- The paper introduces a SISA-based machine unlearning framework in reinforcement learning for ransomware detection, enabling targeted removal of training samples with negligible performance loss.
- The paper demonstrates that DQN and DDQN agents achieve near-perfect detection (AUC > 0.998) while maintaining robust performance post-unlearning.
- The paper shows that one-shard retraining yields a 5x speedup over full retraining, ensuring efficient and practical privacy-aware updates.
Privacy-Aware Machine Unlearning with SISA for RL-Based Ransomware Detection
Introduction
The confluence of privacy mandates in AI deployment and the operational demand for robust ransomware detection systems necessitates methods for efficient and accountable machine unlearning. This work proposes a privacy-aware unlearning framework for reinforcement learning (RL)-based ransomware detection, leveraging the Sharded, Isolated, Sliced, and Aggregated (SISA) training paradigm. The framework allows for targeted removal of the influence of individual training samples by retraining only affected shards, obviating the need for exhaustive model retraining. The proposed approach is systematically compared using Deep Q-Network (DQN) and Double Deep Q-Network (DDQN) agents on state-of-the-art behavioral telemetry from Windows 11 ransomware and benign samples.
SISA-Based RL Framework for Ransomware Detection
The deployment workflow is succinctly captured in the SISA methodology. The dataset is partitioned into disjoint shards, with independent value-based RL agents trained on each shard. Ensemble aggregation of Q-network outputs at inference employs majority voting to enhance robustness and confine the impact of targeted sample deletion to specific shards. Unlearning is operationalized via retraining of the affected shard(s) only, thus maintaining computational tractability.
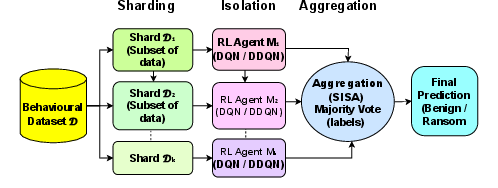
Figure 1: Workflow of the SISA-based training and aggregation framework.
The underlying RL formulation incorporates a cost-sensitive reward function with pronounced asymmetry to reflect the operational risk landscape of ransomware detection; false negatives (missed ransomware) incur a higher penalty than false positives.
Experimental Design and Dataset
The experimental regime utilizes a carefully curated dataset containing 2000 executables encompassing both benign files and 30 ransomware families, with rigorous validation using multi-engine consensus labeling. Feature engineering results in 103-dimensional behavioral vectors capturing filesystem activity, registry interactions, network events, and cryptographic operations.
Value-based RL (DQN, DDQN) agents are instantiated for each shard and trained with hyperparameters tuned for stability and efficiency (e.g., Adam optimizer, γ=0.1, Huber loss, ϵ-greedy exploration). Evaluation employs 5-fold stratified cross-validation, with performance measured via F1-score and continuous Q-score–based ROC-AUC, where Q-score is computed as
Qθ(X,1)−Qθ(X,0)
allowing robust performance assessment beyond standard accuracy.
Both baseline DQN and DDQN configurations yield high discriminative performance, with DDQN demonstrating improved stability as reflected by lower worst-fold F1 variance and reduced utility degradation post-unlearning.
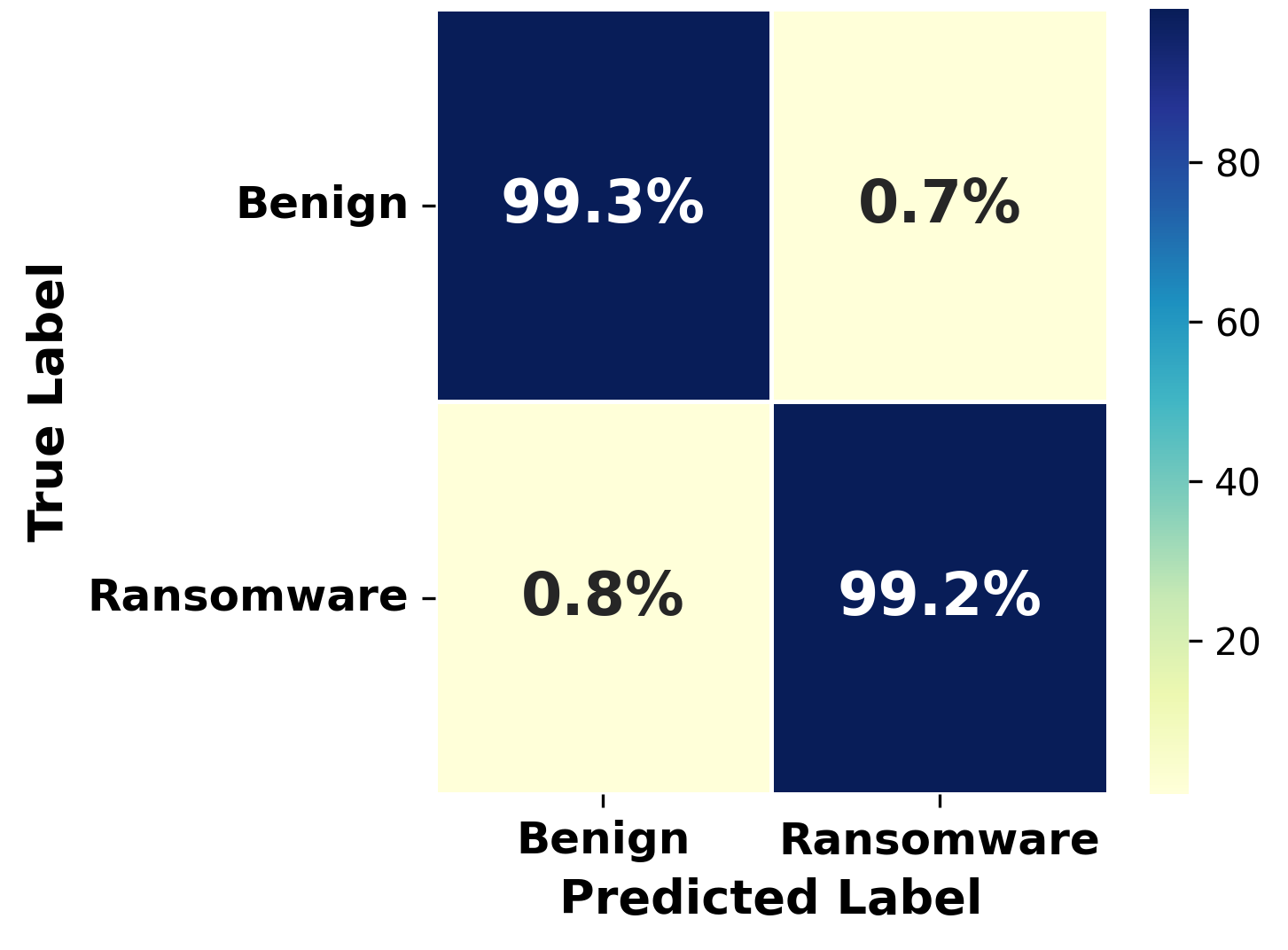
Figure 2: Confusion matrix for DDQN baseline detection, evidencing low false-positive and false-negative rates.
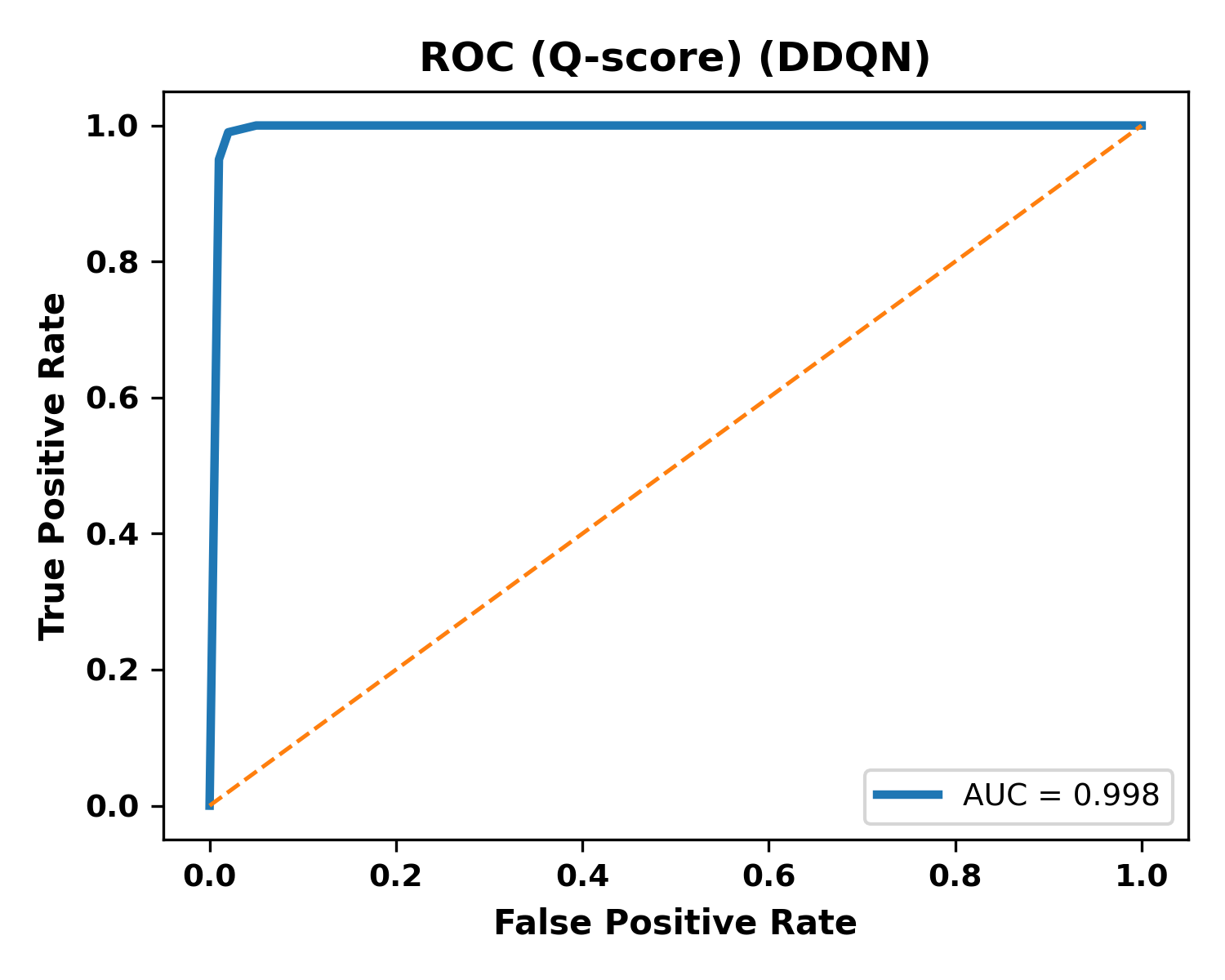
Figure 3: Q-Score ROC curve for DDQN, confirming near-perfect ranking performance with AUC >0.998.
The empirical findings confirm that value-based RL is highly effective for malware detection on structured behavioral telemetry. The Q-score ROC analysis—enabled by the explicit state-action value function—provides well-calibrated detection confidence, essential for security operations.
Utility Preservation and Efficient Unlearning
Post-training, a privacy deletion request is simulated by removing 5% of samples from a single shard and retraining only the affected RL agent. Across both DQN and DDQN, the SISA-based unlearning process incurs negligible detection performance loss (ΔF1≤0.05% for DQN, 0.00% for DDQN) compared to the pre-unlearning state. This result establishes that the majority-vote SISA ensemble can absorb modest, targeted deletion without operationally relevant degradation.
Moreover, the computational cost of one-shard retraining matches baseline (single-agent) training time, representing a 5x speedup over full SISA (multi-shard) retraining. This demonstrates that SISA unlearning can be seamlessly incorporated into production RL detection pipelines with minimal retraining overhead.
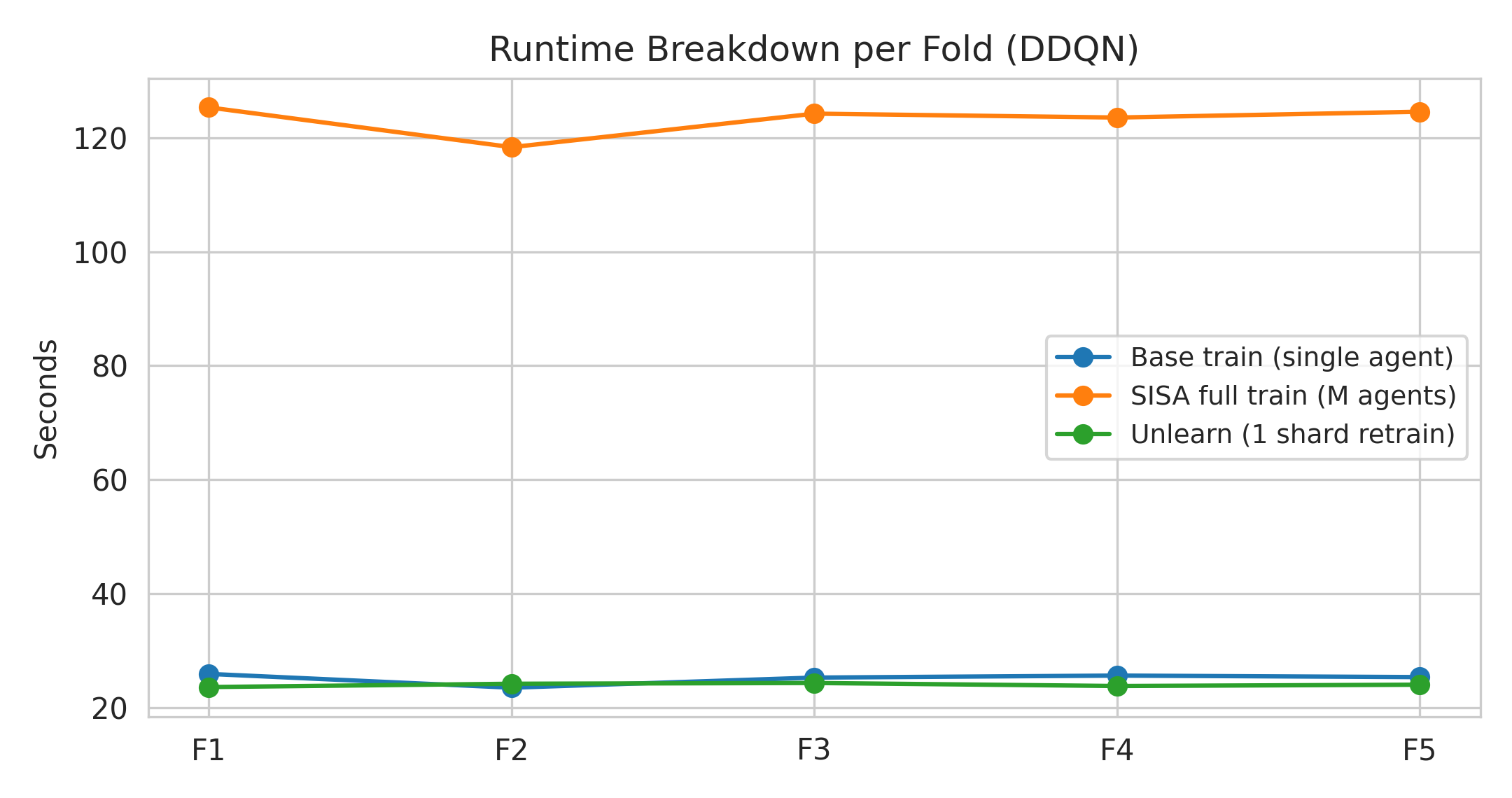
Figure 4: Runtime breakdown per fold for DDQN, illustrating that one-shard SISA unlearning incurs negligible additional cost compared to full SISA retraining.
Theoretical and Practical Implications
The study substantiates that SISA, originally designed for supervised model unlearning, is highly compatible with value-based RL. The explicit action-value function in DQN/DDQN supports robust Q-score confidence estimation, which is preserved post-unlearning. The decoupling of training into shard-isolated agents ensures that privacy deletions are auditable and computationally efficient.
Practically, this positions the SISA RL framework as a viable architecture for responsible AI deployment in security monitoring, particularly where regulatory compliance (e.g., GDPR 'right to be forgotten'), user data correction requests, and dynamic operational environments demand adaptive and privacy-aware behaviors.
Theoretically, the findings open several directions for extension:
- Extending SISA to support multi-shard and sequential deletion scenarios,
- Investigating formal verifiable unlearning and membership inference resistance,
- Incorporating actor-critic or policy-gradient paradigms subject to aggregation and unlearning (requiring new confidence/ranking metrics beyond Q-score),
- Assessing resilience under adversarial data removal attacks.
Conclusion
This work demonstrates that SISA-based machine unlearning provides a practical mechanism for integrating privacy-aware data removal into RL-based ransomware detectors without compromising detection efficacy or operational efficiency. The DDQN agent, leveraging SISA, achieves near-perfect detection (F1 >0.99, AUC >0.998) and exhibits robust utility preservation post-unlearning, with retraining costs reduced to baseline levels. These results directly address the critical intersection of data privacy and effective, deployable AI-driven cybersecurity for dynamic threat landscapes.
Future research will extend these findings to more complex RL algorithms, compositional unlearning scenarios, and formal privacy audits, fostering broad adoption of privacy-preserving AI in security-critical domains.