Enabling AI ASICs for Zero Knowledge Proof
Abstract: Zero-knowledge proof (ZKP) provers remain costly because multi-scalar multiplication (MSM) and number-theoretic transforms (NTTs) dominate runtime as they need significant computation. AI ASICs such as TPUs provide massive matrix throughput and SotA energy efficiency. We present MORPH, the first framework that reformulates ZKP kernels to match AI-ASIC execution. We introduce Big-T complexity, a hardware-aware complexity model that exposes heterogeneous bottlenecks and layout-transformation costs ignored by Big-O. Guided by this analysis, (1) at arithmetic level, MORPH develops an MXU-centric extended-RNS lazy reduction that converts high-precision modular arithmetic into dense low-precision GEMMs, eliminating all carry chains, and (2) at dataflow level, MORPH constructs a unified-sharding layout-stationary TPU Pippenger MSM and optimized 3/5-step NTT that avoid on-TPU shuffles to minimize costly memory reorganization. Implemented in JAX, MORPH enables TPUv6e8 to achieve up-to 10x higher throughput on NTT and comparable throughput on MSM than GZKP. Our code: https://github.com/EfficientPPML/MORPH.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Guide to “Enabling AI ASICs for Zero Knowledge Proof”
1) What is this paper about?
This paper is about making a special kind of proof (called a zero-knowledge proof, or ZKP) much faster and more energy‑efficient by running it on AI chips like Google’s TPUs. ZKPs let someone prove they did a computation correctly without revealing private details—very useful for privacy and blockchains—but creating (or “proving”) them is slow and expensive. The authors introduce MORPH, a way to “reshape” the hardest parts of ZKPs so they fit the strengths of AI chips, which are really good at huge matrix math.
2) What questions were the researchers trying to answer?
The paper focuses on a few big questions:
- Can we turn the most time‑consuming ZKP tasks—MSM (multi‑scalar multiplication) and NTT (number‑theoretic transform)—into the kind of math (big, regular matrix operations) that AI chips love?
- How do we properly measure what’s slow on these chips? (Traditional “Big‑O” math doesn’t show hidden slowdowns caused by data rearrangement.)
- How can we avoid costly “data shuffles” (reorganizing data in memory) that make fast chips wait around?
- Can we redesign these tasks so they run faster in practice, not just in theory?
3) How did they tackle the problem?
The authors use two main ideas: a better way to think about hardware limits and clever rewrites of the math and data movement.
- A new way to measure performance: Big‑T
- Big‑O tells you how work grows with problem size, but it ignores how real hardware behaves.
- Big‑T looks at the slowest part of the chip (like the biggest traffic jam) and also counts the cost of rearranging data in memory, which often dominates on AI chips.
- Think of it like this: If your team is fast but your supplies are poorly organized, you still work slowly. Big‑T counts both the team speed and the “finding stuff” time.
- Arithmetic rewrite: turn big‑number math into matrix math
- ZKPs need math with huge numbers where normal 32‑bit hardware struggles. Traditional methods split big numbers into chunks and carry “borrows,” which causes lots of tiny, scattered operations—very slow on TPUs.
- MORPH uses a trick called RNS (Residue Number System) in a larger “helper” number space so big multiplications become many small, independent 32‑bit multiplications—perfect for AI chips.
- Then, they perform the “reduce back to the original prime field” step using low‑precision matrix multiplications, pushing work onto the TPU’s matrix engine (the MXU). This removes slow carry chains and replaces them with fast, regular matrix ops.
- Dataflow rewrite: arrange the work so the chip doesn’t waste time shuffling data
- MSM (multi‑scalar multiplication): The standard “Pippenger” method sorts and groups points in tricky ways that cause lots of communication and reshuffling on AI chips.
- MORPH’s LS‑PPG (Layout‑Stationary Pippenger) keeps the data layout fixed and splits work across devices so that each chip handles an independent chunk. This avoids cross‑chip talk and on‑chip reshuffles.
- It also merges stages so once data is sorted, it’s used immediately—no extra trips to off‑chip memory.
- NTT (number‑theoretic transform): The classic “butterfly” method does many tiny reorders (like constantly re‑sorting socks), which is slow on TPUs.
- A newer “3‑step NTT” avoids shuffles by turning the problem into matrix multiplications, but it can still be heavy for very large sizes.
- MORPH’s “5‑step NTT” breaks the problem into even smaller, balanced pieces, keeping matrix units busy while reducing memory overhead and avoiding out‑of‑memory issues.
In short: MORPH turns awkward, high‑precision math into dense matrix operations and avoids wasteful data rearrangements, matching what AI chips do best.
4) What did they find, and why is it important?
- Faster NTTs and competitive MSMs on TPUs:
- Up to 10× higher throughput on NTT compared to a strong GPU baseline.
- Similar or better MSM speed (about 1.2×) compared to a leading GPU system.
- Big‑T revealed hidden bottlenecks that Big‑O misses—especially the cost of moving data around—so they focused on fixes that mattered in real hardware.
- By eliminating “carry chains” and minimizing shuffles, they got much better use out of the TPU’s matrix engine and vectors.
Why this matters:
- Faster provers mean cheaper, more practical zero‑knowledge systems.
- This helps privacy‑preserving apps, scalable blockchains, and verifiable computing (checking results quickly).
- It shows a general strategy for mapping complex math to modern AI chips, possibly helping other fields that use big‑number arithmetic.
5) What’s the big picture impact?
MORPH shows that:
- With the right redesign, AI chips built for machine learning can also accelerate advanced cryptography.
- Measuring the “true cost” (with Big‑T) leads to smarter designs that avoid slow data rearrangements.
- This could make privacy and security tools more accessible, lowering costs and reducing energy use.
In everyday terms: The authors reorganized the hardest parts of ZKPs so they look like the kind of tasks AI chips already do extremely well. They also created a better way to spot what’s actually slowing things down. Together, these changes make zero‑knowledge proofs faster and more practical for real‑world use.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each item highlights what is missing, uncertain, or unexplored, to guide future research.
- Big‑T model validation and fidelity: The paper introduces Big‑T but does not empirically validate it against detailed traces or roofline models, nor quantify how well it predicts bottlenecks across kernels and hardware generations; calibration methodology and sensitivity to per‑unit pipeline occupancy, contention, and compiler scheduling are missing.
- Scope of Big‑T: The model abstracts “Mem” and “XLU” costs coarsely; it does not detail how to parameterize layout transformations at sub‑VReg granularity, nor how to integrate overlapping compute/memory pipelines or inter‑device communication costs into T(N).
- Generality of Big‑T beyond TPUs: It is unclear how to instantiate Big‑T for other AI ASICs (e.g., AWS Trainium, NVIDIA/Hopper tensor cores, AMD matrix cores); mapping units and tiling constraints to Wk/Pk and XLUs requires a procedure that is not provided.
- RNS base selection and bounds: The paper lacks a concrete method for choosing the RNS moduli sets, bitwidths, and counts (q_i, p_j) across different prime sizes (256/377/753 bits) to guarantee no overflow under full MSM/NTT pipelines; worst‑case bounds (e.g., in long chains of PADDs) are not derived.
- Correctness of “lazy” reduction end‑to‑end: Formal proofs and tight bounds ensuring that extended‑field RNS with deferred reduction remains correct and within bounds across entire MSM/NTT executions are not provided (including parameter choices for w, u and the maximum number of additions between reductions).
- Exactness on TPU int8 MXUs: The approach relies on uint8/bf16 MXUs, but TPUs primarily expose signed int8; the paper does not explain signed/unsigned mappings, accumulator ranges, or how it ensures exact (non‑saturating) arithmetic for byte‑decomposed matrices under all inputs.
- Parameter precomputation costs: Storage, time, and amortization of precomputed objects (e.g., E matrices, f, g, twiddles) are not quantified; guidance on reuse across proofs and memory footprints at large scales is missing.
- Memory capacity constraints: Doubling state due to extended RNS and additional parameter tensors may cause OOM for large N; thresholds at which 3‑step or 5‑step NTT, or LS‑PPG, exceed TPU HBM capacity are not characterized.
- Auto‑tuning for 5‑step NTT: There is no method to choose (R1, R2, C) optimally under MXU tile constraints, HBM capacity, and interconnect topology; performance sensitivity plots and decision heuristics for when to use 3‑step vs. 5‑step are absent.
- Twiddle factor generation and storage: The paper does not quantify memory/compute costs to generate, store, and distribute twiddles for large N and multiple moduli, nor how 5‑step reduces these in practice and where the break‑even points occur.
- Handling non‑ideal shapes: Padding/tiling overheads when N (or digit counts) are not multiples of MXU‑preferred tiles (e.g., 8×128×128) are not analyzed; the impact of under‑utilization on throughput is unclear.
- MSM presorting practicality: “argsort(I_k)” and bucketization costs are not modeled in Big‑T nor broken down experimentally; whether sorting runs on TPU vs. host CPU, and the data‑transfer overheads and pipeline overlap, are left unspecified.
- Inter‑device scaling and reductions: LS‑PPG claims to avoid inter‑TPU communication during presorting/BA, but global reductions (e.g., window merges or final MSM accumulation) will require cross‑device communication; the associated costs and scaling behavior are not evaluated.
- Load imbalance in buckets: Using N′ (max bucket size) to shape BA may induce wasted compute for skewed distributions; load‑balancing strategies, dynamic scheduling, or overflow/spill handling are not discussed.
- Security/side‑channel considerations: Presorting and bucketization are data‑dependent; the paper does not analyze timing/memory‑access side‑channels on shared TPUs nor propose constant‑time or oblivious variants.
- Curve and field generality: The approach is validated only on selected primes and Twisted Edwards points; support for common pairing‑friendly curves (e.g., BLS12‑381, BN254) with their preferred coordinate systems and endomorphisms is not demonstrated.
- Completeness of arithmetic coverage: The work focuses on modular multiplication; treatments for other critical operations (inversion, modular reduction corner cases, conditional subtraction, equality/compare in RNS) are not detailed.
- NTT variants in real provers: Many provers require inverse NTTs, coset NTTs, and CRT across multiple moduli; how 5‑step integrates with these (including twiddle/sign conventions and memory reuse) is not explored.
- End‑to‑end prover impact: The paper reports kernel‑level speedups but does not present end‑to‑end proof generation time, overlap of data marshaling CPU↔TPU, or JIT/compile overheads in JAX; net wall‑clock benefits under realistic pipelines remain uncertain.
- Benchmark coverage and fairness: Comparisons are primarily against V100 and GZKP; there is no head‑to‑head against A100/H100, recent GPU/ASIC MSM/NTT implementations, or other AI ASICs at matched power and cost.
- Energy efficiency and cost: Despite efficiency claims, the paper does not report energy per operation/proof or cost per proof; practical deployment trade‑offs versus GPUs/FPGAs remain unquantified.
- Numerical exactness testing: While the math is exact, the implementation uses byte decomposition and low‑precision MXUs; there is no published test suite proving bit‑for‑bit agreement across all supported primes/curves and N for both MSM and NTT.
- Robustness to compiler/runtime effects: JAX/XLA scheduling can change tiling, fusion, and memory placement; the sensitivity of Big‑T predictions and performance to compiler choices and version changes is not examined.
- Portability of arithmetic/dataflow ideas: It is unclear how MXU‑centric RNS lazy reduction and LS‑PPG/5‑step NTT translate to non‑TPU matrix engines (e.g., different tile sizes, data types, or lack of XLU‑like units); generalized recipes are lacking.
- Decision boundaries for algorithm choice: Clear criteria for when butterfly, 3‑step, or 5‑step NTT is best (given N, memory, interconnect, and device counts), or when presorting Pippenger vs. alternatives (e.g., bucket methods without global sort) is favored, are not provided.
Practical Applications
Practical Applications of “Enabling AI ASICs for Zero Knowledge Proof”
This paper introduces MORPH, a framework that reformulates ZKP kernels (MSM and NTT) for AI ASICs (e.g., Google TPUs), backed by a hardware-aware Big‑T complexity model, an MXU‑centric RNS lazy reduction for prime-field modular arithmetic, and layout-stationary dataflows (LS‑PPG for MSM, 5‑step NTT). Below are actionable applications grouped by deployment horizon.
Immediate Applications
- TPU-based Proving-as-a-Service (PaaS)
- Sectors: finance/web3, cloud computing, software infrastructure
- What: Deploy MORPH on cloud TPUs to offer high-throughput ZKP proving (up to 10× NTT speedup; MSM parity vs. state-of-the-art GPUs), lowering cost/latency for zk-rollups, zkEVMs, and zk‑oracles.
- Tools/workflows: JAX-based MORPH kernels; managed TPU clusters; CI pipelines that batch proofs and schedule (R,C,R1,R2) choices for 5-step NTT; observability via XProf.
- Assumptions/dependencies: Access to TPUv5e/v6e or equivalent AI ASICs; supported field sizes (e.g., 256/377/753 bits); integration with existing provers (e.g., Groth16/Plonk/Plonky2/arkworks/gnark); witness confidentiality handled operationally.
- Drop-in Acceleration for zk-Rollups and Bridges
- Sectors: blockchain/L2s, cross-chain infrastructure
- What: Replace GPU kernels with MORPH for MSM/NTT in proof pipelines to reduce proving time and energy per transaction; enables higher TPS and lower fees.
- Tools/workflows: Glue code for Halo2/Plonkish pipelines; JIT compilation via XLA; bucketizer ops for LS-PPG; twiddle-factor management for 5-step NTT.
- Assumptions/dependencies: Network I/O and sequencer/oracle bottlenecks don’t dominate; stable twiddle precomputation storage; field compatibility with target curves (e.g., BLS12-381, BN254).
- Verifiable Off-chain Compute for Oracles and Data Feeds
- Sectors: fintech/oracles, DeFi, real-time analytics
- What: Faster proof generation for attestations (e.g., price-feed, weather, credit-score proofs) reduces settlement delays and oracle congestion.
- Tools/workflows: Oracle nodes with TPU-backed proof workers; proof batching and automatic window/NTT sizing per feed.
- Assumptions/dependencies: SLA alignment (latency budgets); network peering and proof-size compression remain standard-compliant.
- ZK-ML Inference Proofs (small-to-mid scale)
- Sectors: AI/ML, security, marketplaces for models
- What: Speed up NTT-heavy polynomial commitments in zk‑ML circuits (e.g., verifying inference correctness) to reduce proof latency for moderately sized models.
- Tools/workflows: Circuit compilers targeting MORPH NTT; model-to-circuit pipelines; JAX front-ends for consistent kernels.
- Assumptions/dependencies: Circuit sizes that fit MXU/VPU tiling; model weights/witness privacy handled out-of-band.
- Energy/Cost Optimization for Proof Generation
- Sectors: sustainability, cloud economics, web3 operations
- What: Leverage AI ASIC energy efficiency per operation (matrix-heavy kernels on MXU) to cut TCO for rollups and proving clusters.
- Tools/workflows: Cost-aware proof schedulers; autoscaling policies; on/off-peak TPU utilization (spot/preemptible).
- Assumptions/dependencies: Accurate cost modeling and utilization; minimal inter-TPU communication (as per LS-PPG).
- Big‑T–Guided Kernel Design and Performance Engineering
- Sectors: HPC, software tooling, academia
- What: Use Big‑T complexity to diagnose bottlenecks (compute/span vs. layout) and guide algorithm selection/tiling on heterogeneous AI ASICs.
- Tools/workflows: Performance guide and checklists; Big‑T annotations in kernel libraries; profiling templates aligned with MXU/VPU/XLU spans.
- Assumptions/dependencies: Team familiarity with MXU/VPU constraints; introspection via JAX/XLA profiles.
- Integration into Existing ZKP Libraries
- Sectors: cryptography software, OSS ecosystems
- What: Bindings from MORPH to arkworks, gnark, Halo2 backends, Plonky2; selective substitution of MSM/NTT kernels.
- Tools/workflows: FFI adapters; curve/field adapters; continuous verification tests for correctness across lazy reduction boundaries.
- Assumptions/dependencies: Maintenance of cross-language/runtime bridges; precise mapping of prime fields to extended RNS configs.
- Education and Training
- Sectors: academia, professional training
- What: Use MORPH and Big‑T to teach heterogeneous computing for cryptography; lab modules showing speed/energy tradeoffs.
- Tools/workflows: Course labs with JAX kernels, profiling tasks; reproducible notebooks.
- Assumptions/dependencies: Classroom/cloud TPU availability; familiarity with ZKP arithmetic.
- Privacy-Preserving Identity/Access Proofs with Lower Latency
- Sectors: identity, compliance, consumer fintech
- What: Accelerate proofs for age/credential/attribute disclosure (commit-and-prove) to support snappier user experiences.
- Tools/workflows: Service endpoints calling TPU-backed provers; batched proof issuance for login bursts.
- Assumptions/dependencies: Protocols use MSM/NTT-heavy schemes; trust and handling of sensitive witness data in cloud.
- Cloud Provider Productization
- Sectors: cloud platforms
- What: New TPU SKUs tuned for ZKP workloads (preloaded kernels; quotas; billing models); dashboards exposing Big‑T metrics.
- Tools/workflows: Prebuilt images; MORPH SDK; ops runbooks for proof pipelines.
- Assumptions/dependencies: Sufficient demand; support commitments; security reviews for cryptographic workloads.
Long-Term Applications
- Real-time zk-Rollups and Sub-Second Settlement
- Sectors: blockchain/L2s, exchanges
- What: With further MSM speedups and cluster scaling, push end-to-end proof latencies to sub-second for high-throughput rollups and DEX settlement.
- Tools/products: TPU clusters with MORPH v2 (more aggressive LS‑PPG and 5‑step factorization strategies); smarter schedulers to coalesce proofs.
- Assumptions/dependencies: Network, sequencer, and data-availability bottlenecks are addressed; coordination with protocol design.
- ZK-Backed Financial Compliance and Auditing at Scale
- Sectors: finance, auditing, regtech
- What: Faster generation of proofs for reserves, risk, AML/KYC attestations; routine, on-demand ZK attestations integrated into reporting workflows.
- Tools/products: Enterprise “ZK compliance nodes” with accelerated proving; APIs connecting core banking systems to provers.
- Assumptions/dependencies: Regulator acceptance of ZK standards; interoperability and auditability; stable cryptographic parameters.
- Privacy-Preserving Healthcare Analytics with Verifiable Computation
- Sectors: healthcare, biomedicine
- What: ZK proofs of analytic results over sensitive medical/genomic data without exposing raw data, enabling shared insights across institutions.
- Tools/products: Middleware that converts analytic queries to circuits and dispatches to AI‑ASIC provers; compliance logging.
- Assumptions/dependencies: Circuit design for relevant workflows; robust witness protection; HIPAA/GDPR-aligned deployments.
- Verifiable Federated Learning (zk‑FL)
- Sectors: AI/ML, edge computing
- What: ZK proofs for aggregation correctness and policy compliance in federated training; detect malicious participants.
- Tools/products: Aggregation servers with MORPH‑accelerated proof backends; integration with FL frameworks.
- Assumptions/dependencies: Circuit expressiveness vs. overhead; bandwidth for model updates vs. proof generation.
- Hardware/Architecture Co-Design for AI‑ASICs
- Sectors: semiconductor, systems research
- What: Influence next-gen AI ASICs to support MXU-friendly integer ops, better XLU for fine-grained permutations, and native RNS assistance.
- Tools/products: Big‑T–driven co-design studies; RTL/IP for layout transformations; benchmarking suites for cryptographic kernels.
- Assumptions/dependencies: Vendor adoption; market size for ZK+AI ASIC convergence; validation of security/side-channel properties.
- Compiler/Auto-Scheduler Frameworks for Heterogeneous Cryptography
- Sectors: software toolchains, compilers
- What: Big‑T–aware compilers that automatically refactor arithmetic/dataflow (e.g., extended RNS, 5‑step NTT) for target AI ASICs.
- Tools/products: XLA/MLIR passes for ZK; autotuners choosing (R,C,R1,R2) to maximize MXU utilization while minimizing memory span.
- Assumptions/dependencies: Stable IRs for crypto kernels; formal verification of transformations.
- Standardization and Policy for ZK Performance/Energy Reporting
- Sectors: policy, sustainability, standards bodies
- What: Introduce Big‑T–style metrics in procurement and sustainability reporting (proofs per Joule, MXU/VPU/XLU spans) to align industry benchmarks.
- Tools/products: Open benchmarks for ZK provers on AI ASICs; whitepapers informing regulators.
- Assumptions/dependencies: Industry consensus; transparent reporting across vendors.
- Consumer Apps with Near-Instant ZK Proofs
- Sectors: consumer fintech, gaming, identity
- What: Rapid proof generation enables private micropayments, in-game asset proofs, and seamless credential checks.
- Tools/products: SDKs for mobile/web clients to delegate proving to edge/cloud TPU endpoints; caching/batching patterns.
- Assumptions/dependencies: UX design for proof delegation; privacy guarantees for witness data in managed services.
- Cross-Domain Crypto Acceleration (FHE/HE + ZK Hybrids)
- Sectors: privacy tech, research
- What: Adapt 5‑step/layout-invariant NTT concepts to homomorphic encryption (where NTT is ubiquitous) and explore ZK–FHE hybrids for complex workflows.
- Tools/products: Unified kernels for HE NTTs; pipeline orchestration for hybrid protocols.
- Assumptions/dependencies: Parameter alignment (moduli, ring sizes); numerical stability/security proofs for adapted kernels.
- End-to-End ZK Pipelines Co-scheduled with ML Inference/Training
- Sectors: cloud/AI platforms
- What: Multi-tenant clusters where TPUs switch between ML workloads and ZK proving using MORPH kernels to monetize idle capacity.
- Tools/products: Schedulers with Big‑T cost models; priority policies; isolation and QoS controls.
- Assumptions/dependencies: Fair-scheduling and isolation; measurable interference bounds; customer appetite for mixed workloads.
Notes on Feasibility, Assumptions, and Dependencies
- Hardware availability: Benefits assume access to AI ASICs with MXU/VPU-like units and high VReg bandwidth (e.g., TPUv5e/v6e). Porting to other AI ASICs (e.g., Trainium) requires matching MXU/tiling capabilities.
- Algorithm-protocol fit: Gains apply when MSM/NTT dominate proving (common in Groth16/Plonkish). Curves/fields must be supported by the extended RNS design and lazy reduction (final-correctness reductions must be performed as specified).
- Dataflow/tiling: Speedups depend on mapping sizes (N, R, C, R1, R2) to MXU-friendly shapes and avoiding XLU-bound layouts. Very small problems may not amortize layout costs; extremely large problems must fit within memory/parameter budgets (5‑step helps).
- Software stack: Current implementation is in JAX; production systems may need hardened kernels (C++/XLA custom calls) and integration with existing provers. Continuous testing is required to ensure correctness across arithmetic edge cases.
- Security and privacy: Provers process witnesses; operational controls (isolation, encryption at rest/in transit, access control) remain necessary in cloud deployments.
- Ecosystem integration: Real-world deployments must interoperate with existing tooling (arkworks, gnark, Halo2, Plonky2), orchestration (Kubernetes, Terraform), and monitoring (XProf, Perfetto).
These applications leverage MORPH’s core innovations: Big‑T complexity for bottleneck visibility, MXU‑centric RNS lazy reduction to remove carry chains and turn prime-field arithmetic into dense low‑precision GEMMs, LS‑PPG to eliminate costly re-sharding for MSM, and 5‑step NTT to reduce MXU/memory spans at scale.
Glossary
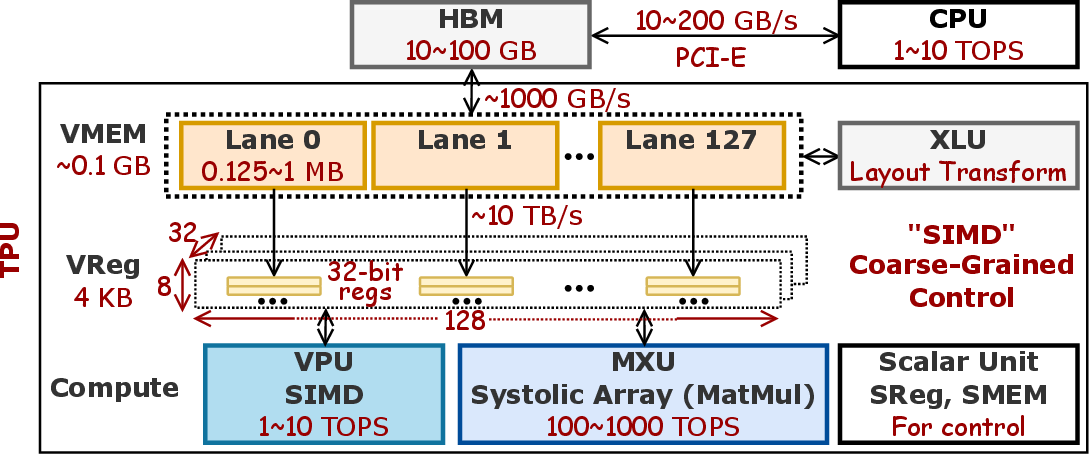
- AI ASICs: Application-specific integrated circuits optimized for AI workloads, offering high compute density and energy efficiency. "AI ASICs such as TPUs provide massive matrix throughput and SotA energy efficiency."
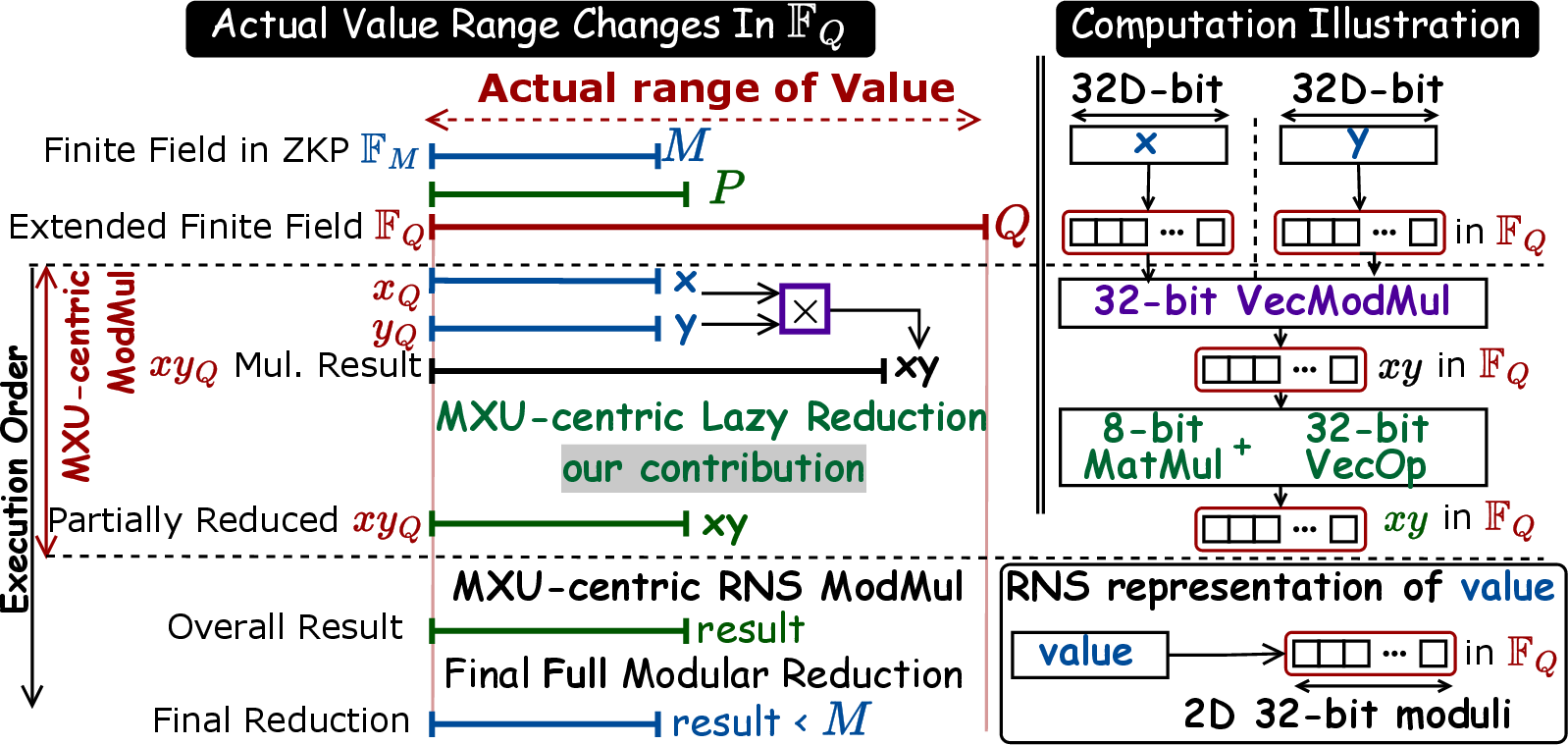
- Basis Aligned Transformation: A technique to align numeric bases so conversions and reductions can be implemented efficiently, e.g., via matrix multiplication. "We reduce this overhead by applying Basis Aligned Transformation~\cite{11408507} to Simonâs reduction~\cite{SimonRNS}"
- Big- complexity: A hardware-aware complexity model capturing heterogeneous compute pipelines and memory/layout costs, providing an asymptotic runtime bound on parallel devices. "We introduce Big- complexity, a hardware-aware complexity model that exposes heterogeneous bottlenecks and layout-transformation costs ignored by Big-."
- Bucket Accumulation (BA): MSM phase that sums all points within each bucket for a given window. "Bucket Accumulation (BA) All points inside each bucket are summed:"
- Bucket Reduction (BR): MSM phase that combines bucket sums into a window result, effectively weighting by bucket index. "Bucket Reduction (BR) The weighted sum for the window is computed: ."
- Butterfly NTT: The standard Cooley–Tukey style NTT implementation with minimal arithmetic complexity but substantial data shuffling. "Butterfly NTT and \textbf{layout invariant 3-step NTT}."
- Chinese Remainder Theorem (CRT): Theorem enabling reconstruction of integers from residues; used for conversions between RNS and standard representations. "Note: we refer to \cite{SimonRNS} for details of ."
- Cooley-Tukey NTT: Decomposition-based algorithm for NTT/FFT using recursive factorization into smaller transforms. "SotA NTT acceleration ... implements recursive Cooley-Tukey NTT with minimal computation complexity , commonly called as ``butterfly NTT\""
- GEMM: General matrix–matrix multiplication; a dense linear algebra primitive used to accelerate modular arithmetic here. "converts high-precision modular arithmetic into dense low-precision GEMMs, eliminating all carry chains,"
- HBM: High Bandwidth Memory, an off-chip memory technology providing high throughput but still lower than on-chip bandwidth. "HBM and the host CPU serve as the off-chip data sources, but their bandwidth is typically an order of magnitude lower than on-chip VReg bandwidth."
- Layout Transformation Unit (XLU): TPU unit that performs shuffles, transposes, broadcasts, and reductions at VReg granularity. "XLU performs shuffles, transposes, broadcasts, and reductions of VRegs."
- Layout-invariant 3-step NTT: An NTT formulation mapping to matrix ops that avoids on-chip shuffles, trading arithmetic for layout efficiency. "Recent TPU work~\cite{11408507} proposes a layout-invariant 3-step NTT achieving arithmetic with zero layout transformation,"
- Layout-Stationary Pippenger (LS-PPG): A dataflow for MSM that keeps data layout consistent across stages to avoid communication and reshaping. "MORPH introduces Layout-Stationary Pippenger (LS-PPG), which enforces a common sharding and layout across presorting and Bucket Accumulation (BA)"
- Matrix Multiplication Unit (MXU): TPU’s systolic array engine for high-throughput matrix multiplications (int8/bf16). "The MXU in TPUv4 is a large systolic array (128128) for int8 and bf16 matrix multiplication."
- Montgomery multiplication: A method for modular multiplication using a transformed representation to avoid expensive division. "For a value with 32-bit digits, radix- Montgomery multiplication requires"
- Montgomery reduction: The reduction step in Montgomery arithmetic that maps products back into the Montgomery residue class. "achieving up-to speedup over the SotA radix decomposed Montgomery reduction."
- Multi-Scalar Multiplication (MSM): Core elliptic-curve kernel computing a sum of scalar–point products, typically via windowing and bucketing. "Multi-Scalar Multiplication. MSM~\cite{groth2016size} computes "
- Number-Theoretic Transform (NTT): The finite-field analogue of the DFT, evaluating a polynomial at roots of unity. "Number Theory Transformation. NTT~\cite{groth2016size} converts a polynomial of degree into its frequency-domain representation"
- Pippenger (PPG): An MSM algorithm that groups points by scalar windows into buckets to reduce point additions. "Presorting Pippenger (PPG) - MSM In prior work of MSM acceleration on GPU \cite{ma2023gzkp, DistMSM}, FPGA \cite{CycloneMSM,PriorMSM,HardcamlMSM, pottier2025optimsm, ohno2025acceleratingellipticcurvepoint} and ASICs \cite{zhang2021pipezk, UniZK, SZKP, legoZK, gypsophila}, Presorting PPG is the SotA MSM algorithm."
- Point addition (PADD): Elliptic-curve group operation of adding two points; the basic primitive used heavily within MSM. "point addition (PADD, )."
- Primitive N-th root of unity: An element whose powers generate all N distinct Nth roots; basis of NTT. "where is a primitive -th root of unity."
- Residue Number System (RNS): Representation of integers by residues modulo pairwise-coprime moduli, enabling carry-free parallel arithmetic. "RNS represents an integer by residues over coprime moduli "
- Roofline analysis: A performance model relating arithmetic intensity to compute and memory ceilings to assess bottlenecks. "Further, Roofline analysis\cite{roofline_model} and trace-based profiling quantify how far execution is from hardware limits,"
- Systolic array: A regular, pipelined array of processing elements for high-throughput linear algebra, e.g., matrix multiplication. "The MXU in TPUv4 is a large systolic array (128128) for int8 and bf16 matrix multiplication."
- Tensor Processing Unit (TPU): Google’s AI accelerator architecture centered on VRegs, with VPU/MXU/XLU compute units. "The TPU~\cite{jouppi2023tpuv4opticallyreconfigurable} is Googleâs AI ASIC designed to accelerate machine learning training and inference with high energy efficiency."
- Twiddle factors: Precomputed powers of roots of unity used in FFT/NTT stages. "TF refers to twiddle factors, which are generated offline."
- Twisted Edwards curve: An elliptic-curve form enabling faster, more regular group operations. "offline converted into Twisted Edwards form to minimize compute overhead."
- Vector Processing Unit (VPU): TPU unit for 32-bit SIMD vector arithmetic over VRegs. "The VPU performs 32-bit SIMD arithmetic on VRegs."
- Vector Register (VReg): TPU-wide register abstraction consisting of 8×128 lanes used by all compute units. "All on-chip computation is organized around the Vector Register (VReg) abstraction."
- Work–span model: Parallel complexity model measuring total work and critical path length; here deemed inadequate for heterogeneous TPUs. "TPUâs heterogeneous compute units, each with different parallelism and tiling constraints, make classical models such as Big~ and the workâspan model inadequate."
- Zero-knowledge proof (ZKP): A cryptographic proof revealing no additional information beyond correctness; central to scalable verifiable computation. "Zero-knowledge proof (ZKP) provers remain costly because multi-scalar multiplication (MSM) and number-theoretic transforms (NTTs) dominate runtime"
Collections
Sign up for free to add this paper to one or more collections.