- The paper introduces a multi-dimensional optimization framework that adjusts the trade-off between completeness and conciseness in summary generation.
- It employs a composite loss function—combining margin ranking, maximum scoring, and control-oriented losses—to align model likelihoods with quality scores.
- Empirical results across various domains validate robust controllability and high ranking alignment, confirming the framework's effectiveness.
Score-Ranked, Controllable Summarization via Fine-Grained Multi-Dimensional Optimization
Motivation and Research Problem
The automatic generation of concise, yet complete, summaries from text is a central problem in sequence transensing with broad applications. Traditional neural summarization approaches have been optimized against proxies such as token-level likelihoods or n-gram-based metrics, which are known to be poorly aligned with human judgments of semantic fidelity, faithfulness, and balance. Recent advances in model-based evaluation, specifically using fine-grained metrics like completeness and conciseness from LLM-based evaluators (e.g., FineSurE), afford more nuanced assessment but have yet to be fully leveraged to control generation along specific summary dimensions.
This work directly addresses the challenge of multidimensional control in summarization: adjusting the trade-off between completeness and conciseness at generation time, in light of their inherent antagonistic relationship. Notably, the authors define a learning framework allowing a single model to yield summaries tailored, via prompts, to prioritize completeness, conciseness, or a balanced configuration.

Figure 1: Summaries of the abstract prioritizing completeness, conciseness, and balance.
Methodology and Learning Objective
The technical framework reframes summary generation as a problem of aligning conditional log-likelihoods with black-box model-based scores for multiple quality dimensions. Model control occurs via a prompt variable Z so that pθ(Y∣X,Z) is modulated according to the desired summary trait.
The central loss is composed of three parts:
- Margin Ranking Loss (MR): Enforces consistency between the model’s likelihood ranking and the ranking by model-based scores (e.g., summaries rated as higher quality by FineSurE should have higher log-probabilities). Pairwise margin-penalties encourage robust separation.
- Maximum Scoring Loss (MS): Drives the generator to produce summaries whose model-based score matches or exceeds the best among a set of diverse candidates.
- Control-Oriented Loss (CO): Explicitly leverages the ratio of completeness to conciseness (or other metric pairs) in the objective. During training, the ratio is shaped by the control prompt to increase, decrease, or equilibrate, depending on whether completeness, conciseness, or balance is the instructed priority.
The overall loss, LTotal, is a weighted sum of these objectives, with hyperparameters tuned via cross-validation. Training operates in a LoRA fine-tuning regime on open-source backbones (LLaMA, Qwen, Mistral), incorporating candidate diversity via reference summary sampling and nucleus-sampled predictions.
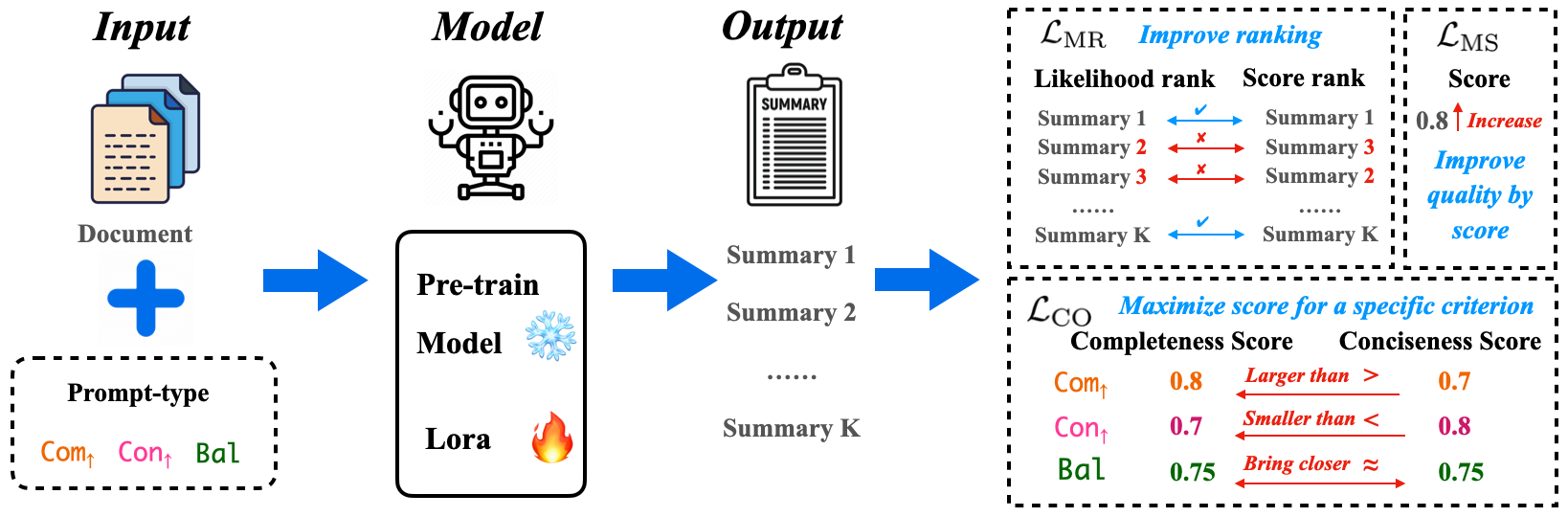
Figure 2: Model architecture and loss functions. Losses computed over K candidate summaries generated according to specified prompt/control type.
Experimental Results
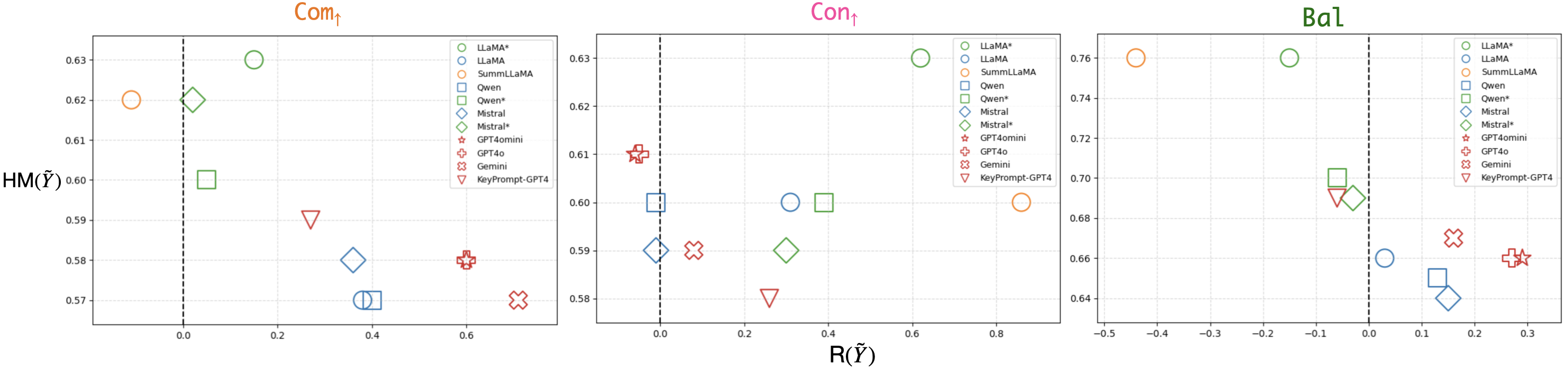
Quality–Control Trade-off
Empirical validation is conducted on a comprehensive suite of in-domain (WikiHow, CNN/DM, DialogSum) and out-of-domain (OpoSum, MeQSum) datasets. The model is evaluated with harmonic mean of FineSurE completeness and conciseness (HM(Y~)), control ratio (R(Y~)), and correlation between log-likelihoods and model-based evaluation scores.
Key findings include:
Qualitative Analysis and Distributions
Distributions over quality–control axes visualize the trade-offs and controllability:
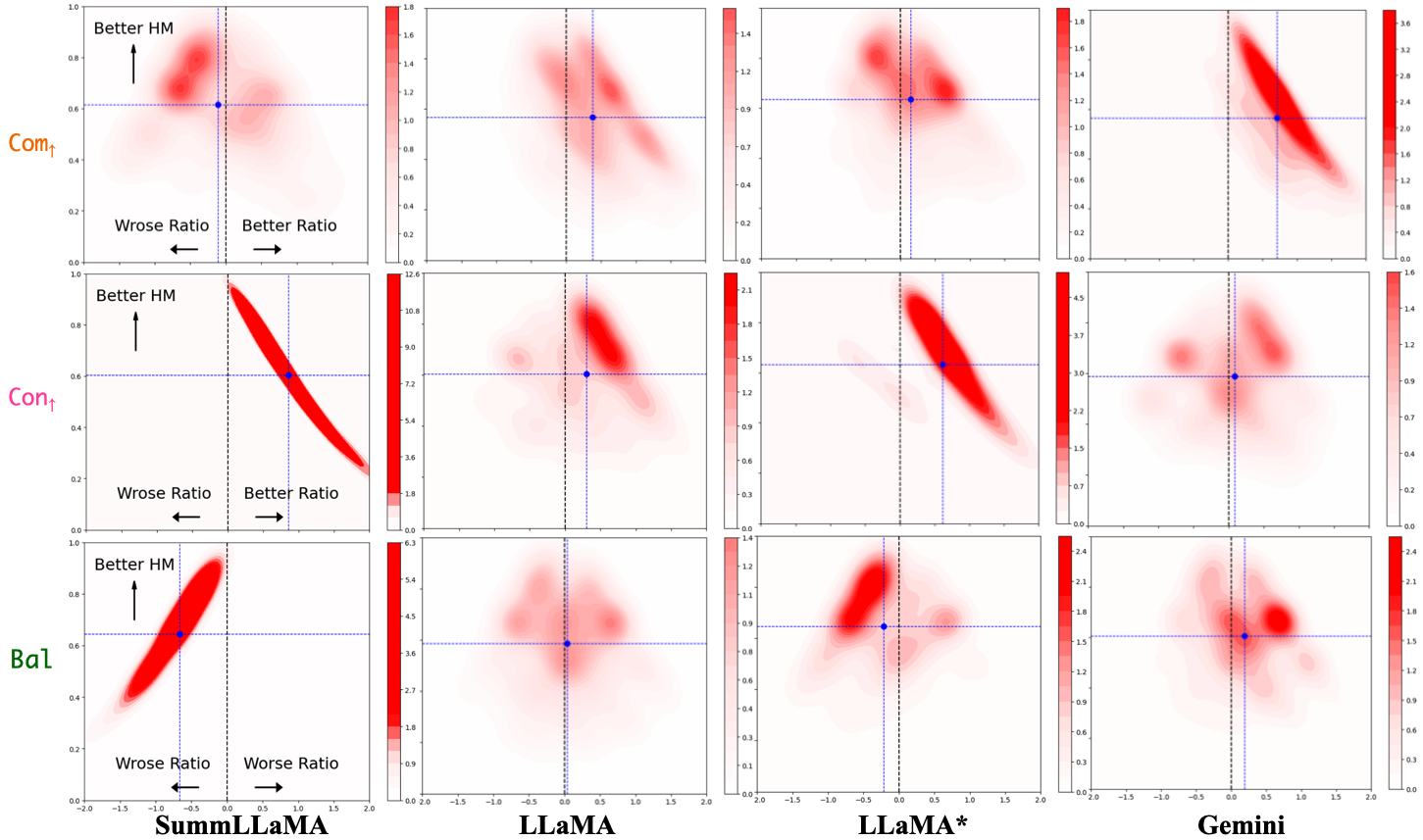
Figure 4: Distributions of Z0 visualizing density and bias per control setting.
Contour plots and score distributions show, for optimal settings and control, highly desirable clustering in regions of high summary quality and controlled metric, which prior baselines do not achieve.
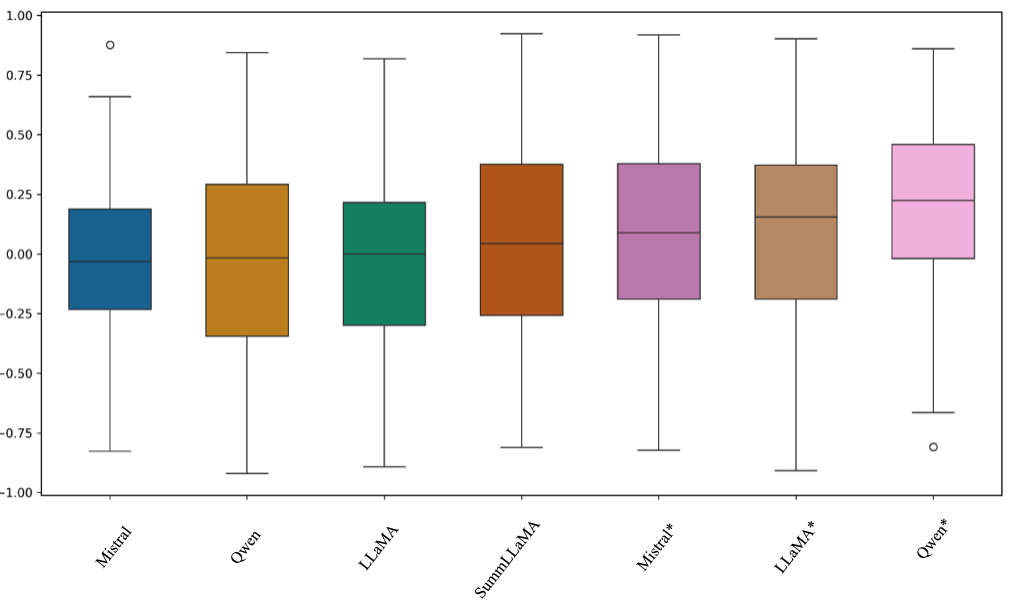
Figure 5: Distribution of Spearman correlations between model likelihood and model-based scores for models sorted by median.
Ablation and Human Alignment
Ablation experiments confirm that all objective components (MR, MS, CO) are necessary to achieve both high ranking alignment and controllability. Human studies further indicate that the model’s controlled outputs are robustly aligned with annotator judgments, achieving average annotation alignment accuracy of 0.85 and Spearman correlation of 0.72.
Domain Generalization
Scattered plots across domains (DialogSum, CNN/DM, WikiHow) and across control settings demonstrate the approach’s consistency, with fine-tuned open models approaching the quality and control attainable by black-box commercial APIs. Further, out-of-domain performance remains strong—reinforcing the modularity and generality of the score-alignment method.
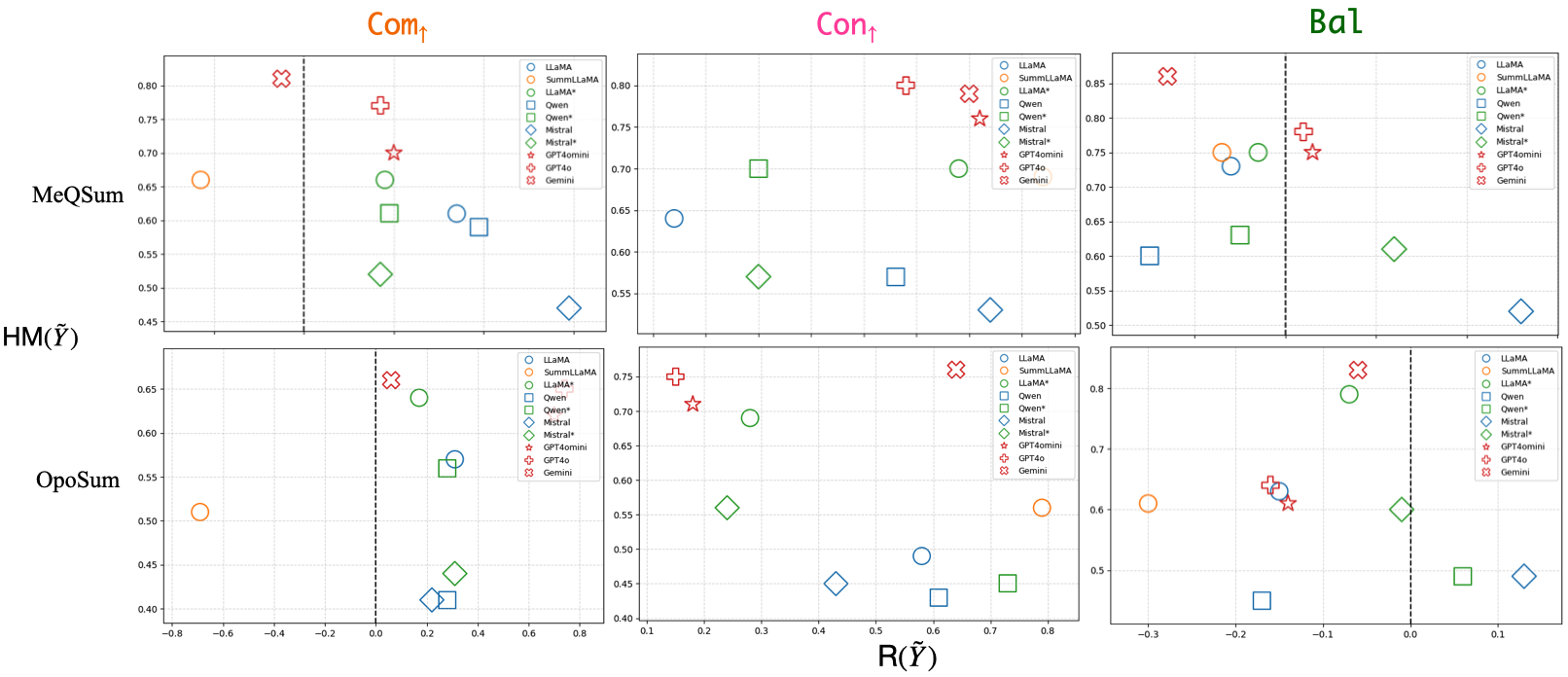
Figure 6: Scatter plot of model performance on out-of-domain data (MeQSum; OpoSum), showing cross-domain generalization under different controls.
Implications and Future Directions
The work formalizes controllable, multidimensional summary generation via scalable objectives that move beyond both likelihood-based training and RL-fitted reward models. Unlike RLHF, which requires policy-reference pairs (as in PPO, GRPO), this approach leverages only the black-box scorer and diverse candidate sets, yielding substantial resource savings and facilitating straightforward application to a broad class of controllable generation tasks.
Potential axes for future research include:
- Integration of additional fine-grained evaluator signals (e.g., style, coherence, relevance, domain-specific preferences).
- Extension to scenarios with more than two simultaneously controlled dimensions.
- Application to high-latency, high-cost evaluators (e.g., human-in-the-loop, multi-model committees).
- Investigation of interaction between scorer quality, candidate diversity, and controllable range in emergent models.
Conclusion
This paper establishes a practical, generalizable method for controlling summary generation across multiple quality dimensions by aligning likelihoods with black-box, model-based evaluators. Evidence is provided for control efficacy, improved summary ranking, and high-quality generation both in- and out-of-domain. The framework’s modularity, efficiency over RL approaches, and empirical strength indicate a robust foundation for future research on fine-grained controllable text generation.