- The paper introduces a plug-and-play adapter that leverages decoupled cross-attention and structural masks to guide compound text-to-motion generation.
- It achieves improved semantic alignment and spatial fidelity, outperforming baselines in metrics such as R-Precision, MM-Dist, and FID.
- The approach mitigates issues like catastrophic neglect and attention collapse, paving the way for natural animation in AR/VR and robotics applications.
Motion-Adapter: A Diffusion Model Adapter for Text-to-Motion Generation of Compound Actions
Problem Statement and Motivation
The synthesis of realistic human motion sequences from textual prompts has advanced considerably, yet generating compound actions—coordinated full-body behaviors composed of multiple concurrent sub-actions—remains a major challenge in text-to-motion architectures. Existing diffusion-based models suffer from catastrophic neglect (where earlier actions are overwritten by later ones during temporal integration) and attention collapse (spatial selectivity loss in cross-attention mechanisms). Models typically demand verbose, highly explicit text inputs or resort to LLMs for body-part interpretation, which often fail to capture sufficient semantic or kinematic structure for natural action composition. This deficiency curtails practical controllability and realism, especially for prompts like "greet while walking," where concurrent actions must be mapped to distinct articulated segments.
Motion-Adapter Architecture
The paper introduces the Motion-Adapter, a plug-and-play module for guiding text-to-motion diffusion models in generating compound actions via structural masks derived from decoupled cross-attention maps. The adapter integrates with diffusion backbones such as MDM and MotionDiffuse, imposing minimal overhead and requiring no additional paired training data.
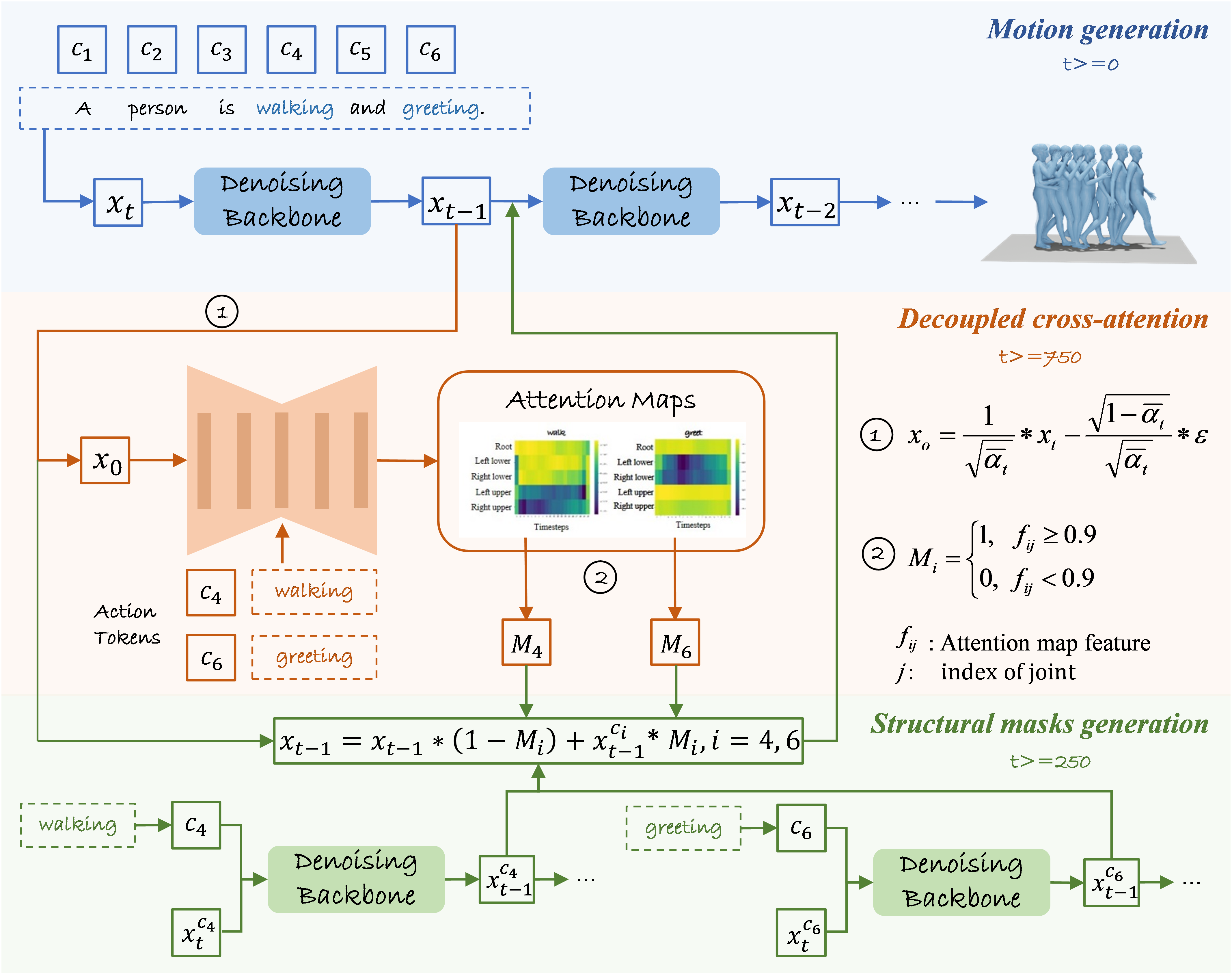
Figure 1: Overview of the Motion-Adapter integrated into the diffusion model at step t.
The adapter comprises two principal components:
- A decoupled cross-attention mechanism, where motion features (joint-wise representations) serve as queries and text embeddings (produced via CLIP) serve as keys/values.
- A structural mask generation module, transforming cross-attention maps into spatial masks applied to noisy motion predictions at each denoising step.
The decoupled cross-attention is constructed over five STEncoder modules (leveraging spatial-temporal convolutions and joint pooling), enabling robust extraction of token-to-joint correspondences. Masks represent activations for anatomical regions associated with each action token and are applied during inference to mediate the fusion of sub-actions without excessive spatial blending.
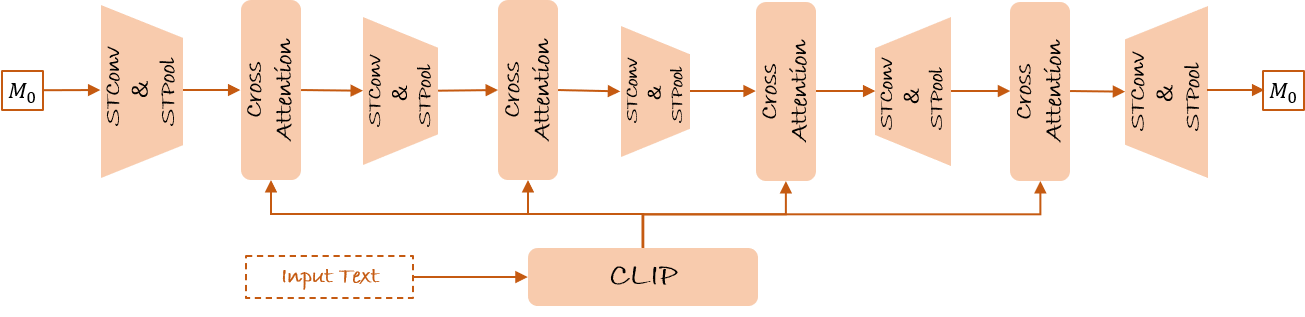
Figure 2: The architecture of the decoupled cross-attention.
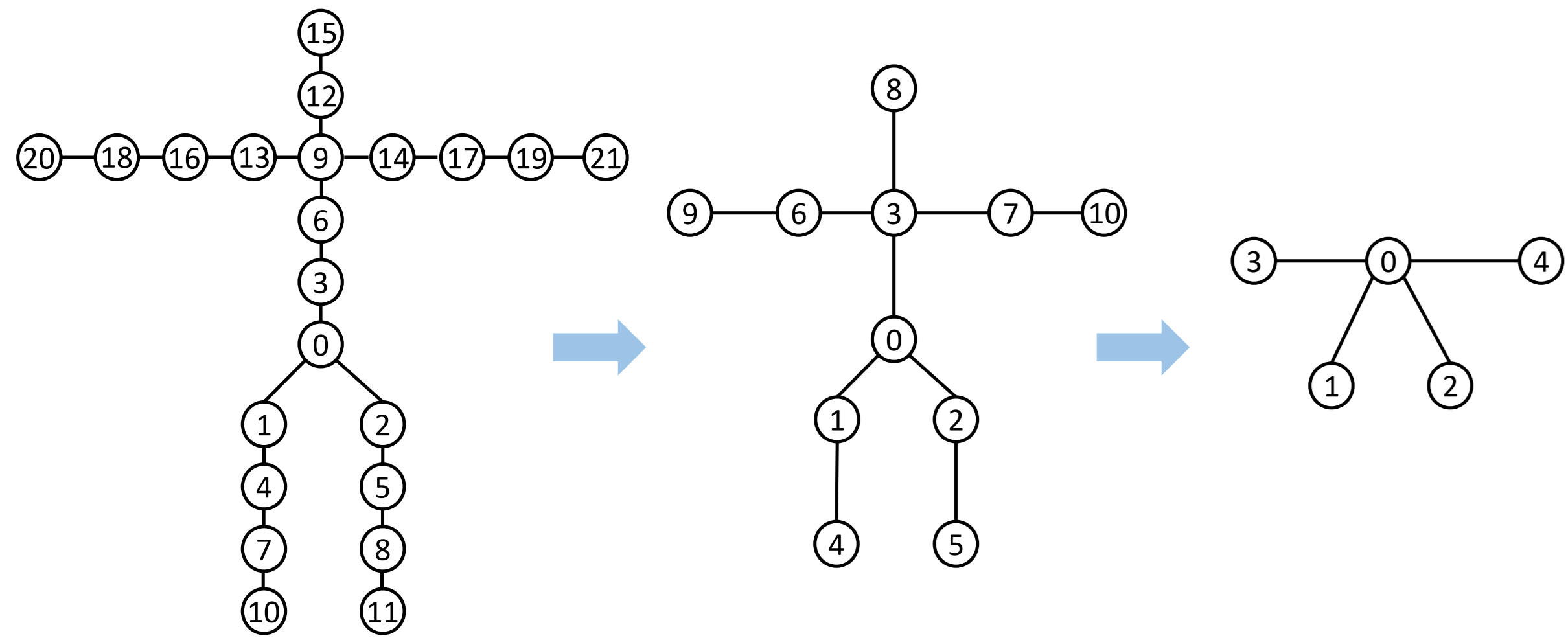
Figure 3: Illustration of the skeletal pooling on the HumanML3D dataset.
Handling Catastrophic Neglect and Attention Collapse
Compound motion generation in baseline models is impeded by attention collapse, as illustrated by comparative attention maps between SALAD and Motion-Adapter.
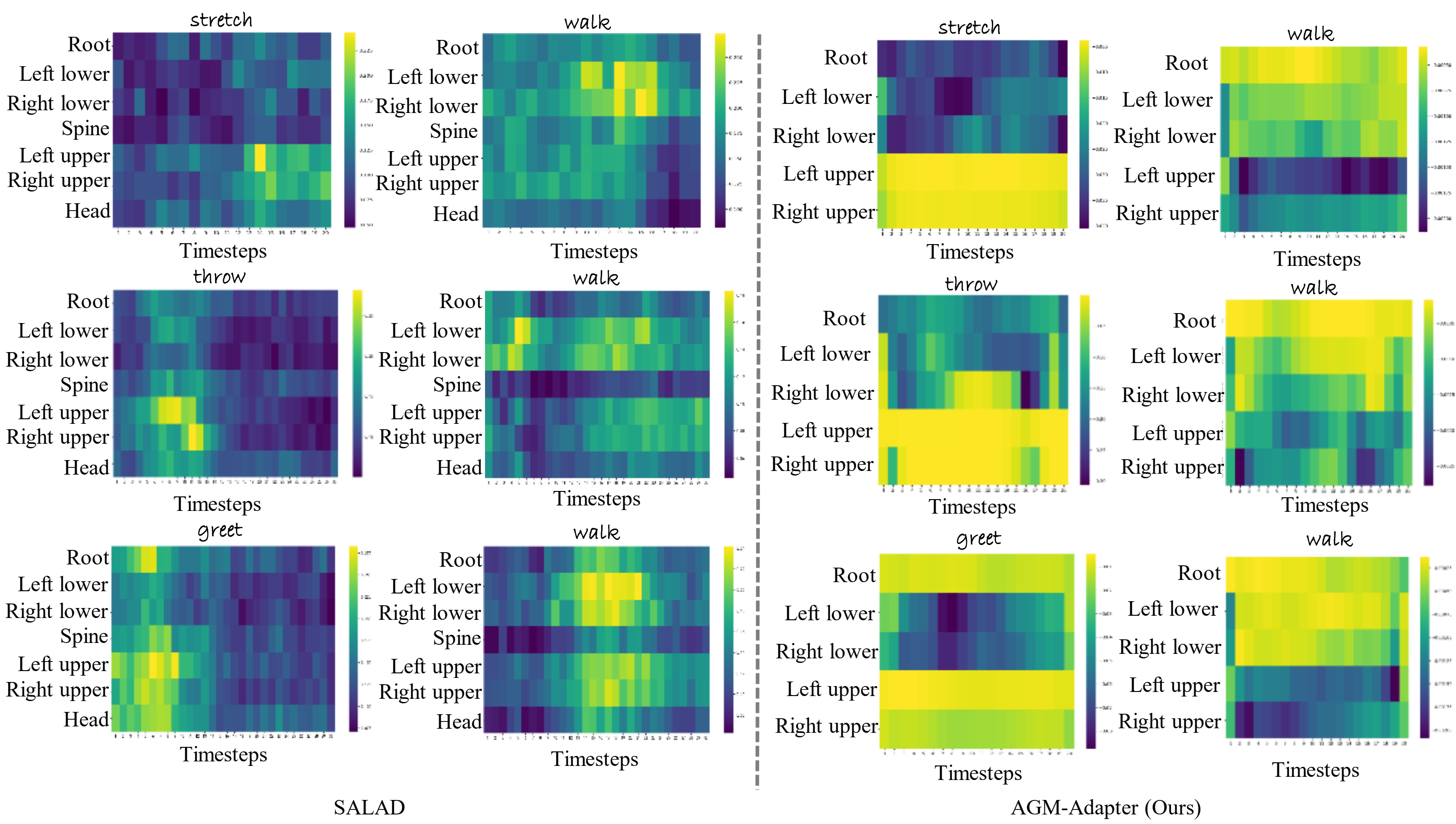
Figure 4: Comparison of attention maps from SALAD and Motion-Adapter; SALAD exhibits diffuseness across joints, while Motion-Adapter localizes actions.
Motion-Adapter’s decoupled attention ensures preservation of spatial specificity, preventing overwriting of concurrent actions by maintaining distinct structural masks per action token. This approach robustly manages overlapping or concurrent movements and enables semantically faithful, physically plausible motion generation.
Qualitative and Quantitative Evaluation
Evaluation is performed using extensive benchmarks on compound prompts, paired upper-body and lower-body actions. Motion-Adapter is integrated with MDM and MotionDiffuse backbones, and compared against seven baselines (including text-to-motion, spatial composition, and motion editing frameworks).
Strong qualitative results show that baseline models either neglect sub-actions (e.g., lack simultaneous hand movement during walking) or execute actions sequentially rather than concurrently. In contrast, Motion-Adapter reliably produces temporally coherent, natural compound actions in both simple and complex prompts.

Figure 5: Motion sequences generated by Motion-Adapter given textual prompts and a pre-trained motion diffusion model.

Figure 6: Qualitative comparison of compound actions combining 'greeting' with 'walking' or 'running'.

Figure 7: Qualitative comparison results of compound actions combining 'stretching' with either 'hopping' or 'walking'.

Figure 8: Qualitative comparison results of compound actions combining 'throwing' with either 'walking', 'running', or 'jumping'.
Compound prompts involving multiple modifiers and complex temporal structures further evidence the robustness of the approach.
Quantitatively, Motion-Adapter-based models consistently achieve superior scores in R-Precision, MM-Dist, FID, Diversity, and Transition metrics, indicating strong semantic alignment, distributional fidelity, smoothness, and variance. For example, Motion-Adapter_MDM yields R-Precision top-3 =0.36, MM-Dist =14.95, FID =3.59, outperforming all baselines (see Table~\ref{tab: Quatitative} of the paper).
User studies confirm that the majority of generated motions by Motion-Adapter align closely with textual prompts, with fidelity ratings above 9 and perceptual quality above 87%, substantially exceeding those by baseline frameworks.
Figure 9: Results of Motion-Adapter_MotionDiffuse.
Ablation Study
Ablation studies demonstrate that removal of the Motion-Adapter or masking step constraints degrades compound action generation, causing loss of semantic alignment and smooth transitions. The core architecture effectively disentangles spatial dependencies and preserves the structural relationships critical for compound actions.
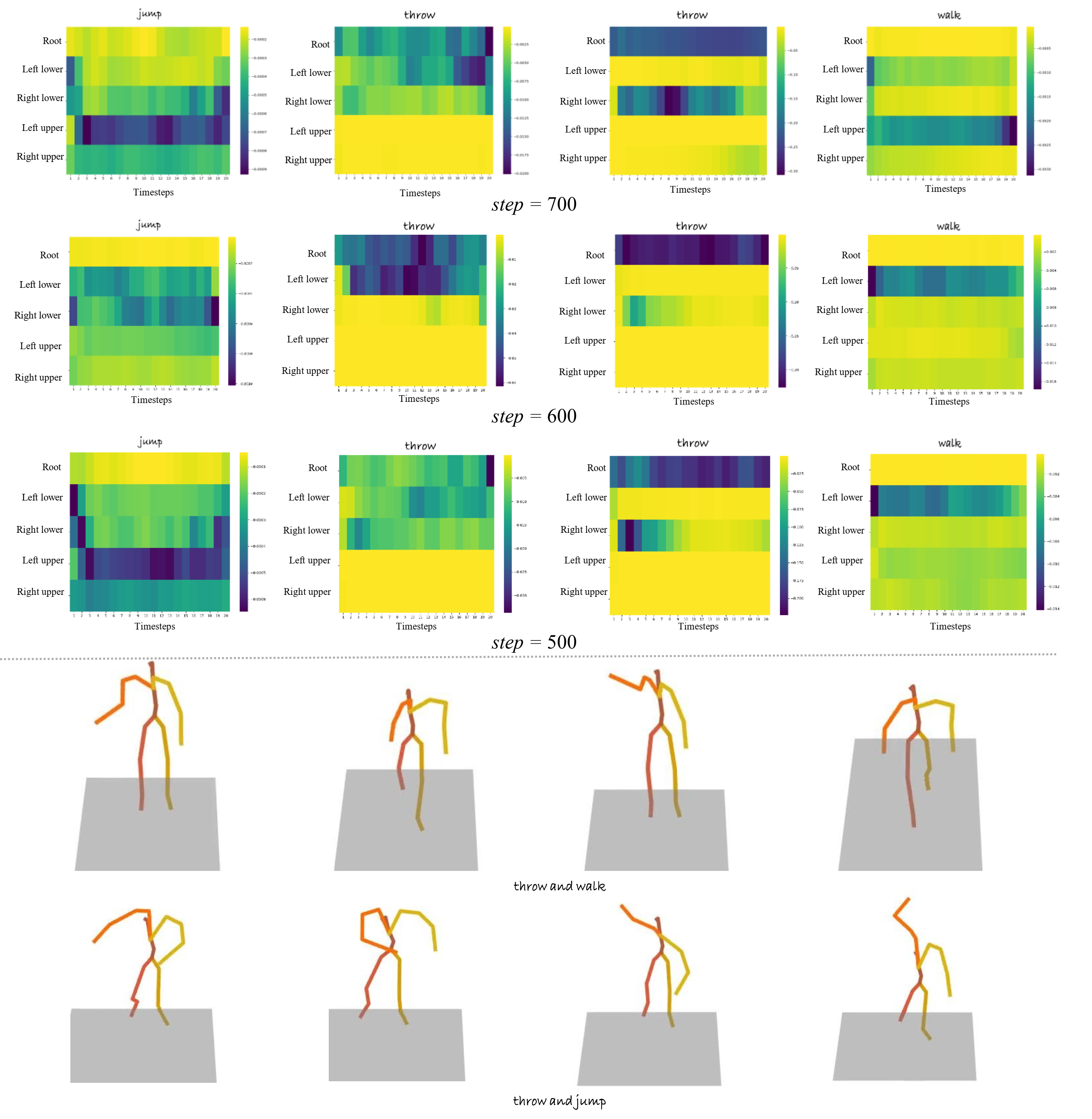
Figure 10: Attention maps extracted at t=700,600,500 along with resulting motion generated by applying masks throughout all denoising steps.
Implications and Future Directions
By integrating decoupled cross-attention and structurally tuned masking, the Motion-Adapter advances text-conditioned motion diffusion models in their capacity for compound action synthesis. Practical implications include enhanced controllability in animation, AR/VR, and robotics—where complex, naturalistic behaviors are required from succinct textual prompts. The theoretical significance lies in demonstrating that structural masks can mediate semantic-to-kinematic alignment in diffusion pipelines, bypassing the limitations of feature fusion and LLM-based text interpretation.
Limitations persist, notably the granularity of control (currently restricted to upper/lower body regions) and dependency on the expressive power of the underlying diffusion backbone. Future developments may include extension to finer body-part segmentation, dynamic mask learning, and generalized applications in broader motion editing and multi-modal synthesis.
Conclusion
This work presents Motion-Adapter, a diffusion model adapter enabling efficient text-to-motion generation of compound actions by disentangling cross-attention, generating structural masks, and guiding denoising steps to ensure semantic and spatial fidelity. The approach mitigates catastrophic neglect and attention collapse endemic to prior methods, outperforming state-of-the-art baselines in both quantitative metrics and perceptual evaluations. The research substantiates structural masking as a scalable mechanism for compound motion synthesis and opens prospects for more granular, controllable, and context-aware generative motion frameworks.

