- The paper introduces DreamShot, a framework that uses video diffusion priors to achieve coherent storyboard synthesis across multiple shots.
- It integrates a Video-VAE with a Diffusion Transformer and employs Role-Attention Consistency Loss to maintain identity and scene consistency.
- Extensive experiments demonstrate state-of-the-art performance on metrics like CIDS and CSD, highlighting its robustness in narrative-driven visual storytelling.
DreamShot: Personalized Storyboard Synthesis with Video Diffusion Prior
Motivation and Problem Statement
Conventional AIGC paradigms in visual storytelling have primarily relied on text-to-image or text-to-video diffusion models. These methods excel at producing compelling imagery but are fundamentally inadequate for generating coherent multi-shot narratives due to an inability to preserve role consistency, temporal coherence, and semantic continuity across discrete shots. Dense video synthesis is computationally wasteful and inflexible, while image diffusion models lack the temporal modeling essential for narrative structure (Figure 1).
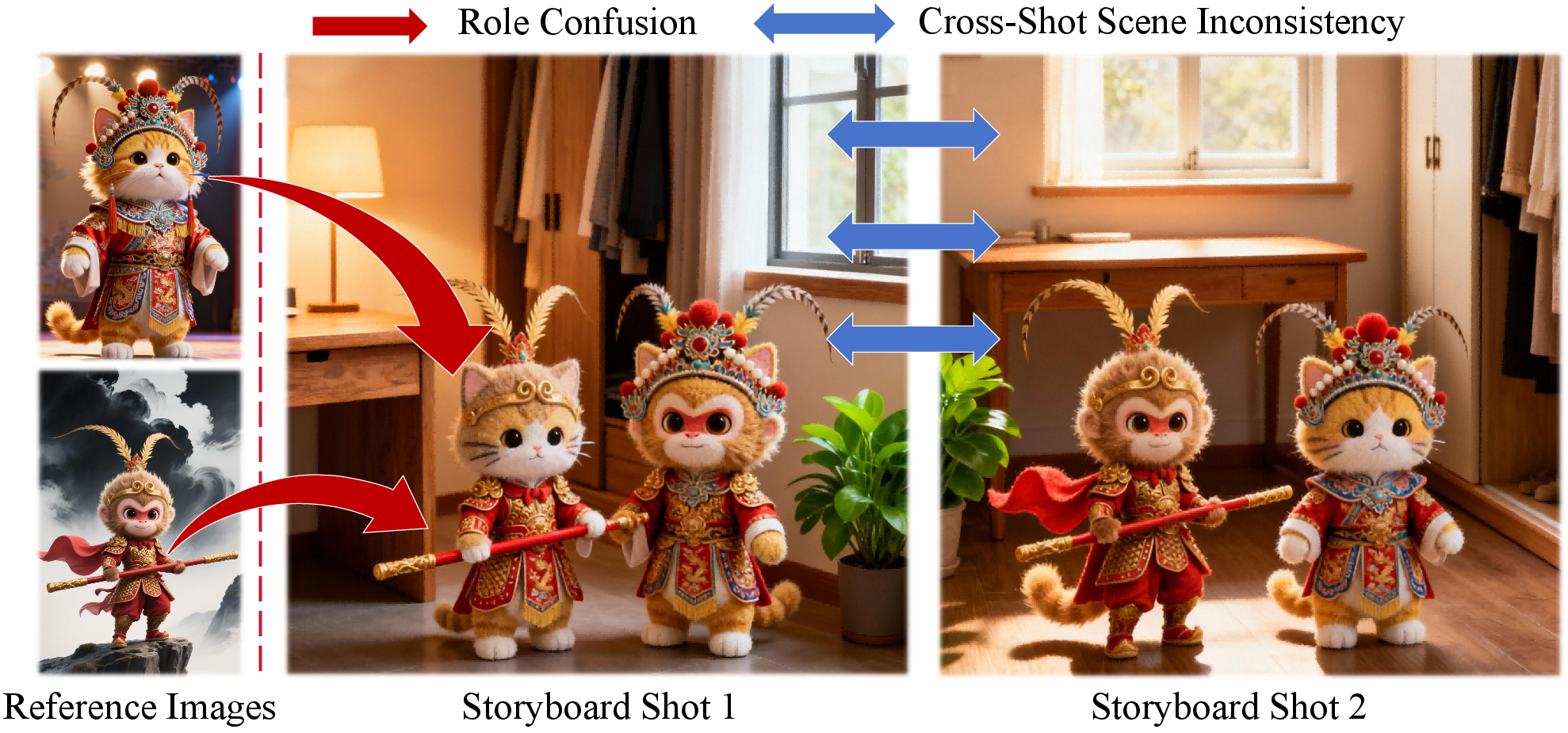
Figure 1: Image-based models often suffer from role confusion and scene inconsistency across shots.
Storyboard synthesis provides an efficient intermediate representation for cinematic visual storytelling, emphasizing shot composition and narrative over dense frame redundancy. However, existing methods—such as AnyStory, UNO, InstantID, and StoryMaker—suffer from feature entanglement, poor multi-reference personalization, and limited scene control. The absence of explicit temporal modeling across shots remains the central obstacle.
DreamShot Framework and Methodology
DreamShot leverages a video diffusion prior to address the temporal and contextual deficiencies of previous storyboard generation systems. Its architecture synergizes a spatio-temporal Video-VAE (e.g., Wan-VAE) for latent sequence construction with a Diffusion Transformer (DiT) backbone for autoregressive storyboard synthesis (Figure 2). The integration of strong video priors allows the system to model global narrative flow across variable-length sequences.
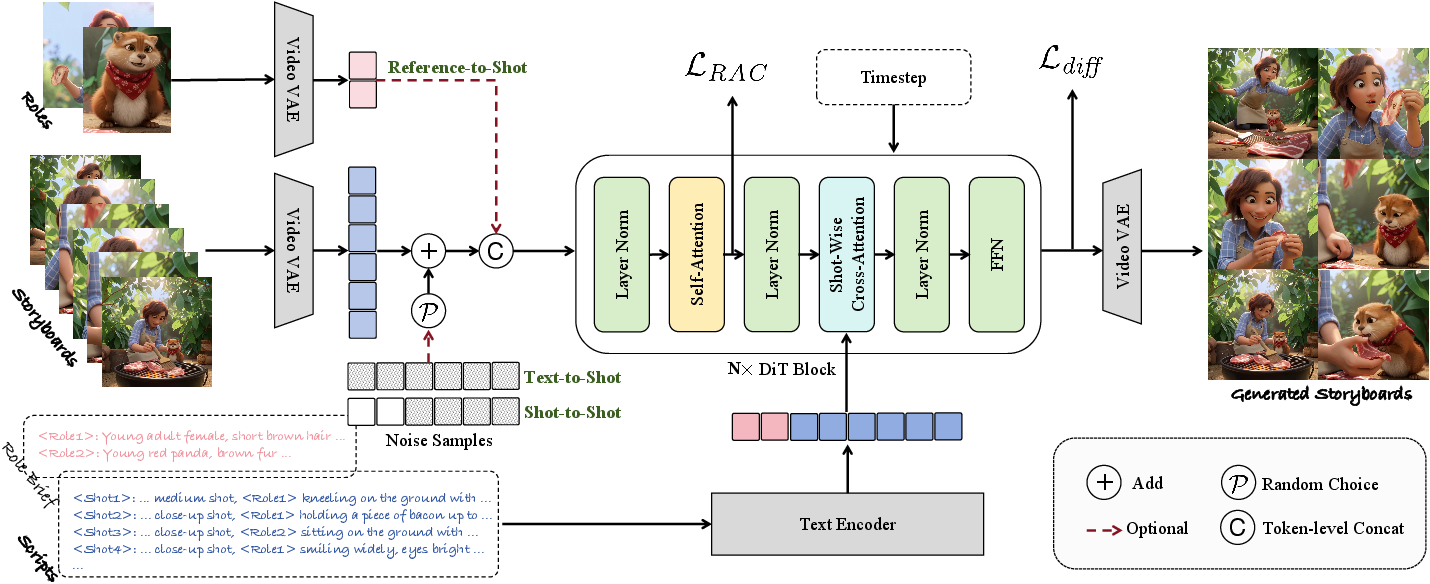
Figure 2: The DreamShot framework combines Video-VAE and DiT for flexible generation in reference-to-shot, text-to-shot, and shot-to-shot modes with explicit role and scene conditioning.
Key architectural elements:
- Temporal Causal Encoding: Reference and storyboard images are encoded via causal video VAE. Each storyboard shot is repeated according to the VAE's temporal stride for coherent latent sequencing.
- Reference and Shot Token Ordering: Reference latents precede shot latents, exploiting 3D RoPE in the DiT and propagating identity forward in sequence, a critical improvement over 2D image-only diffusion models.
- Shot-Wise Cross-Attention: This mechanism enables granular vision-language alignment between individual shot latents and their corresponding text prompts, enhancing semantic controllability at the shot level.
- Mix-Mode Diffusion Training: DreamShot jointly optimizes across text-to-shot, reference-to-shot, and shot-to-shot paradigms. This heterogeneity in supervision enables robust generalization and controllable synthesis.
Role-Attention Consistency Loss (RACL)
Maintaining identity and disentanglement among multiple roles across shots is a core challenge in story visualization. DreamShot introduces the Role-Attention Consistency Loss (RACL) to regularize cross-role attention (Figure 3). RACL uses ArcFace and VLM-based matching to derive one-to-one correspondences between reference images and their target shots, applying saliency and segmentation masks to supervise attention maps.
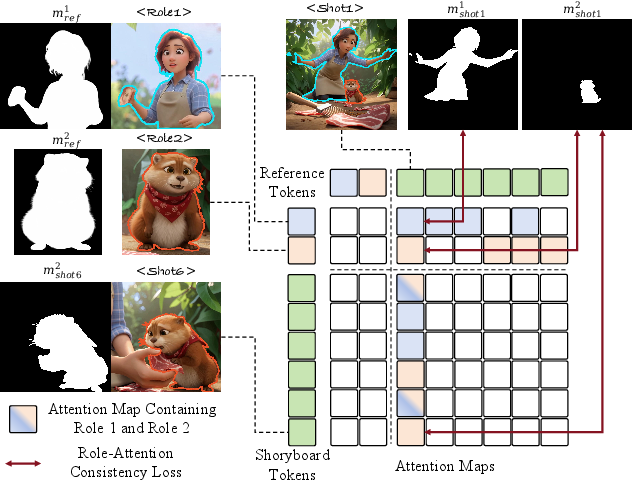
Figure 3: The RACL supervises attention maps to align reference-shot pairs, explicitly penalizing cross-role entanglements and improving multi-identity consistency.
RACL penalizes attention dispersion and rewards focused correspondence via a binary cross-entropy loss over matched spatial masks. The RACL term is integrated into the joint objective with a tunable λ coefficient, empirically balancing identity consistency and aesthetic fidelity.
Data Construction Pipeline
A high-quality, scalable dataset is foundational for supervised learning in storyboard synthesis. DreamShot introduces a novel multi-stage dataset pipeline (Figure 4), consisting of:
- Data Source Selection: 40K real videos and 50K AIGC-generated ones ensure stylistic and narrative diversity.
- Keyframe Extraction & Scene Grouping: Utilizes PySceneDetect, Laplacian scoring, VLM clustering, and quality filtering to extract narratively coherent shots.
- Role Extraction & Augmentation: Instance segmentation, cross-scene character matching with ArcFace, and multi-view synthetic augmentation provide robust multi-reference supervision.
- Shot & Reference Annotation: VLMs annotate perspective, scene, action, and fine-grained character attributes for every shot and reference.
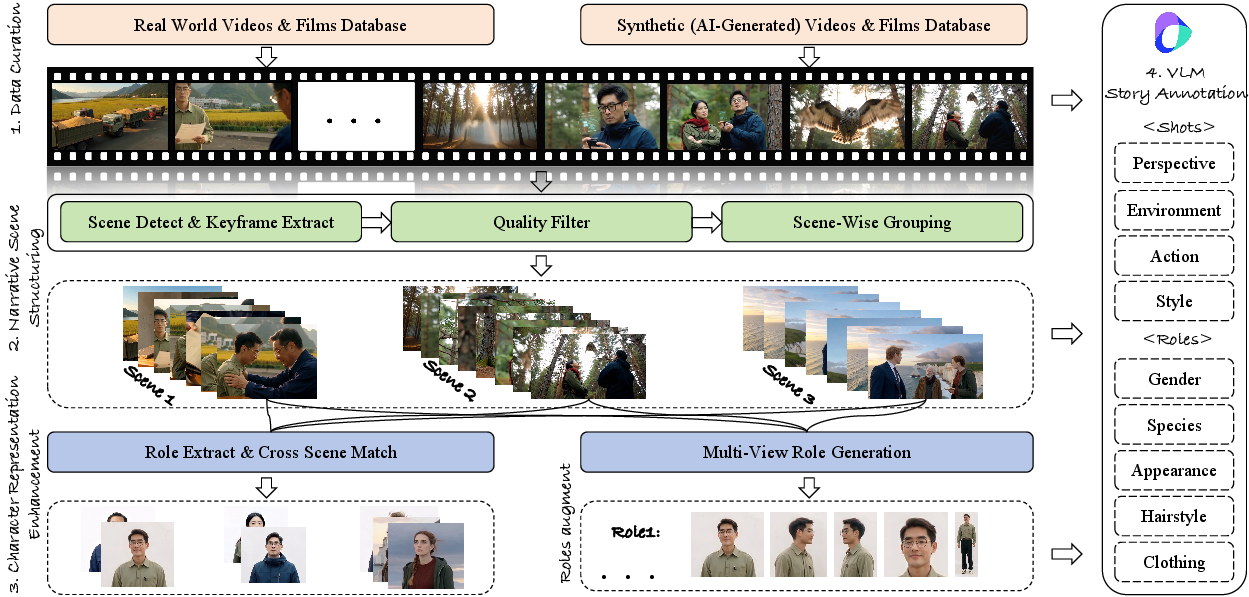
Figure 4: Overview of the DreamShot data construction pipeline, supporting rich narrative diversity, identity control, and scene consistency.
Experimental Results
Quantitative Benchmarks
DreamShot achieves state-of-the-art results on both the internal DreamShot Test Set and the public VistoryBench benchmark. Key metrics include:
- CIDS (Character Identification Similarity): DreamShot achieves up to 65.6 (Self) and 60.2 (Cross) on VistoryBench, exceeding previous methods' role consistency.
- CSD (Contrastive Style Descriptors): Scores surpass 61 in style self-similarity, reflecting superior scene and stylistic coherence.
- Alignment and AES Scores: The model displays robustness in prompt-image alignment and maintains high aesthetic quality.
DreamShot's improvements are particularly pronounced in role consistency and scene alignment across multi-shot sequences, clearly demonstrating the impact of leveraging video priors and explicit role attention regularization.
Qualitative Evaluation

Figure 5: DreamShot preserves environmental and stylistic consistency under both reference-to-shot and text-to-shot conditions, outperforming prior story visualization systems.

Figure 6: In all modes (reference-to-shot, text-to-shot, shot-to-shot), DreamShot preserves identity, accommodates prompt changes, and maintains stylistic continuity.
Further visualizations (Figures 13, 14, 15) highlight DreamShot's generalization capacity, compositional accuracy, and current limitations in rendering dynamic, high-motion scenes.
Ablation Analysis
Comprehensive ablations validate the efficacy of the RACL term and critical model choices:
- Using RACL yields a +3.3 boost in CIDS-Cross, and attention map visualizations confirm improved disentanglement.
- Reference positioning at the sequence head (rather than via positional offsets or at the tail) is optimal for identity propagation.
- Reference-free classifier-free guidance with properly tuned ω1, ω2 accentuates role fidelity without degrading aesthetics (Figure 7).
- LoRA rank tuning reinforces text alignment without sacrificing visual quality (Figure 8).
Implications, Limitations, and Future Directions
Practical Implications:
DreamShot represents a significant advance toward practical, controllable storyboard synthesis for narrative-driven media. Its multi-mode operation supports flexible conditioning (text, reference, continuation), and the dataset pipeline provides a blueprint for future scalable, annotated data creation.
Limitations:
- Generalization in ultra-long shot sequences is limited by the training distribution skew toward shorter stories.
- Dynamic action frames with motion blur are underrepresented due to the necessary rejection of low-clarity frames in the current data curation stage (Figure 9).
- Output resolution is constrained by the foundation video models, currently not on par with top image diffusion models.
Future Developments:
- Augmenting the dataset with longer narratives and explicit motion-rich segments.
- Exploring self-forcing or autoregressive error-correction to improve character drift across extended stories.
- Leveraging emerging high-res video diffusion architectures and adaptive resolution decoding to bridge the quality gap.
Conclusion
DreamShot introduces a rigorously engineered, video prior-driven approach for personalized storyboard generation. By unifying multi-role reference handling, explicit temporal modeling, and comprehensive data annotation, it achieves superior shot consistency and narrative coherence relative to past image-centric paradigms. The methodology, dataset, and experimental insights prescribed by DreamShot set a new standard for controllable visual storytelling systems and inform ongoing research in multimodal, narrative-generative machine intelligence.
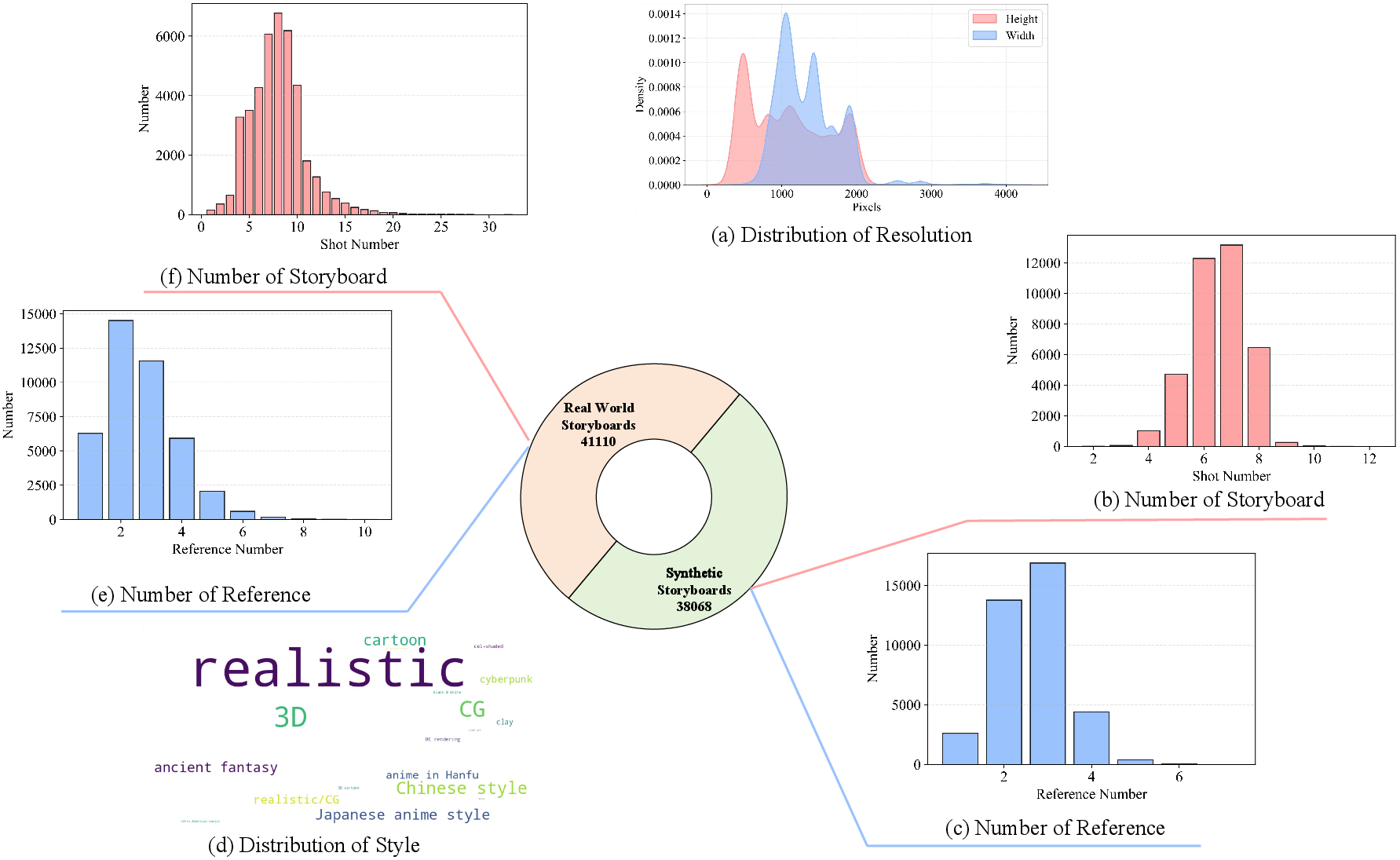
Figure 10: Data statistics illustrate the resolution, shot count, reference diversity, and stylistic range of the assembled DreamShot dataset.