- The paper introduces a framework that integrates spatial, wavelet, and Fourier cues with dual continual learning to robustly detect DeepFakes.
- It employs Elastic Weight Consolidation and Orthogonal Gradient Constraints to mitigate catastrophic forgetting while adapting to emerging forgery techniques.
- Experimental results demonstrate a 60.7% reduction in detection error and enhanced robustness against image perturbations compared to state-of-the-art methods.
Face-D2CL: Multi-Domain Synergistic Representation with Dual Continual Learning for Facial DeepFake Detection
Introduction
Face-D2CL addresses two central challenges in continual DeepFake detection: insufficient representational robustness in feature learning and catastrophic forgetting during adaptation to new forgery paradigms. Most prior work either relies exclusively on spatial artifacts or enforces stability with strong regularization or replay, limiting both generalization to novel forgeries and rapid adaptation. This framework strategically integrates multi-domain representation—jointly exploiting spatial, wavelet, and Fourier cues—with a dual continual learning mechanism consisting of parameter-level EWC regularization and LoRA-specific orthogonal gradient constraints. The framework is designed to prevent the erasure of prior discrimination capability while furnishing the flexibility required to capture emergent generative manipulation patterns.
Architecture and Methodology
The Face-D2CL framework comprises two synergistic modules: a multi-domain feature extraction pathway and a dual continual learning constraint pipeline.
Multi-Domain Synergistic Representation: Input face images are decomposed into three parallel domains:
- Spatial: Preserves pixel-level artifacts such as blending and inconsistent illumination.
- Wavelet: Captures reconstruction irregularities via multi-scale frequency decomposition, targeting upsampling artifacts characteristic of synthetic faces.
- Fourier: Models global magnitude–phase discrepancies; these facilitate detection of frequency manipulation traces often induced by diffusion or GAN-based generators.
Domain alignment is performed via batch-wise normalization, ensuring feature scale homogeneity between branches. Aligned features are projected via a shared CLIP ViT-L/14 visual encoder augmented with independent LoRA adapters for each domain, as depicted in (Figure 1).
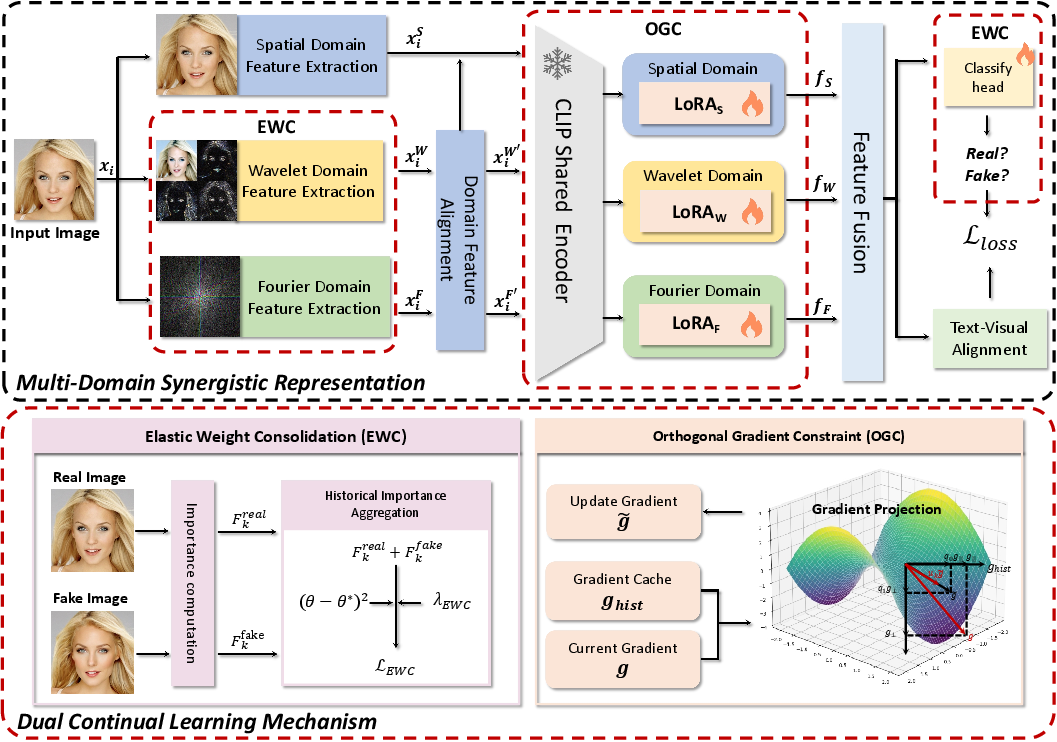
Figure 1: The Face-D2CL architecture, with parallel domain branches, domain-specific LoRA adapters, feature fusion for classification/contrastive alignment, and continual learning via EWC+OGC.
Feature fusion is performed by concatenating the three branches for classification and averaging for text–visual alignment. The latter utilizes a contrastive loss employing fixed prompts ("real face", "fake face") to enforce domain-invariant semantics, promoting higher-order representation stability across task shifts.
Dual Continual Learning Mechanism:
Relying on neither experience replay nor network expansion, continual learning is achieved by:
- EWC (Elastic Weight Consolidation): Parameter importance is quantified via Fisher information, computed separately on real and fake classes. This class-aware regularization is critical: face forgeries occupy a diverse distribution space, in contrast to the compact manifold real faces cluster on throughout incremental tasks.
- OGC (Orthogonal Gradient Constraint): LoRA-adapted gradients are orthogonally projected relative to historical gradient subspaces, constraining low-rank task adaptation so as not to interfere with previously encoded knowledge.
The joint optimization objective, balancing binary cross-entropy, class-aware EWC, orthogonality, and contrastive alignment, preserves both discriminativity and plasticity.
Experimental Results
Continual Learning Protocols: Experiments are conducted on two standard protocols: (1) dataset-incremental, cycling through four major face manipulation benchmarks, and (2) forgery-type incremental, introducing new manipulation categories while keeping the real subset fixed. Metrics include per-dataset accuracy, average accuracy (AA), forgetting (AF), and ROC-AUC on held-out and unseen domains.
Comparison with State-of-the-Art:
Face-D2CL surpasses replay-based and replay-free SOTA methods such as DFIL, SUR-LID, and SAIDO by large margins, particularly in forgetting mitigation and cross-domain generalization. It demonstrates:
- 60.7% reduction in average detection error rate compared to SOTA continual learning approaches.
- 7.9% higher AUC on unseen forgery types (across datasets such as DF40, UADFV, and WildDeepfake).
Ablation studies confirm that both EWC and multi-domain fusion are necessary: removing EWC increases forgetting by more than 12% in Protocol 1, while ablation of frequency branches reduces AA by 3–5%.
Task Order Robustness: Performance remains stable under task order permutations, suggesting high resilience to continual learning instability phenomena.
Robustness to Perturbations:
Under severe image degradations—including block-wise dropout, grid shuffle, additive Gaussian noise, and median blur—Face-D2CL exhibits minimal AUC decline relative to existing methods (Figure 2).
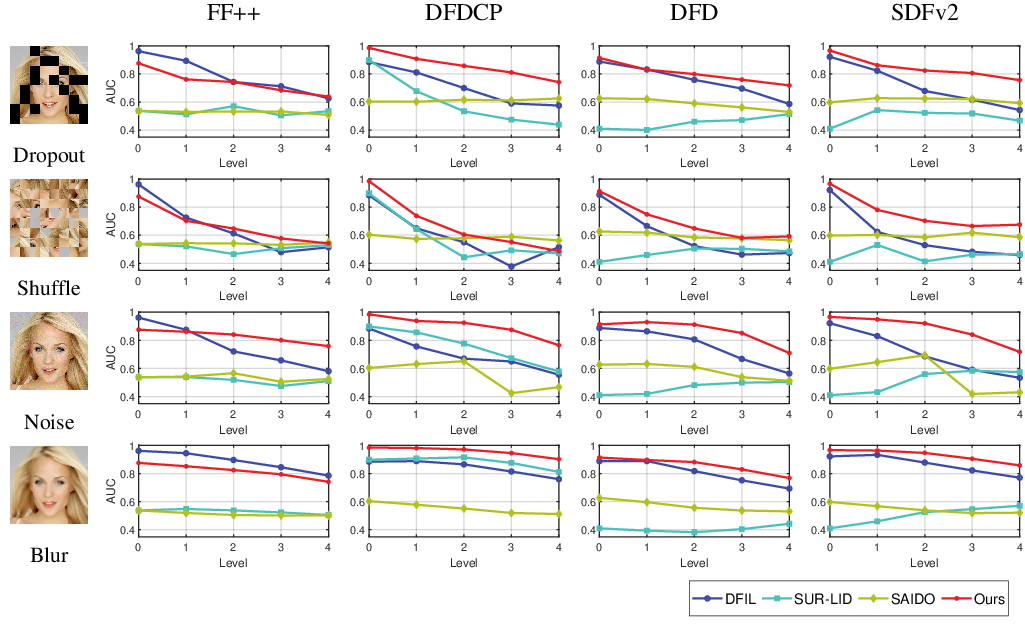
Figure 2: Average AUC under four perturbation types (block-wise dropout, grid shuffle, Gaussian noise, median blur) at five intensity levels; Face-D2CL maintains robustness despite severe image degradation.
Pipeline Overview:
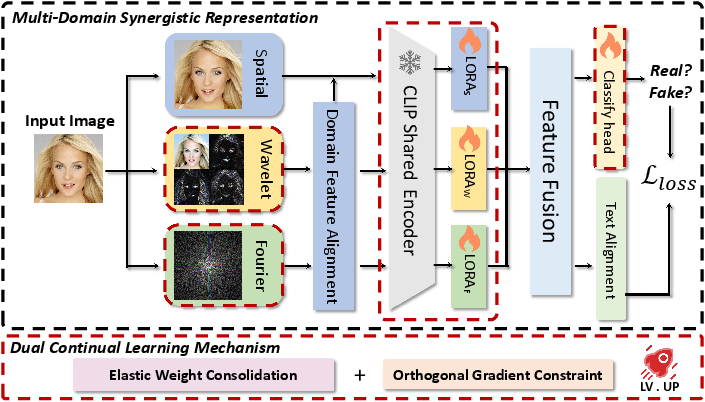
Figure 3: The Face-D2CL pipeline, illustrating the sequential application of spatial/wavelet/Fourier feature extraction, alignment, domain-specific LoRA encoding, fusion, and dual continual learning.
Theoretical and Practical Implications
The integration of multitier domain knowledge harnesses complementary discriminative signals unavailable to single-domain detectors, and the decoupling of parameter protection (EWC) from task adaptation (OGC on LoRA) yields a method that is replay-free and parameter-efficient. The class-aware EWC regularization acknowledges the non-symmetric distributional properties of real and fake classes, which is critical as deepfakes diversify with new generative paradigms.
The demonstrated robustness to out-of-distribution forgeries and image perturbations highlights practical suitability for deployment settings, especially where data privacy restricts replay or when new manipulation types emerge rapidly in the wild.
Future Directions
Potential exploration includes:
- Extending multi-domain adaptation to incorporate color space transforms, motion cues (for videos), or ensemble frequency analyses.
- Further generalization via automated domain prompt alignment using large-scale vision–LLMs or prompt-tuning for task-conditioned detection.
- Online lifelong learning scenarios where the task boundary is not explicit, and unsupervised or self-supervised discovery of new forgery classes is required.
Conclusion
Face-D2CL advances the state-of-the-art in continual DeepFake detection through synergistic multi-domain representation and a principled dual continual learning mechanism. Empirical results demonstrate superior stability, adaptability, and robustness in both seen and unseen manipulation scenarios, without reliance on historical data replay or model growth. The framework is extensible to new domains and tasks, offering a scalable path for future research in open-world synthetic media forensics.
(2604.08159)