- The paper introduces MRPD, which efficiently transfers robustness from image, text, and 3D teachers to 3D point cloud models via learnable prompts.
- It achieves state-of-the-art robust accuracy on ModelNet40 and ScanObjectNN, outperforming traditional defense methods under diverse adversarial attacks.
- Adaptive techniques like confidence-gated loss and dynamic loss weighting ensure effective multimodal supervision with zero inference overhead.
Multimodal Robust Prompt Distillation for 3D Point Cloud Models
3D deep learning systems, particularly those operating on point cloud data, are critically susceptible to adversarial attacks due to the geometric sparsity and irregularity inherent in their data representations. Existing defense strategies, such as adversarial training or architectural modifications, either impose substantial computational burden or display narrow generalizability, making them unsuitable for real-time deployment in safety-critical applications. The recent surge of vision-LLMs (VLMs) suggests the feasibility of transferring robustness from mature 2D and textual domains to 3D tasks. However, prior work primarily exploits VLMs for semantic enrichment, rarely addressing robust knowledge transfer. This paper proposes Multimodal Robust Prompt Distillation (MRPD), a teacher-student paradigm to efficiently distill robustness from image, text, and 3D teachers into learnable prompts, thereby yielding adversarial resilience with no additional inference cost.
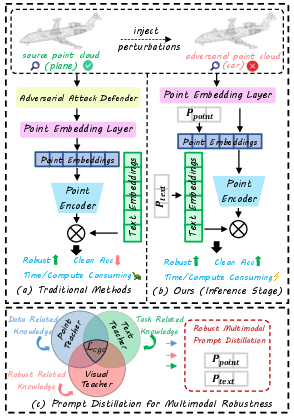
Figure 1: Comparison of defense modalities: (a) traditional defenses with high inference costs, (b) MRPD's inference phase utilizing only prompts (zero overhead), and (c) robust, multimodal knowledge distillation in training.
MRPD Framework: Multimodal Prompt Distillation
The MRPD framework operates under a teacher-student architecture during training. Three robust teacher models—an image encoder (2D projection-based), a text encoder (semantic regularizer), and a high-performance 3D model (geometric anchor)—generate stable feature representations. The student model, a VLM-guided 3D encoder, is augmented with two forms of learnable prompts: one in the point cloud encoder and one in the text encoder.
Crucially, robust knowledge transfer during distillation is governed by:
- Confidence-Gated Distillation: This loss function leverages a gating mechanism that validates teacher signal reliability on a per-sample basis, ensuring only confident, correct predictions are distilled, thereby avoiding negative knowledge transfer from ambiguous or unreliable teacher outputs.
- Dynamic Loss Weighting: A learnable multi-task weighting balances contributions from the three modalities based on learned uncertainties via log-variance parameters, enabling adaptive emphasis toward the most reliable supervision source.
After training, all teacher modules and distillation losses are discarded. At inference, only the optimized prompts are retained, ensuring zero added computational overhead and architectural integrity.
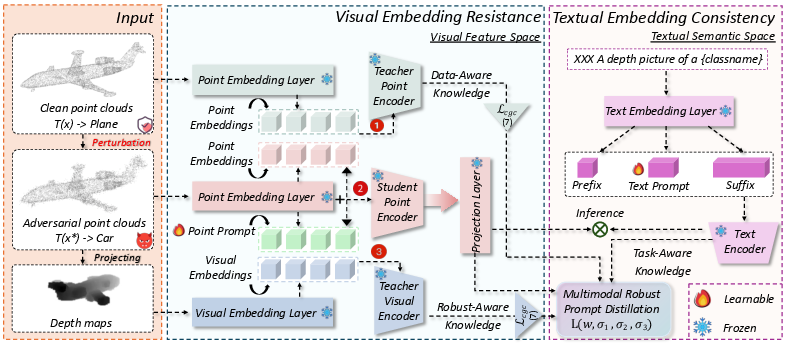
Figure 2: The MRPD framework. Training distills knowledge from image, text, and 3D teachers into lightweight prompts; inference employs only prompts, eliminating extra computational cost.
Empirical Evaluation
White-box and Black-box Robustness
Extensive benchmarks on ModelNet40 and ScanObjectNN datasets demonstrate that MRPD provides the highest average robust accuracy across a suite of white-box and transfer-based black-box adversarial attacks—outperforming all existing crisp and computationally intensive defenses.
Key numerical highlights include:
- ModelNet40: MRPD achieves 72.58% average robust accuracy; surpasses adversarial training in both clean (90.52% vs. 89.95%) and robust settings (notably +12.64% under Perturb attack and +11.50% under ADD-HD).
- ScanObjectNN: MRPD leads with 67.39% average robustness versus adversarial training's 64.18%; robust against occlusion and real-world geometry noise.
In black-box (transfer) attack evaluations, MRPD continues to outperform, indicating that its learned representations are less correlated with those of conventional architectures, thus better generalizing to unseen attack distributions and adversarial patterns.
Feature Space Analysis
MRPD preserves semantic and geometric feature separation even under severe adversarial corruption, corroborated by t-SNE visualizations. While unprotected models suffer feature space collapse and class entanglement under attack, MRPD maintains distinct and compact class clusters, preserving classification integrity.
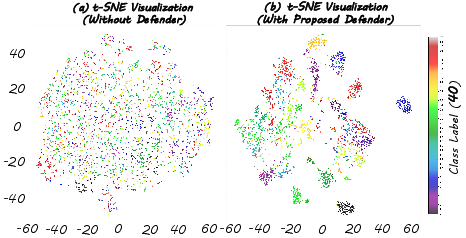
Figure 3: MRPD preserves feature space integrity under adversarial attack on ModelNet40, keeping class features well separated and robust.
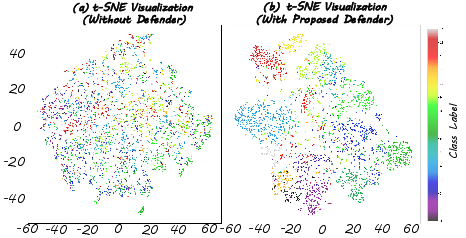
Figure 4: MRPD restores clear class separation on ScanObjectNN under strong white-box attacks, preventing feature collapse.
Ablation Analyses
Theoretical and Practical Implications
MRPD advances robust 3D point cloud learning by demonstrating that multimodal prompt distillation can bridge the robustness gap without architectural inflation or inference overhead. The approach generalizes across attack modalities, domains, and noise regimes, representing an efficient robustification route for neural networks tasked with 3D perception—an area of critical relevance for autonomous driving, robotics, and safety-critical systems.
By reframing robustness induction as a knowledge distillation problem guided by composite confidence and loss-weighting strategies, this methodology further paves the way for efficient, modality-agnostic defense strategies in future AI systems. The MRPD paradigm is readily extensible to segmentation, detection, or cross-modal retrieval where robust invariance is paramount.
Conclusion
This study introduces a robust, inference-efficient framework—MRPD—that leverages an ensemble of multimodal teachers to confer adversarial resilience upon 3D point cloud models via prompt distillation. Empirical results set new benchmarks, confirm superior generalization, and validate the synergy of prompt-based, multimodal knowledge transfer. These findings indicate a promising future for prompt-centric defense paradigms, not only in 3D vision but for multimodal AI tasks broadly, supporting both theoretical insight and practical deployment in adversarially hostile environments.