- The paper introduces a two-stage framework combining flow-matching voice anonymization (F3-VA) and generative speech editing (SECA) to balance privacy protection with data utility.
- It demonstrates minimal degradation in ASR, TTS, and SER performance, achieving low WER and robust acoustic continuity compared to traditional approaches.
- The architecture employs stochastic flow-matching with tunable speaker weights, offering robust privacy guarantees against both acoustic and content-based re-identification attacks.
Utility-Preserved Speech Anonymization: A Two-Stage Framework
Introduction
The scaling of foundation speech models and the proliferation of machine learning applications have foregrounded the need for effective privacy-preserving mechanisms in speech data processing. Conventional anonymization pipelines typically introduce significant degradation in linguistic content fidelity, acoustic continuity, and speaker diversity, undermining the usability of anonymized data for tasks such as ASR, TTS, and SER. "Anonymization, Not Elimination: Utility-Preserved Speech Anonymization" (2604.17000) proposes an integrated two-stage anonymization pipeline that protects both content and voice privacy, specifically targeting robust privacy guarantees and retention of utility for downstream learning applications.
Two-Stage Privacy Protection Framework
The presented framework specifies sequential, orthogonally designed modules for voice and content privacy, ensuring flexibility and completeness across varied application scenarios. In interactive settings (e.g., conversational agents or telemedicine), voice anonymization is applied to safeguard identity while preserving semantic content for fluid interaction. For storage or model training, content anonymization is further employed to excise PII and prevent content-based re-identification.
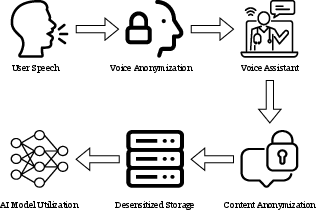
Figure 1: The two-stage privacy framework first anonymizes speaker identity for interactive scenarios and subsequently anonymizes content semantics for storage and model training.
Voice Anonymization: Flow-Matching Speaker Embedding (F3-VA)
The F3-VA module addresses prevailing limitations in disentanglement-based approaches and generative systems (GANs, VAEs), namely, reliance on external speaker pools, restricted speaker diversity, and low controllability of identity deviation. The framework models speaker embeddings directly using a flow-matching generative mechanism. The speaker anonymizer is a U-shaped MLP-based network that operates in a flow-based ODE framework, allowing for fine-grained and stochastic control over the trade-off between speaker identity retention and deviation by adjusting a continuous speaker weight.
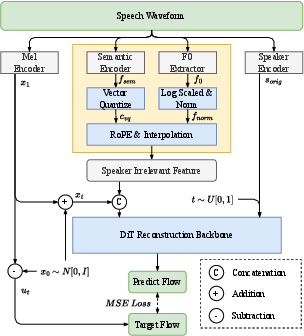
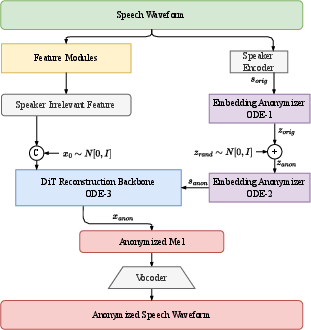
Figure 2: Architecture for training and inference: the backbone predicts flows with speaker-irrelevant features in training; at inference, reconstruction is conditioned on generated anonymized embeddings.
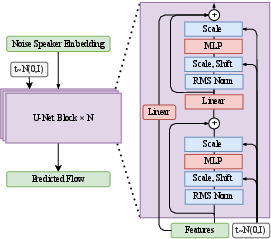
Figure 3: Speaker embedding anonymizer architecture leveraging MLP blocks for flow-matching generation along the Gaussian–speaker embedding probabilistic path.
The reconstructed speech pipeline operates on disentangled content, prosody, and speaker representations. Content features are extracted and quantized (HuBERT VQ), prosody is normalized (F0-semitone), and the speaker identity is encoded as a 192-dimensional embedding. The diffusion-based reconstruction backbone, employing the DiT architecture, synthesizes the final anonymized speech using the anonymized speaker embedding and speaker-irrelevant condition features. This mechanism ensures diversity and non-reversibility of speaker identities, mitigating re-identification risks from both ignorant and informed attackers.
Content Anonymization: Generative Speech Editing (SECA)
The content anonymization protocol extends beyond conventional cascaded redaction (ASR + NER + masking). Instead, the pipeline employs generative in-place speech editing that replaces localized PII tokens with contextually and structurally plausible alternatives using F5-TTS, ensuring fluency and natural prosody. The replacement pool is carefully matched to maintain entity type and segment duration, preserving utterance-level rhythm and minimizing boundary artifacts.
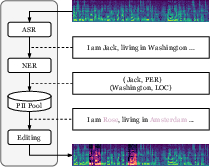
Figure 4: Four-stage content anonymization: ASR transcription, NER for PII detection, matching from a PII pool, and generative speech editing.
Compared to TTS-resynthesis and redaction (silence, noise), SECA maintains local and global acoustic integrity and provides empirical improvements in downstream usability and content privacy robustness.
Experimental Results
Utility-Preserving Properties
Systematic evaluations were performed on LibriSpeech (ASR), LibriTTS (TTS), and IEMOCAP (SER) datasets. Utility was measured by training modern task models from scratch on anonymized data. F3-VA and SECA both demonstrated minimal utility degradation compared to ground truth data across all downstream tasks. For ASR, WER for F3-VA was 2.46% (ground truth: 2.22%), while for SECA it remained at 2.23%. For TTS, SECS for F3-VA was 0.56; SECA yielded 0.60, matching the original data. SER metrics (weighted/unweighted accuracy, F1) also exhibited negligible loss. In direct comparison, NAC and ASR-BN baselines degraded performance by a far greater margin, particularly in ASR and TTS utility.
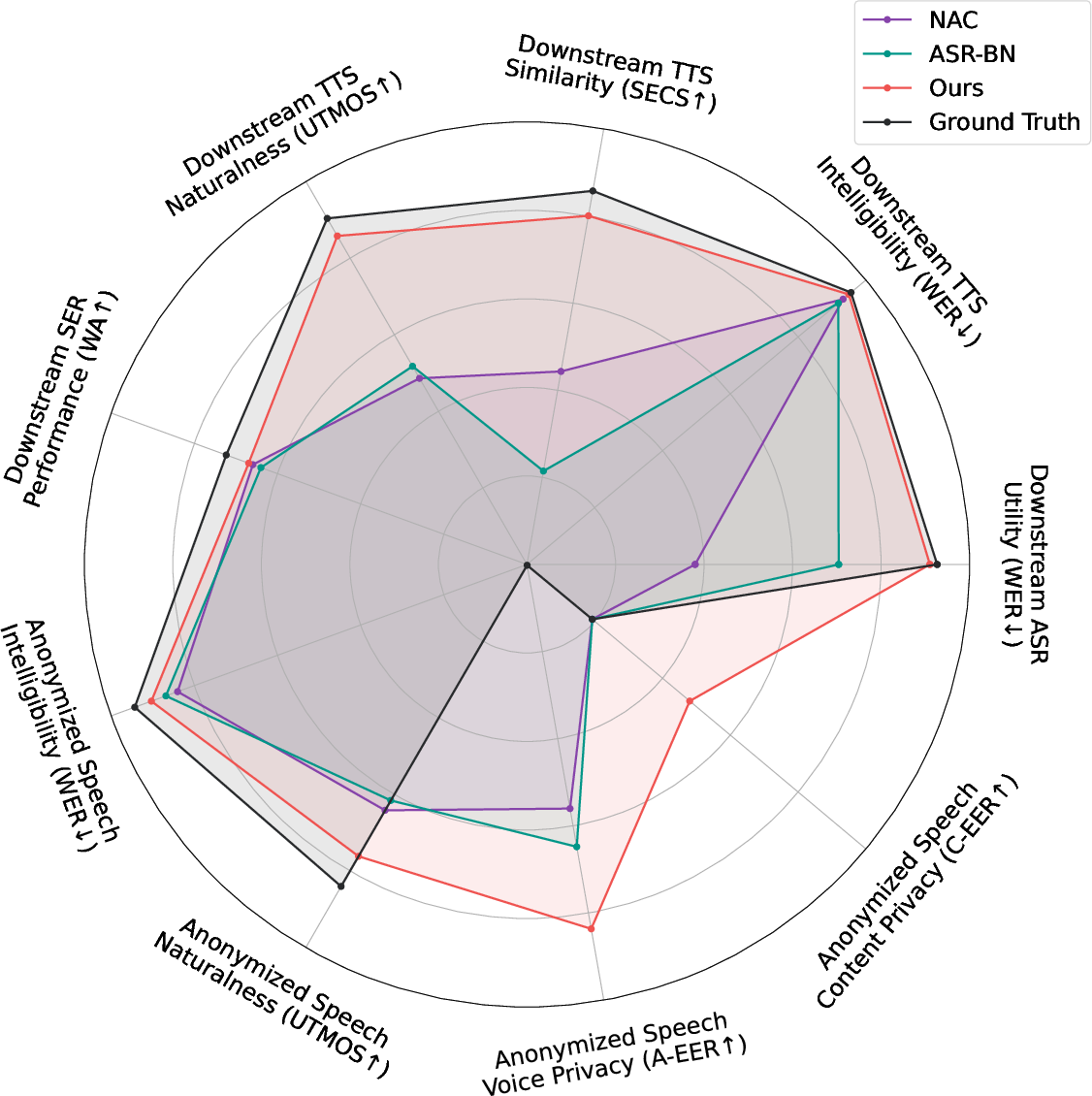
Figure 5: Radar chart summarizing privacy and utility trade-offs for anonymization systems. The proposed SECA+F3-VA jointly optimizes across all axes, closely approaching ground truth utility and privacy.
Privacy Guarantees
Privacy evaluations considered both acoustic-based (A-EER) and content-based (C-EER) speaker verification. F3-VA-alone elevated A-EER to 62.85% (baseline: ~48%), but left C-EER unchanged. SECA, in contrast, increased C-EER (by removing PII) but did not affect acoustic privacy. The two-stage SECA + F3-VA configuration is the only pipeline to jointly achieve high privacy in both dimensions. Comprehensive trials under VPC-inspired attacker models (ignorant, lazy-informed) demonstrated that the stochasticity introduced by flow-matching is robust against model-aware attackers, and the effect of speaker weighting provides tunable privacy–utility trade-offs.
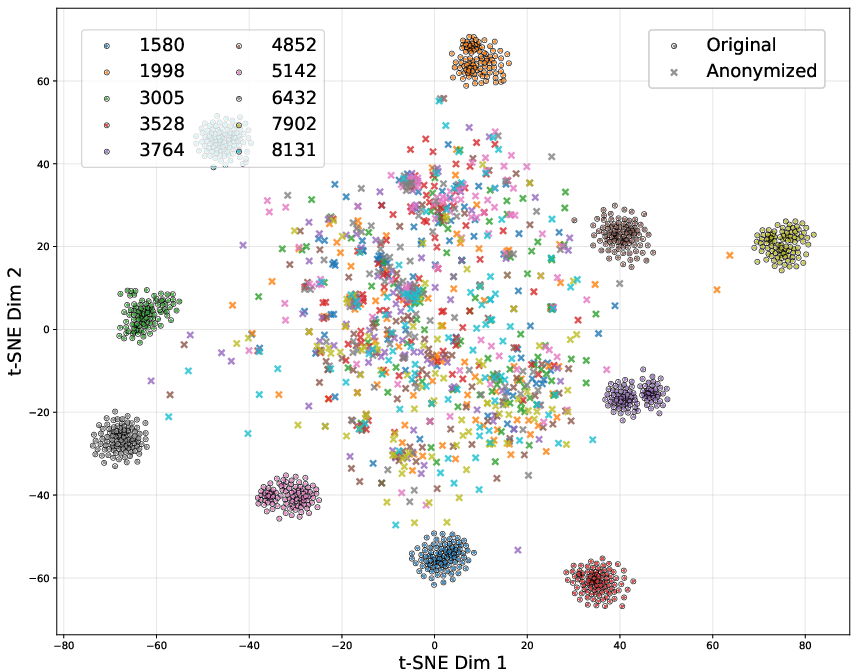
Figure 6: t-SNE projection of speaker embeddings: strong clustering (circles) pre-anonymization versus broad spatial dispersion (crosses) post-anonymization.
Ablation studies further confirmed that the generative anonymizer achieves greater voice diversity than reference pool-based replacement, improving TTS robustness and generalization from anonymized data.
Robustness and Attack Analysis
Experiments with speaker weight adjustment (w) in the anonymizer revealed monotonic control of privacy strength against ignorant attackers (maximal deviation at w=−1), while weight settings near zero delivered the highest robustness to lazy-informed adversaries due to the lack of deterministic mapping between source and anonymized embeddings. The generative editing of PII in SECA is robust against content-based re-ID, but residual stylistic speaker traces in the remaining transcript can still yield non-negligible risk, suggesting future extensions in stylization or paraphrase mechanisms.
Theoretical and Practical Implications
This work challenges prevailing assumptions that privacy and utility objectives are fundamentally antagonistic. By decomposing speech privacy into voice and content axes and leveraging flow-matching generative models with stochastic and non-deterministic mapping, it enables anonymization approaches that are amenable to large-scale data reuse and downstream training. The adoption of realistic evaluation involving scratch-trained ASR, TTS, SER, and direct privacy probing establishes new precedents for assessing the dual axes of privacy and learnability, transcending surface quality metrics.
Practically, the methods facilitate legal compliance for speech data under frameworks such as GDPR, enabling shared datasets and collaborative learning without incurring significant degradation of model performance. The adaptability and efficiency of the flow-matching mechanism, together with localized generative speech editing, provide viable templates for production-grade anonymization systems.
Future Directions
The residual privacy risk from linguistic style (even after explicit PII masking) indicates a need for more sophisticated content anonymization, possibly drawing on LLM-based text style transfer, adversarial paraphrase generation, or non-autoregressive masking systems. Research into privacy-utility trade-offs under advanced adversarial models, as well as deployment under realistic and adverse acoustic conditions (background noise, code-switching, emotional speech), remains an open challenge.
Integration with cryptography-based content protection, as well as improved composability with multilingual and multimodal foundation models, constitutes fertile ground for future studies. Systematic benchmarking under VPC-style attacker simulation will continue to be indispensable for measuring and driving progress.
Conclusion
"Anonymization, Not Elimination: Utility-Preserved Speech Anonymization" represents a technical advance in speech privacy by demonstrating that comprehensive, orthogonally designed anonymization of both voice and content can yield joint privacy and utility without significant compromise. The flow-matching-based F3-VA and generative SECA editing modules facilitate efficient, tunable, and realistic anonymization, as validated on large-scale downstream modeling tasks and rigorous attacker scenarios. This research lays the foundation for scalable, privacy-preserving speech pipelines that retain training value for advanced neural models, with further work required to address stylistic privacy risks and complex deployment environments.

