Repurposing 3D Generative Model for Autoregressive Layout Generation
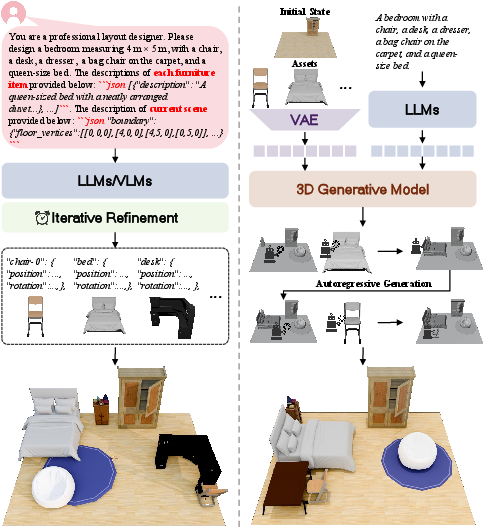
Abstract: We introduce LaviGen, a framework that repurposes 3D generative models for 3D layout generation. Unlike previous methods that infer object layouts from textual descriptions, LaviGen operates directly in the native 3D space, formulating layout generation as an autoregressive process that explicitly models geometric relations and physical constraints among objects, producing coherent and physically plausible 3D scenes. To further enhance this process, we propose an adapted 3D diffusion model that integrates scene, object, and instruction information and employs a dual-guidance self-rollout distillation mechanism to improve efficiency and spatial accuracy. Extensive experiments on the LayoutVLM benchmark show LaviGen achieves superior 3D layout generation performance, with 19% higher physical plausibility than the state of the art and 65% faster computation. Our code is publicly available at https://github.com/fenghora/LaviGen.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine you’re decorating a room in a video game. You want the chairs to go around the table, the sofa to face the TV, and nothing to float or overlap. This paper introduces LaviGen, a new computer method that automatically arranges 3D objects in a room so they’re placed in smart, realistic positions. It uses a “3D-first” approach, thinking directly in 3D space instead of only reading words or looking at images, so the results make sense both visually and physically.
What questions the researchers asked
- Can we arrange 3D objects in a room directly in true 3D space, instead of treating the layout like text or relying on 2D images?
- Can a model place objects one by one, step by step (like you would in real life), while keeping everything realistic and non-colliding?
- How can we reduce mistakes that build up when placing many objects in sequence?
- Can this approach be fast and accurate, and also handle tasks like “fill in the rest of this room” or “edit this layout”?
How they did it (methods explained simply)
Think of building a room with LEGO pieces:
- Instead of writing a to-do list (“put chair here”), LaviGen looks at the 3D room directly and places pieces where they fit best.
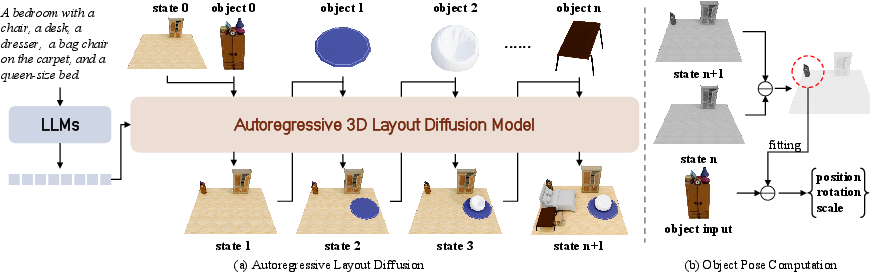
- It places objects one at a time, checking how each new piece fits with what’s already there. This is called an “autoregressive” process—like adding items in a sequence.
- It uses a 3D “generative model” trained on lots of 3D objects and scenes. You can think of this as the model having “common sense” about how furniture usually goes together.
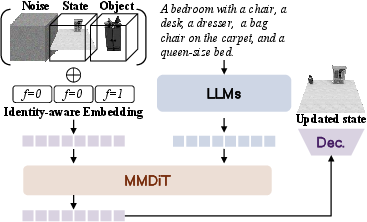
- Under the hood, it uses a “diffusion” model. You can imagine diffusion like starting with a noisy, scrambled version of the room and then slowly cleaning it up until you get a clear, correct layout.
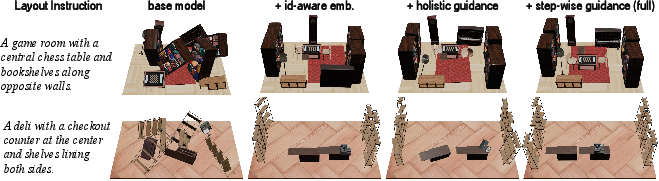
- It also uses an “identity-aware” trick to tell the difference between the current room and the new object being added, so it doesn’t mix them up.
- To get the final, clean geometry, it first predicts a rough 3D shape grid (like a voxel/3D pixel version of the scene) and then fits the real furniture models to those shapes so everything is crisp and aligned.
Fixing the “practice vs. real game” problem:
- Models often practice with perfect examples but struggle in real situations where their own small mistakes add up. This is called “exposure bias.”
- LaviGen reduces this by training the model to use its own previous placements during practice (self-rollout), then correcting itself using two kinds of guidance:
- Holistic guidance: a “teacher” checks the whole scene at the end—does the final room look good overall?
- Step-wise guidance: another “teacher” checks each step—was each new object placed correctly?
- This “dual-guidance” distillation is like having a coach who reviews both every move and the whole game plan, helping the “student” model get more accurate and faster over time.
What they found (main results)
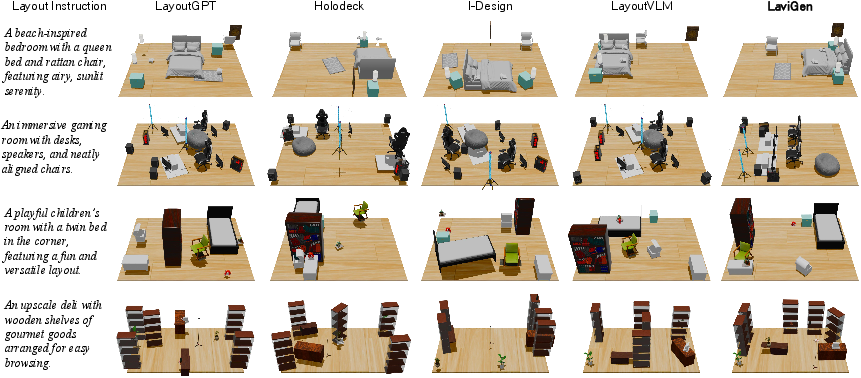
- More realistic spaces: Compared to other methods that treat layouts like text or rely on 2D images, LaviGen made 3D rooms with far fewer problems like objects colliding, interpenetrating, floating, or going out of bounds.
- Better physical plausibility: On a public test (LayoutVLM benchmark), it scored higher on being collision-free and staying within room boundaries. The paper reports about 19% better physical realism than the previous best method.
- Faster: It ran about 65% faster than a strong baseline that uses image-based refinement.
- Flexible: Because it works directly in 3D, it can:
- Complete a partially designed room (layout completion).
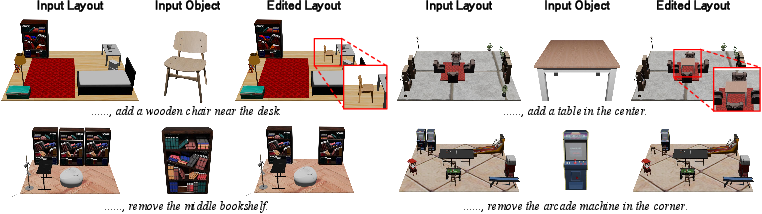
- Edit a layout by inserting, removing, or replacing objects while keeping the scene consistent.
- People preferred it: In a user study, people chose LaviGen more often for physical realism and overall quality.
Why this matters
- For games, VR/AR, and interior design tools: You get smarter automatic room setups that feel natural and look good right away.
- For robots and simulations: Realistic, physically sensible layouts help robots navigate or interact with rooms more reliably.
- For creativity: Designers can quickly try ideas, fill in missing pieces, or make edits without starting over.
A few key ideas explained in everyday language
- Native 3D space: The model “thinks” directly in 3D, like placing real objects on a floor plan, rather than converting everything to text or flat images.
- Autoregressive (step-by-step) placement: It adds objects one at a time, checking how each new object fits with the rest—like you would when decorating a room.
- Diffusion model: Starts from a noisy guess and gradually cleans it up into a good layout, guided by learned 3D knowledge.
- Exposure bias: If you only practice with perfect examples, you may stumble when things aren’t perfect. Training with your own outputs prepares you for reality.
- Distillation: A way to “teach” a smaller/faster model by learning from a stronger “teacher” model, keeping accuracy while boosting speed.
Limitations and future directions
- Small objects can be tricky: The model uses a 3D grid that’s not super high resolution. Tiny items may be harder to place precisely.
- The authors plan to explore more efficient ways to use finer 3D details and improve handling of small or complex objects.
Bottom line
LaviGen is like a smart interior designer for 3D spaces. It places objects directly in 3D, one by one, using strong geometric “common sense,” and learns to avoid mistakes as it goes. It produces layouts that look right, obey physics, and can be created quickly—making it useful for games, VR/AR, robotics, and creative tools.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of unresolved issues and concrete open problems that future work could address:
- Limited spatial resolution: the voxel grid under-represents small or thin objects and fine spatial relations; explore adaptive grids (e.g., octrees), multi-resolution latents, or sparse convs to improve small-object placement without prohibitive memory.
- Post-hoc object fitting fragility: alignment via ICP and least-squares to a “newly generated region” is sensitive to symmetry, clutter, and noise; quantify failure modes and investigate learned shape-to-occupancy registration or contact-aware fitting.
- Narrow physics modeling: “physical plausibility” is evaluated with collision-free and in-boundary checks only; incorporate support/stability (contact normals, gravity), friction, and affordance constraints, or lightweight physics-in-the-loop training/inference.
- Dependence on pre-existing 3D assets: the pipeline assumes access to target object meshes ; extend to category-level planning (place-by-class with later retrieval) or joint layout + object synthesis when assets are unknown.
- Autoregressive ordering not studied: the impact of object placement order (LLM-derived vs. heuristics like bottom-up or heavy-first) on error accumulation and plausibility is unquantified; develop order-optimization or learned policies and report sensitivity.
- Long-sequence robustness: beyond qualitative >20-object examples, there is no quantitative evaluation of performance degradation with sequence length; benchmark CF/IB/semantic scores across 10–50 objects and analyze compounding errors.
- Generalization to real and diverse scenes: training/evaluation focus on synthetic indoor datasets (3D-FRONT, InternScenes); test on real scans (e.g., ScanNet, Matterport3D), multi-room and non-Manhattan layouts, outdoor and mixed environments.
- Semantic evaluation reliability: semantic alignment uses GPT-4o ratings from limited views; validate with human annotations, 3D-aware metrics, or CLIP-like view-aggregated scoring, and report inter-rater reliability/bias sensitivity.
- Real-time interaction: the reported ~24 s for 8–10 objects is not interactive; profile per-object latency and explore fewer denoising steps, distillation schedules, or caching to achieve sub-second edits.
- Exposure-bias mitigation scope: dual-guidance self-rollout is validated on the target benchmarks, but its stability and critic-teacher interplay are not analyzed; study convergence, sensitivity to critic updates, and failure cases (e.g., drift, mode collapse).
- Ordering/teacher choice ablations: the dual-guidance scheme uses a bidirectional holistic teacher and a causal step-wise teacher; compare alternative teachers (e.g., physics-regularized, larger/smaller priors) and different weightings or curriculum schedules.
- Rotational and orientation biases: voxel grids can bias rotation handling and small-angle precision; evaluate orientation errors explicitly and consider rotation-equivariant architectures or continuous pose latents.
- Door/window/fixture constraints: layouts rarely consider doors, windows, and clearances; integrate architectural constraints and evaluate on scenes with functional pathways and egress requirements.
- Editing evaluation: layout editing is only demonstrated qualitatively; define quantitative edit metrics (locality, minimal unintended change, post-edit CF/IB/semantic deltas) and compare to baselines.
- Instruction robustness: robustness to ambiguous, contradictory, or under-specified instructions is untested; benchmark with noisy/ambiguous prompts and analyze failure modes and uncertainty reporting.
- Multimodal conditioning breadth: only text-based conditioning is studied; assess conditioning from sketches, floor plans, or partial scans and quantify cross-modal generalization.
- Language and domain coverage: the text encoder is frozen (Qwen2.5-VL-7B); examine multi-lingual prompts, domain shifts (e.g., commercial/industrial layouts), and fine-tuning strategies for domain adaptation.
- Bias from auto-generated annotations: GPT-4o-generated asset annotations may inject biases or noise; analyze annotation quality, propagate uncertainty into training, and study its effect on spatial priors.
- Constraint-aware controllability: beyond implicit priors, explicit constraints (e.g., “desk 1.2 m from window,” symmetry, alignment along walls) are not supported; introduce constraint tokens or differentiable solvers for precise control.
- Diversity calibration: while diverse outputs are shown, diversity is not quantified; report coverage/diversity metrics (e.g., set coverage over relational constraints) and assess trade-offs with plausibility.
- Category and asset OOD robustness: test performance on unseen categories, unusual aspect ratios, and procedurally generated assets to assess generalization beyond the training distribution.
- Scaling and memory footprint: training relies on large GPU budgets; profile memory/compute, explore parameter-efficient backbones, token pruning, or sparse attention for broader accessibility.
- Evaluation beyond CF/IB: collisions and boundaries do not capture higher-order relations (e.g., functional groupings, reachability); add metrics for relational correctness (distance/angle distributions), accessibility, and human factors.
- Theoretical guarantees: the method offers empirical plausibility but no guarantees of constraint satisfaction; investigate projection layers or constraint-aware denoisers that ensure hard constraints at each step.
- Integration with downstream tasks: applicability to robotics/AR (e.g., navigation, grasp planning) is asserted but not validated; perform task-driven evaluations where layout quality impacts downstream performance.
Practical Applications
Overview
Based on the paper’s findings—native 3D autoregressive layout generation, an adapted 3D diffusion model with identity-aware embeddings, and dual‑guidance self‑rollout distillation—LaviGen enables physically plausible, semantically coherent, and editable 3D layouts with faster inference than prior methods. Below are practical, real‑world applications organized by deployment horizon, with sector links, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
- 3D content creation and game development (software, media/entertainment)
- Use case: Rapid scene “dressing” and grayboxing in Unity/Unreal/Blender for level/blockout design from short instructions (e.g., “a small kitchen with an island and two stools”).
- Tools/workflows:
- LaviGen-powered plugin for Unity/Unreal/Blender that ingests a room shell and an asset library, then sequentially places objects; an “Auto‑Layout Assistant” panel for prompt → layout → edit.
- Batch generation for A/B scene variants to support art direction and playtesting.
- Assumptions/dependencies:
- Availability of a curated 3D asset library with canonical scales/orientations and room boundary geometry; GPU/cloud inference (~tens of seconds for 8–10 objects); format bridges (e.g., glTF/FBX, voxel-to-mesh fitting) integrated into DCC tools.
- Interior design and e‑commerce visualization (retail, real estate, AR)
- Use case: “One‑click” arrangement of products in a user’s scanned room (e.g., sofa + rug + coffee table) with collision-free placement for online furniture retail or AR “try‑in‑room” apps.
- Tools/workflows:
- Cloud API that accepts a LiDAR/photogrammetry room scan, store catalog meshes, and a style prompt; returns a staged scene plus multiple alternatives.
- In-app layout editing (insert/remove/replace) for shoppers and sales associates.
- Assumptions/dependencies:
- Accurate room capture/segmentation; asset-scale normalization; domain adaptation from synthetic training (3D‑FRONT/Objaverse) to real rooms; latency acceptable for interactive shopping (likely cloud, not edge).
- Virtual staging for real estate (real estate marketing)
- Use case: Automated staging of empty floor plans or scans into multiple décor styles with physically plausible arrangements.
- Tools/workflows:
- Pipeline: reconstruct room → LaviGen generates base layouts → agent performs style sweeps (e.g., modern, minimalist) → export renders or WebGL viewers.
- Assumptions/dependencies:
- Good wall/door/window geometry; adherence to basic staging constraints; licensing of 3D assets; human QA for final selection.
- Robotics simulation scene generation (robotics, autonomy R&D)
- Use case: Large-scale creation of physically plausible indoor environments for training navigation/manipulation policies (reducing object collisions and implausible placements).
- Tools/workflows:
- Data generation in Isaac Sim, Habitat, or Gibson: programmatically produce thousands of apartments/rooms with realistic clutter; export semantic maps for supervised learning.
- Assumptions/dependencies:
- Simulator connectors; assets with appropriate physical properties; coverage of target domain layouts; labeling pipelines for tasks (e.g., object search, rearrangement).
- CAD/architecture education and prototyping (education, AEC)
- Use case: Teaching spatial reasoning and building rapid floor plan prototypes with exemplar furniture placements.
- Tools/workflows:
- Classroom modules: students prompt room intent and iterate layouts; instant collision/boundary checks and object edits; export to CAD/BIM formats for refinement.
- Assumptions/dependencies:
- BIM/CAD interoperability (e.g., IFC/Revit families mapping to asset geometry); unit consistency and scale validation.
- Scene QA and automated plausibility checks (software QA for 3D pipelines)
- Use case: Automated collision-free and in‑boundary validation during build pipelines for games/VR/AR content; optional “auto‑fix” via LaviGen re‑placement.
- Tools/workflows:
- CI/CD job: run CF/IB checks at every scene commit; trigger LaviGen to re‑arrange flagged areas; produce diffs for review.
- Assumptions/dependencies:
- Stable thresholds and units; per‑project collision tolerances; reproducibility across compute nodes.
- Academic benchmarking and dataset augmentation (academia)
- Use case: Baseline for 3D layout completion/editing research; generation of labeled scene corpora with coherent placements for downstream tasks (e.g., affordance learning).
- Tools/workflows:
- Reproducible scripts to generate benchmarks; ablation-ready configs for studying exposure bias mitigation and 3D priors.
- Assumptions/dependencies:
- Compute and storage for dataset generation; careful license management for assets and annotations.
- Personalized VR/Metaverse room setup (daily life, consumer VR)
- Use case: Users auto‑populate personal virtual spaces (e.g., social VR rooms) with themed layouts and then tweak via simple edits.
- Tools/workflows:
- In‑app “Generate Layout” → “Edit by instruction” loops; lightweight mesh fitting for platform constraints.
- Assumptions/dependencies:
- Platform-specific performance budgets; content moderation/style constraints.
Long-Term Applications
- Real-time AR layout generation on-device (mobile AR, consumer apps)
- Use case: Interactive in-room layout placement that updates live as the user moves the device, with immediate collision-aware edits.
- Tools/workflows:
- Distilled, quantized LaviGen variants; streaming or hybrid edge/cloud inference; incremental updates to avoid re‑generating full scenes.
- Assumptions/dependencies:
- Significant model compression and acceleration; robust tracking/SLAM and room understanding; low-latency networking when offloading compute.
- Robotics with layout priors for perception and planning (robotics, smart home)
- Use case: Layout-informed object search/navigation and rearrangement in real homes (e.g., predicting plausible chair placements to guide search).
- Tools/workflows:
- Fuse LaviGen priors with SLAM maps and semantic segmentation; integrate hard constraints (sensors, reachability) into autoregressive placement for planning hypotheses.
- Assumptions/dependencies:
- Tight coupling with perception stacks; continual adaptation to real-world distributions; formal safety constraints; online inference budgets.
- Code- and policy-aware layout generation (policy, AEC, facilities)
- Use case: Generate and validate room layouts against accessibility (e.g., ADA), fire egress, and safety clearance regulations.
- Tools/workflows:
- Constraint-augmented generation: rule engines/SMT solvers guiding diffusion steps; post-hoc verification; reports for plan approvals.
- Assumptions/dependencies:
- Formalized rulesets and machine-readable codes; precise units and tolerances; auditable pipelines for compliance.
- Hospital/retail/warehouse layout optimization (healthcare, retail, logistics)
- Use case: Multi-objective layout synthesis (flow efficiency, safety, throughput) beyond aesthetics; scenario exploration at scale.
- Tools/workflows:
- Coupling LaviGen with simulators (e.g., crowd/agent-based, material handling) and optimization loops; reinforcement learning over generated variants.
- Assumptions/dependencies:
- Domain-specific cost functions and constraints; datasets of operational patterns; higher-resolution modeling and accurate physical parameters.
- Generative BIM and digital twins (AEC, smart buildings)
- Use case: From 2D plans or sparse scans to fully furnished BIM/digital-twin interiors with rule-constrained placements and metadata.
- Tools/workflows:
- Revit/IFC plugins: map LaviGen placements to parametric BIM families; synchronize with asset catalogs and facility standards.
- Assumptions/dependencies:
- Reliable plan-to-3D reconstruction; strict unit fidelity; metadata mapping (types, fire ratings, maintenance data).
- Ergonomic and personalized layout synthesis (healthcare, accessibility, workplace)
- Use case: Generate layouts tailored to user anthropometrics and mobility needs (e.g., wheelchair turning radii, reachability).
- Tools/workflows:
- Conditioning on ergonomic models and user profiles; automatic clearance enforcement and evaluation dashboards.
- Assumptions/dependencies:
- Accurate human factors models; integration with wearable/device measurements; clear objective trade-offs.
- Dynamic scenes and physics-rich environments (simulation, training, safety)
- Use case: Extend to time-varying layouts (moving furniture/agents) and rigid-body constraints for advanced training sims (e.g., evacuation).
- Tools/workflows:
- Hybrid generative+physics loops; differentiable physics for constraint satisfaction; agent models for crowd dynamics.
- Assumptions/dependencies:
- Stable simulation coupling with generative steps; datasets for dynamic interactions; computational scalability.
- Cross-domain generalization (outdoor/industrial, multi-scale environments)
- Use case: Apply to factory floors, outdoor installations, or events with non-residential objects and larger scales.
- Tools/workflows:
- Domain-adaptive training on new object/scene distributions; hierarchical layout reasoning (zones → objects → fine placement).
- Assumptions/dependencies:
- New datasets and labels; modified priors for non-furniture geometries; extended resolution beyond current 64³ limits.
- Secure, privacy-preserving in-home generation (policy, consumer tech)
- Use case: On-device or federated layout generation for private home scans, minimizing data exposure.
- Tools/workflows:
- Federated finetuning; secure enclaves; differentially-private annotations.
- Assumptions/dependencies:
- Efficient on-device models; privacy governance; user consent frameworks.
- LLM-integrated design co-pilots (software, productivity)
- Use case: Chain-of-thought design assistants that decompose high-level briefs into sequential 3D placements with rationale and revisions.
- Tools/workflows:
- Tighter coupling between LLM planning and LaviGen’s 3D autoregression; interactive “why this placement” explanations; multi-turn refinement.
- Assumptions/dependencies:
- Reliable semantic-to-geometry mappings; guardrails for hallucination; UX for human-in-the-loop oversight.
Notes on global feasibility across applications:
- Current grid resolution (64³) limits fidelity for small objects; higher-resolution or multi-scale schemes may be required for professional AEC and safety-critical use.
- Inference currently targets batch/offline or near-interactive speeds; real-time AR and robotics demand significant optimization or specialized hardware.
- Generalization from synthetic training corpora to diverse real-world interiors may require domain adaptation and curated asset libraries.
- For regulated or safety-critical domains, explicit constraint integration and post-verification are necessary; text-only conditioning is insufficient for guaranteed compliance.
Glossary
- Autoregressive: A sequential generation strategy where outputs are produced step-by-step, each conditioned on previous outputs. "LaviGen formulates layout generation as an autoregressive process."
- Bidirectional attention: An attention mechanism that allows information flow in both temporal directions, often unsuitable for strictly causal generation. "conventional diffusion models with bidirectional attention perform poorly on such autoregressive tasks"
- Causal autoregressive model: A model that enforces causal (past-to-future) dependencies for step-wise generation. "we use the causal autoregressive model from \cref{sec:auto_layout_gen} as a per-step teacher ."
- Classifier-Free Guidance (CFG): A sampling technique that trades off conditional fidelity and diversity by interpolating between conditional and unconditional model predictions. "we adopt classifier-free guidance (CFG)~\cite{cfg} with a drop rate of 0.1"
- Cross-attention: An attention mechanism that conditions one set of tokens on another (e.g., scene tokens conditioned on text). "The model then performs denoising conditioned on through cross-attention, producing the updated scene state ."
- Critic (model): A network trained to estimate scores or gradients of a target distribution, used to stabilize or guide student models. "minimizing the reverse KL divergence via score distillation with a learned critic model."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion-based denoising in structured domains. "a diffusion transformer (DiT)~\cite{dit} for structured denoising in 3D space."
- Distribution Matching Distillation (DMD): A distillation objective that aligns student and teacher distributions, often via score matching. "We instantiate as distribution matching distillation~\cite{yin2024improved}"
- Exposure bias: The mismatch between training on ground-truth contexts and inference on self-generated contexts in autoregressive models, causing error accumulation. "autoreg generation inherently suffers from exposure bias~\cite{huang2025self};"
- Flow Matching: A generative modeling framework that learns a vector field to transport noise to data along continuous-time paths. "For generation, TRELLIS adopts Flow Matching models, which add noise to clean data samples through over time step ."
- Flow transformer: A transformer architecture used to parameterize dynamics or flows in continuous generative processes. "The design of our flow transformer builds upon the architecture of Qwen-Image~\cite{qwenimage} and integrates the Multimodal Diffusion Transformer (MMDiT)~\cite{mmdit}"
- Holistic guidance: A training signal that supervises the global, scene-level outcome rather than only local steps. "Holistic Guidance."
- Identity-aware embedding: Positional/feature encoding augmented with identity signals to distinguish sources (e.g., scene vs. object tokens). "an identity-aware embedding is introduced to explicitly encode the source identity of each token."
- Identity flag: An explicit indicator embedded in token positions to denote their source stream. "with an additional identity flag indicating the source of each token."
- Iterative Closest Point (ICP): An algorithm that aligns two point sets by iteratively minimizing distances between closest points. "register them to the extracted surface points via Iterative Closest Point, estimating optimal rotation, scale, and translation parameters through least-squares fitting."
- Kullback–Leibler divergence (reverse KL divergence): An asymmetric divergence measuring how one probability distribution diverges from a reference, here used in reverse form for distillation. "minimizing the reverse KL divergence via score distillation with a learned critic model."
- Latent codes: Compact learned representations (vectors) associated with spatial elements (e.g., voxels) used for generation. "Each 3D asset is represented by a set of voxel-indexed local latent codes"
- Least-squares fitting: An optimization method that estimates parameters by minimizing the sum of squared residuals. "estimating optimal rotation, scale, and translation parameters through least-squares fitting."
- Multimodal Diffusion Transformer (MMDiT): A diffusion transformer designed to jointly model multiple modalities (e.g., text and 3D). "integrates the Multimodal Diffusion Transformer (MMDiT)~\cite{mmdit}, thereby enabling unified modeling of text and 3D representations within a single Transformer framework."
- Multimodal Scalable RoPE (MSRoPE): A positional encoding scheme extending RoPE for consistent, scale-robust representations across modalities. "we incorporate a novel positional encoding mechanism, Multimodal Scalable RoPE (MSRoPE), designed to provide consistent and scale-robust positional representations across both modalities."
- Rotary Position Embedding (RoPE): A positional encoding technique that represents positions via rotations in complex space for attention. "extending the standard Rotary Position Embedding (RoPE)~\cite{rope} with an additional identity flag "
- Score distillation: A technique that uses teacher score estimates to guide the student’s generative distribution. "via score distillation with a learned critic model."
- Score function: The gradient of the log-density of a distribution, used in score-based generative modeling and distillation. "to approximate the score function of the student's generated data distribution."
- Self-rollout distillation: A training scheme where the student conditions on its own generated context during rollout and is distilled using teacher signals. "employs a dual-guidance self-rollout distillation mechanism"
- Step-wise guidance: Supervision applied at each generation step to correct placements incrementally. "Step-Wise Guidance."
- Teacher Forcing: A training procedure that feeds ground-truth context into the model at each step instead of its own predictions. "In contrast to Teacher Forcing, which conditions on ground-truth context ,"
- Variational Autoencoder (VAE): A generative model that learns latent variables via variational inference and reconstructs data. "variational autoencoder~\cite{vae} for latent encoding"
- Voxel grid: A discretized 3D volume representation composed of cubic cells (voxels). "We represent the 3D scene using a voxel grid"
- Voxel occupancy: A binary or probabilistic indication of whether voxels are occupied by geometry. "predicting sparse voxel occupancies"
Collections
Sign up for free to add this paper to one or more collections.