Scaling Test-Time Compute for Agentic Coding
Abstract: Test-time scaling has become a powerful way to improve LLMs. However, existing methods are best suited to short, bounded outputs that can be directly compared, ranked or refined. Long-horizon coding agents violate this premise: each attempt produces an extended trajectory of actions, observations, errors, and partial progress taken by the agent. In this setting, the main challenge is no longer generating more attempts, but representing prior experience in a form that can be effectively selected from and reused. We propose a test-time scaling framework for agentic coding based on compact representations of rollout trajectories. Our framework converts each rollout into a structured summary that preserves its salient hypotheses, progress, and failure modes while discarding low-signal trace details. This representation enables two complementary forms of inference-time scaling. For parallel scaling, we introduce Recursive Tournament Voting (RTV), which recursively narrows a population of rollout summaries through small-group comparisons. For sequential scaling, we adapt Parallel-Distill-Refine (PDR) to the agentic setting by conditioning new rollouts on summaries distilled from prior attempts. Our method consistently improves the performance of frontier coding agents across SWE-Bench Verified and Terminal-Bench v2.0. For example, by using our method Claude-4.5-Opus improves from 70.9% to 77.6% on SWE-Bench Verified (mini-SWE-agent) and 46.9% to 59.1% on Terminal-Bench v2.0 (Terminus 1). Our results suggest that test-time scaling for long-horizon agents is fundamentally a problem of representation, selection, and reuse.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Scaling Test-Time Compute for Agentic Coding — A simple explanation
1. What is this paper about?
This paper is about teaching coding AIs to use their extra “thinking time” more wisely. Instead of giving an AI one shot to fix a bug or finish a coding task, the researchers let it try many times and learn from those tries. But there’s a problem: each try is a long, messy story of actions, errors, and partial progress. The main idea of the paper is to turn those messy stories into short, smart summaries and then use those summaries to pick the best ideas and guide the next tries.
2. What questions did the researchers ask?
They focused on three simple questions:
- How can we represent (summarize) an AI’s long, step-by-step attempts so they’re easy to compare and reuse?
- How can we pick the best attempt when we have many different tries running in parallel?
- How can we use what was learned from earlier tries to make later tries better?
3. How did they do it? (Methods in everyday language)
Think of the AI like a student programmer working in a computer terminal. Each “attempt” (called a rollout) is a full session: reading files, editing code, running tests, seeing errors, and trying fixes. That’s a lot of detail.
The researchers used two big ideas, built on a key ingredient: summaries.
- First ingredient: Compact summaries
- They turn each long attempt into a short, structured “highlight reel” that captures the main ideas: what the AI tried, what seemed promising, what partially worked, and what failed. This throws away noisy details (like long logs) and keeps the useful bits.
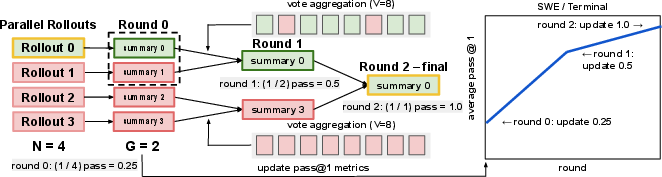
- Parallel selection: Recursive Tournament Voting (RTV)
- Picture a sports tournament for ideas. Many summaries enter. The AI compares small groups (usually pairs) of summaries and votes on which one seems better. Winners move up to the next round. It repeats until one best attempt remains.
- Why small groups? Comparing two at a time is easier and more accurate than judging a huge group all at once. They also use multiple “votes” to reduce random mistakes.
- Sequential reuse: Parallel-Distill-Refine (PDR) adapted for agents
- Now imagine starting a new set of attempts, but before you do, you study notes from a few of the best earlier attempts. The AI takes the top K summaries (like the best 4 highlight reels), combines their lessons, and uses that to guide a fresh attempt from scratch. This helps the AI skip dead ends and head straight for promising fixes.
- Unified recipe: Selection → Reuse → Selection
- Step 1: Run many attempts and summarize them.
- Step 2: Use the tournament (RTV) to pick the top K summaries.
- Step 3: Start new attempts guided by those K summaries (PDR).
- Step 4: Run the tournament again on the new attempts to pick the final best solution.
4. What did they find, and why is it important?
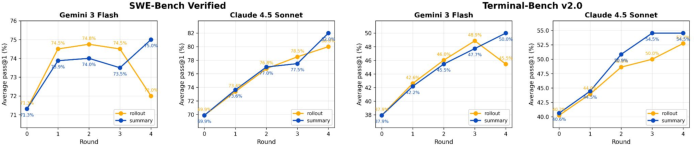
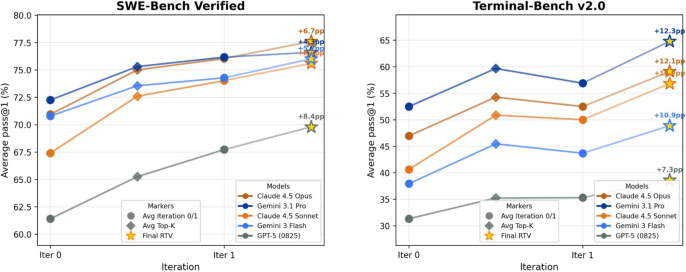
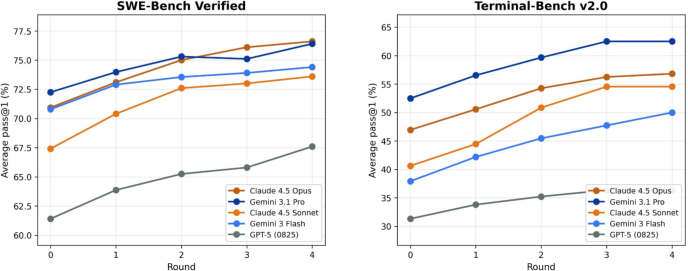
Main results across two tough coding benchmarks (SWE-Bench Verified and Terminal-Bench v2.0) and several top AI models (like Claude and Gemini):
- Big performance boosts:
- Claude-4.5-Opus improved from about 71% to 78% on SWE-Bench Verified and from about 47% to 59% on Terminal-Bench v2.0.
- Gemini-3.1-Pro improved from about 72% to 77% on SWE-Bench Verified and from about 53% to 65% on Terminal-Bench v2.0.
- Consistent wins across multiple models and both benchmarks.
Key discoveries about how to get these gains:
- Summaries beat raw logs: It’s easier and more accurate to compare “highlight reels” than long messy transcripts.
- Small matches beat big showdowns: Pairwise (two-at-a-time) comparisons with multiple votes choose better winners than one huge comparison.
- Learn from several good tries, not just one: Using multiple strong summaries to guide a new attempt works much better than using only one.
- Better notes → better next tries: If the summaries used for guidance come from successful attempts, the next attempts are far more likely to succeed.
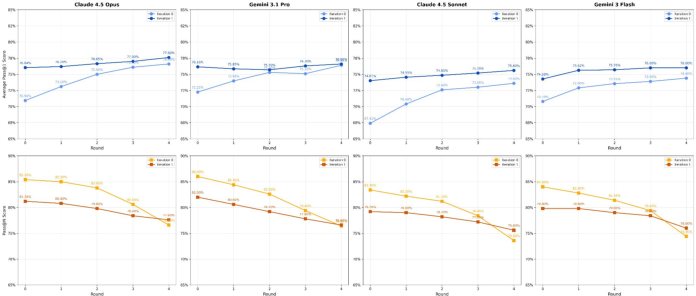
- Fewer steps to success: Guided attempts take about half as many steps on average, meaning the AI wastes less time on unhelpful detours.
Why this matters: It shows that smarter use of test-time compute (how much effort you spend when you run the model) can make a big difference—especially for long, complicated tasks like coding in a real terminal.
5. What’s the impact? (Why this could matter in the future)
- Smarter agent design: For long, multi-step tasks (coding, data analysis, planning), the secret sauce isn’t just a bigger AI model—it’s also how you represent, select, and reuse its experience.
- Practical coding help: Coding AIs can fix more bugs and do it faster if they compare and combine their best ideas from multiple tries.
- General strategy for long tasks: This “summarize → select → reuse” approach could help any agent that works step-by-step in the real world (not just coding), like scientific assistants, data wranglers, or digital task runners.
In short: The paper shows that managing the AI’s “memories” (by summarizing them well), picking the best attempts through small fair comparisons, and reusing the best ideas to guide new tries can make long-horizon AI agents much more effective.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open problems that remain unresolved and could guide future research.
- Summary representation design and learning
- The summary schema is prompt-crafted; no exploration of learned or trainable representations (e.g., encoder-based or contrastively trained summaries) that optimize downstream selection/refinement performance.
- No method to quantify summary sufficiency (which information is “necessary and sufficient”) or to detect/mitigate summary omissions that cause downstream errors.
- Lack of robustness analysis for summaries across different agent scaffolds, programming languages, repository sizes, and verbosity/noise regimes.
- No mechanisms to calibrate or verify factuality of summaries (e.g., cross-checks against logs, static analysis) to prevent propagating hallucinated progress or spurious diagnoses.
- No study of summary length/structure trade-offs (token budget vs. fidelity) or incremental/streaming summarization for very long trajectories.
- Selection via Recursive Tournament Voting (RTV)
- Sensitivity to judge-prompt wording, position bias, and formatting is unreported; no robustness checks across alternative prompts/judges or randomized ordering.
- Pairwise tournament selection can encounter non-transitive preference cycles; no analysis or mitigation (e.g., Condorcet methods, Bradley–Terry models, probabilistic ranking).
- Vulnerability to “persuasive” but misleading summaries is untested; no adversarial stress tests or safeguards against gaming the comparator.
- Cost/latency footprint is not characterized (N rollouts + summaries + V votes per match); no compute–accuracy curves or cost-aware scheduling.
- No adaptive allocation: G, V, and the number of rounds are fixed; no uncertainty modeling to stop early when confidence is high or to spend more votes on close calls.
- No hybridization with weak external signals (e.g., static analysis, lint warnings, partial unit tests) to anchor the comparator to verifiable evidence.
- Sequential reuse via PDR in agentic settings
- Only T=2 iterations are explored; no scaling to deeper refinement, convergence behavior, or detection of diminishing returns/regressions with more iterations.
- K is fixed and not diversity-aware; no mechanisms to select a diverse-but-strong set (e.g., clustering, DPPs) or to weight/prune redundant/conflicting contexts.
- In 0/4 or 1/4-success contexts, iteration-1 performance collapses; no fallback exploration strategies (e.g., inject fresh seeds, diversify prompts, expand N/K adaptively).
- Refinement conditioning is a raw concatenation of K summaries; no study of learned fusion, retrieval-augmented planning, or plan merging across proposals.
- No techniques to estimate “context quality” before refinement to drive adaptive K or to skip refinement when prior experience is unreliable.
- Risk of propagating consistent but incorrect hypotheses across iterations is not analyzed; no mechanisms for contradiction detection or hypothesis revision.
- Generalization and scope
- Evaluations are limited to SWE-Bench Verified and Terminal-Bench v2.0 under specific scaffolds; no tests on other agentic domains (e.g., web automation, robotics, GUI), languages, large monorepos, or tasks requiring external APIs/services.
- Focus on binary pass/fail tasks; applicability to non-binary or multi-objective metrics (e.g., performance, style, partial credit) remains untested.
- All base models are frontier, proprietary LLMs; generalization to smaller/open models or on-device settings is unknown.
- Cross-task or long-term memory reuse (building a library of reusable solutions/failure modes across tasks) is not addressed.
- Measurement, variance, and reproducibility
- No reporting of statistical uncertainty (variance across seeds/runs) for selection/refinement outcomes; stability under stochasticity is unclear.
- Reproducibility details (code, prompts, container configs, deterministic seeds) and sensitivity to minor prompt/environment changes are not provided.
- Per-category error analysis is missing (which bug types/repo structures benefit or regress); lack of granular insights to target method improvements.
- Practical constraints and systems issues
- Wall-clock latency, resource utilization (CPU/GPU/memory), container overhead, and scheduling constraints are not quantified.
- Token costs for summarization, voting, and refinement contexts are not analyzed; no token budgeting or amortization strategies.
- No dynamic compute allocation policy (bandits/BO) to allocate N, K, V per-task based on difficulty signals or early diagnostics.
- Safety and security
- Operating in bash environments raises safety risks; sandboxing, permissioning, and side-effect auditing are not discussed.
- No checks for data leakage or contamination (e.g., tasks in model pretraining) that could inflate results.
- Integration with training and tooling
- No exploration of training a judge/discriminator with supervision (e.g., sparse test outcomes) to improve selection reliability and reduce vote counts.
- No attempt to distill test-time scaling into the base model (e.g., fine-tune to produce better summaries or to self-rank trajectories).
- No integration with static/dynamic analysis tools, symbolic execution, or patch-merging systems to combine partial fixes across rollouts.
- Theoretical understanding
- No formalization of summaries as sufficient statistics for selection/refinement or of RTV’s advantage of small-group comparisons; absence of guarantees or error bounds.
- Lack of analysis of information flow: how much actionable signal is transferred via summaries, and what failure modes dominate when transfer fails.
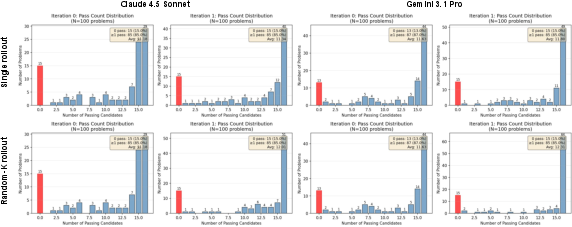
- Edge cases and failure modes
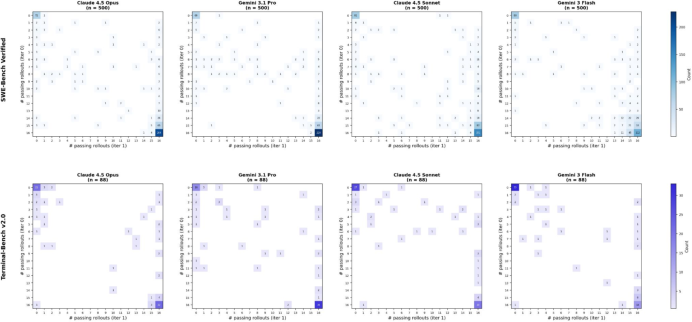
- Iteration-1 bimodality (increase in 0/16 and 16/16 tasks) is observed but not addressed; methods to mitigate regressions are absent.
- Tasks requiring intermediate artifacts or long-running computations may not be captured by summaries; no protocol for artifact handoff across fresh containers.
- Handling flaky tests or nondeterministic environments is not discussed; selection strategies may be brittle under evaluation noise.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can adopt the paper’s representation–selection–reuse (RTV + PDR) recipe with today’s models and tooling. Each bullet notes sector(s), what to build or change, and key dependencies/assumptions.
- “Tournament mode” coding assistant in IDEs
- Sectors: Software, Developer Tools
- What: Add a mode where the assistant spawns N parallel fix attempts for a bug or feature, creates structured summaries, applies Recursive Tournament Voting (pairwise with voting) to select K best, then reruns refined attempts (PDR) and proposes the top patch and PR.
- Tools/workflows: IDE plugin; containerized sandboxes per rollout; summary prompt templates; RTV selector; PDR orchestrator; integration with tests.
- Assumptions/dependencies: Access to strong LLMs; deterministic, sandboxed builds; available tests for validation; compute budget for multiple rollouts/votes.
- CI/CD auto-remediation with selection-and-refine
- Sectors: Software/DevOps/QA
- What: When a pipeline fails, spawn N containerized repair attempts, summarize, RTV to pick K, run refined attempts, validate with tests, open a PR with the best patch and a summary of hypotheses and failure modes.
- Tools/workflows: CI runners (GitHub Actions/GitLab Runners); ephemeral containers; test executors; RTV/PDR modules; approvals workflow.
- Assumptions/dependencies: Reliable test suite; sandboxing; cost/latency budgets; review gates for change control.
- SRE runbook automation in terminals
- Sectors: IT Operations, SRE
- What: For incident tasks (e.g., log triage, service restarts), run multiple agentic terminal rollouts, summarize partial progress and errors, RTV to select safer strategies, and refine in a clean environment before proposing an execute plan.
- Tools/workflows: Read-only rehearsal environments; guardrails for command execution; human-in-the-loop approval with summaries.
- Assumptions/dependencies: Strict sandboxing; role-based access; immutable infra or canarying; audit logging.
- Code review triage and patch selection
- Sectors: Software Engineering
- What: For a given issue or failing test, generate multiple alternative patches; produce structured summaries (hypotheses, diffs, tests touched), apply RTV to rank patches; present top-1 plus runner-up rationales to reviewers.
- Tools/workflows: PR bots; summary UI in code review; small-group comparisons with vote aggregation.
- Assumptions/dependencies: Test/linters as ground truth; reviewer oversight; compatible repo policies.
- Test generation and selection
- Sectors: QA, Software
- What: Generate N candidate tests for a feature or bug, summarize coverage intent and failure modes, RTV to select diverse K high-value tests, refine to increase stability.
- Tools/workflows: Test runners; flake detection; summary schema for test intent/coverage.
- Assumptions/dependencies: Stable environments; clear coverage metrics; compute budget.
- Agent orchestration plugin for LangChain/LangGraph/AutoGen
- Sectors: Agent frameworks, Software
- What: Ship pluggable components implementing rollout summarization, pairwise RTV with voting, and PDR-K conditioning for long-horizon agents (coding, web, CLI).
- Tools/workflows: Python SDK; batteries-included summary prompts; knobs for N, G, V, K.
- Assumptions/dependencies: Framework adoption; compatible memory/token limits.
- Benchmarking and evaluation upgrades
- Sectors: Academia, AI Labs
- What: Evaluate agents using summary-based selection (RTV) and iterative refinement (PDR) on SWE-Bench/Terminal-Bench and similar; report pass@N, RTV pass@1, and refinement gains.
- Tools/workflows: Bench harnesses; summary artifact storage; ablation dashboards.
- Assumptions/dependencies: Reproducible environments; cost tracking for fair comparisons.
- Auditability and explainability for agents
- Sectors: Regulated industries, Enterprise IT
- What: Store the compact structured summaries (hypotheses, decisions, failure modes) for each attempt; use them as human-readable audit trails and postmortems.
- Tools/workflows: Summary schema; governance dashboards; immutable logs.
- Assumptions/dependencies: Data retention policies; privacy controls; standardized formats.
- Web/CLI task automation with safer selection
- Sectors: RPA, Productivity
- What: For scripted browser/CLI automation (data wrangling, file ops), run multiple plans in dry-run sandboxes, summarize diffs and errors, RTV to pick/refine, then execute with confirmation.
- Tools/workflows: Headless browsers; filesystem sandboxes; diff previews; consent UI.
- Assumptions/dependencies: Non-destructive rehearsal; user approval gates.
- Security patch reproduction and remediation support
- Sectors: Security Engineering
- What: Generate multiple PoCs/fix attempts for a reported CVE, summarize root-cause hypotheses and impacts, select/refine candidates, and propose a vetted patch and test.
- Tools/workflows: Isolated vuln labs; static/dynamic analysis; security review checklists integrated with summaries.
- Assumptions/dependencies: Strong sandboxing; disclosure controls; human review.
- CS education: debugging tutor with “multiple hypotheses”
- Sectors: Education
- What: Show students structured summaries of several debugging approaches and a selected refined approach; let students compare hypotheses/failure modes.
- Tools/workflows: LMS integration; per-assignment sandboxes; rubric-linked summary fields.
- Assumptions/dependencies: Academic integrity policies; compute quotas.
- Cloud “test-time compute” knobs in model endpoints
- Sectors: Cloud/AI Platforms
- What: Offer turnkey N, K, G, V parameters (rollouts, top-K, group size, vote count) in agent endpoints and report selection/refinement metrics and costs.
- Tools/workflows: Managed containers; metering; SDKs.
- Assumptions/dependencies: Clear SLAs; observability; user education on cost–quality tradeoffs.
Long-Term Applications
These rely on additional R&D, scaling, or safety assurance. They extend the paper’s representation–selection–reuse paradigm to broader long-horizon agents.
- Robotics: parallel exploration and distilled reuse
- Sectors: Robotics, Manufacturing, Warehousing
- What: Run multiple task-level policies (e.g., manipulation strategies) in sim or safe real trials; summarize trajectories (preconditions, progress, failure modes); RTV to pick strategies and condition refined policies.
- Dependencies: High-fidelity simulators; safety envelopes; sensor-to-summary encoders; latency constraints.
- Scientific automation and AutoML pipelines
- Sectors: R&D, Pharma, Materials, ML Ops
- What: Execute N experiment/code/training pipelines, summarize hypotheses and intermediate metrics, RTV select/refine to converge faster on promising designs or models.
- Dependencies: Orchestrators (Airflow/Kubeflow); experiment tracking; domain-specific summary schemas; budget-aware scheduling.
- Healthcare workflow agents with auditable summaries
- Sectors: Healthcare IT, Clinical Ops
- What: Use agentic EHR automation (e.g., chart abstractions, order set configuration) where each attempt is summarized and selected/refined before any change; summaries serve as audit logs.
- Dependencies: Regulatory approval; PHI-safe sandboxes; rigorous human-in-the-loop; formal safety constraints.
- Finance and enterprise ops with high-assurance selection
- Sectors: Finance Ops, Risk, Compliance
- What: Multi-attempt agents prepare reconciliations or reports; structured summaries enable RTV and PDR with controls; only refined, selected outputs proceed.
- Dependencies: Audit trails; segregation of duties; model risk management; formal validation.
- Formal verification integrated with tournament selection
- Sectors: Safety-critical Software, Infrastructure
- What: Add proof/verification checks into RTV voting (e.g., type/unit proofs, model checking) so only candidates that satisfy constraints can win/refine.
- Dependencies: Mature verification tools; proof-aware summaries; performance tuning.
- Cross-agent collaboration via summary-mediated coordination
- Sectors: Enterprise AI, Research
- What: Specialized agents (e.g., data, backend, frontend) produce interoperable summaries; a coordinator uses RTV to assemble and refine composite solutions.
- Dependencies: Summary standards; interop protocols; conflict resolution policies.
- Training-time distillation from test-time summaries
- Sectors: AI Research, Platform
- What: Use curated summaries and winning trajectories as supervised signals to fine-tune agents on better representations and decision criteria.
- Dependencies: Data pipelines; de-biasing; privacy; catastrophic forgetting safeguards.
- Compute marketplaces for test-time scaling
- Sectors: Cloud, Edge
- What: “Inference-time compute as a service” where users trade off N/K/G/V within budgets; schedulers allocate parallel rollout capacity dynamically.
- Dependencies: Cost transparency; auto-scaling; QoS; policy on energy/cost reporting.
- Hardware and runtime optimized for many rollouts + voting
- Sectors: Semiconductors, Systems
- What: Runtime kernels and schedulers that batch parallel agent rollouts, fast summary generation, and voting efficiently.
- Dependencies: Model architectures; memory bandwidth; tokenization throughput.
- Process control in energy/industrial systems
- Sectors: Energy, Industrial Automation
- What: In simulators, run multiple control policies, summarize stability and safety margins, RTV to select/refine before deployment to real systems.
- Dependencies: Digital twins; strict safety gates; regulator approval.
- Personal digital employees for complex workflows
- Sectors: Productivity, Consumer
- What: Agents that plan/execute multi-step tasks (e.g., complex trip booking, data migration) via multi-attempt summaries and tournament selection to improve reliability.
- Dependencies: Robust sandboxing; privacy; UX for approvals; cost control.
- Standards and governance for agent summaries and selection
- Sectors: Policy, Standards Bodies
- What: Define schemas and metrics for rollout summaries, selection practices (e.g., declare N/K/G/V), and audit requirements for long-horizon agents.
- Dependencies: Multi-stakeholder alignment; sector-specific regulations; conformance tests.
- Education at scale: “debugging tournaments” in curricula
- Sectors: Education
- What: Platforms where students compare agent-produced summaries and learn to critique/choose strategies; instructors assess reasoning quality.
- Dependencies: Pedagogical studies; fairness; accessibility; infra subsidies.
Common Assumptions and Dependencies Affecting Feasibility
- Model capability and context limits: Benefits depend on strong LLMs and reliable summary prompts; token budgets must accommodate summaries and votes.
- Compute and latency budgets: Parallel rollouts (N) and voting (V) increase cost and latency; products need knobs and budget-aware schedulers.
- Safe execution: Terminal/code actions require robust sandboxing, dry runs, and approval gates, especially in production or regulated settings.
- Tests/ground truth availability: While RTV operates without ground-truth during selection, downstream validation (tests, checks) is critical for deployment.
- Summary quality and schema design: The representation must capture hypotheses, progress, and failure modes consistently to be comparable and reusable.
- Data governance and privacy: Storing and sharing summaries implies logging sensitive context; enforce privacy and access controls.
- Organizational processes: Human-in-the-loop reviews, change management, and audit requirements must align with automated selection/refinement workflows.
Glossary
- agentic coding: A paradigm where a model acts as an autonomous agent, interacting with tools and environments over many steps to solve coding tasks. "However, agentic coding introduces a distinct regime from such existing domains."
- bash environment: A Unix shell-based execution environment used by the agent to run commands during coding tasks. "We scale test-time compute for agentic coding tasks, where a LLM must solve a coding problem by interacting with an external bash environment over multiple steps."
- bimodal distribution: A distribution with two distinct peaks; used here to describe the split of tasks into mostly-all-pass or mostly-all-fail outcomes after refinement. "we obtain a sharp, bimodal distribution of tasks for the iteration-1 rollouts"
- conditioning: Supplying specific context to a model so its next outputs depend on that information. "by conditioning new rollouts on summaries distilled from prior attempts."
- distilled prior experience: Compact information extracted from earlier rollouts that guides subsequent attempts. "generating the first action conditioned on both the original problem and this distilled prior experience:"
- failure modes: Characteristic ways that attempts go wrong; capturing these helps selection and reuse. "preserves its salient hypotheses, progress, and failure modes"
- frontier LLMs: The latest high-performing LLMs at the leading edge of capability. "across frontier LLMs {Claude-4.5-Opus, Gemini-3.1-Pro, Claude-4.5-Sonnet, Gemini-3-Flash, GPT-5-0825}"
- ground-truth outcomes: True labels or definitive results used to evaluate solutions. "without access to any ground-truth outcomes, test cases or test samples."
- head-to-head comparisons: Direct empirical comparisons between models. "Appendix~\ref{sec:model_comparisons_appendix} for their head-to-head comparisons"
- inference-time compute: The computation budget spent during model inference (not training), often increased to sample and compare multiple candidates. "allocate additional inference-time compute to sample multiple candidates, aggregate or compare them, or refine later attempts using information from earlier ones"
- inference-time scaling: Strategies that improve performance by spending more compute during inference, such as selection and refinement across attempts. "We first study the parallel dimension of inference-time scaling."
- iteration: One round of executing a batch of rollouts in a multi-iteration refinement scheme. "We refer to the execution of parallel rollouts as an iteration, such that iteration-1 rollouts are refined from iteration-0 rollouts."
- long-horizon: Describes tasks or agents requiring many steps and extended trajectories to reach a solution. "Long-horizon coding agents violate this premise: each attempt produces an extended trajectory of actions, observations, errors, and partial progress taken by the agent."
- mini-SWE-agent: A specific agent scaffold or configuration used for SWE-Bench experiments. "SWE-Bench Verified (mini-SWE-agent)"
- oracle performance: The ideal upper bound achievable with perfect knowledge or selection. "the upper bound of the post-aggregation pass@1 score is the pass@N score, where the selection matches oracle performance."
- pairwise comparisons: Comparing two candidates at a time, often yielding more reliable judgments than large-group comparisons. "with pairwise comparisons () yielding the strongest results."
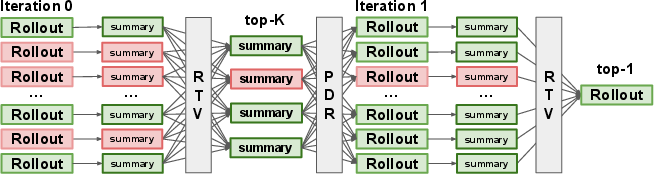
- Parallel-Distill-Refine (PDR): A test-time method that runs parallel attempts, distills information from them, and then refines new attempts using that distilled context. "we adapt Parallel-Distill-Refine (PDR;~\citet{pdr-paper}) to agentic coding"
- parallel aggregation: Selecting or combining results across multiple parallel rollouts to pick the best candidate. "RTV is our parallel aggregation technique designed for agentic tasks"
- parallel scaling: Improving performance by executing more attempts in parallel and aggregating their information. "For parallel scaling, we introduce Recursive Tournament Voting (RTV), which recursively narrows a population of rollout summaries through small-group comparisons."
- pass@1: The probability (or fraction) that a single selected attempt passes. "the upper bound of the post-aggregation pass@1 score is the pass@N score"
- pass@N: The probability (or fraction) that at least one of N attempts passes. "the upper bound of the post-aggregation pass@1 score is the pass@N score"
- Recursive Tournament Voting (RTV): A recursive, small-group voting scheme that narrows a population of candidates to a winner via repeated comparisons. "we introduce Recursive Tournament Voting (RTV), which recursively narrows a population of rollout summaries through small-group comparisons."
- refinement context: The selected set of prior summaries provided to guide next-iteration rollouts. "which define the refinement context for the next iteration."
- rollout: A full attempt by the agent consisting of interleaved actions and observations within the environment. "We treat a rollout as the primary scaling unit since it interleaves model outputs with observations, making token-level scaling difficult to interpret consistently across steps."
- rollout summaries: Compact, structured representations of rollouts that capture key hypotheses, progress, and failures. "we introduce Recursive Tournament Voting (RTV), which recursively narrows a population of rollout summaries through small-group comparisons."
- rollout trajectories: The sequences of actions and observations produced by the agent over time. "compact representations of rollout trajectories."
- random-K: A PDR variant that samples K prior summaries at random to build the refinement context. "we apply the random- variant of PDR to an agentic setting."
- scaffold (Terminus-1 scaffold): The agent framework or tooling setup used to run and evaluate tasks. "under the Terminus-1 scaffold."
- Select-K (select-): Choosing the top K prior summaries (e.g., via RTV) to form a higher-quality refinement context. "Select-: apply RTV to obtain a high-quality subset of summaries;"
- sequential refinement: Improving later attempts by reusing information distilled from earlier attempts across iterations. "We next probe our design choices for sequential refinement."
- sequential scaling: Increasing performance by executing multiple refinement iterations that reuse selected prior experience. "For sequential scaling, we adapt Parallel-Distill-Refine (PDR) to the agentic setting by conditioning new rollouts on summaries distilled from prior attempts."
- small-group comparisons: Evaluations conducted on small subsets of candidates to improve reliability before recursive narrowing. "through small-group comparisons."
- SWE-Bench Verified: A benchmark of software engineering tasks used to evaluate agentic coding systems. "on SWE-Bench Verified (mini-SWE-agent)"
- structured summary: A bounded, organized synopsis of a rollout that preserves key insights while discarding low-signal details. "convert each rollout into a structured summary"
- Terminal-Bench v2.0: A benchmark suite focused on terminal-based coding tasks and command execution. "on Terminal-Bench v2.0 (Terminus 1)."
- test-time scaling: Techniques that allocate more attempts or computation at inference time to improve results. "Test-time scaling has become a powerful way to improve LLMs."
- top-1 rollout: The single final selected attempt after aggregation. "Finally, RTV aggregates the refined rollouts and returns the top-1 rollout."
- vote aggregation: Combining multiple comparison votes to make a more reliable selection decision. "vote aggregation improves the reliability of these local decisions"
Collections
Sign up for free to add this paper to one or more collections.