- The paper introduces the PDB framework featuring novel edit-aware metrics to quantify LLM precision in debugging tasks.
- Empirical results show that high unit-test success can mask issues, as over-editing and full-code regeneration are common.
- Findings suggest that current models and iterative/agentic approaches fall short in enforcing minimal, targeted code edits.
Precise Debugging Benchmark: Is Your Model Debugging or Regenerating? — An Expert Analysis
Introduction
The paper "Precise Debugging Benchmark: Is Your Model Debugging or Regenerating?" (2604.17338) presents a systematic evaluation framework and associated benchmarks for analyzing the real debugging behavior of LLMs on program repair tasks. Rather than measuring solely by the usual pass/fail binary on unit tests, the authors introduce precise edit-aware metrics to expose the tendency of LLMs to rely on over-editing or outright full-code regeneration rather than minimal, targeted edits. The work is situated in the context of increasing LLM capabilities in code synthesis but identifies acute limitations in their real-world applicability to debugging and maintainability.
Motivation and Problem Statement
Frontier LLMs have brought measurable advances in code synthesis and problem-solving, but in software engineering, the value lies less in end-to-end generation and more in localized, constrained editing—i.e., precise debugging. Current benchmarks, relying purely on functional testing, fail to distinguish whether LLMs effect semantically meaningful, minimal edits or simply regenerate large code segments (which may be effective but are impractical in real software development). As exemplified by empirical observations, even state-of-the-art models like GPT-5.2 often employ full-solution rewrites when tasked with debugging, as opposed to minimal editing:

Figure 1: A real debugging case from GPT-5.2 where the model rewrites the entire solution rather than making targeted bug fixes.
Clearly, true debugging competence requires robust mechanisms for fault localization and maintaining code intent, not just brute-force solution search.
PDB Framework: Generation and Evaluation
To address the inadequacies of current evaluation paradigms, the authors introduce the Precise Debugging Benchmarking (PDB) framework. PDB's pipeline has two principal stages: (1) Generation—automatically synthesizing atomic, independently verifiable bugs (using LLMs) and composing them into multi-bug programs; (2) Evaluation—measuring LLM performance via both traditional unit-test accuracy and two novel edit-aware metrics: edit-level precision and bug-level recall.
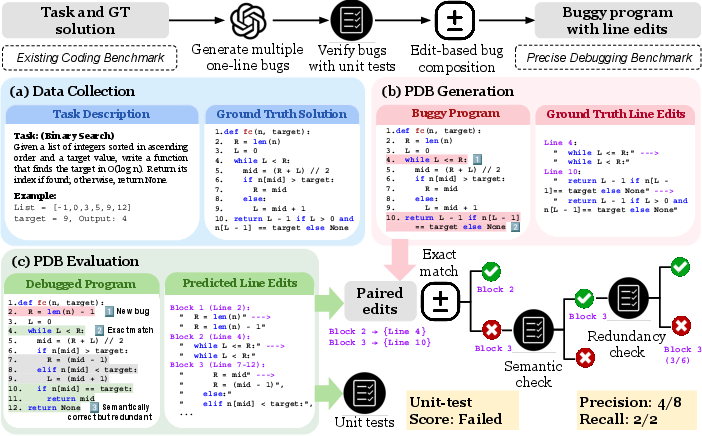
Figure 2: Overview of the PDB pipeline: Buggy programs are generated and composed from existing datasets, then evaluated on both functional correctness and edit-level metrics.
- Edit-level precision quantifies the fraction of LLM-generated edits that are necessary and correct, penalizing unnecessary or spurious changes.
- Bug-level recall assesses the proportion of ground-truth bugs actually fixed by the LLM's edits.
A data distribution illustration is provided, demonstrating the systematic coverage of bug types and compositions across the generated benchmark instances.
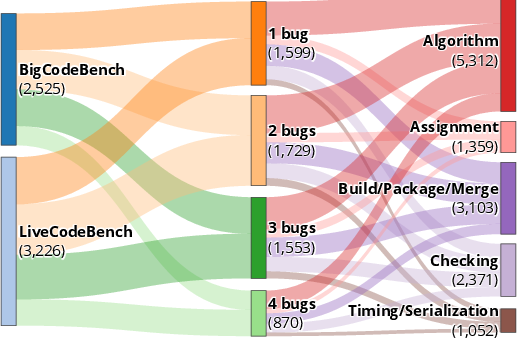
Figure 3: Compositional diversity and coverage of the generated PDB dataset.
Empirical Evaluation
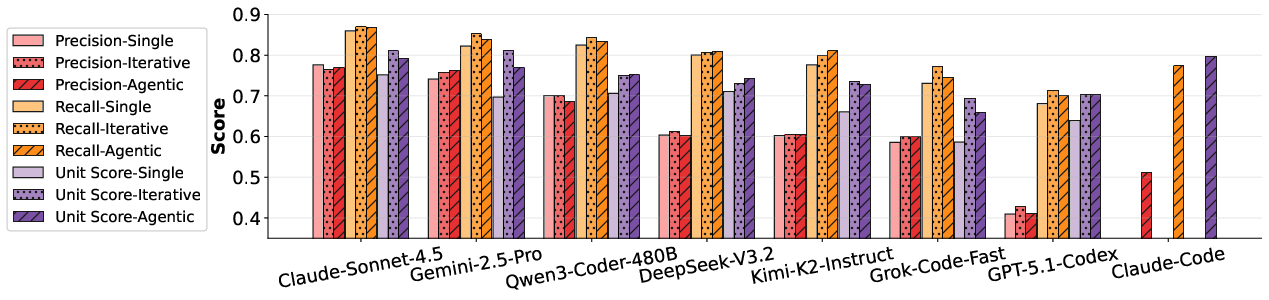
The benchmarks—PDB-Single-Hard (single-line bugs) and PDB-Multi (multi-line bugs)—provide challenging and diverse scenarios across two code task sources, BigCodeBench and LiveCodeBench. Nine models, including both “thinking” and non-thinking LLM variants, as well as current agent-based systems, were evaluated.
Key Numerical Results
The analysis demonstrates several critical findings:
- Unit-test performance and edit-precision decoupling: Models like GPT-5.1-Codex and DeepSeek-V3.2-Thinking achieve high unit-test pass rates (>76%), but precision is below 45%, with frequent over-editing and regeneration observed.
- Ranking inversion: Qwen3-Coder-480B, for example, achieves a lower unit-test pass rate (70%) but substantially higher precision (66%); this clearly demonstrates the inadequacy of binary test-based metrics in debugging evaluation.
- Generalization to multi-line bugs: The precision gap persists and even widens with more complex bug scenarios (Table results and multi-bug analysis), confirming the robustness of the findings.
As bug count increases, precision degrades, displaying a negative correlation with unit-test success. Recall, on the other hand, is dataset-dependent and not strictly monotonic.
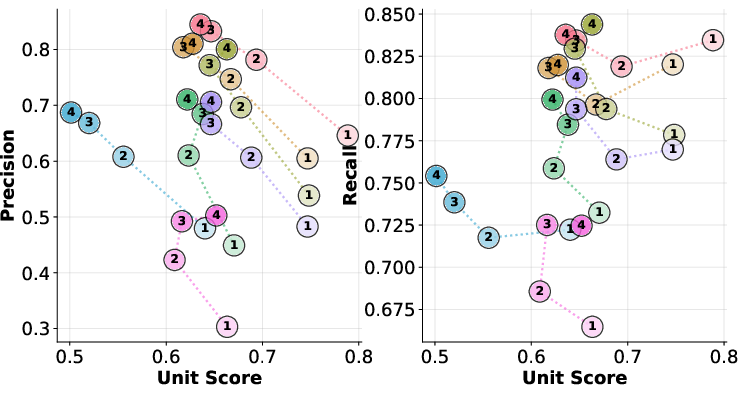
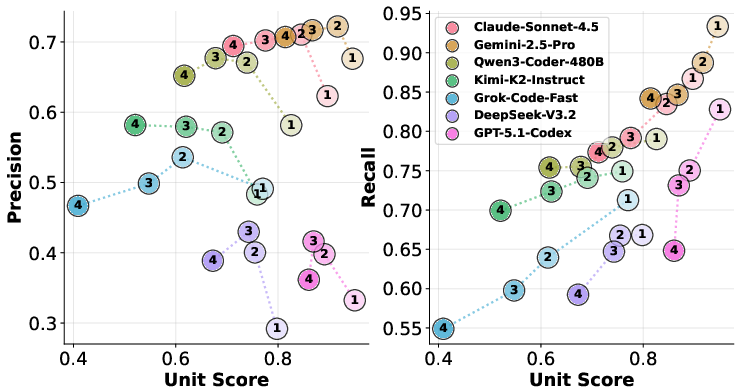
Figure 4: As the number of bugs per instance increases, precision drops, revealing degradation in targeted edit behavior; recall varies non-monotonically.
Effect of Iterative and Agentic Setups
Despite reasoning that iterative or agentic workflows—where models interact with feedback or self-refinement—could improve debugging, the empirical results show that:
Furthermore, prompt-level constraints (minimal-edit prompts vs. freeform prompting) are necessary to curb over-editing, but such constraints are insufficient alone to achieve true minimality.
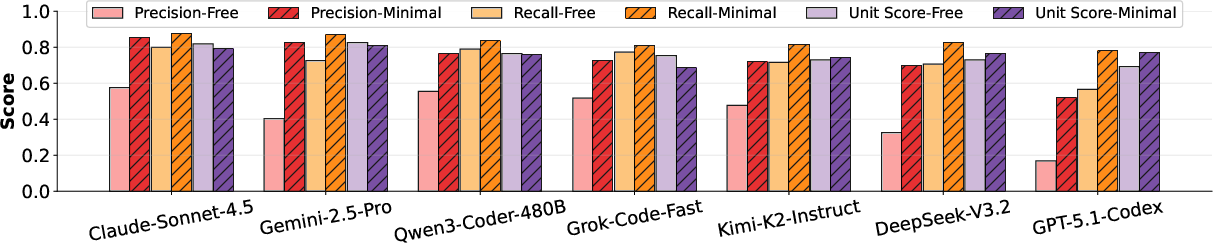
Figure 6: Removing the minimal-edit constraint in prompts leads to substantial precision and recall drops across models.
Error Analysis and Taxonomy
Manual examination of both passing and failing cases under the new metrics reveals the sources of imprecision:
- The majority of “passing but not precise” cases involve extra modifications that do not impact correctness but are unnecessary (66.8%), complete rewrites (7.8%), redundant guards, or rare cases where models fix overlooked ground-truth bugs.
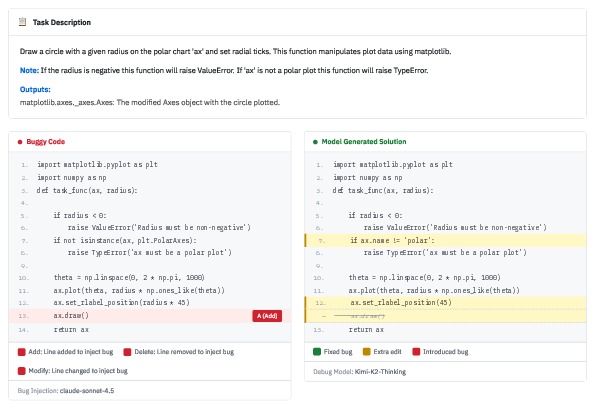
Figure 7: Most imprecise repairs are due to superfluous changes to correct code regions.
- When recall is imperfect, 70% of cases correspond to functionally correct but structurally divergent fixes undetectable by heuristics, with additional fractions attributable to bug composition issues or multiple minimal-fix possibilities.
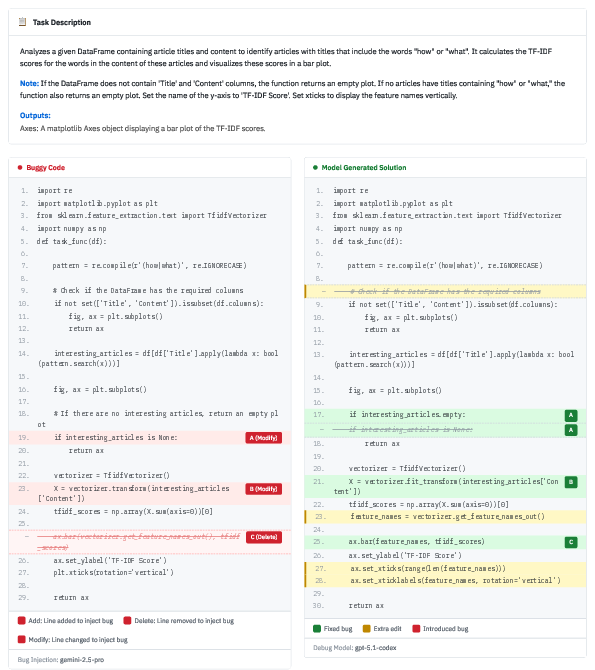
Figure 8: Many cases with imperfect recall are actually functionally correct but over-edit or structurally diverge beyond matching heuristics.
Failures (“unit test fail” cases) are divided among under-repair, imprecise repair, and regressive repair, where new bugs are introduced during patching (31.4%, 29.4%, and 39.2% respectively).
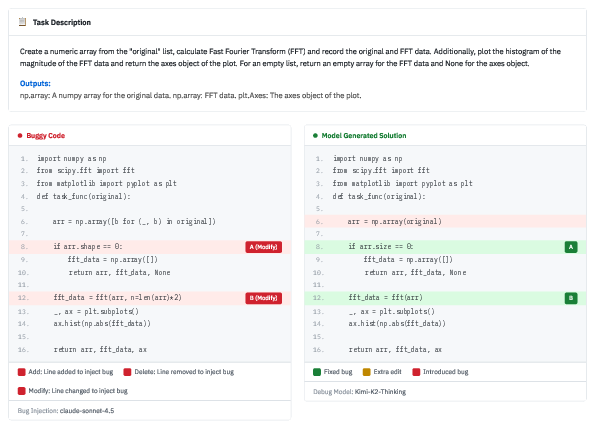
Figure 9: Nearly 40% of failed instances involve the introduction of new regressions.
Categorical and Contamination Analysis
Debugging performance varies with bug type and generation source. Bugs generated by GPT-5.1-Codex are easier for all models, while Claude-Sonnet-4.5-sourced bugs prove more difficult. The impairment in edit-level behavior is not an artifact of data contamination: rewriting references for more surface diversity yields only modest improvements in edit-precision, confirming the robustness of the observed regeneration bias.
Implications for LLM Debugging and Model Development
The divergences exposed by PDB are highly relevant for both theoretical study and practical LLM application:
- Functional correctness (unit test passing) cannot be interpreted as robust debugging ability.
- Post-training or RLHF pipelines are insufficient to instill edit-awareness: current reward schemas do not enforce minimality or discipline in patching strategies.
- Prompt engineering alone is inadequate: while prompt minimality helps, the underlying inductive biases of LLMs remain inclined toward over-generation and solution regeneration.
- Agentic and feedback-driven approaches do not substantially mitigate over-editing. New agent architectures or learning mechanisms focusing on edit discipline and code intent preservation are necessary.
- Benchmarking for edit-level metrics is critical: code LLMs must be evaluated beyond functional success to approach operational relevance in practical software maintenance scenarios.
Limitations and Future Directions
PDB’s current implementation assumes bug independence. Although empirical rates of composition-induced interaction are low, real-world codebases exhibit complex bug dependencies. Additionally, evaluation is presently focused on Python, though the methodology is broadly language-agnostic. Finally, edit-level precision and recall, while robust, can miss semantically correct, functionally valid but structurally divergent repairs—a limitation possibly addressable via model-in-the-loop or LLM-as-a-judge assessment in future work.
Conclusion
This work systematically deconstructs the overreliance of LLMs on wholesale code regeneration during debugging and exposes the inadequacies of current functional evaluation metrics for code repair tasks. The PDB framework and its associated benchmarks offer a rigorous, edit-aware evaluation platform, making evident the necessity for targeted advances in both LLM model-objective design and debugging pipeline methodologies. These insights set a new bar for evaluating and developing LLMs for safe, reliable deployment in real-world software engineering workflows.