- The paper introduces a transparent, OS-inspired proxy that centrally coordinates retries and admission control, dramatically reducing agent failure rates.
- It implements scheduling primitives—such as admission control, rate-limit tracking, AIMD backpressure, and token budgeting—to optimize concurrent LLM agent performance.
- Empirical evaluations demonstrate near-linear scalability and a 96–97% reduction in resource waste, validating the efficacy of centralized proxy-mediated scheduling.
HiveMind: OS-Inspired Scheduling for Concurrent LLM Agent Workloads
Overview
"HiveMind: OS-Inspired Scheduling for Concurrent LLM Agent Workloads" (2604.17111) addresses failure-prone patterns emerging when multiple autonomous LLM-based coding agents interact with rate-limited APIs in parallel. The core contribution is a transparent, provider-agnostic proxy implementing a set of operating system–inspired scheduling primitives, which enables robust, efficient resource management for concurrent LMM agent workloads. The paper evidences dramatic reductions in agent failure rates and token waste under contention, and systematically isolates the efficacy and necessity of each proxy primitive through ablation studies.
Modern autonomous LLM agents—such as Claude Code, Devin, and OpenAI Codex variants—are increasingly deployed in parallel to automate complex developer workflows. However, such deployments frequently encounter infrastructural limits imposed by model providers: request and token quotas, connection ceilings, and rate-limiting. Agent orchestration frameworks currently treat LLM APIs as effectively unlimited resources, and attempt no sophisticated resource management at the multi-agent level.
Empirical analysis demonstrates that, in such a naively parallel deployment, agent failures (e.g., connection resets, HTTP 502/429 responses) occur at high rates—even when the cumulative demand is within the nominal provider limits, but requests are poorly coordinated. The motivating incident cited in the paper records a 27% failure rate (3/11 agents irrecoverably dead) solely due to the lack of temporal staggering between agent requests.
Architecture and Scheduling Primitives
HiveMind inserts a structured, OS-inspired proxy between LLM agents and their upstream API endpoints. The proxy's core architecture comprises five tightly coupled scheduling primitives:
- Admission Control: Limits in-flight API requests using a gated counter and condition variables, supporting dynamic concurrency window adaptation.
- Rate-Limit Tracking: Incorporates header-based (reactive) and sliding-window (proactive) mechanisms, using provider profile detection for correct limits.
- AIMD Backpressure and Circuit Breaking: Applies additive-increase/multiplicative-decrease logic for concurrency, driven by observed API latency and errors, and overlays a circuit breaker for fast failure on persistent upstream instability.
- Token Budget Management: Enforces agent-level token ceilings, with agent warnings and automated checkpoint/termination.
- Priority Queue with Dependency DAG: Orders and schedules tasks with multi-level priorities and dependency tracking.
The proxy design is fully transparent: agents require zero code modification, ensuring compatibility with heterogeneous frameworks and provider APIs.
(Figure 1)
Figure 1: Failure rates by scenario: direct mode exhibits catastrophic failure at 10+ agents, while HiveMind reduces failures to 0–18%.
(Figure 2)
Figure 2: Scaling behaviour: successful completions and throughput drop to zero in direct mode for 5+ agents, while HiveMind scales linearly.
Experimental Evaluation
Failure Rate, Throughput, and Token Wastage
Extensive evaluation across seven concurrency and error-injection scenarios quantitatively demonstrates the utility of the scheduling primitives. At 10 or more concurrent agents, direct (unscheduled) execution universally yields failure rates from 72% to 100%. Under identical load, HiveMind reduces failures to between 0% and 18%, with the remaining failures attributable to deliberately injected error rates that exceed the retry budget.
Throughput analysis (completed agent tasks per minute) further confirms that, under contention, direct mode collapses while HiveMind maintains near-linear scaling with agent count. In all high-concurrency scenarios, HiveMind virtually eliminates wasted token expenditures from dead agents, thus providing strong economic benefits.
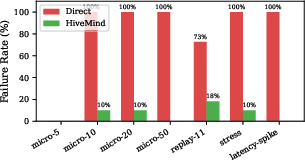
Figure 3: Ablation study: removing retry induces a 63.6% failure rate; admission-only mode fails in 81.8% of cases.
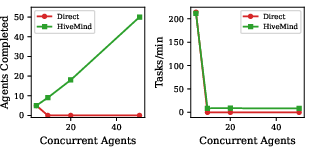
Figure 4: Wasted tokens per scenario: HiveMind brings wastage near zero, whereas direct mode wastes up to 12K tokens per run.
Ablation Studies and Primitive Interactions
A targeted ablation on the replay-11 scenario isolates the essential scheduling primitive contributions. Contrary to prior OS analogies, mere admission control yields only marginal improvement (failure rate remains 81.8%); transparent, centralised retry handling is the most critical single primitive, reducing failures by over 63 percentage points. However, the combination of primitives is optimal: retries mitigate transient failures, admission control prevents resource exhaustion, rate limiting pre-empts further errors, and backpressure adjusts for variable latency.
Centralised, proxy-mediated retry coordination is highlighted as essential. Independent per-agent retries produce synchronized retry storms ("thundering herd") and repeated rate-limiting errors, a pathology completely avoided by HiveMind's cross-agent, admission-gated retry layer.
Real-World Validation
Validation on local deployable models (Ollama, MLX) establishes that HiveMind's minimal proxy overhead (<3 ms per request) does not impede or degrade throughput when the backend API supports internal queuing. In some cases, HiveMind's admission gate harmonizes more efficiently with naturally low-concurrency models, reducing queuing time relative to direct execution.
Implementation and Design Rationale
HiveMind's transparent proxy leverages asynchronous Python (Uvicorn, Starlette), with explicit separation between admission, rate-limit, and backpressure controllers. The admission gate uses condition variables rather than semaphores to safely support dynamic concurrency resizing without race conditions or undefined behaviour.
Provider profile auto-detection ensures correct header parsing, rate tracking, and retry logic for major public (Anthropic, OpenAI, Google, Azure) and local (Ollama, MLX) providers. SSE streaming and token counting are handled natively. Direct backpressure-admission wiring enables immediate concurrency tuning and avoids lag or oscillation.
Theoretical and Practical Implications
From a theoretical perspective, the direct mapping of classic OS resource management mechanisms to LLM agent scheduling is formalized and systematized. The analogy is operationally exact: admission control parallels process scheduling, AIMD mirrors TCP congestion avoidance, circuit-breaking stabilizes the shared service, and resource budgeting prevents agent-level monopolization.
Practically, HiveMind establishes that robust, high-throughput multi-agent LLM workloads on rate-limited APIs are only realizable with a proxy–mediated, centrally coordinated approach. The system's design eliminates failure modes that are unavoidable in direct and per-agent retry strategies, and reduces compute and cost waste by 96–97% across all agent workloads tested.
Limitations and Future Directions
HiveMind is currently scoped to single-machine deployments; distributed, multi-host scheduling state is architecturally possible but not deployed at scale. Token estimation falls back on heuristics in the absence of provider tokenizer APIs. The mock evaluation framework, while realistic, does not exercise all possible cloud-provider corner cases.
Future work includes cloud-scale validation, integration of provider tokenizers for improved budgeting, dynamic or feedback-driven agent priority schemes, and coupling with agent-level resilience (e.g., checkpoint/restart).
Conclusion
HiveMind (2604.17111) provides a substantial advancement in concurrent LLM agent orchestration by formalizing and implementing an OS-inspired scheduling proxy. Its admission-gated, centrally retried, priority-aware design robustly eliminates agent failures and wasted computational resources under provider-imposed constraints without requiring any changes to agent codebases. Ablation studies clarify that centralised retry is paramount, while optimal results are realized only through the composition of all five primitives. HiveMind constitutes a critical enabling infrastructure for production-grade, parallel LLM agent deployments.