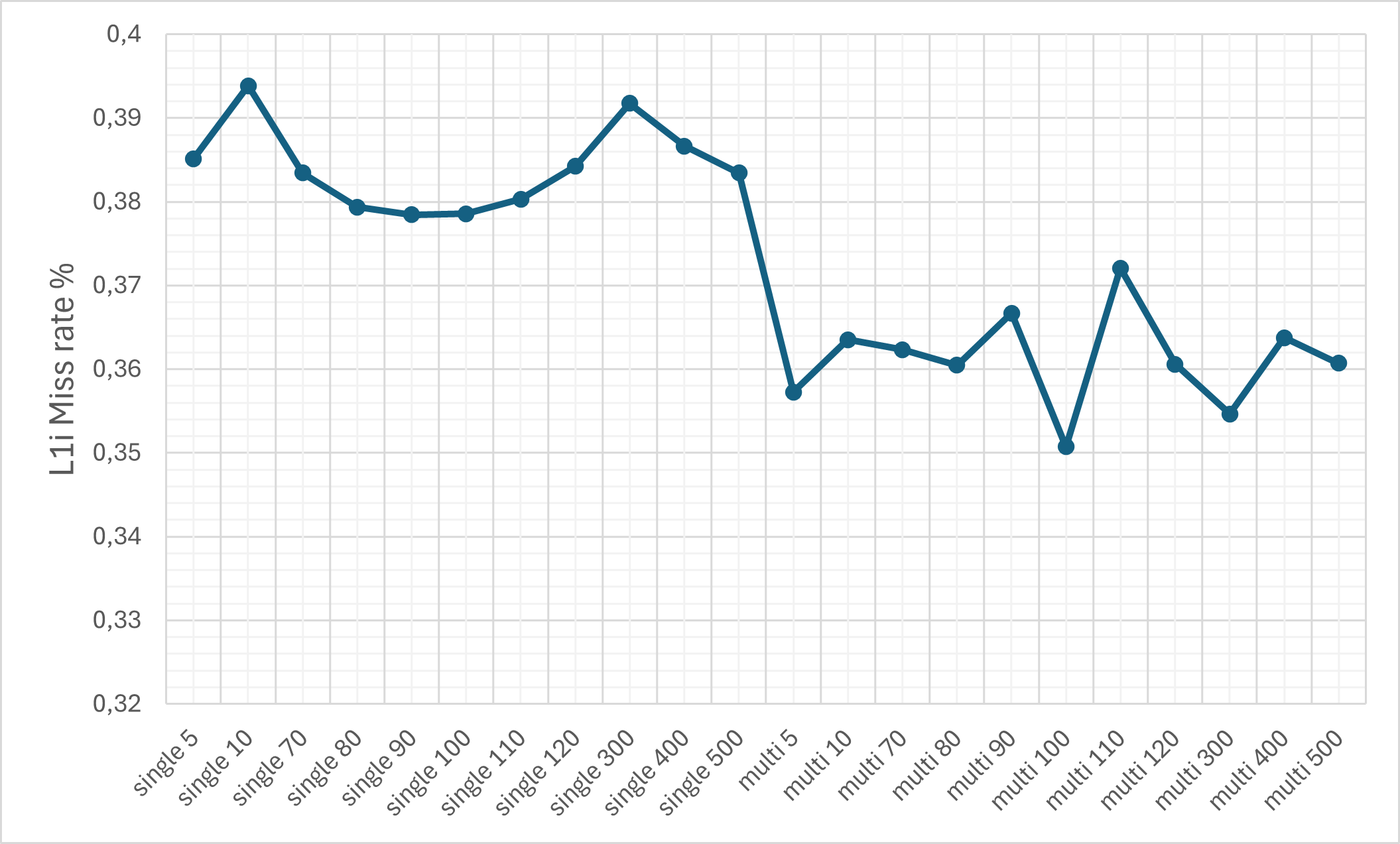
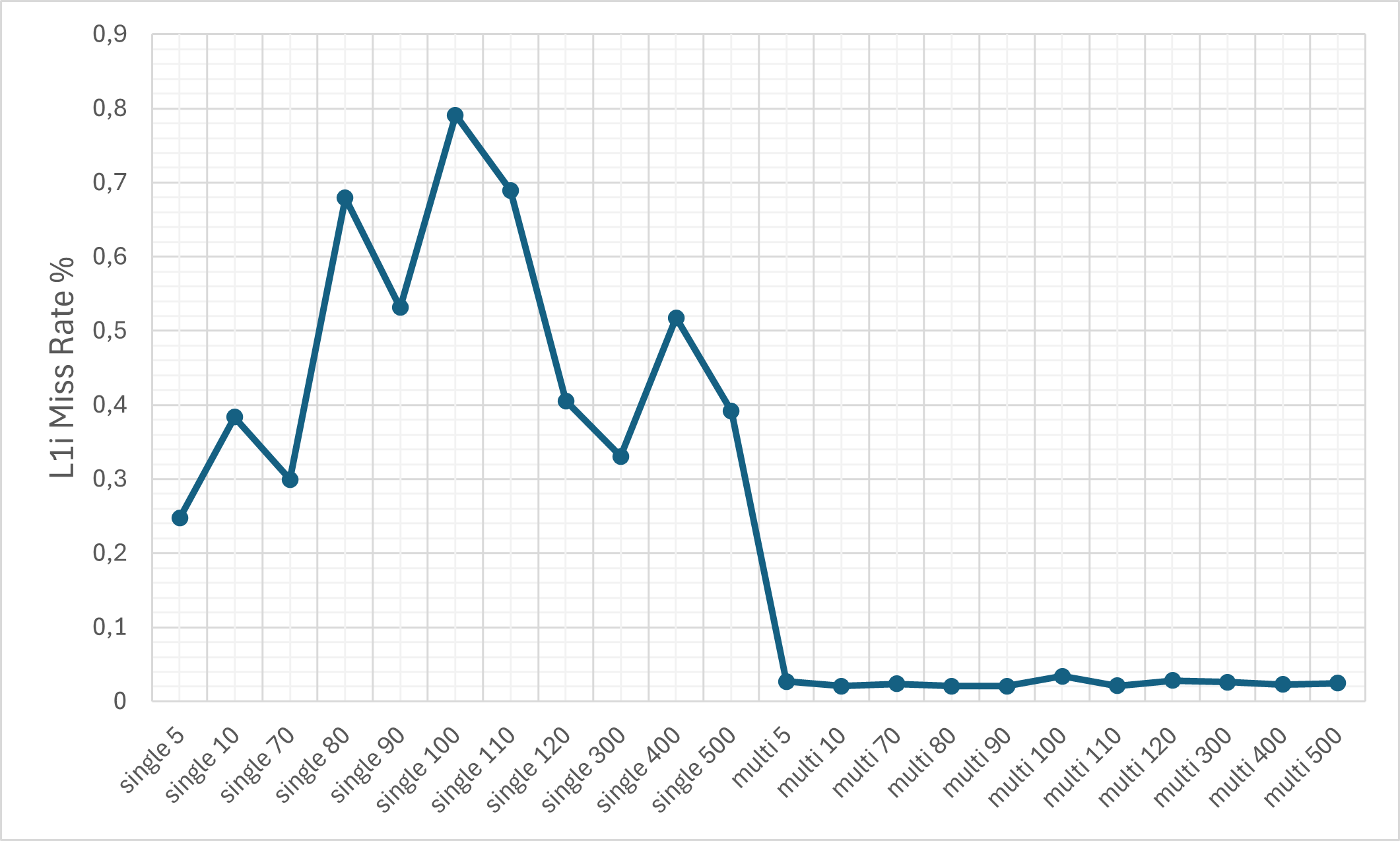
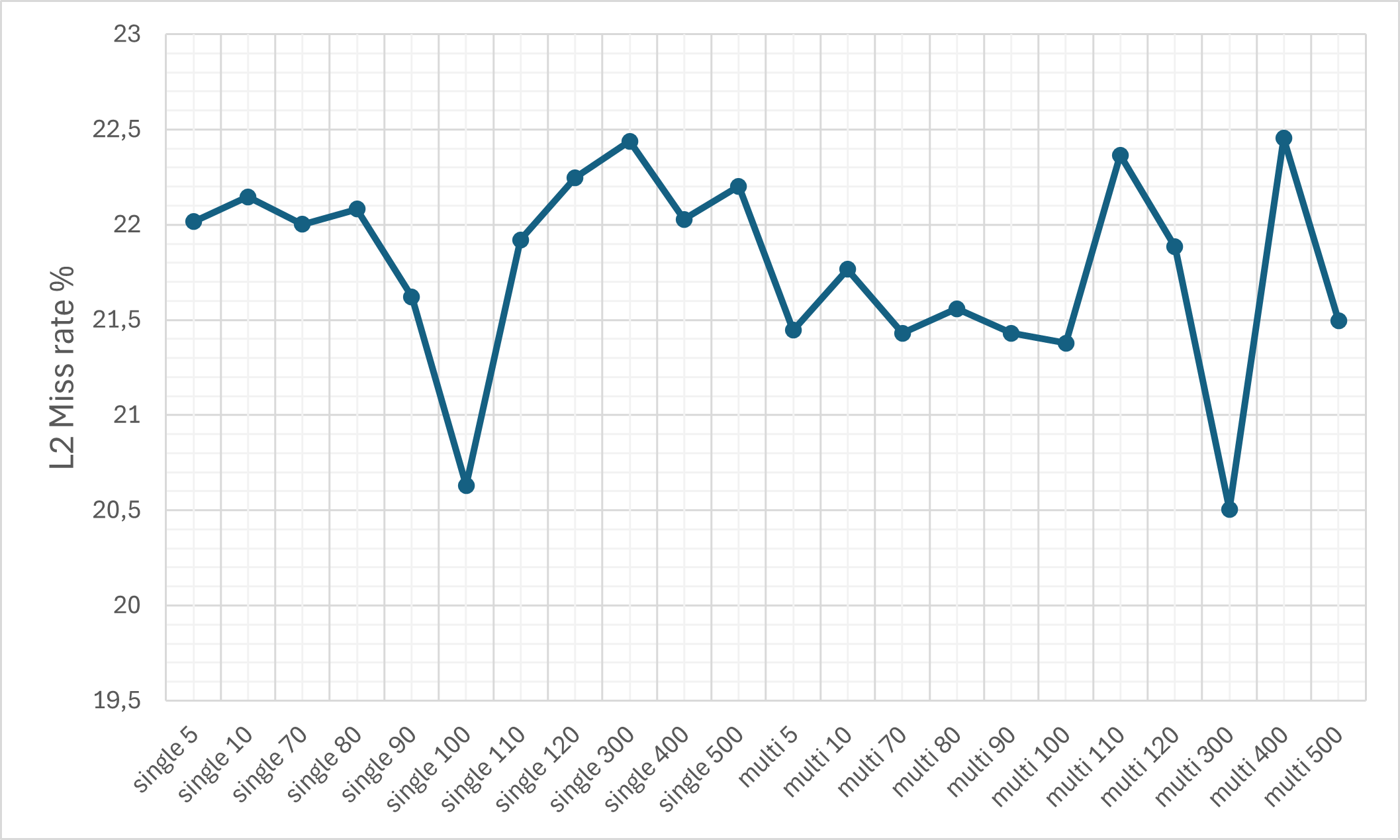
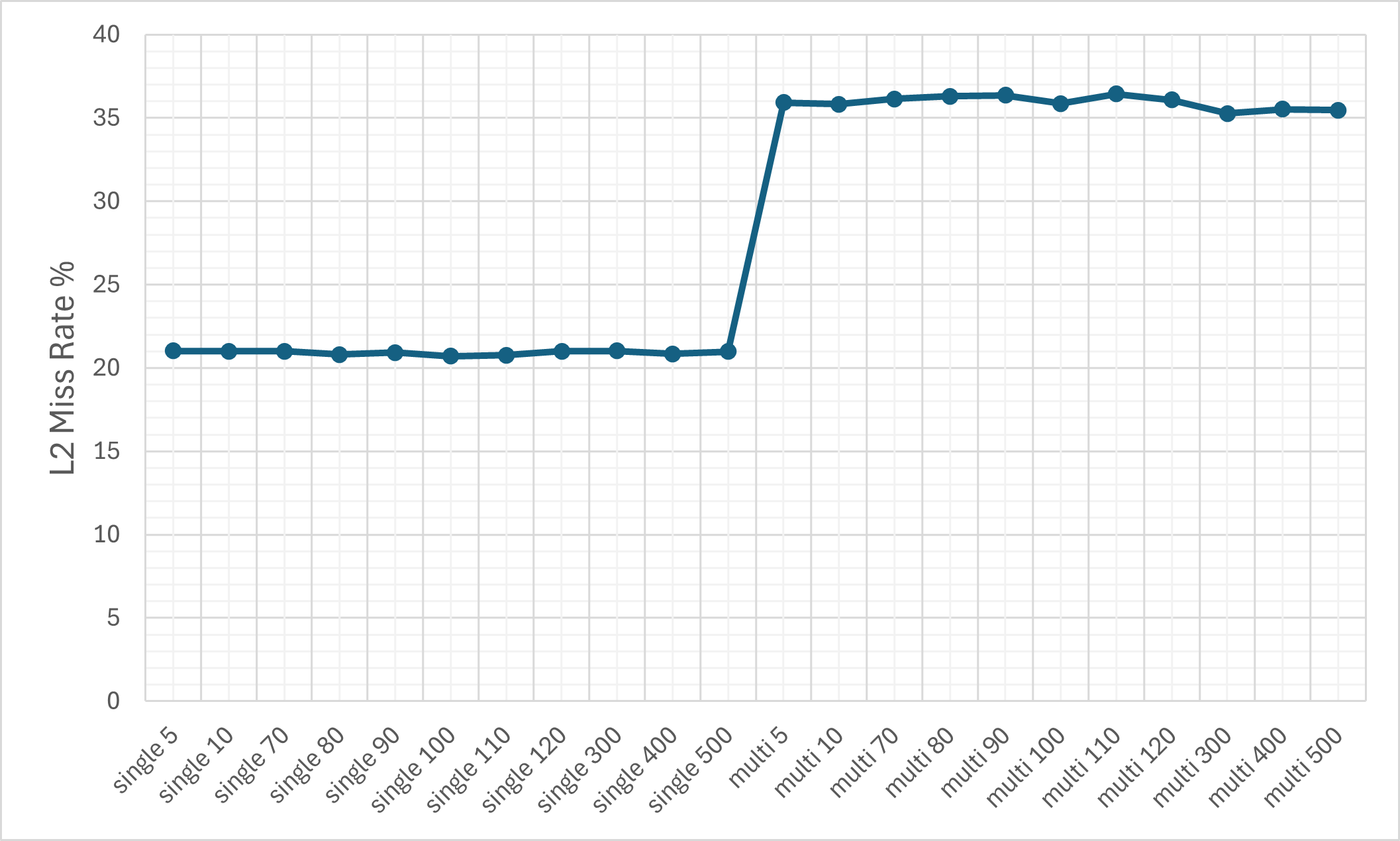
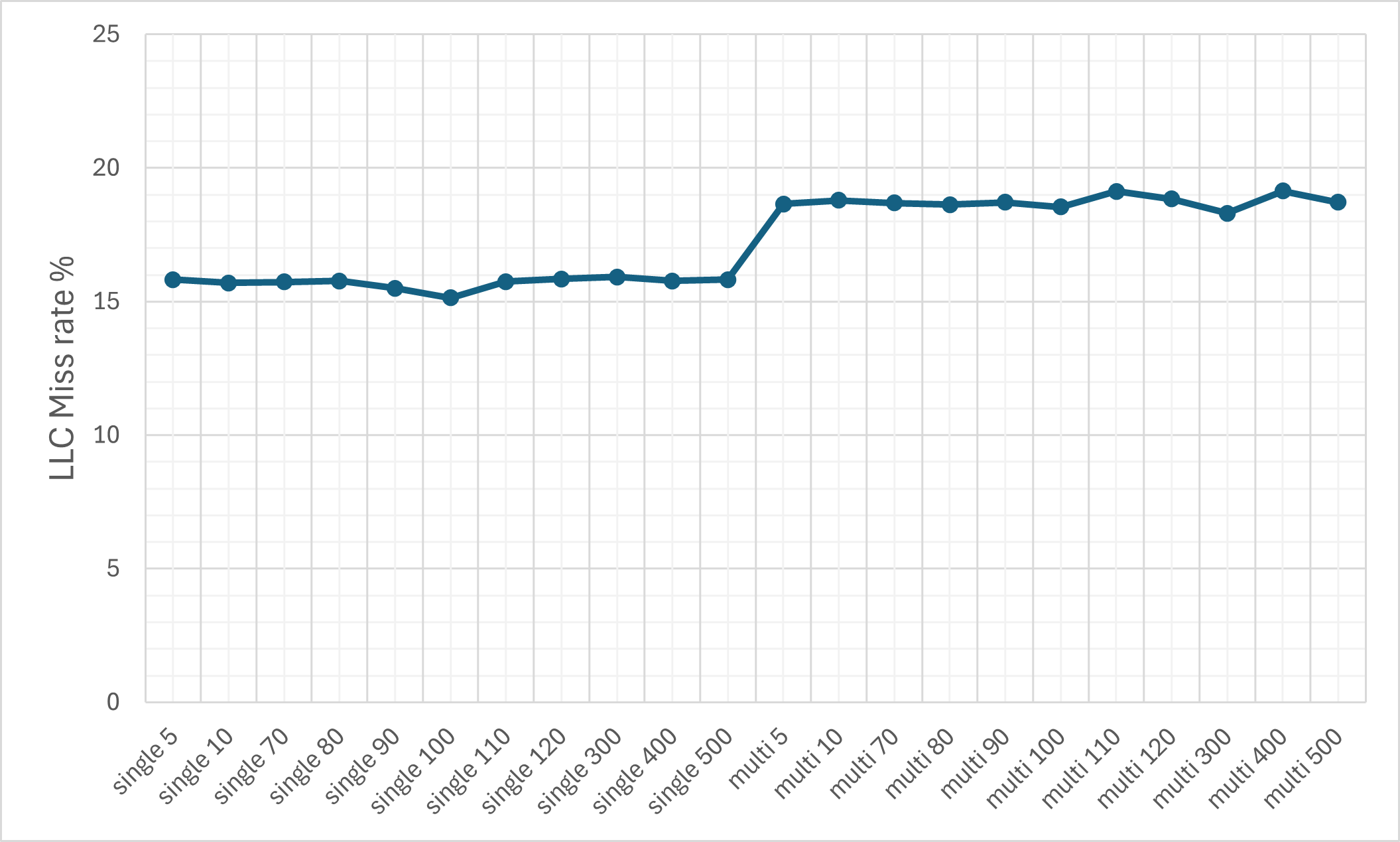
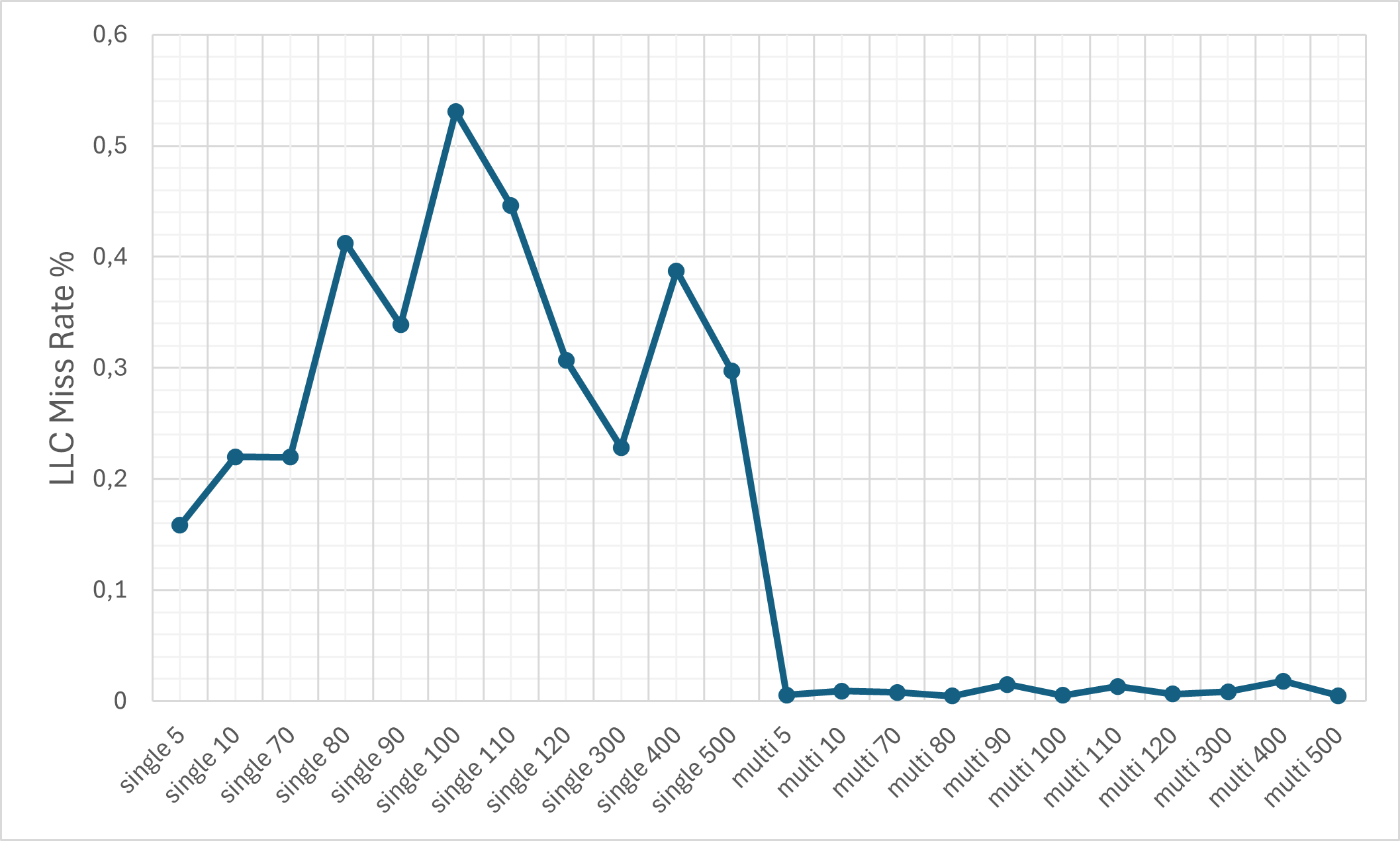
Figure 8: The L1d cache miss rate on the M1 machine.
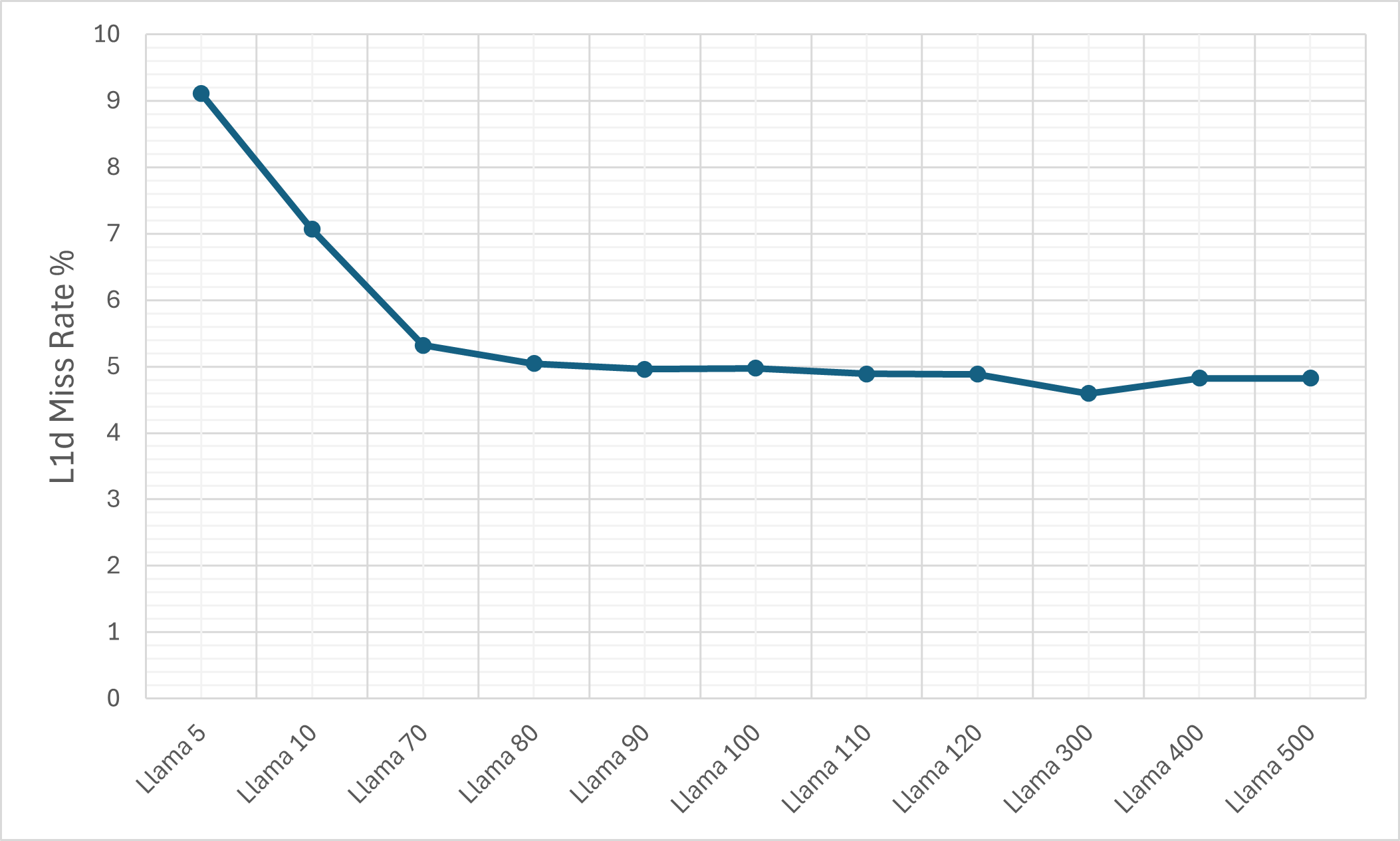
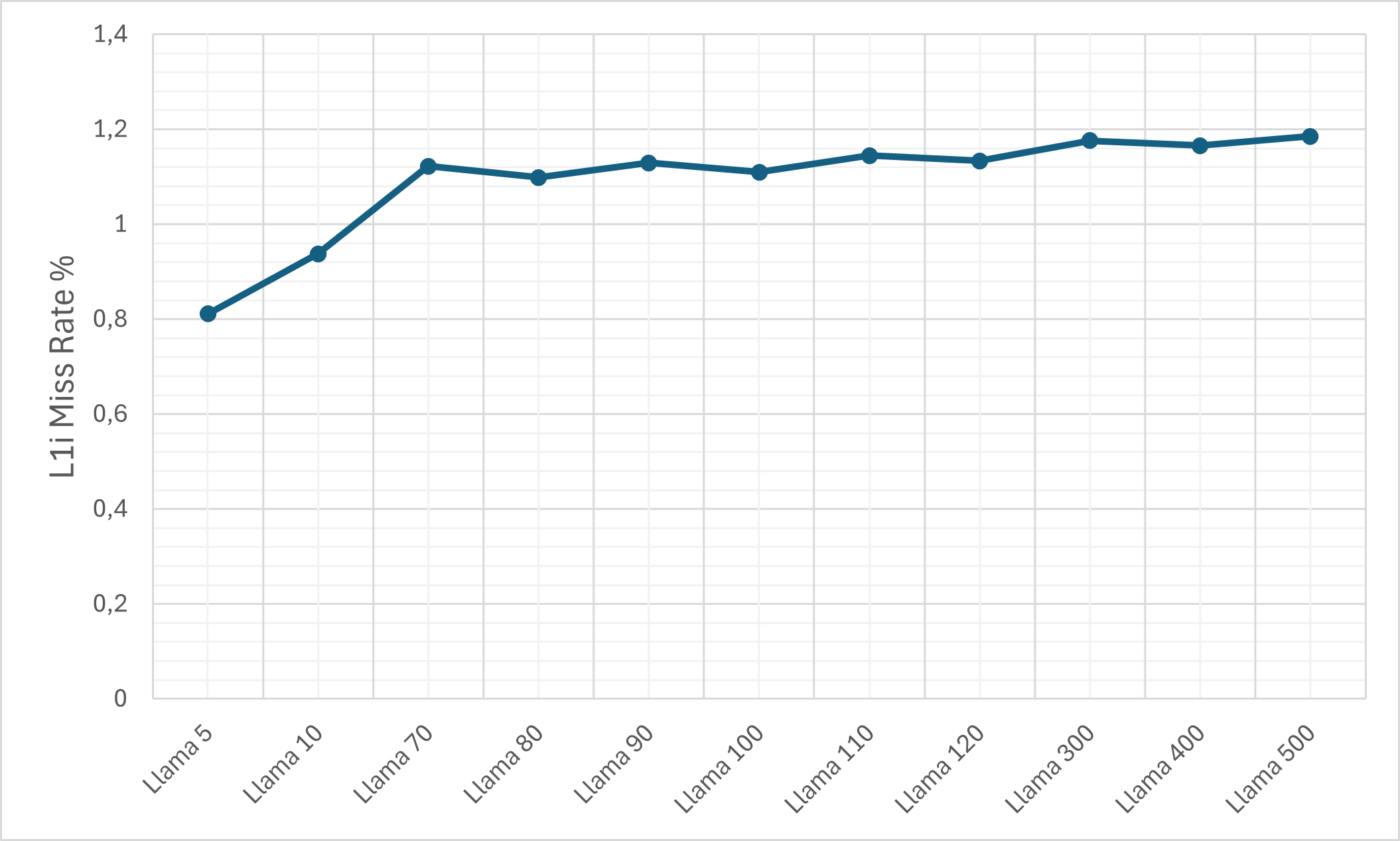
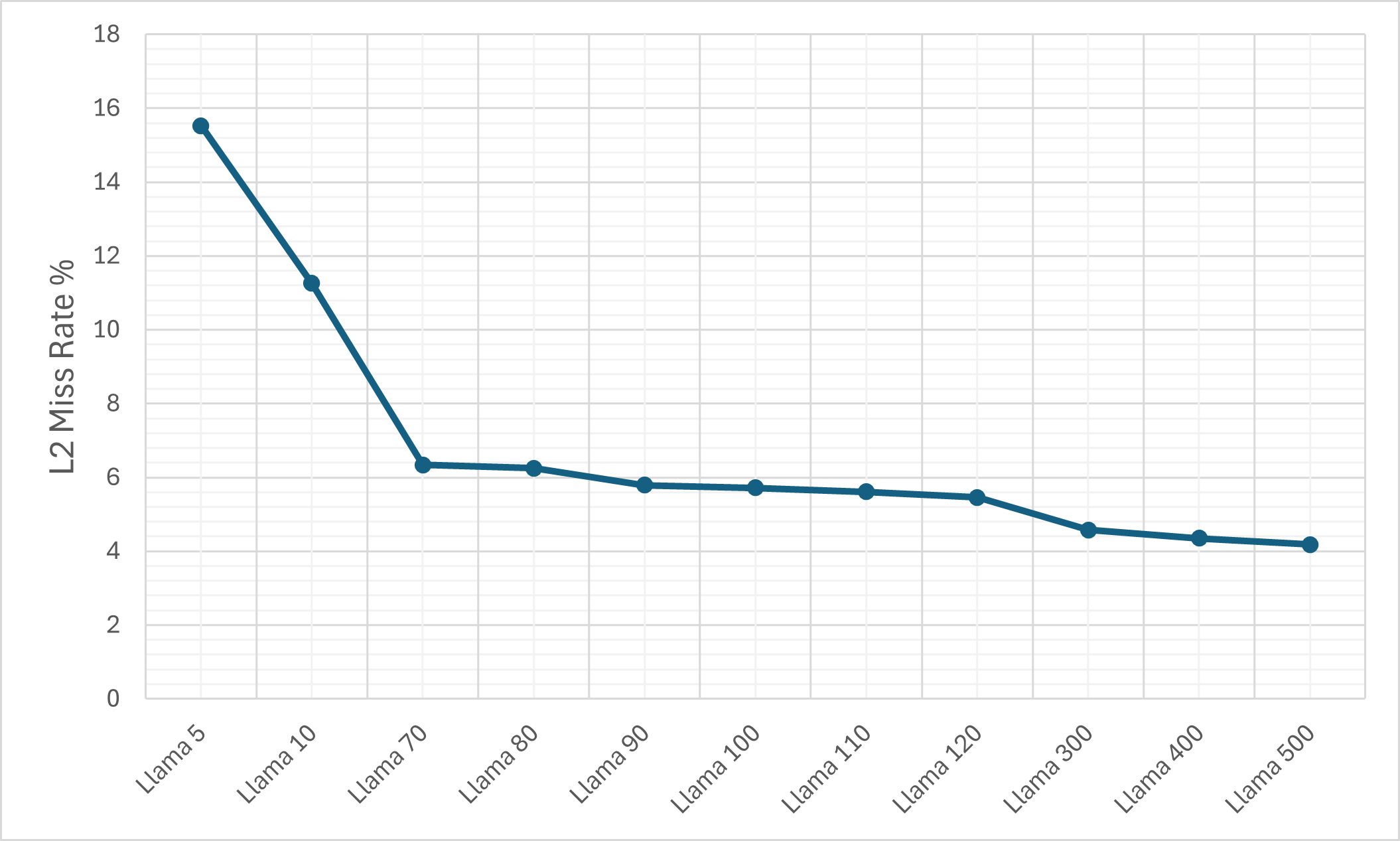
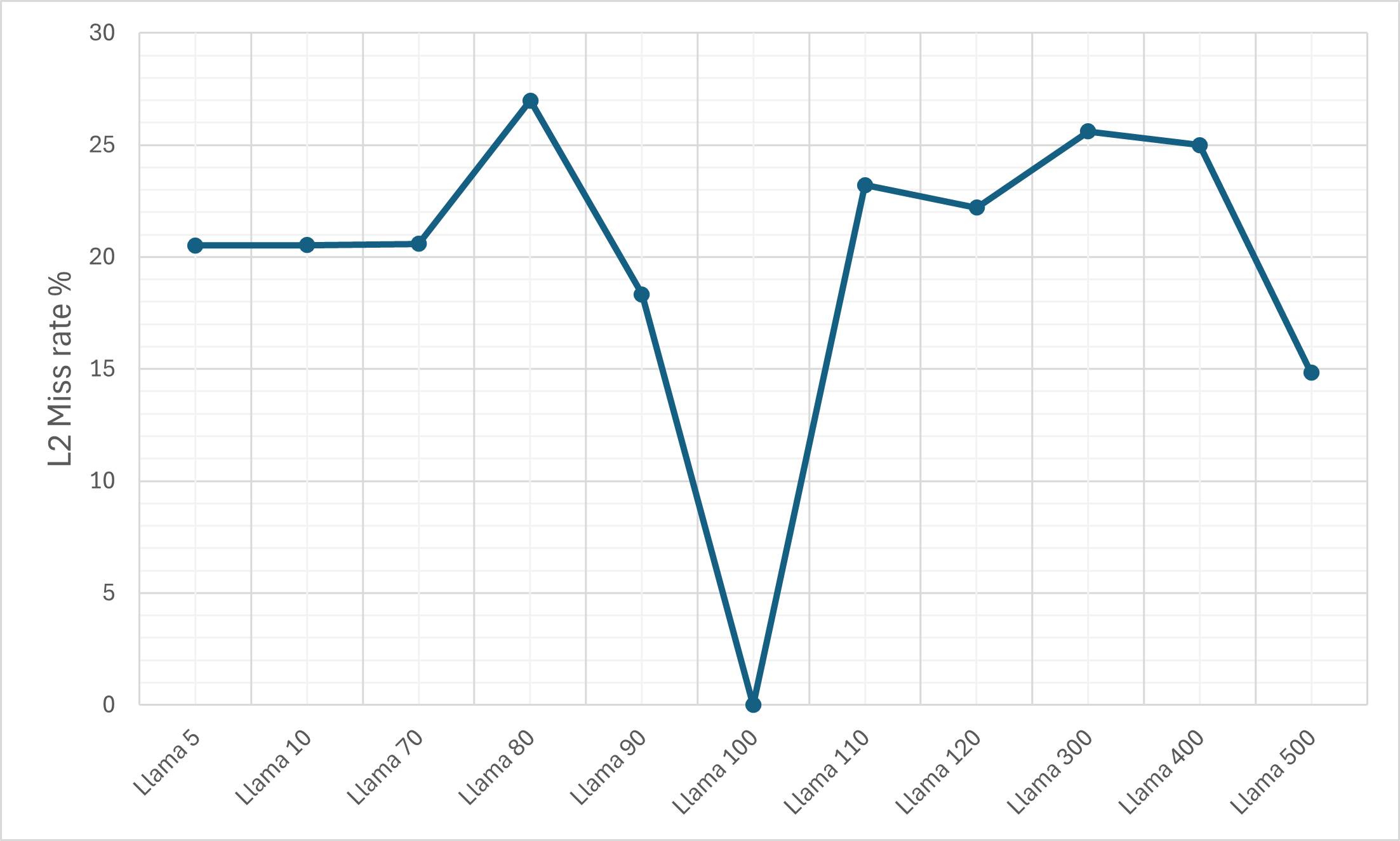
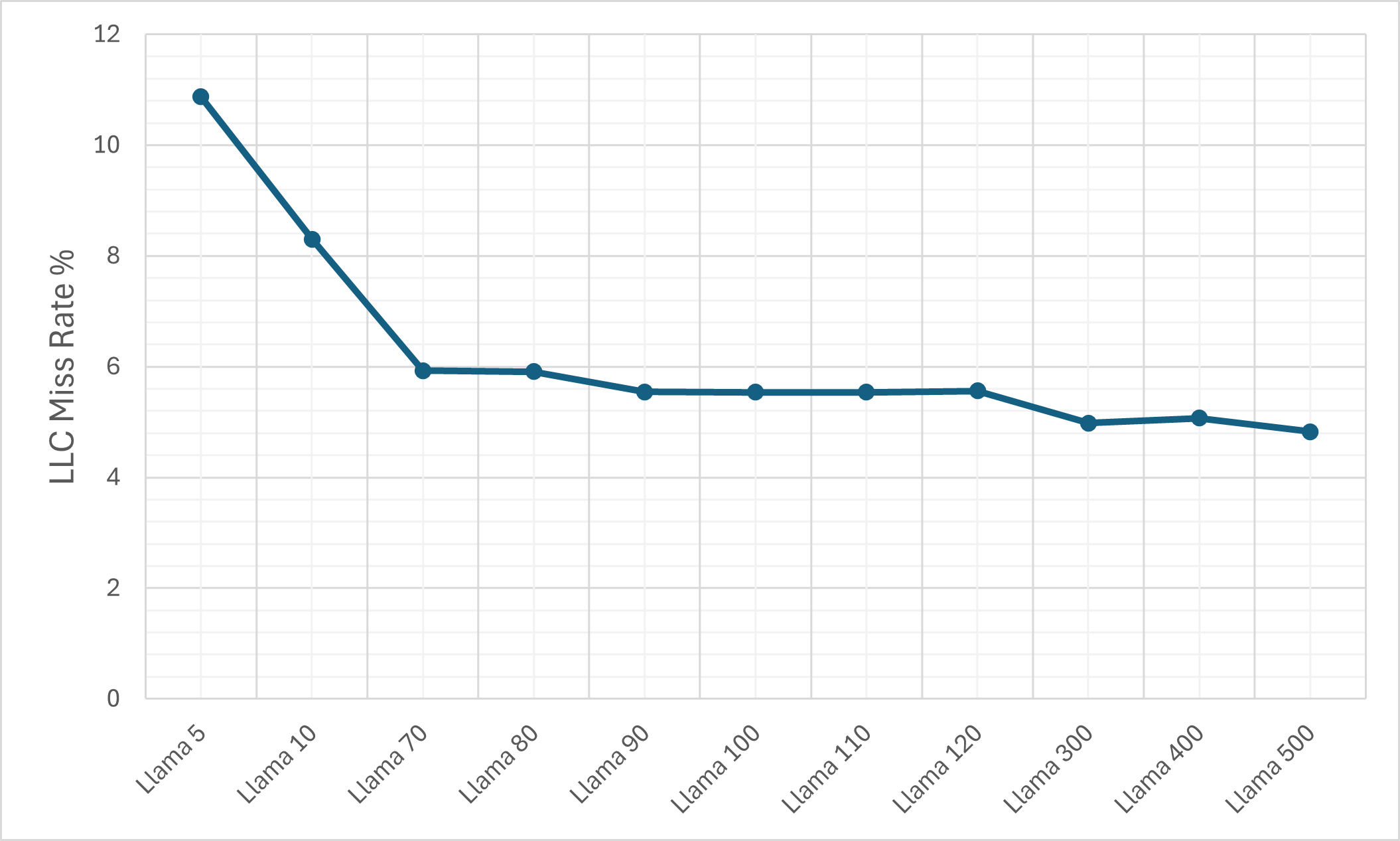
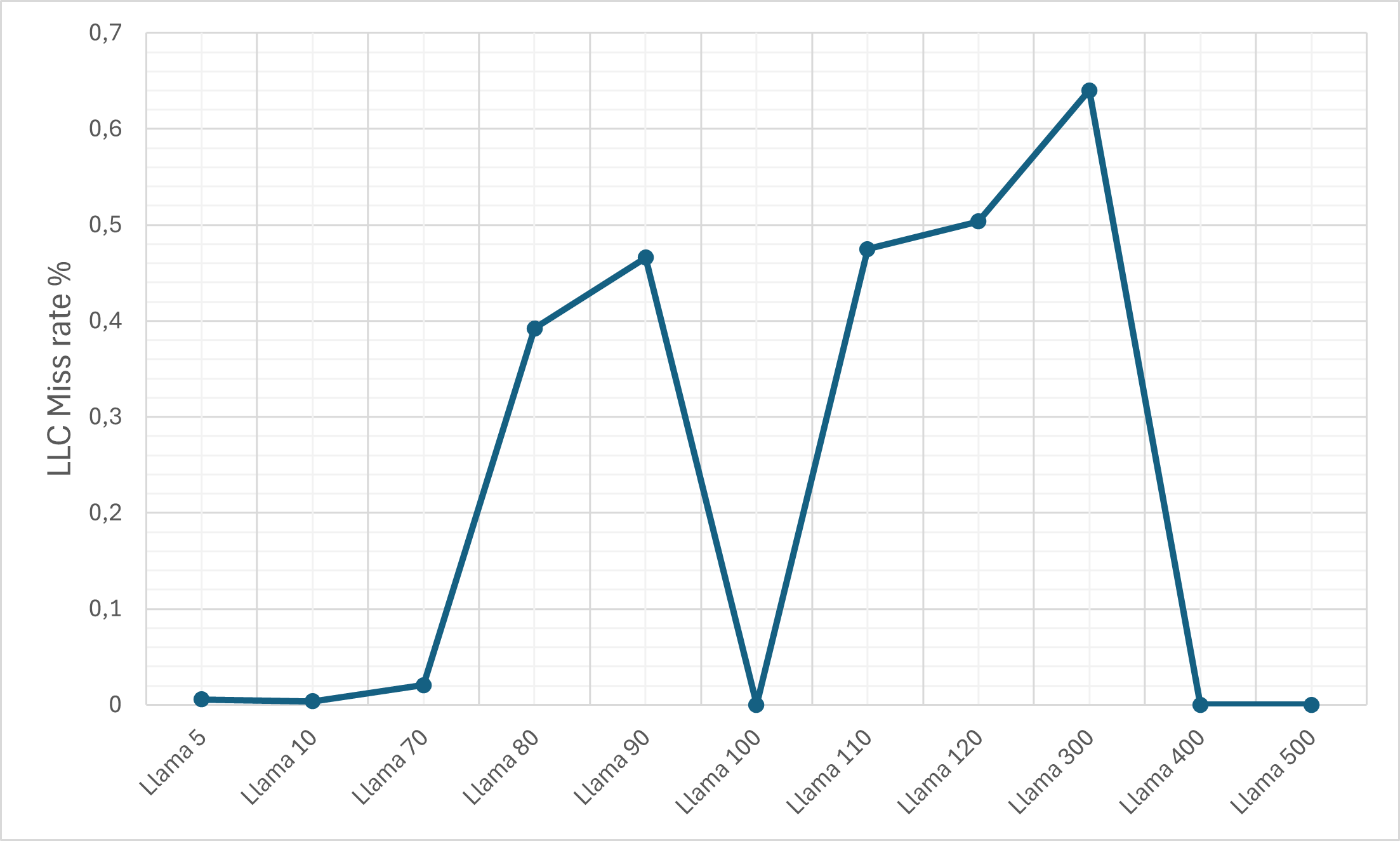
Figure 9: The L1d cache miss rate on the M1 machine for the plain LLaMA-3 model.
Security Considerations
The RLWE-FHE layer is robust against input/context leakage, output reconstruction, and gradient exfiltration as long as ciphertexts are not decrypted server-side and side-channel mitigations are enforced. Training-stage poisoning remains in scope unless inputs are pre-validated, and black-box attacks such as model extraction and adversarial example crafting are not mitigated by FHE alone.
The system is quantum-attack-resistant by construction, as lattice-based FHE is not known to be efficiently breakable by any quantum algorithm.
Implications and Future Directions
This work demonstrates the empirical viability of multi-billion-parameter transformer inference over encrypted data in production-relevant timeframes at only moderate accuracy and throughput degradation. The demonstrated architecture suggests several future AI security directions:
- Selective FHE Deployment: Targeting only the most critical attention layers for FHE evaluation may provide an optimal privacy-per-latency tradeoff for production LLM SaaS.
- End-to-End Privacy: When combined with differential privacy and input/output sanitization, the proposed PQC-LLaMA-3 model composes a robust foundation for deployment in adversarial or compliance-bound environments.
- Hardware-Accelerated FHE: Further gain would accrue from FPGA- or ASIC-based FHE primitives, amortizing programmable bootstrapping cost at scale.
- FHE Training: Current work is inference-only; scalable FHE training remains an open challenge.
Conclusion
The integration of lattice-based, post-quantum FHE into Llama-3’s inference pipeline achieves strong cryptographic privacy guarantees for user data and model parameters during inference, with empirical results confirming high text generation accuracy (up to 98%) and inference throughput (80 tokens/s) under realistic deployment conditions. The methodology enables practical deployment of LLMs in regulated settings, subject to explicit tradeoffs between security, computational cost, and model expressivity. Achieving FHE-secured LLM inference at scale will drive new research at the intersection of cryptography, hardware, and deep learning system design.