- The paper introduces MedP-CLIP, which integrates feature-level region prompt conditioning to effectively align spatial image features with clinical text descriptions.
- It leverages a large-scale dataset of 97.3M region–text pairs to enable zero-shot classification, interactive segmentation, and region-level retrieval across diverse modalities.
- Performance gains, including up to +5.9% overall improvement and +3.52% on binary classification, demonstrate its superior precision in localized medical image analysis.
MedP-CLIP: A Region-Aware Medical Vision-LLM with Prompt Integration
Introduction and Motivation
Recent advances in contrastive language-image pre-training (CLIP) have facilitated significant improvements in zero-shot transfer, visual grounding, and multimodal reasoning. However, standard CLIP architectures and their domain-adapted counterparts (e.g., MedCLIP, BiomedCLIP, UniMed-CLIP) exhibit a critical deficiency for medical imaging: the lack of explicit region-aware representation. Given that diagnostic workflows rely fundamentally on precise, localized reasoning about anatomical structures and lesions, classical global encoders are inherently misaligned with clinical requirements. Attempts to introduce regional awareness—such as crop- or mask-based cues, alpha channel fusion (Alpha-CLIP), or complex task-specific multimodal pipelines—have suffered from loss of context, inflexibility, or poor scalability.
MedP-CLIP directly addresses this architectural and functional gap by implementing a feature-level region prompt integration mechanism, allowing for direct, plug-and-play conditioning on spatial prompts (points, boxes, masks) without sacrificing holistic global context. Leveraging a meticulously curated large-scale dataset of 97.3M region–text pairs covering diverse modalities and anatomies, MedP-CLIP serves as a unified, scalable backbone for medical AI, supporting zero-shot recognition, interactive segmentation, region-level retrieval, and multimodal LLM reasoning.
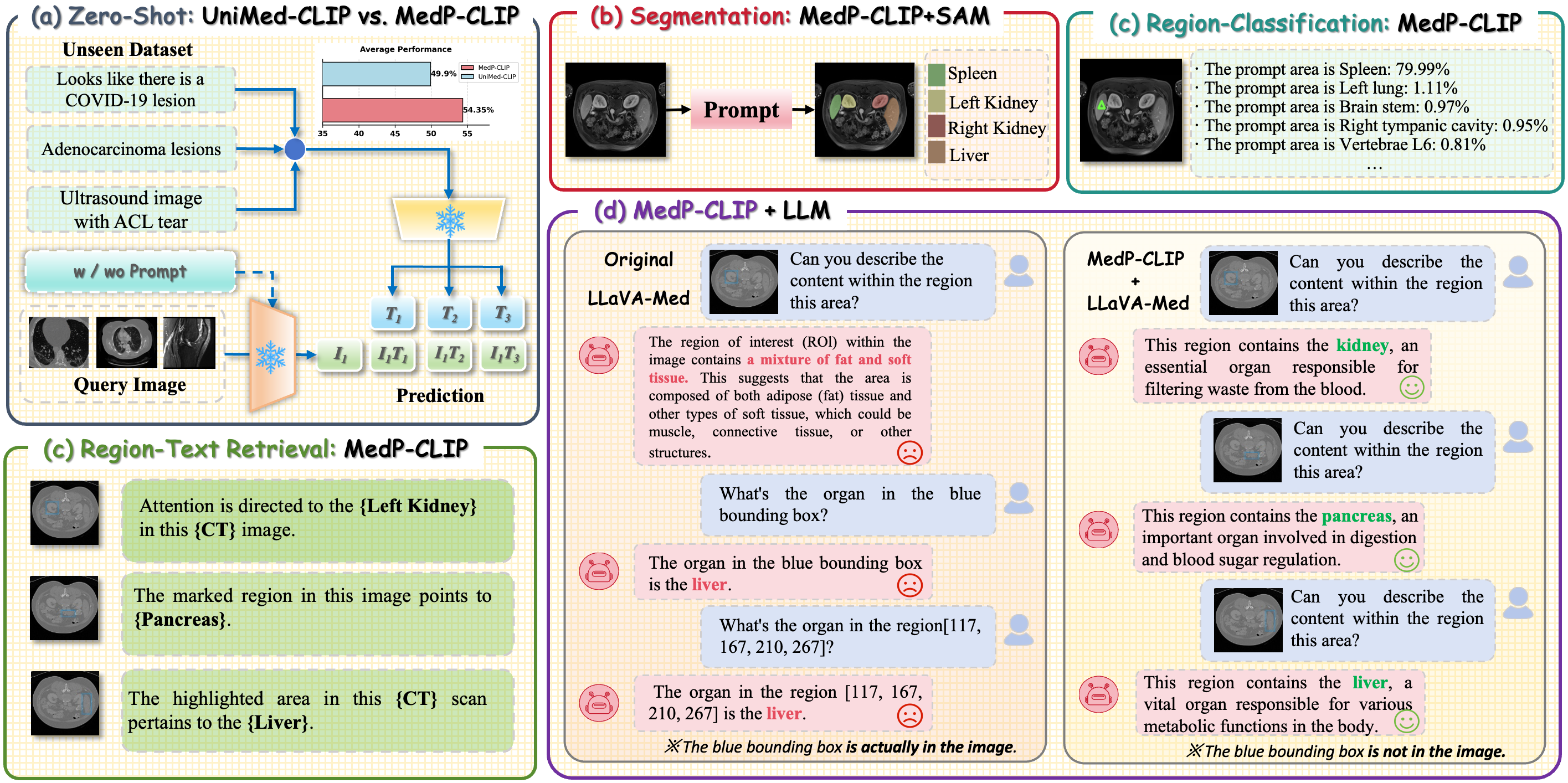
Figure 1: MedP-CLIP enables flexible downstream deployment: direct tasks, plug-and-play integration, and explicit/implicit prompt conditioning for region-aware medical image analysis.
Data Synthesis and Architecture
Region-Text Pair Generation
MedP-CLIP's backbone is a unique region-aware dataset derived from IMed-361M. For each medical image, pixel-level masks delineating anatomical/lesion regions are converted to multiple region-annotated samples. Each region is described using clinical narratives generated by GPT-4o, with strong ontology constraints based on RadLex Lexicon v4.1 to prevent hallucination and enforce anatomical and textual consistency. Additional multi-stage quality control, similarity clustering, and double-blind radiologist validation yield a dataset with high semantic validity and clinical fidelity.
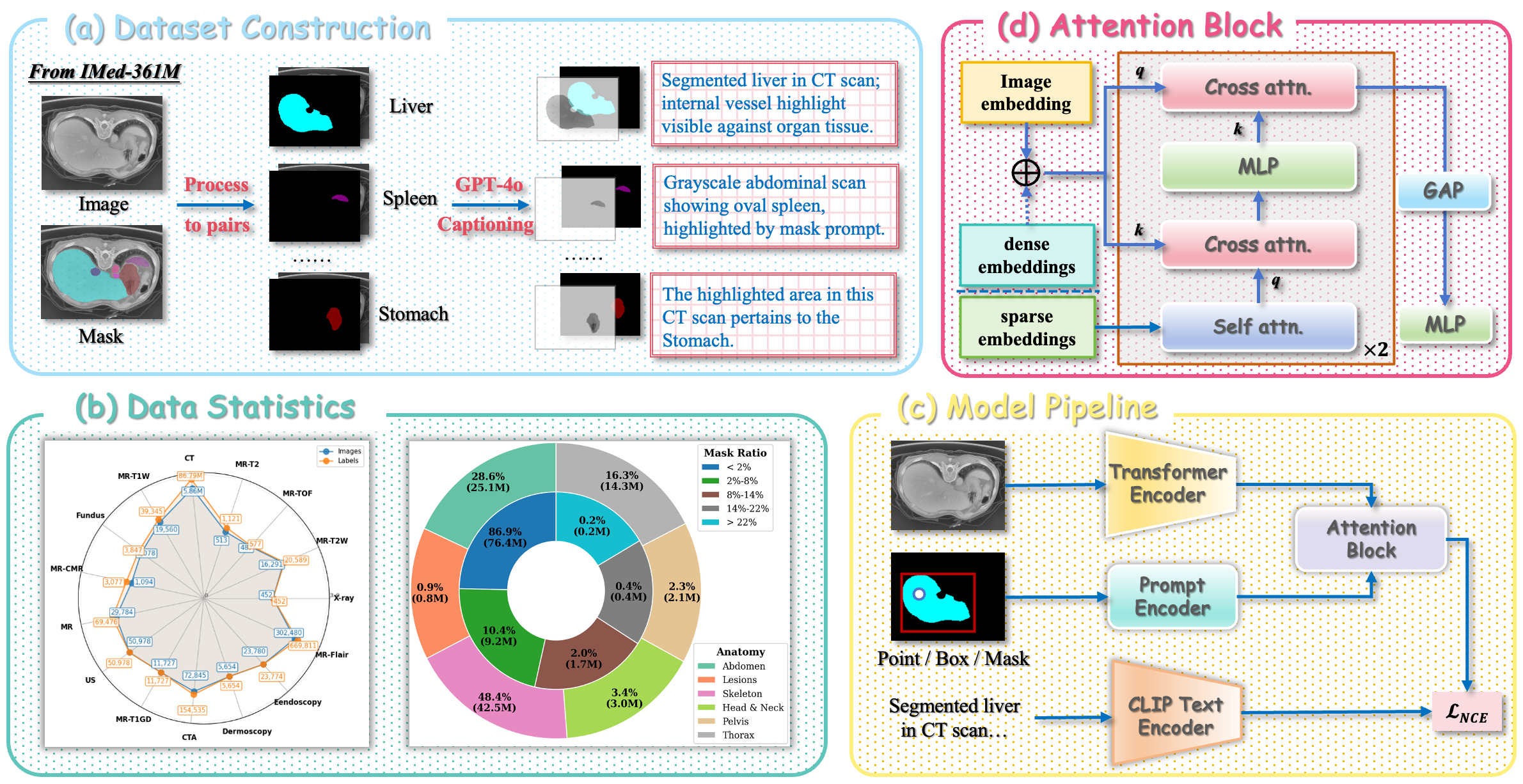
Figure 2: Overview of data pipeline, architecture, and training. Pixel-level masks → region-text pairs via GPT-4o (a), dataset statistics (b), ViT-based backbone and prompt encoder architecture (c), and cross/self-attention fusion module (d).
Notably, 86.9% of all regions occupy <2% of the image area, empirically highlighting the necessity for fine-grained local pre-training in medical contexts.
Network and Feature-Level Prompt Integration
MedP-CLIP retains CLIP's ViT backbone while introducing:
- A lightweight prompt encoder accepting points/boxes (sparse) and masks (dense)
- Feature-level fusion by cross/self-attention blocks integrating prompt, image, and text embeddings
- Decoupled training, where the model is exposed to randomized prompt types (including, with nonzero probability, the full image) to prevent overfitting to any single prompt format.
During pre-training, region-aware attention aligns visual features with region-specific text, and the model is explicitly optimized for robust reasoning under noisy, sparse, or ambiguous prompts.
Experimental Evaluation
Zero-Shot Image-Level Classification
On held-out evaluation datasets spanning multiple modalities and pathologies (COVID-CT, ACL, ChestCT, ACRIMA), MedP-CLIP consistently outperforms all prior global and region-aware SOTA models in mean top-1 accuracy, with particularly strong gains of +3.52% over GenMedCLIP on binary classification tasks. Qualitative analysis of attention maps reveals sharper and more discriminative localization of pathological regions with prompt conditioning, as opposed to the diffuse, semantically ambiguous focus of former baselines.
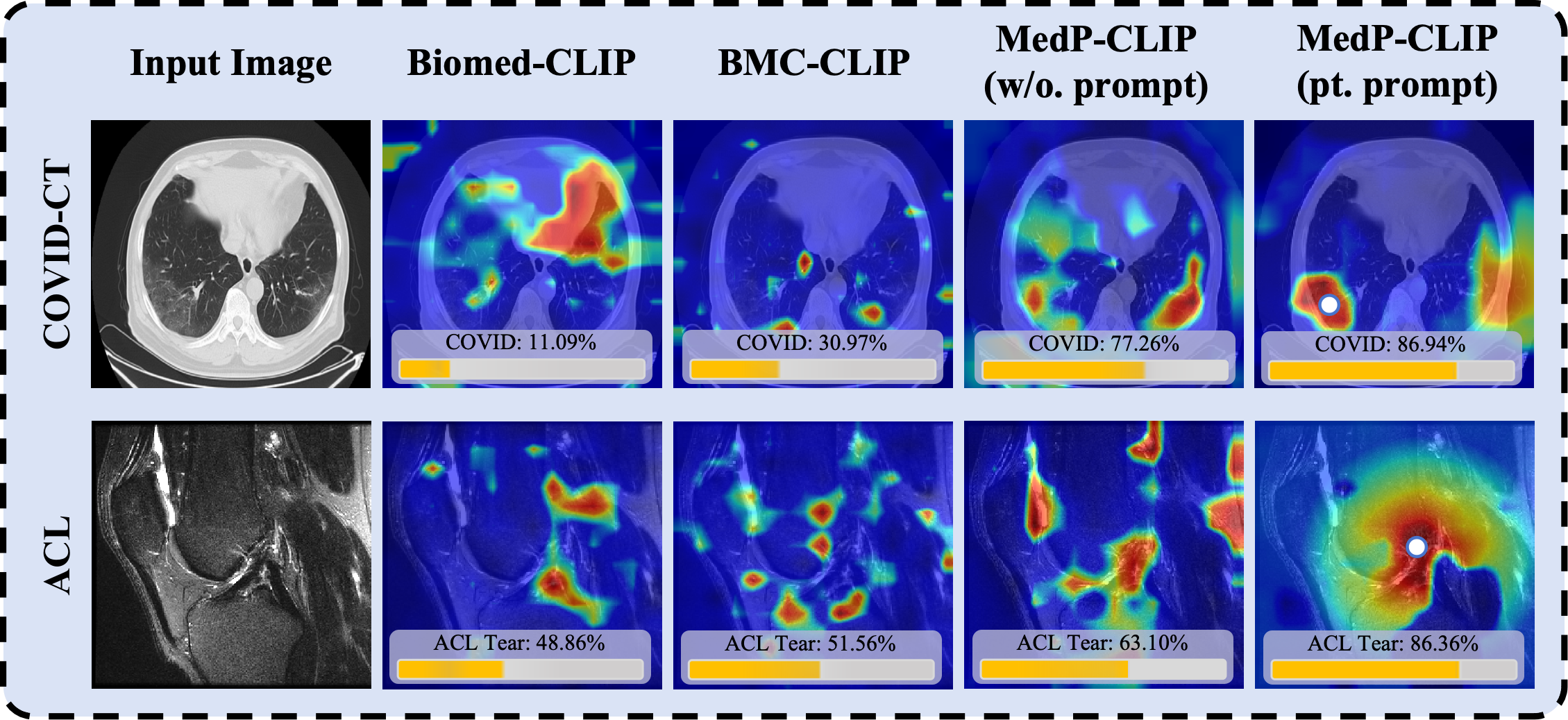
Figure 3: Qualitative comparison: MedP-CLIP exhibits highly precise and prompt-localized attention in zero-shot settings compared to prior models.
Region-Level Retrieval and Classification
MedP-CLIP achieves substantial improvements in region-level classification: for Br35H, point prompts yield 69.8% accuracy, bounding boxes 79.5% (outperforming GenMedCLIP, BMC-CLIP, and BiomedCLIP), and an ensemble with ViT-L/14 backbone reaches 92.4%. Multi-organ datasets confirm consistent superiority to Alpha-CLIP, especially when supplied with spatial context. Visualization indicates that prompt quality and specificity are directly correlated with discriminative power and text alignment confidence.
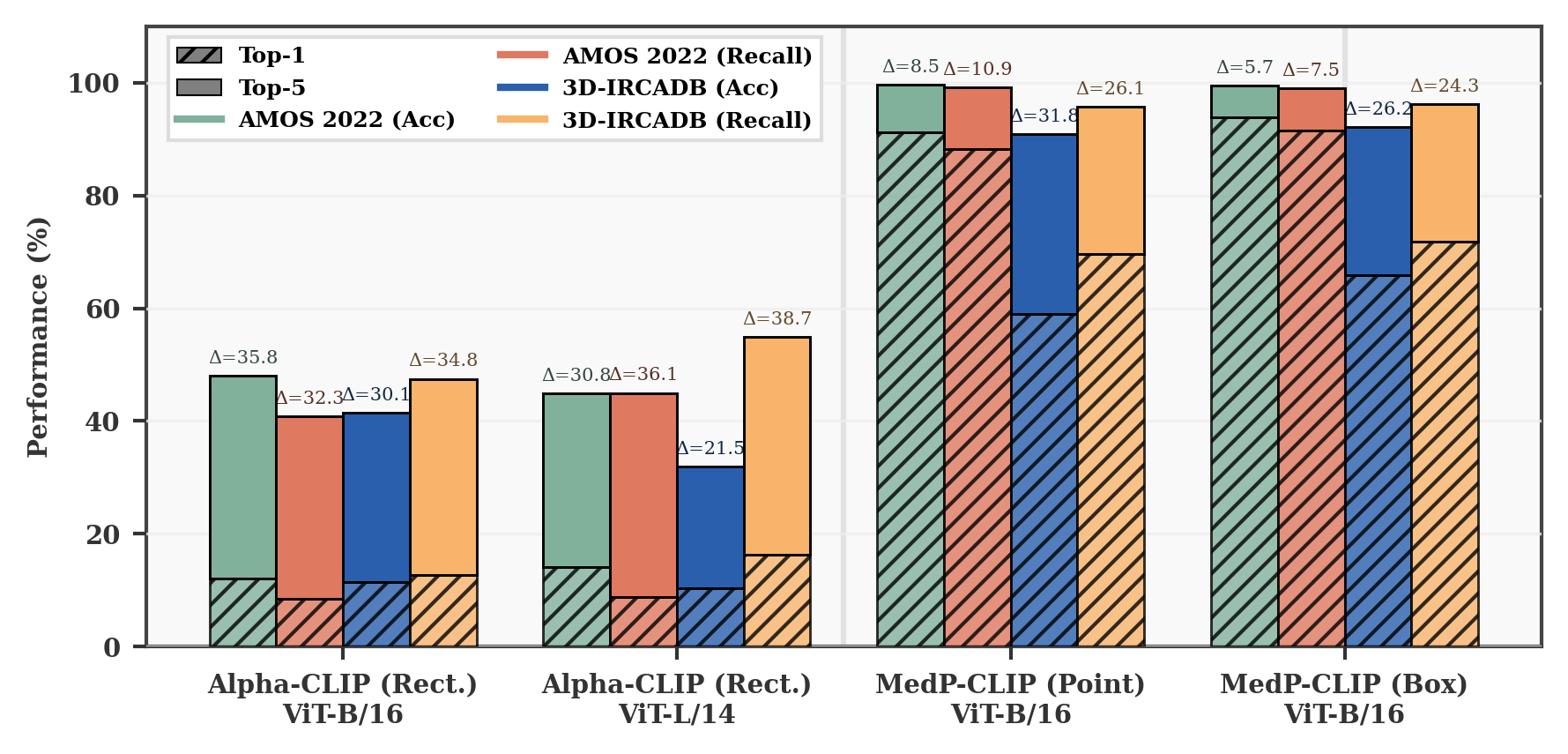
Figure 4: Comparison of region-level classification on complex multi-organ tasks. MedP-CLIP achieves significantly higher accuracy, especially with composite prompts.
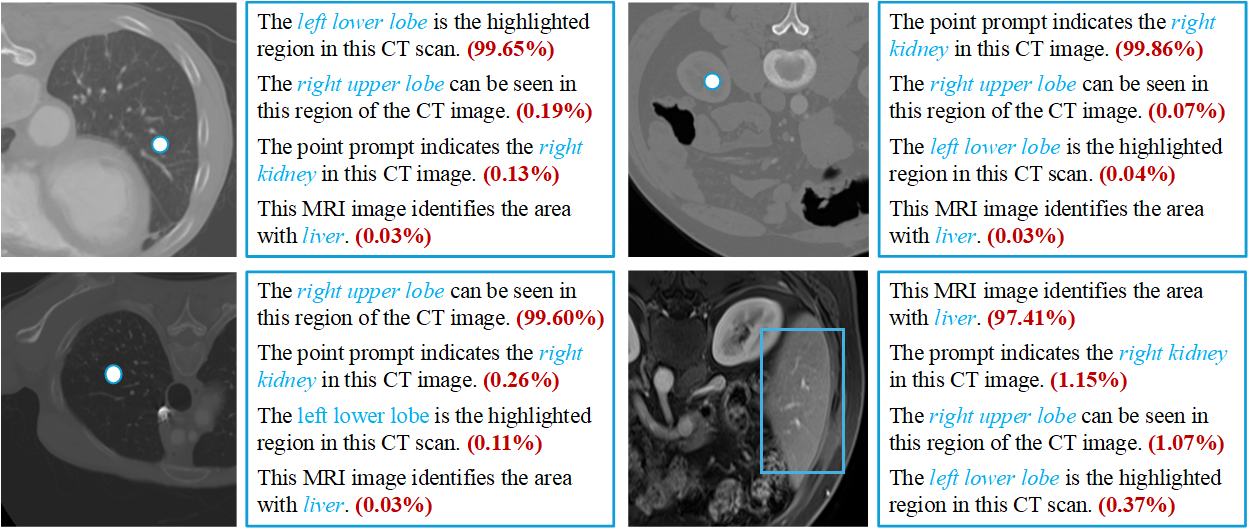
Figure 5: Visual validation: MedP-CLIP efficiently retrieves semantically accurate region-level text using flexible prompts.
Interactive Segmentation
Integrating MedP-CLIP as a vision backbone in the Segment Anything Model (SAM) leads to new SOTA in interactive segmentation benchmarks (ISLES, SegThor, TotalSegmentator MRI), with <1% additional fine-tuning required. Prompted attention consistently refines model focus onto structures of interest, resulting in improved Dice coefficients and anatomical delineation, even in ambiguous or occluded cases.
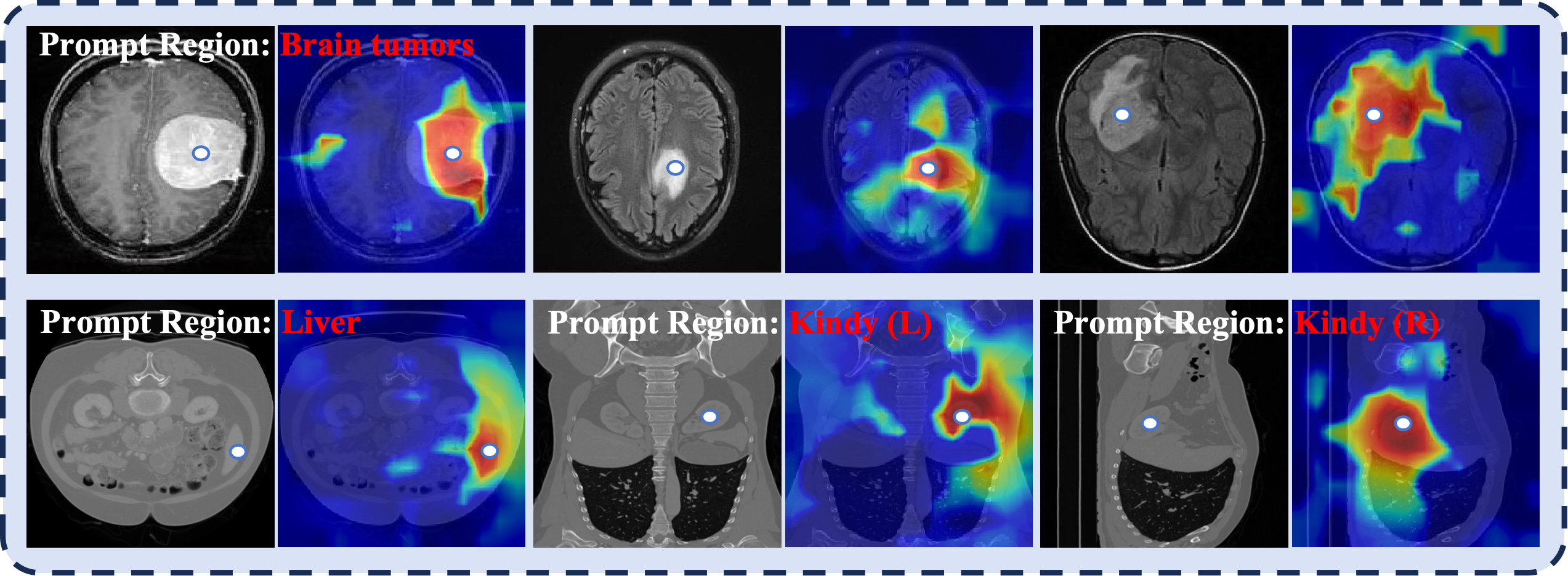
Figure 6: Prompt-guided segmentation: MedP-CLIP’s prompts direct feature aggregation to the true ROIs, enhancing segmentation quality.
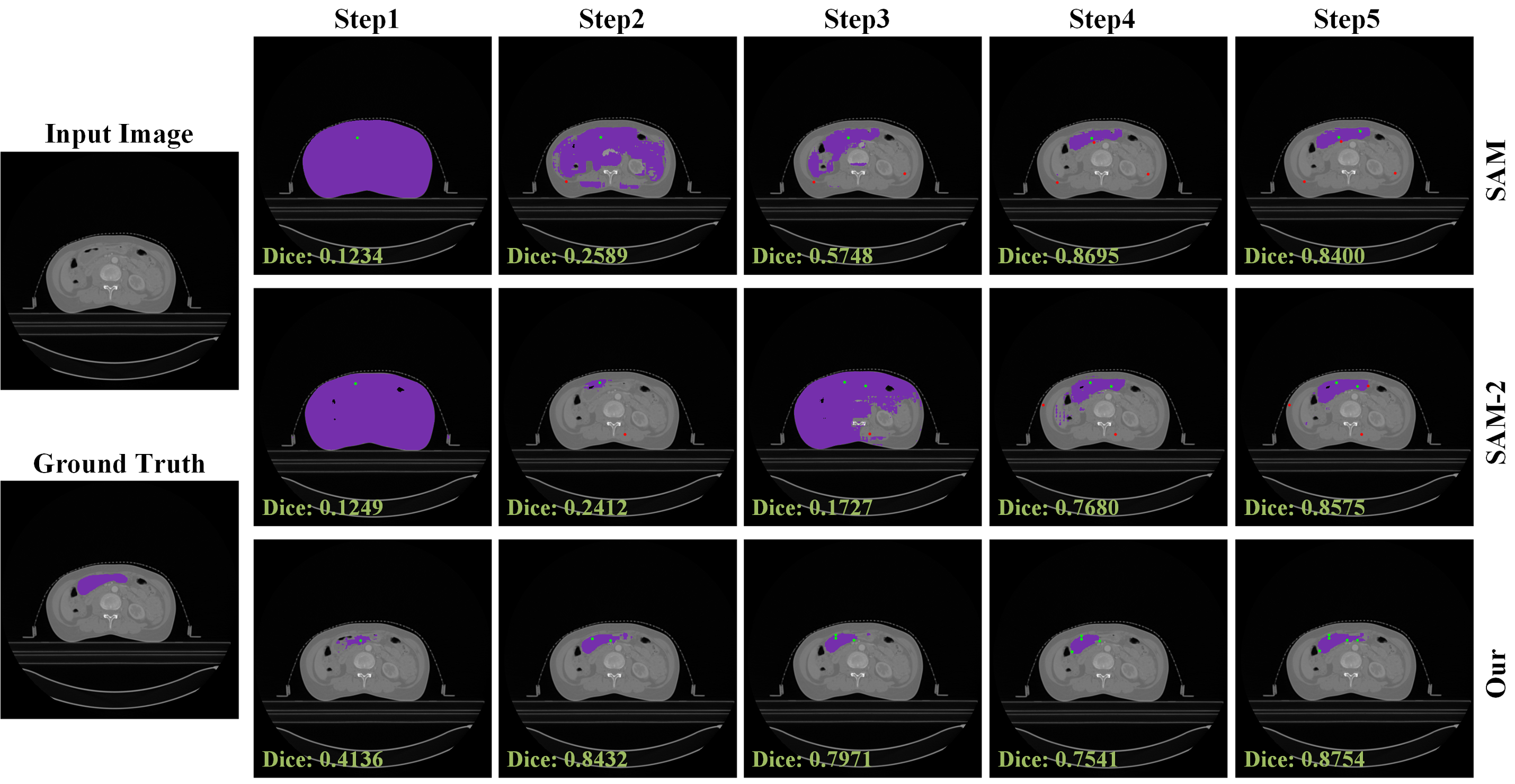
Figure 7: MedP-CLIP + SAM: Segmentation masks resulting from five-point interaction demonstrate precise, prompt-dependent localization.
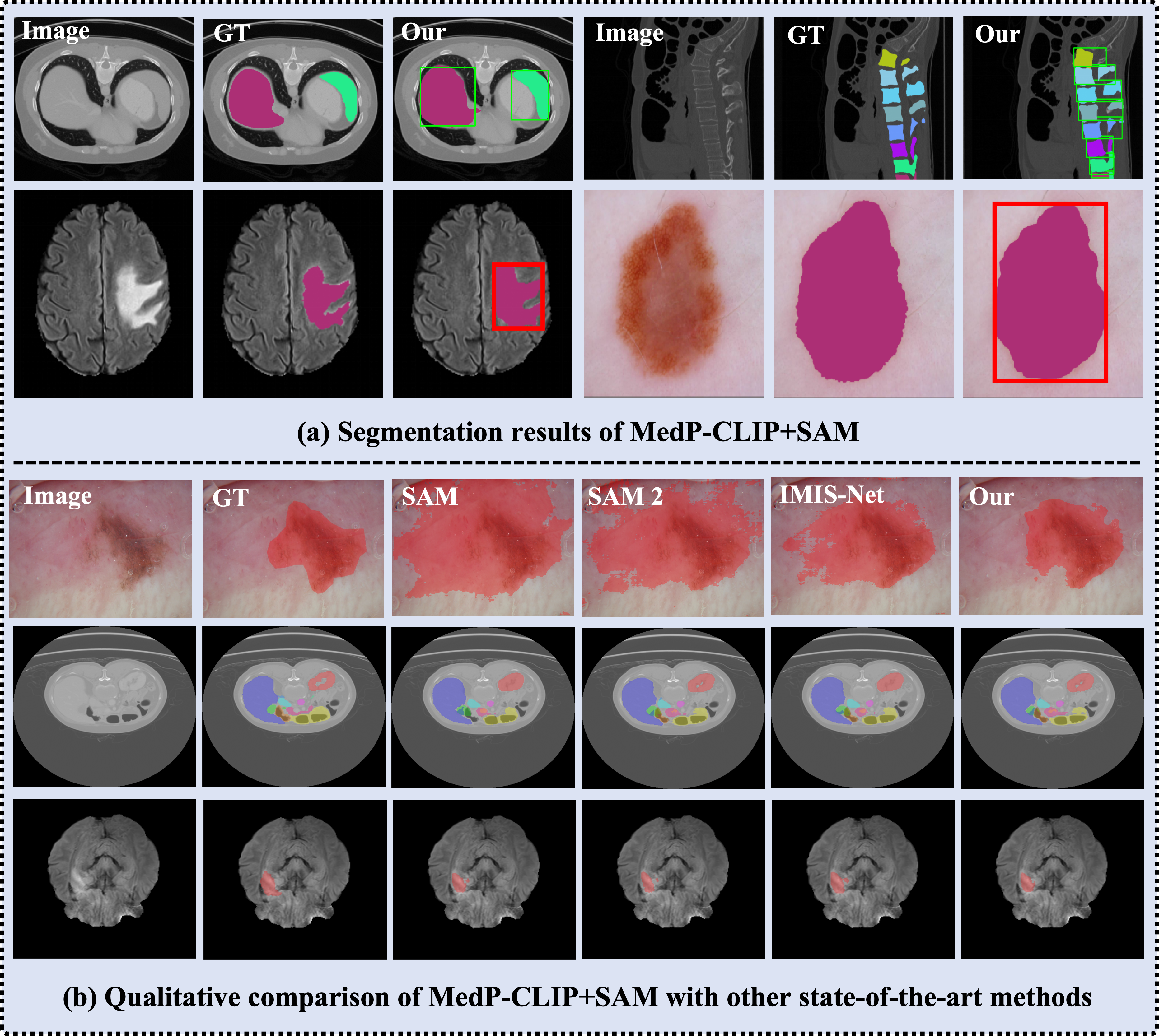
Figure 8: Comparative qualitative study: MedP-CLIP + SAM outperforms SAM and SAM2 in difficult, boundary-ambiguous cases.
Region-Level Medical Visual QA
MedP-CLIP + LLaVA-Med, with region-level prompts, yields precision/recall of 67.96%/70.36% on MeCoVQA-R, surpassing specialized methods like MedPLIB by +3% (and generic MLLMs by >50%). Qualitative results show severe error reduction in anatomical misidentification and hallucinated findings, corroborating the utility of direct, feature-level region-text fusion.
Figure 9: MedP-CLIP enables region-aware VQA: Only the proposed model consistently grounds answers to the true prompted organs or lesions.
Prompt Sensitivity and Limitation Analysis
Failure analyses highlight that single-point prompts are vulnerable to local noise or anatomical ambiguity (e.g., cysts vs. gallbladder). In contrast, composite or denser spatial prompts mitigate misclassification by injecting richer contextual constraints. Nonetheless, 2D morphological ambiguity among adjacent structures remains a nontrivial limitation—pointing to the eventual necessity for 3D anatomical priors for error-proof reasoning.
Figure 10: Case studies of prompt sensitivity: Multi-point/box prompts systematically improve robustness in the presence of OOD noise or adjacent semantics.
Discussion
A systematic, empirical comparison demonstrates that MedP-CLIP's feature-level integration mechanism is decisively superior to input-level adapters (SAM, Alpha-CLIP) and global-encoder VLMs (UniMed-CLIP, BiomedCLIP, BMC-CLIP) with respect to:
- Support for intuitive, native promptable interaction without auxiliary input channels or architectural modifications.
- True region-level visual–text alignment and fine-grained spatial reasoning, preserving holistic context.
- Unification across tasks (recognition, retrieval, segmentation, VQA), supporting both clinician and model outputs as prompts.
- Best-in-class performance benchmarks—even when scaling SOTA baselines to equivalent data volumes, MedP-CLIP demonstrates a consistent +5.9% gain.
Ablation analyses further confirm:
- The choice and diversity of prompt templates at inference time critically impact stability; ensembling mitigates template brittleness.
- Performance is strongly data-scale dependent, yet MedP-CLIP’s architectural advances are not simply a function of pre-training corpus size.
Practical and Theoretical Implications
MedP-CLIP operationalizes a principle shift for medical VLMs, refocusing model design on fine-grained, spatially-conditioned reasoning rather than blanket global feature pooling. For clinical workflows, this translates to:
- Efficient and interactive clinician-in-the-loop AI, where bespoke points/boxes/masks deliver immediate, explainable feedback on arbitrarily small regions.
- Seamless backbone integration for future medical LLMs and multimodal reasoning, minimizing error propagation and hallucinated findings.
- Improved support for rare/atypical disease phenotypes and heterogeneous imaging protocols, as prompt granularity “grounds” the model directly in the relevant clinical context.
Nevertheless, expanding beyond 2D priors and augmenting promptless, fully automated ROI localization remain as open frontiers. Incorporating 3D anatomical atlases and self-inferred spatial priors presents a critical direction for robust, context-aware AI deployment in highly variable medical imaging scenarios.
Conclusion
MedP-CLIP establishes a new paradigm in medical vision-language modeling, natively reconciling the antagonistic requirements of global semantic alignment and region-specific fine-grained analysis. Its feature-level region prompt integration, massive region–text dataset, and downstream task versatility set new standards in zero-shot recognition, segmentation, and multimodal reasoning. The architectural principles outlined have immediate translational relevance for next-generation medical AI, with future progress contingent on further integration of 3D priors and implicit region detection for fully scalable diagnostic intelligence.