- The paper reveals a substantial modality gap, with text-only accuracy at 92.8% dropping to 12.4% for image-only inputs.
- It introduces the CrossMath benchmark, ensuring strict information symmetry across text, image, and multimodal conditions for rigorous assessment.
- Post-training with SFT and GRPO boosts visual reasoning from 3.20% to 50.40%, though a significant gap between modalities remains.
Evaluating Vision Reasoning in Vision-LLMs: A Rigorous Analysis of Modality Gaps
Introduction
This paper addresses the critical question of whether state-of-the-art Vision-LLMs (VLMs) truly perform vision-grounded reasoning or if their apparent success is largely reliant on the reasoning capabilities encoded in their language backbones. The authors introduce a meticulously controlled multimodal benchmark to examine modality-specific reasoning in a systematized manner. The investigation is set against a background where prior benchmarks inadequately disentangle vision and language contributions or fail to ensure information symmetry across modalities, thereby confounding conclusions about genuine visual reasoning in contemporary VLMs.
Benchmark Design and Experimental Setup
The cornerstone of the methodology is the construction of a benchmark task—here denoted as CrossMath—that enforces strict information alignment across three modalities: text-only, image-only, and image+text. Each instance in the benchmark encapsulates task-relevant information with semantic equivalence verified by human annotation, eliminating confounding factors such as incomplete or asymmetric modality representation.
The task involves solving 2D grid-based mathematical puzzles requiring multi-step spatial, geometric, and symbolic reasoning. The benchmark is procedurally generated, allowing for precise, stratified control over difficulty (by varying grid size, number of missing values, and operator complexity) and supporting both micro and macro accuracy as well as hop-based metrics for fine-grained analysis of reasoning depth.
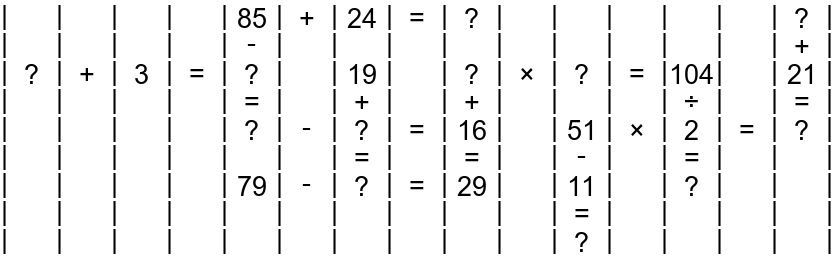
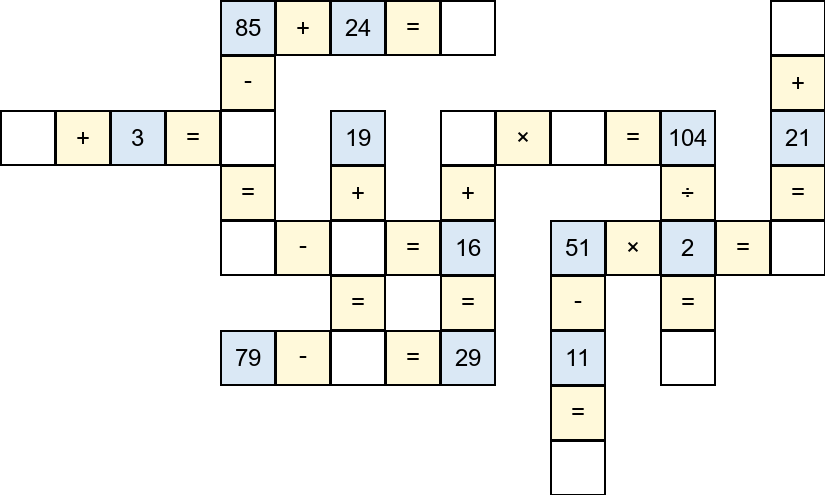
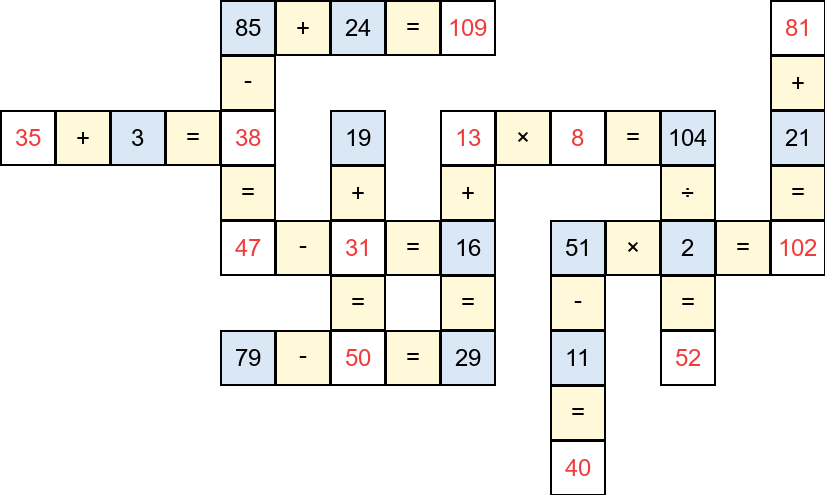
Figure 1: Example images of the CrossMath puzzle, including raw input, solution steps, and complete solutions highlighting targets in red (Left→Right).
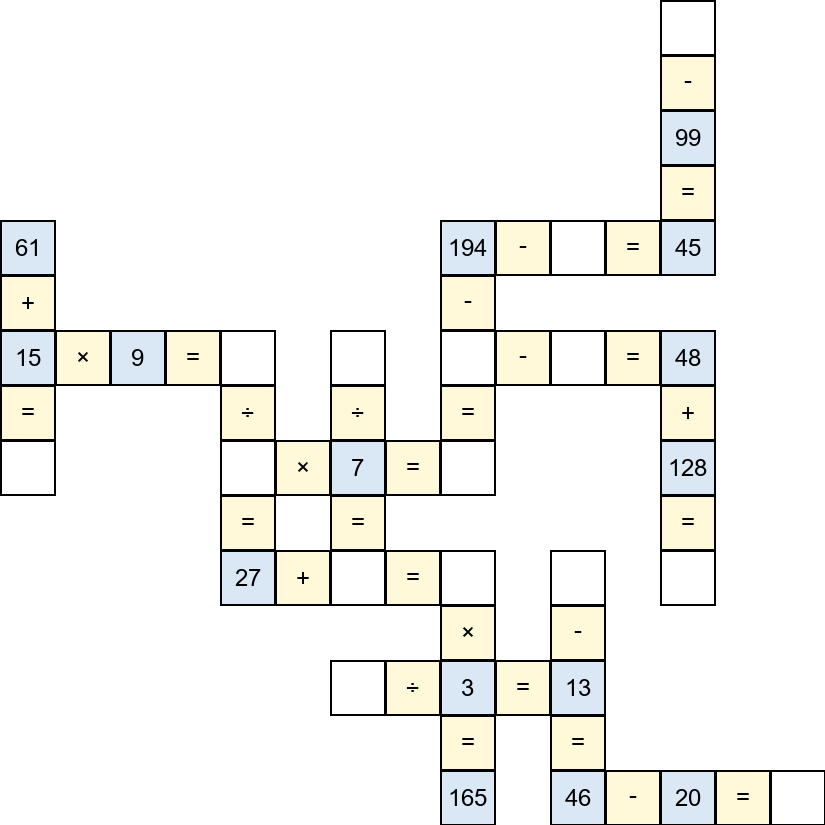

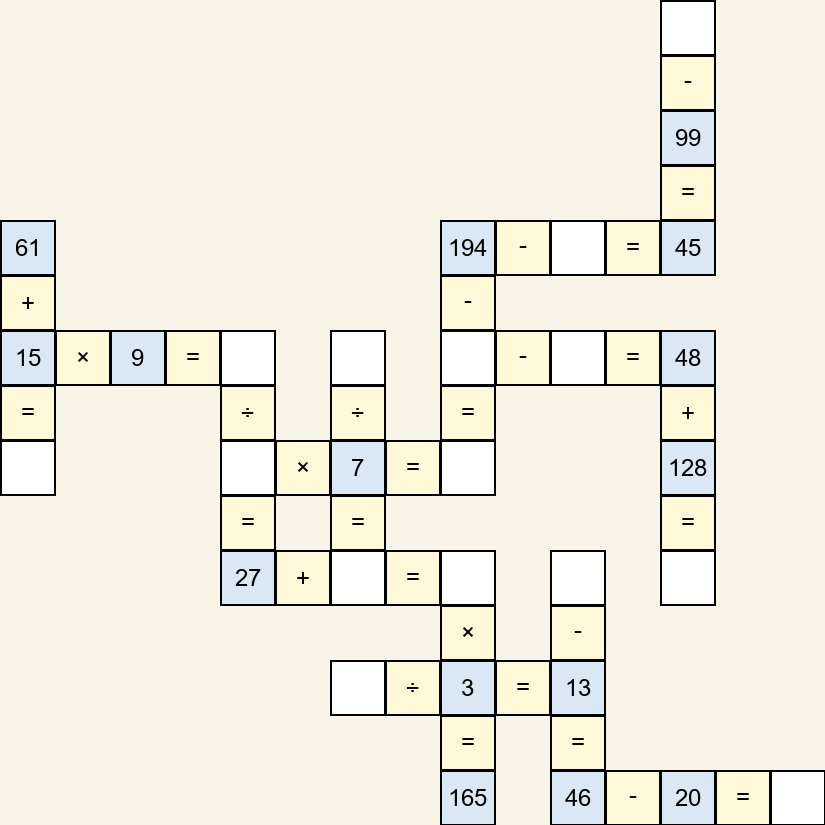
Figure 2: Example images for different vision formats—original, borderless, background-augmented, and color/font-altered—to evaluate the model’s robustness to visual perturbations.
Dataset construction follows an automated multi-step pipeline: (1) web-scraping and screenshot capture of grid puzzles, (2) conversion from images to structured Markdown via OCR and post-correction for information symmetry, (3) extraction of intermediate reasoning chains using a symbolic solver, and (4) extensive style augmentation to create visual permutations resilient to superficial variations.
Empirical Findings: The Modality Gap
Comprehensive evaluation on modern VLMs—including both open-source and proprietary Qwen models—reveals a consistent, substantial gap between text-only and image-based reasoning. When exposed to identical task information, VLMs deliver their strongest performance in text-only settings, with a drastic decline in both micro and macro accuracy when visual information is introduced. Notably, multimodal (image+text) inputs often further degrade performance compared to the text-only baseline, even though they provide strictly redundant information.
This phenomenon is robust across all evaluated model sizes and architectures. For example, macro accuracy for Qwen3.5-Plus drops from 92.8% (text-only) to 12.4% (image-only), with similar trends observed for other variants. These results unequivocally demonstrate a modality-specific reasoning deficit: the models’ symbolic reasoning is hinged on language representations, and vision features are at best underutilized and at worst a source of spurious noise.
Analysis of Perceptual and Reasoning Bottlenecks
The paper demonstrates that this vision-language gap does not primarily stem from perception errors. VLMs reliably perform OCR and symbol recognition even under diverse style augmentations. The principal deficiency, instead, lies in transforming these low-level visual tokens into well-structured, multi-step reasoning trajectories—particularly as the number of reasoning hops increases.
This interpretation is further reinforced by the observation that accuracy inversely correlates with the number of logical hops required by the task, in both visual and textual settings. Models are capable of executing local reasoning but consistently fail to propagate logic across extended dependency chains, a limitation that is magnified with visual inputs.
Visual Robustness
Post-training variants subjected to extensive visual data augmentation manifest pronounced robustness to most superficial image perturbations (color, font, background), but performance degrades in the absence of grid borders. This suggests a reliance on explicit structural cues for spatial localization in reasoning, highlighting the need for improved spatial parsing mechanisms in future architectures.
Closing the Modality Gap: Post-Training Interventions
The authors propose and validate an effective remediation strategy comprising supervised fine-tuning (SFT) and reinforcement learning with Group Relative Policy Optimization (GRPO), based solely on image-based reasoning chains. Empirical evidence shows that such post-training substantially boosts visual reasoning accuracy. For instance, vision-only macro accuracy for Qwen3.5-9B improves from 3.20% (pre-training) to 50.40% (SFT+GRPO), with gains persisting under various visual style perturbations.
However, despite this substantial improvement, a clear performance gap remains between image-only and text-only modalities—suggesting that architectural constraints, rather than lack of in-domain examples, fundamentally limit visual reasoning in current VLMs.
Out-of-Domain Generalization and Theoretical Implications
Post-trained models also demonstrate improved zero-shot generalization on external multimodal benchmarks (e.g., MathVerse, MMMU), indicating a positive transfer for reasoning abilities across structurally related tasks.
These findings collectively point to the limitations of scale and pretraining-driven improvements for visual reasoning. While increasing language-model capacity enhances textual reasoning, it does not translate to better image-based logical inference, unless complemented by explicit visual reasoning supervision and potentially, architectural overhaul in modality fusion and cross-modal alignment.
Future Directions and Theoretical Considerations
The study’s rigorous experimental design and ablations lay the groundwork for advancing research in cross-modal reasoning. The residual gap between visual and textual reasoning—even after tailored post-training—raises important questions on:
- Vision encoder architectures: There is mounting evidence that current encoders insufficiently encode compositional, spatial, or geometric information necessary for deep reasoning.
- Cross-modal alignment: Reliance on simple projection layers is inadequate; more sophisticated alignment mechanisms and bidirectional fusion could ameliorate the integration of visual evidence into symbolic reasoning.
- Benchmark design and evaluation: Strict information matching and multi-hop, vision-first benchmarks are essential for exposing true multimodal reasoning capacity and benchmarking robust progress across architectures.
Conclusion
This work presents a systematic and rigorous evaluation of the modality gap in VLMs, demonstrating significant, persistent deficiencies in image-grounded reasoning even with access to state-of-the-art architectures and extensive training. Task-specific post-training narrows but does not close the gap, implicating fundamental architectural challenges rather than mere data scarcity. The findings prompt a paradigmatic shift toward the development of VLMs that can genuinely integrate and reason over vision and language, with implications spanning both practical applications in cross-modal tasks and theoretical understanding of multimodal intelligence.