- The paper introduces a novel closed-loop framework that jointly evolves agent skills and multimodal communication topologies to enhance multimodal reasoning.
- It proposes a five-stage Multimodal Graph Transformer (MMGT) that adaptively integrates visual and textual cues, enabling content-aware agent collaboration.
- Empirical results across multiple benchmarks show performance gains up to 3.0 points, validating the efficacy of co-evolving skills and graph structures.
SkillGraph: Self-Evolving Multi-Agent Collaboration with Multimodal Graph Topology
Motivation and Background
Visual Multi-Agent Systems (VMAS) offer a scalable framework for synergizing multiple specialist vision-LLMs (VLMs) to solve complex multimodal reasoning tasks beyond the reach of single-agent paradigms. Conventional VMAS approaches are fundamentally limited by structural rigidity (static communication topologies, hand-engineered role assignments) and by cognitive inflexibility (frozen agent reasoning strategies). Existing methods usually rely on pre-defined communication graphs that are insensitive to both the visual intricacies and the contextual semantics of each input query; simultaneously, agent skill banks or role prompts remain static, precluding adaptation as the environment and tasks shift. This hard decoupling between content, graph structure, and agent specialization severely constrains the expressivity and adaptability of current VMAS models.
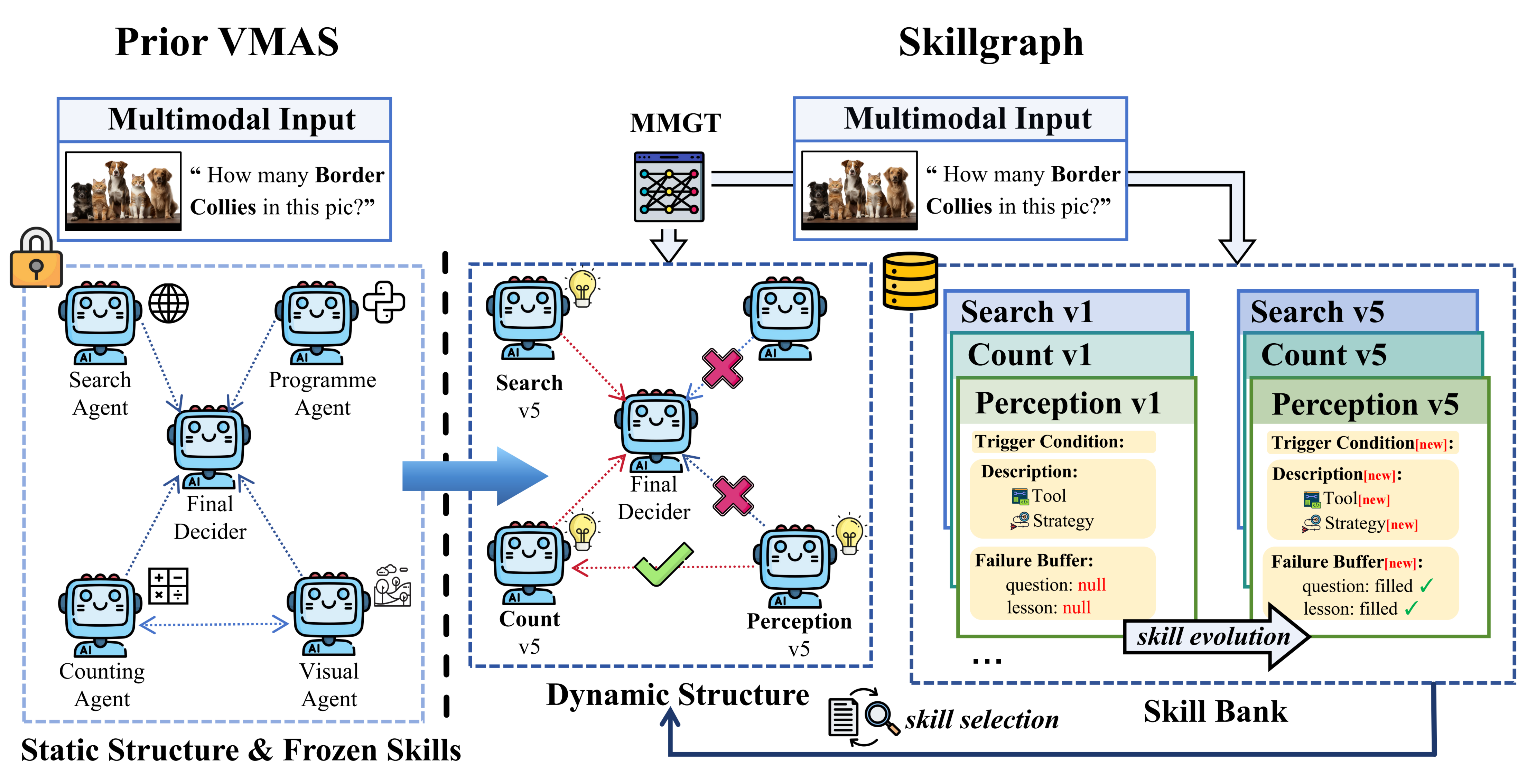
Figure 1: Comparison between prior static-topology, static-skill VMAS and SkillGraph's dynamic co-evolution of skills and multimodal graph topology.
SkillGraph Framework Overview
SkillGraph addresses these deficits through a tightly coupled, closed-loop framework comprising two core innovations: the Multimodal Graph Transformer (MMGT) and a self-evolving Skill Bank. MMGT replaces hand-engineered, static communication with a learned, content-aware, query-adaptive topology design protocol. It fuses visual patch features, instruction semantics, and the current agent skill profile to synthesize a context-sensitive, directed communication graph for collaboration on each query. In parallel, the Skill Designer module orchestrates dynamic evolution of agent skills by mining failures, conducting structured diagnosis, and driving skill bank refinement or expansion. Critically, evolved skill embeddings are immediately reintegrated into MMGT’s node features, ensuring that advances in agent reasoning capacity are reflected in future topology choices. This bi-directional co-adaptation—structural plasticity and skill improvement—drives joint optimization unavailable in previous multi-agent systems.
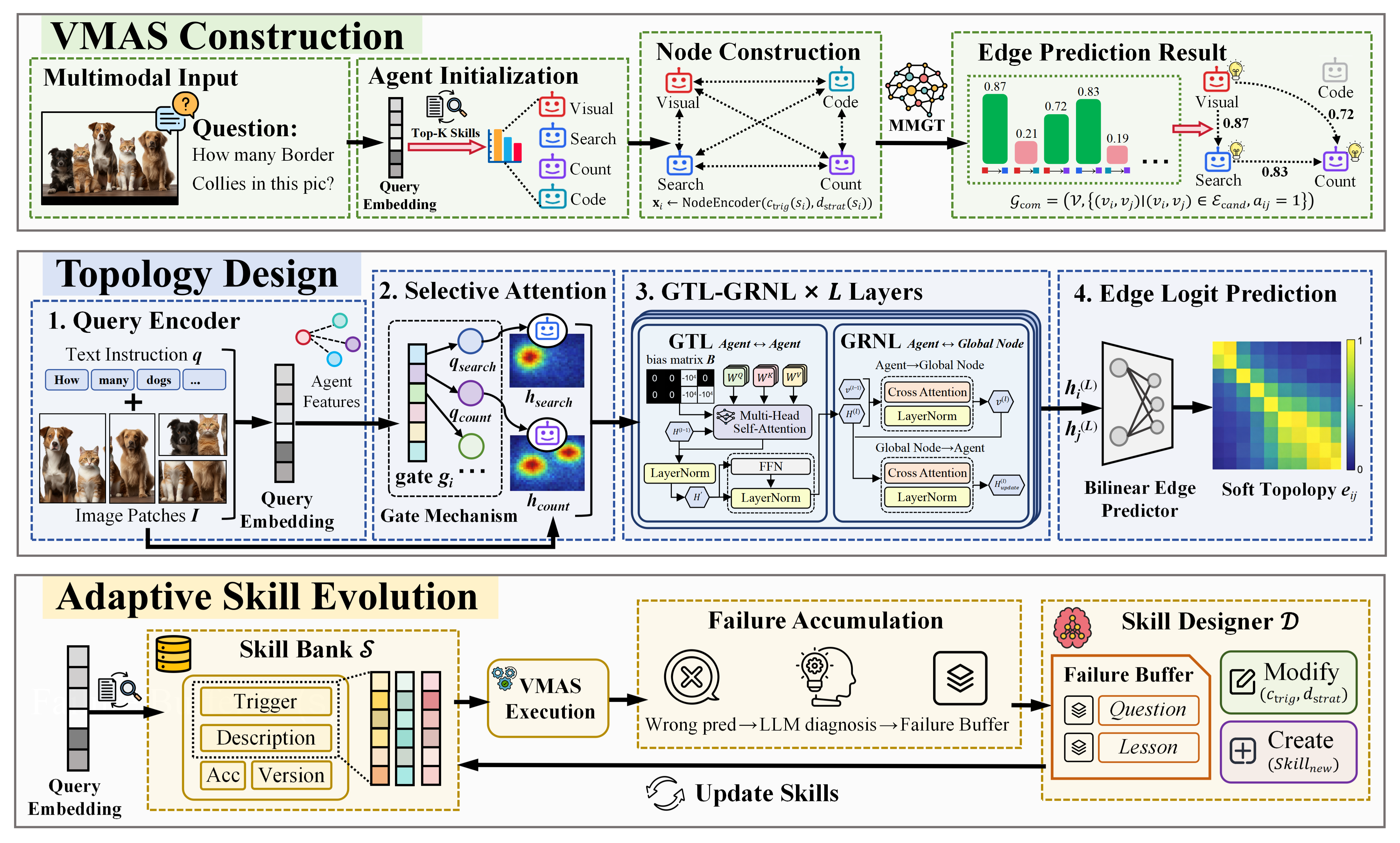
Figure 2: Architecture of SkillGraph, illustrating (1) agent initialization with dynamic skills, (2) MMGT-based graph topology design, and (3) adaptive skill evolution and feedback for closed-loop co-evolution.
Technical Contributions
MMGT is a five-stage encoder that constructs the agent communication topology as a function of both visual and textual cues, as well as agent skill states. It introduces:
- Per-Agent Selective Image Attention: Each agent constructs a personalized image embedding through gated attention modulated by its skill embedding, allowing for heterogeneous, capability-aligned spatial feature extraction across agent nodes.
- Role-Prior Graph Attention: A role-based prior bias softly restricts message passing between agents, but the model can override these priors if multimodal evidence warrants unconventional communication.
- Global Relay Node: Bidirectional relay between agent-specific features and a global, task-level latent ensures tight coupling of collective state and individual roles.
The communication graph Gcom is sampled via policy gradients, with the MMGT optimized for query-answering correctness using stochastic graph construction as a discrete policy.
Self-Evolving Skill Bank
The lifelong learning protocol includes:
- Structured Failure Attribution: Each skill logs structured error records (queries, images, agent outputs, ground truth, and LLM-based failure lessons) into a bounded diagnostic buffer.
- Skill Evolution Procedures: The Skill Designer periodically triggers modifications to existing skills (updating trigger conditions/strategies) or creates entirely new skills in response to consistent failure patterns, ensuring both refinement and expansion.
- Immediate Feedback Coupling: Post-evolution, updated skills are re-encoded and injected into the MMGT for topology prediction, closing the adaptation loop, and making both agent capacity and collaboration routes contextually optimal.
Empirical Results
SkillGraph is thoroughly evaluated across four multimodal reasoning benchmarks (MMBench, MathVista, RealWorldQA, InfoVQA) and four VLM backbone families (Qwen3-VL, LLaVA-OneVision, Qwen2.5-VL, InternVL3), spanning five VMAS graph archetypes. It consistently outperforms all single-agent and static-topology VMAS baselines, with accuracy gains typically in the +1.0 to +3.0 points range depending on the structural prior, backbone, and benchmark.
Key findings:
- Co-Evolution is Synergistic: Ablation reveals that enabling either MMGT or skill evolution in isolation improves performance, but their combination yields strictly superior overall generalization, especially on challenging mathematical/spatial tasks like MathVista.
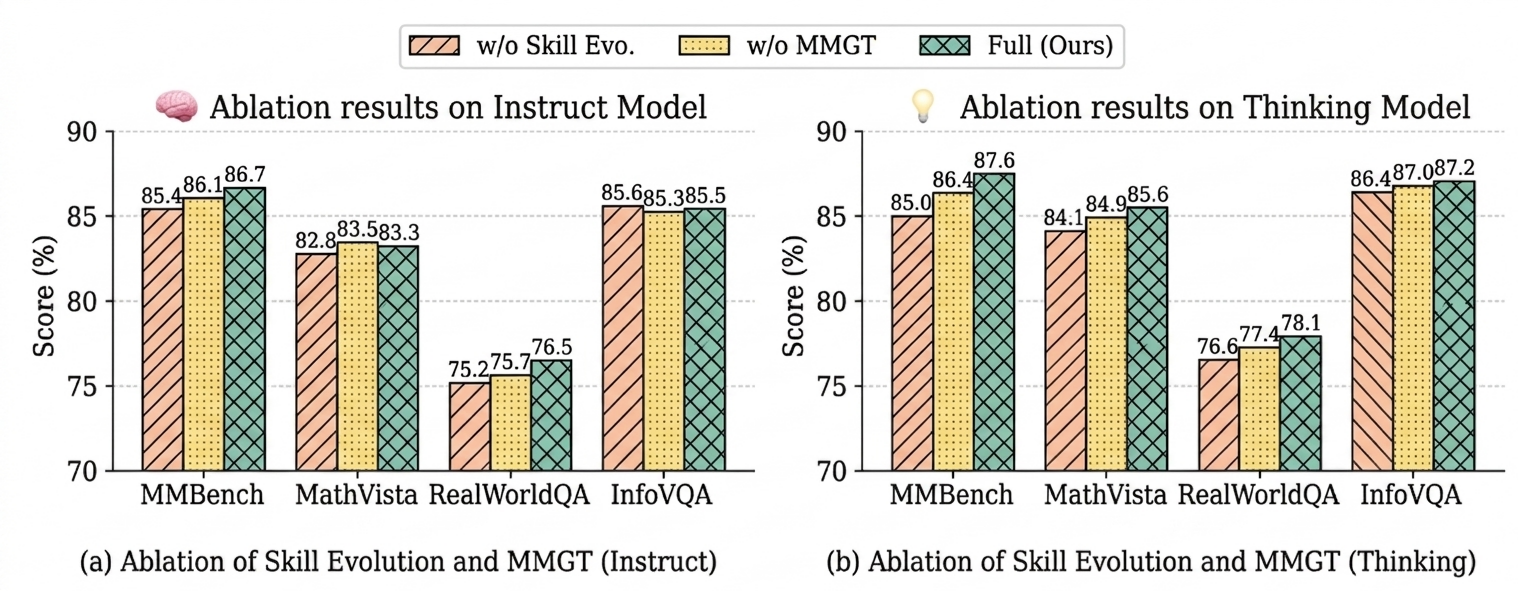
Figure 3: Ablation of MMGT and Skill Evolution, showing that both contribute positively, with their combination yielding the best performance in both Instruct and Thinking configurations.
- Performance Scales with Iteration: Most skill and topology adaptation benefit accrues in the first 10-15 evolutionary cycles, after which convergence is observed, with the largest absolute gains early in the process.
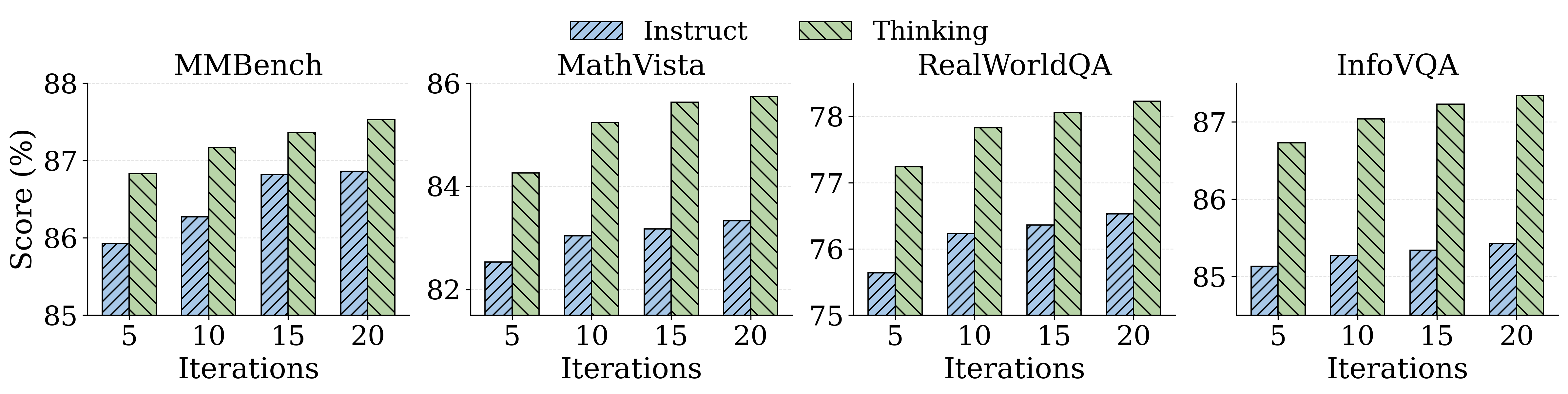
Figure 4: SkillGraph performance as a function of evolutionary iteration, indicating rapid improvement and eventual plateau.
- Skill Bank Stabilization: Skill creation and modification events decrease monotonically, confirming that the system converges to a compact, reusable set of adaptive skills reflective of the domain complexity.
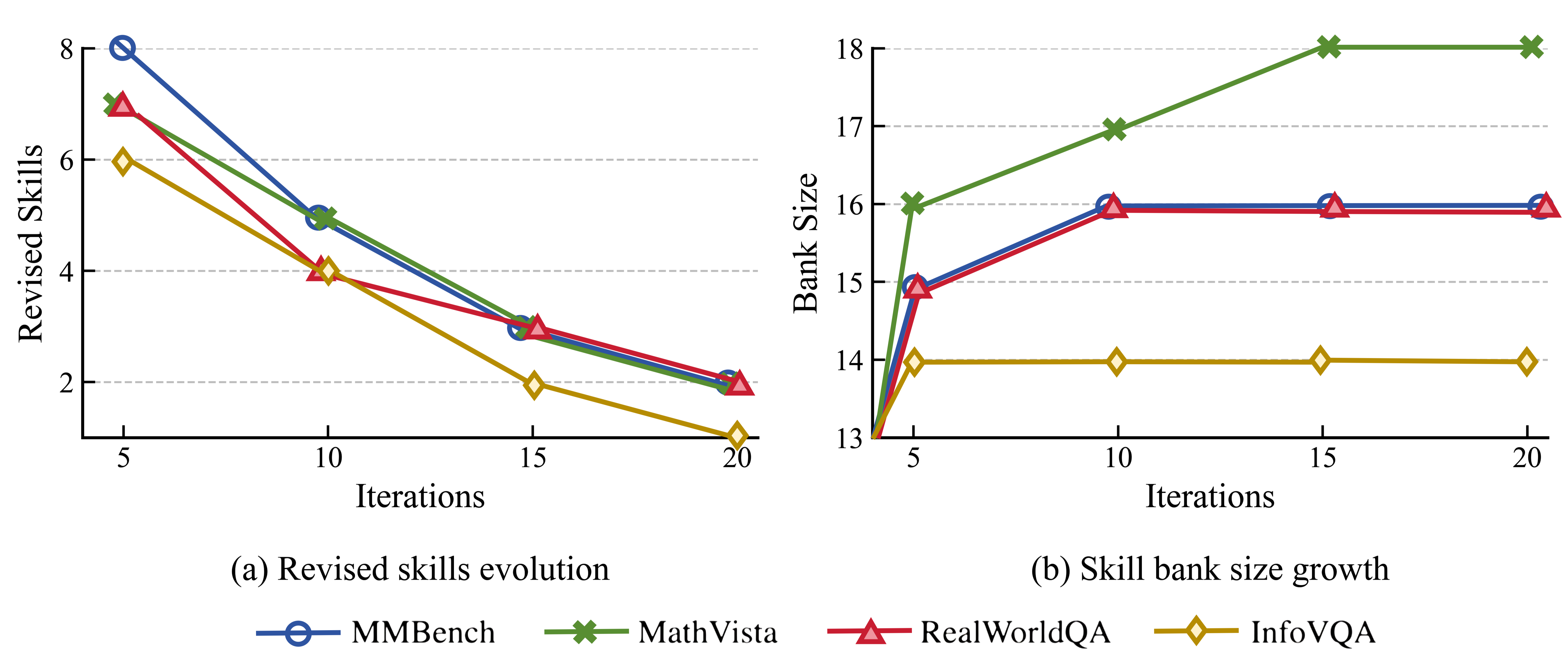
Figure 5: Frequency of skill evolution actions (Create, Modify) and resulting bank size, by benchmark; different task complexities induce distinct final skill inventories.
Implications and Future Directions
SkillGraph resolves the decoupling between reasoning skills and collaboration topology that has hampered the scaling of VMAS for multimodal tasks. The demonstrated accuracy improvements are robust across model scales and structures, with pronounced gains in settings demanding compositional or mathematical visual reasoning. Notably, qualitative analysis of skill evolution reveals that SkillGraph can shift agent behaviors from naive, prior-driven reasoning to careful, evidence-grounded hypothesis testing—directly addressing the brittleness and hallucination risks pervasive in large VLMs.
The closed co-evolution paradigm suggests several promising future avenues:
- Transfer and Expansion: The modularity of the Skill Bank and MMGT enables plug-and-play extension to other domains (e.g., multimodal medical agents, complex web navigation).
- Meta-Optimization: Endogenously tuning the evolution schedule, bank management, and policy parameters could further stabilize and accelerate adaptation.
- Safety and Auditability: Fine-grained failure logging and skill versioning support verifiable skill improvement, aligning with current research priorities in agent safety and interpretability.
Conclusion
SkillGraph introduces a rigorous, closed-loop method for co-evolving agent reasoning skills and multimodal collaboration topology in visual multi-agent systems. By synchronizing adaptive communication structure with continual improvement of agent expertise, SkillGraph sidesteps the rigidity of previous VMAS architectures and achieves demonstrable, benchmark-verified gains in diverse multimodal reasoning scenarios. This work establishes a robust technical precedent for both general VMAS development and the future of adaptive, content-aware collective intelligence in AI systems.
Reference: "SkillGraph: Self-Evolving Multi-Agent Collaboration with Multimodal Graph Topology" (2604.17503)

