- The paper introduces a multi-model, multi-prompt annotation pipeline that creates the DDEP dataset with dynamic, sample-level emotion and personality profiling.
- It proposes Rel-DDEP, a reliability-weighted multimodal fusion framework that uses uncertainty quantification to adaptively fuse cues for enhanced deception detection.
- Experimental results show that dynamic profiling and adaptive fusion significantly improve F1 scores in both deception and personality detection tasks.
Dynamic Emotion and Personality Profiling for Multimodal Deception Detection
Introduction
Automated deception detection poses complex challenges in representation learning, as effective identification relies on nuanced, context-specific social cues across modalities. While prior multimodal deception datasets [cai2024mdpe] included personality and emotion annotations, they are typically subject-level and fail to capture the dynamic variations critical to real-world deception detection scenarios. The paper "Dynamic Emotion and Personality Profiling for Multimodal Deception Detection" (2604.17037) presents substantive methodological advances to address this deficit. The work introduces (1) a multi-model, multi-prompt annotation pipeline yielding the DDEP dataset with sample-level emotion and personality labels, and (2) Rel-DDEP, a reliability-weighted multimodal fusion framework that leverages uncertainty quantification to optimize joint detection of deception, emotion, and personality.
Motivation and Observational Analysis
Most existing deception detection frameworks operate under the constraint of static, subject-level emotion and personality attributes, which obfuscates the situational volatility intrinsic to deceptive behavior. Detailed empirical and visualization analyses demonstrate that this static treatment severely limits discriminative capacity. As illustrated, for the same individual, emotion and apparent personality indicators can diverge significantly between instances, producing essential cues for truthful versus deceptive distinction.

Figure 1: Examples of two data instances for the same subject demonstrate divergent emotion and personality cues central to deception recognition.
Systematic t-SNE visualizations of sample distributions further expose boundary blurring for fixed-label annotation, while dynamic, multi-label emotion and sample-level personality profiling leads to cluster separation and increased correct predictions (from 32 to 141 samples in a controlled setting).
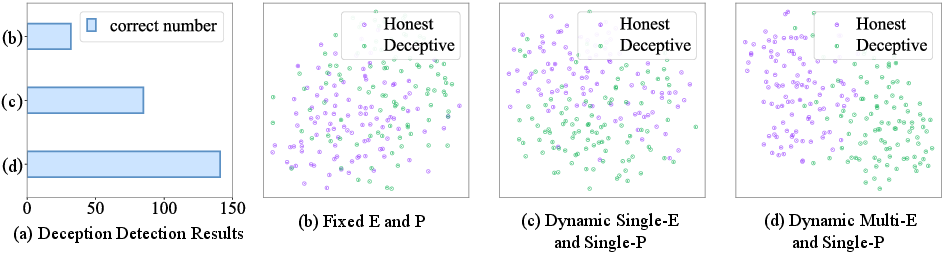
Figure 2: Visualization of feature separability improves markedly as annotation granularity moves from subject-level fixed labels to dynamic sample-level annotation with multi-label emotions.
DDEP Dataset Construction: Multi-Model, Multi-Prompt Annotation
Addressing the annotation bottleneck, the workflow employs a hierarchical annotation and validation protocol. Multiple LLMs (e.g., GPT-4o, Llama3, VideoLlama3, Qwen2 Audio) are prompted with diversely phrased instructions targeting both holistic and cue-specific emotion/personality inference. Outputs are aggregated via a voting and scoring mechanism incorporating kappa-based consistency, entropy-based uncertainty, and LLM self-assessed confidence, establishing a composite quality score.
Ambiguous cases failing the confidence threshold are escalated for review by multimodal LLMs, and subsequently, if needed, expert human annotation with inter-annotator agreement verification (kappa = 0.85). This pipeline ensures high-quality, context-sensitive multimodal instance annotation.
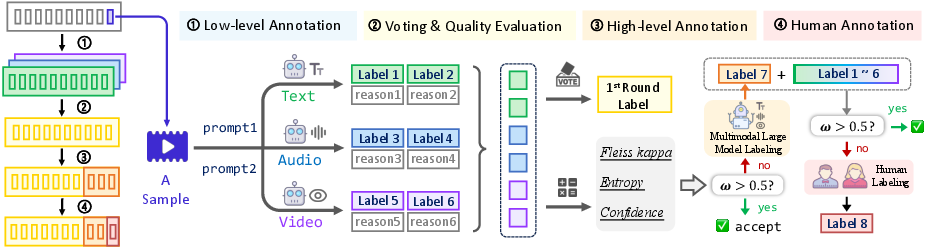
Figure 3: The hierarchical annotation pipeline integrates multiple LLMs, prompt diversity, quality scoring, and expert arbitration.
Quantitative distributions reveal a predominance of "Openness" personality, diverse emotional tags, and balanced deception classes, reflecting the complexity of the source environment.
Rel-DDEP: Adaptive Reliability-Weighted Fusion Framework
The proposed architecture, Rel-DDEP, comprises:
- Feature Extraction: State-of-the-art unimodal representations (BaiChuan for text, CLIP/ViT for vision, Wav2vec2/Hubert/WavLM for audio).
- Uncertainty Modeling: Each modality's embedding is projected into a high-dimensional Gaussian, parameterized by learned μ and σ, to quantify per-sample predictive uncertainty.
- Reliability-Weighted Fusion: Modalities are fused via weights inversely proportional to uncertainty, emphasizing reliable cues adaptively at inference time.
- Auxiliary Modules: An alignment module explicitly penalizes divergence between estimated uncertainty and observed prediction errors; a sorting constraint module enforces coherent ranking between fusion weights and uncertainty orderings.
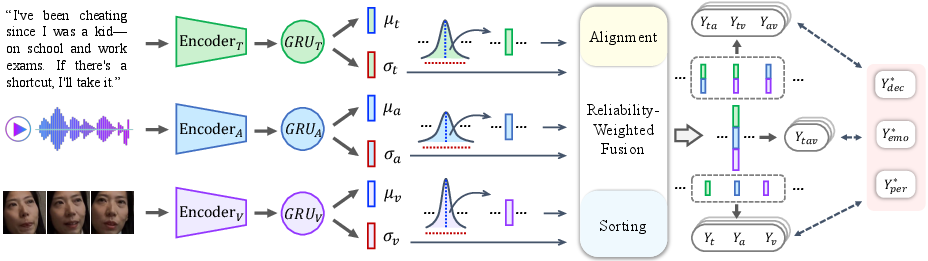
Figure 4: Overview of Rel-DDEP, illustrating feature extraction, uncertainty quantification, reliability-weighted fusion, and auxiliary regularization.
Experimental Results
Comprehensive benchmarks on both the legacy MDPE and the new DDEP datasets validate three primary claims:
- Annotating dynamic, sample-level multimodal emotion and personality labels yields substantive information gain and improved separability, significantly raising F1 in deception detection (by 2.53%).
- The reliability-weighted fusion module contributes further, outperforming architecture-matched models with naive, static, or single-modal fusion, confirming the utility of adaptive uncertainty modeling.
- Joint learning of deception, emotion, and personality produces mutual benefit across all tasks; for personality detection in particular, the F1 gain is pronounced (9.3%).
Ablation studies isolate the contributions of the alignment and sorting constraint modules, both of which further rationalize fusion weight allocation and stabilize cross-task gradients.
Implications and Future Directions
The work demonstrates the critical value of high-granularity, contextually responsive annotation for complex social AI tasks. The adaptation and integration of reliability-weighted fusion—originally deployed mainly in low-level vision and robust classification—establishes its utility for multimodal behavioral analysis under uncertainty. Constructing DDEP via carefully verified LLM and expert pipelines sets a new baseline for multimodal deception research, while Rel-DDEP forms a template for reliability-aware, multi-head prediction models.
In practical deployment, such models have strong implications for automated moderation, forensic analysis, and human-computer interaction scenarios requiring nuanced attribution of intent or affect. Theoretically, the findings support the position that cross-modal context alignment and task co-adaptation are essential for high-fidelity behavioral inference.
Future directions include investigating more flexible, dynamic multi-task learning architectures to unlock further task-specific synergy and developing higher-order reasoning mechanisms for temporal and relational dynamics.
Conclusion
This paper provides substantial advances in both dataset construction and modeling for multimodal deception detection, demonstrating that dynamic, fine-grained, and uncertainty-aware approaches yield measurable improvements. The work lays critical groundwork for future research targeting nuanced joint behavioral inference across social AI domains.