- The paper introduces a reranking-based generation method that improves summary coverage and faithfulness using preference tuning.
- It demonstrates that language model-based metrics outperform traditional metrics, validated by a new human-annotated testbed.
- DPO+RR achieves the highest performance in both coverage and faithfulness compared to zero-shot and prompting-based methods.
Reranking-based Generation for Unbiased Perspective Summarization
Introduction
The paper "Reranking-based Generation for Unbiased Perspective Summarization" addresses the challenges of creating summaries that faithfully represent diverse perspectives, particularly in political contexts. It critiques existing evaluation frameworks, which often rely on traditional metrics like ROUGE and BERTScore without validating their applicability to perspective summarization. The authors propose a new testbed for evaluating metric reliability using human annotations and demonstrate that LLM-based metrics outperform traditionally used methods. The paper highlights reranking-based generation methods, supplemented by preference tuning, as effective strategies for improving the coverage and faithfulness of summaries.
Identifying Reliable Metrics
Metric Definition and Evaluation
To evaluate the efficacy of existing metrics for perspective summarization, the authors construct a benchmarking test set using human annotations. This involves highlighting key excerpts from documents and paraphrasing these excerpts into concise key points. They assess coverage (including all key points) and faithfulness (excluding unsupported content). The authors argue that LLM-based metrics such as AlignScore and prompting-based scoring methods serve as strong evaluators, while traditional metrics underperform. The evaluation framework is critical for benchmarking improvement capacities in summarization models.
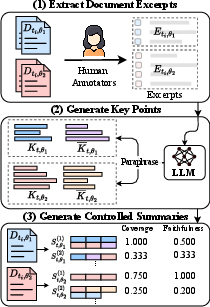
Figure 1: Pipeline for curating the synthetic testbed for metric evaluation. Annotators extract the most important excerpts Et,θ.
Evaluation of Summarization Methods
Methods Explored
The paper explores several methods for generating perspective summaries:
- Prompting-Based Approaches: Techniques like Multi-Agent Debate and Self-Refine improve factual consistency via iterative generation and self-feedback.
- Mechanistic Approach: PINE modifies attention to focus on key input segments, attempting to mitigate biases.
- Reranking Generations: Selection of the best summary from multiple generated candidates using proxy metrics.
Preference Tuning
Utilizing Direct Preference Optimization (DPO) and reranking-generated data enhances summary generation by refining models based on synthetic data. This approach shows improvements in faithfulness, indicating that even without large-scale labeled data, these methods can facilitate effective summarization.
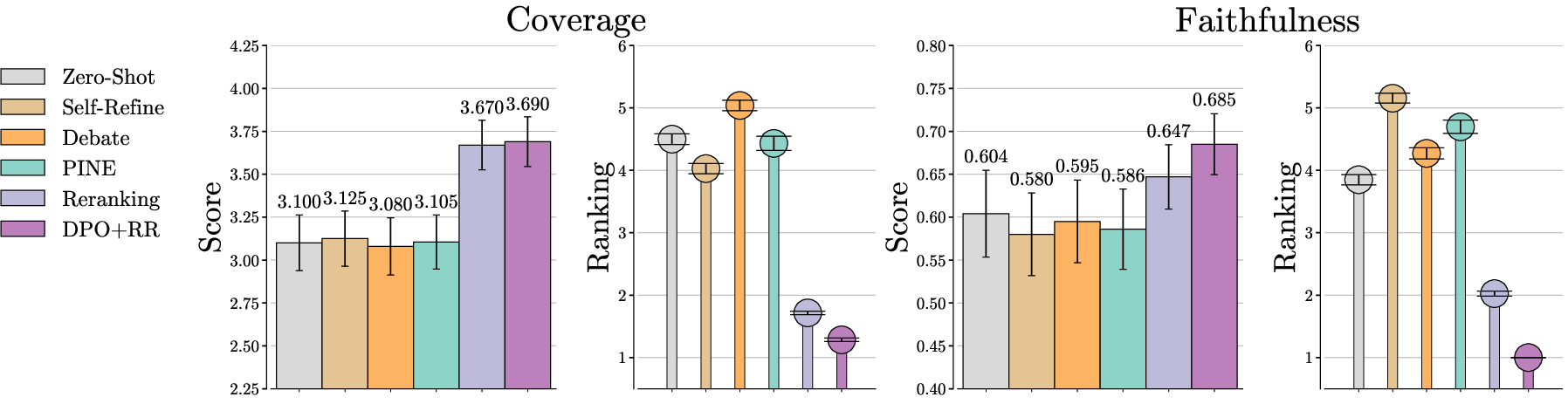
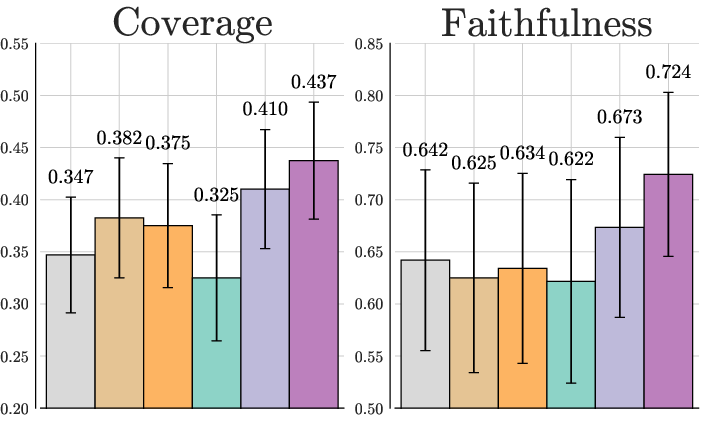
Figure 2: Automatic evaluation results. Higher values indicate better performance for Score (Bars), while lower values are better for Ranking (Lolipops). Coverage scores range from 1 to 5, while faithfulness scores lie in the interval [0,1]. DPO+RR achieves the highest scores and best average rank, followed by Reranking. Other methods show similar performance in both coverage and faithfulness.
Results
Automatic Evaluation
The study finds that reranking-based methods outperform others, including prompting frameworks. DPO+RR achieves the highest performance across both coverage and faithfulness attributes, with significant gains compared to zero-shot inference methods. Reranking mechanisms reveal the importance of evaluating multiple generation outputs, especially in political perspective summarization.
Human Evaluation
Human evaluations corroborate automatic results, showing DPO+RR's superiority in both coverage and faithfulness. This process emphasizes the importance of using human judgment alongside automatic metrics for more reliable evaluation in complex summarization tasks.
Analysis and Discussion
Summary Characteristics
The generated summaries' characteristics were analyzed, focusing on key point inclusion, abstractiveness, and summary length. Reranking methods show a balance between abstractiveness and faithfulness, unlike PINE, which tends towards more extractive summaries.
Ablation Studies
Prompting-based methods consistently underperform compared to reranking-based strategies. Increasing agents and rounds in Multi-Agent Debate improves coverage but not faithfulness, demonstrating that reranking remains preferable even in high-resource settings.
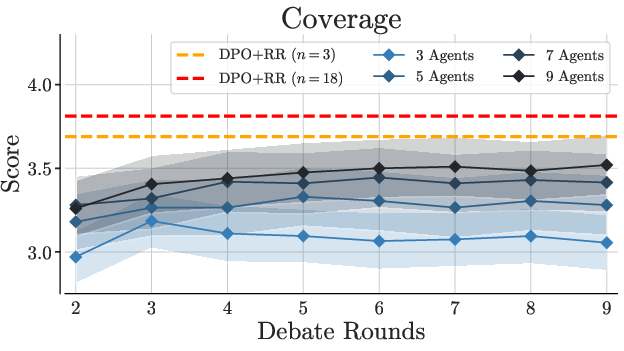
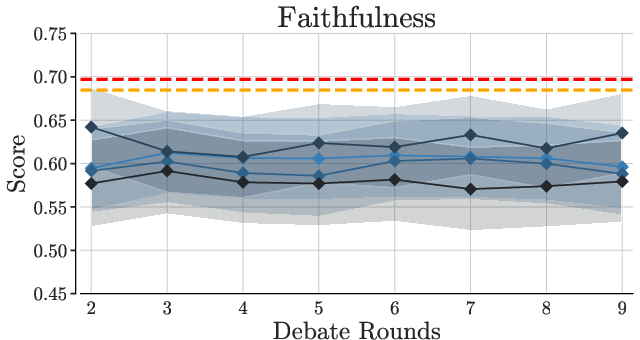
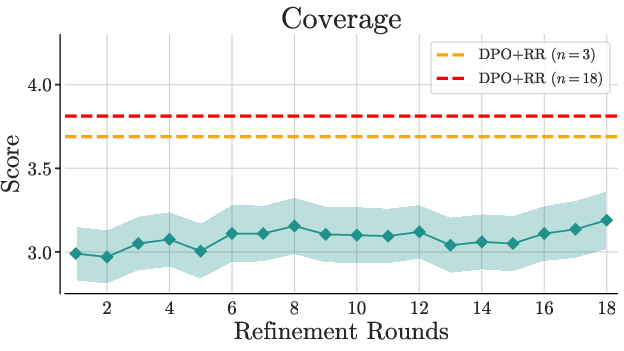
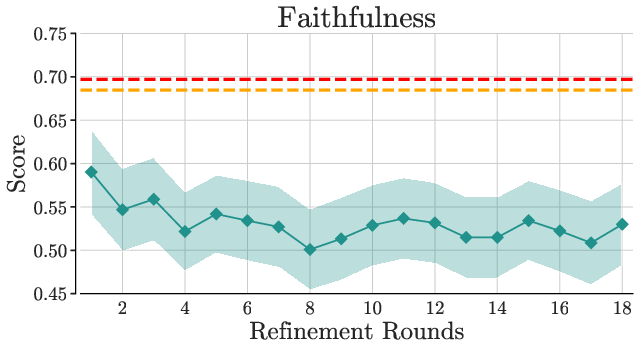
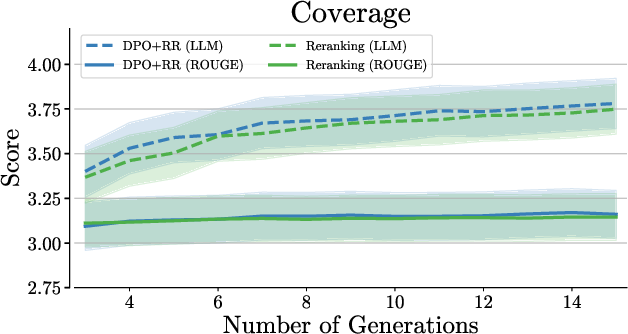
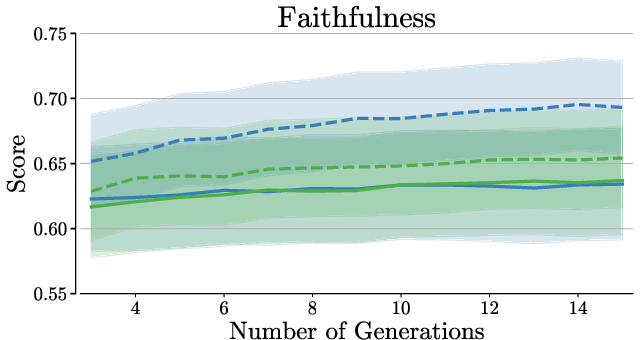
Figure 3: Debate performance across varying agent counts and debate rounds.
Conclusion
The paper highlights the limitations of traditional summarization metrics and proposes reranking-based generation as an effective strategy for unbiased perspective summarization. By identifying reliable metrics and demonstrating the success of preference tuning on synthetic data, the study advances methodologies for high-quality summary generation, especially in politicized contexts. Future research could explore these methods' applicability to varied domains beyond political perspectives.