- The paper introduces the MLA-Gen framework that leverages learnable memory slots, cross-modal token alignment, and sink-aware strategies to improve motion synthesis.
- It employs fine-grained alignment mechanisms and adaptive guidance to mitigate the attention sink phenomenon, ensuring robust temporal and semantic consistency.
- Empirical evaluations on HumanML3D demonstrate significant gains in FID, R-Precision, and semantic matching compared to prior methods.
Motion-Language Alignment for Text-Driven Motion Generation: The MLA-Gen Framework
Motivation and Challenges in Text-to-Motion Generation
Text-driven human motion generation requires synthesizing temporally and spatially coherent 3D motion sequences conditioned on natural language descriptions. Prevailing methods predominantly utilize global text embeddings (e.g., CLIP-based features) to guide motion generation, which are effective for capturing high-level semantics but insufficient for establishing detailed, temporally sensitive alignment between individual tokens and specific motion dynamics. This deficiency results in generated motions that often match coarse intent but lack fidelity in fine-grained movement details and semantic grounding, as exemplified in numerous prior failure cases.
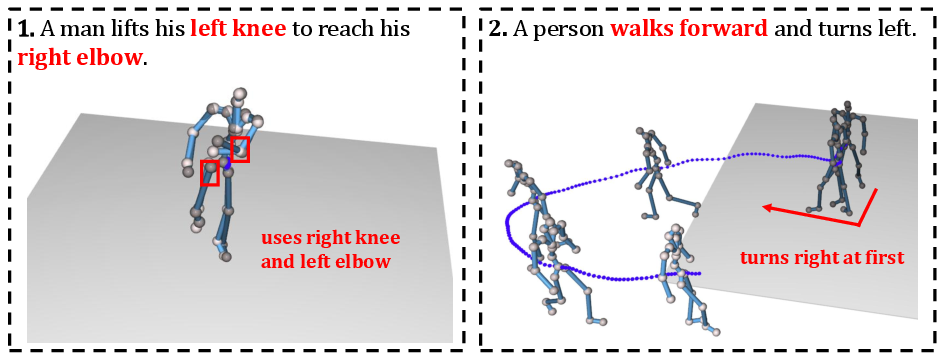
Figure 1: Failure cases from previous text-to-motion generation framework, which captures global motion patterns but often overlooks fine-grained motion details.
A central technical challenge, therefore, is achieving fine-grained motion-language alignment, ensuring that the motion generator not only adheres to the global context but also exploits local textual cues for enhanced realism and semantic precision.
The MLA-Gen Framework: Components and Architectural Innovations
MLA-Gen introduces a principled architectural approach to tackle these alignment issues via three synergistic modules: learnable memory slots, a motion-language alignment mechanism, and attention sink mitigation strategies.
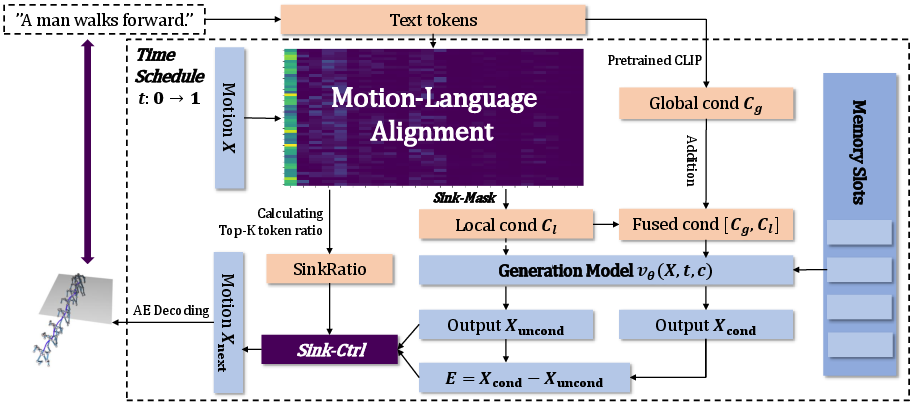
Figure 2: Overview of the MLA-Gen framework, comprising memory slots, fine-grained motion-language alignment, and attention sink mitigation strategies.
Memory Slots for Global Motion Priors:
MLA-Gen employs a set of learnable memory slots that serve as global motion prototypes, encoding shared structural patterns across the motion dataset. Within each transformer layer, motion representations query these slots via multi-head attention, retrieving contextually relevant priors that improve overall motion coherence. Heatmap visualizations of slot activations reveal heterogeneous slot focus, underpinning the slot-based structural modeling.
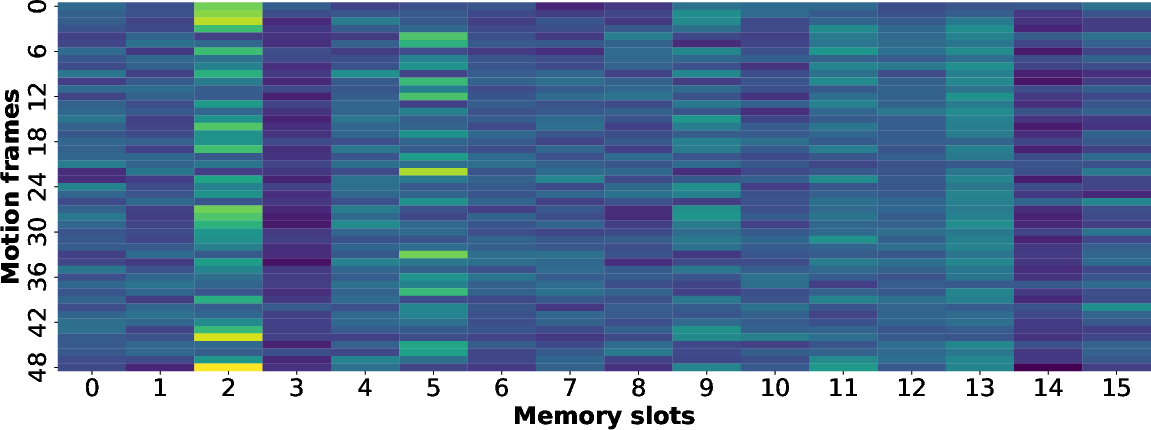
Figure 3: Heatmap of memory slot activation reveals heterogeneous retrieval of motion prototypes.
Fine-Grained Motion-Language Alignment:
Motion frames and text tokens are mapped into embedding spaces through respective encoders. A cross-modal attention mechanism computes dynamic alignment between each motion frame and textual token, facilitating granular conditioning. Local text-token features are projected, reweighted, and fused with global text embeddings, providing both coarse and fine semantic guidance. Attention heatmaps demonstrate robust alignment to semantically rich tokens (e.g., "aims", "throws", "baseball").
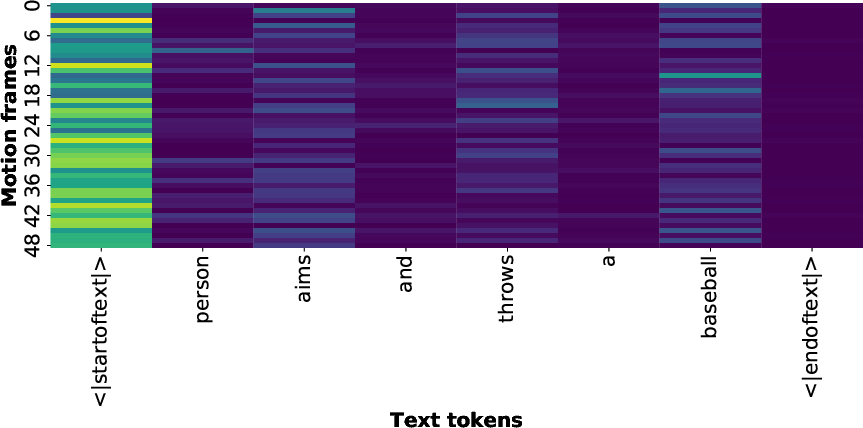
Figure 4: Heatmap of motion-language alignment, with high attention on semantically rich text tokens.
Attention Sink Phenomenon and SinkRatio Metric
MLA-Gen identifies, quantifies, and mitigates an "attention sink" phenomenon: cross-modal attention systematically fixates on the start token of textual input, inhibiting exploitation of informative tokens—a finding that parallels attention sink issues documented in LLMs [xiao2023efficient, barbero2025llms, rulli2025attention].
SinkRatio Metric:
A top-K strategy is adopted to compute SinkRatio, the mean concentration of attention weights to the highest-attended tokens for each motion frame. Higher SinkRatio values indicate greater attention fixation, leading to reduced semantic informativeness. Ablative masking experiments show that attention sink persists even after masking the start token, relocating to subsequent neutral tokens, indicative of deep-seated adaptive model bias.
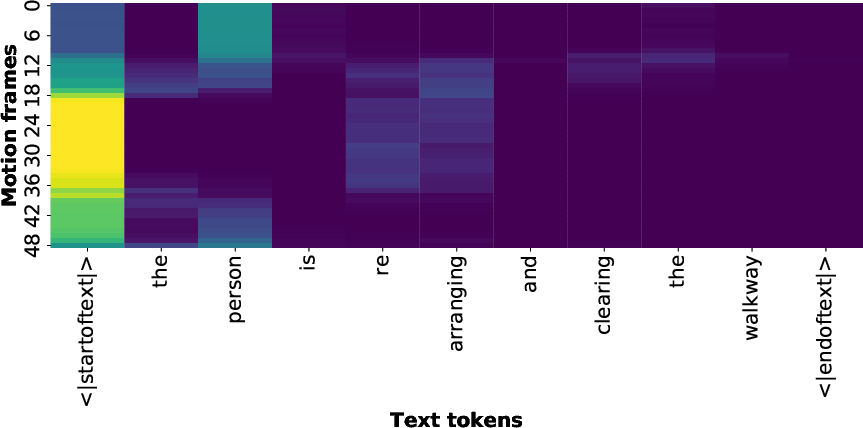
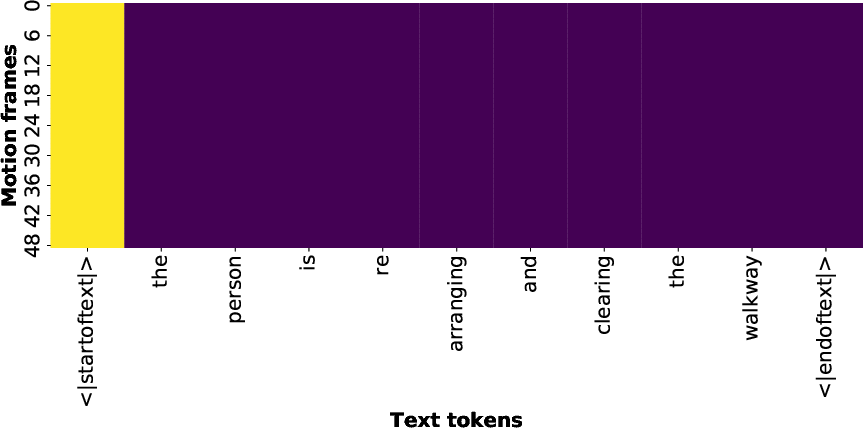
Figure 5: Heatmaps comparison of alignment on masked model (left) and unmasked model (right); masking reduces but does not eliminate sink.
Temporal SinkRatio Analysis:
Temporal curves demonstrate that sink-mask mechanisms induce decreasing SinkRatio across timesteps, mitigating the intensification of attention sink and promoting balanced token utilization.
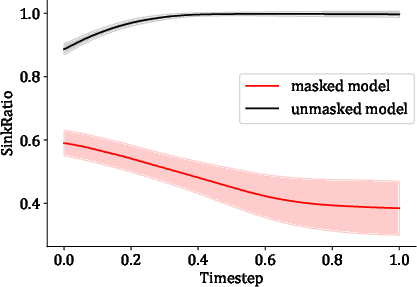
Figure 6: SinkRatio curves for masked and unmasked models; masking reduces attention concentration.
Sink-Aware Generation Strategies
MLA-Gen introduces two sink-aware strategies:
Sink-Mask (Token Weight Masking):
Start-token attention weights are masked above a timestep threshold, enforcing more distributed attention and compelling the model to utilize broader semantic cues.
Sink-Ctrl (Adaptive Classifier-Free Guidance):
CFG guidance strength is rectified by an adaptive coefficient scaled by SinkRatio, amplifying corrective updates when SinkRatio is high. Local text features are injected into unconditional branches to stabilize generation.
Empirical Evaluation and Ablation
MLA-Gen is extensively evaluated on the HumanML3D benchmark. Strong numerical gains are reported in FID (0.107→0.056 small-scale, 0.083→0.040 big-scale), R-Precision, Matching, and CLIP score, indicating improved distributional quality, semantic alignment, and motion diversity. Ablation studies confirm the necessity of both memory slots and local alignment modules, with sink-aware strategies yielding marked performance gains. Visualization comparisons against ACMDM reveal higher fidelity in temporal consistency and joint-level semantic matching.
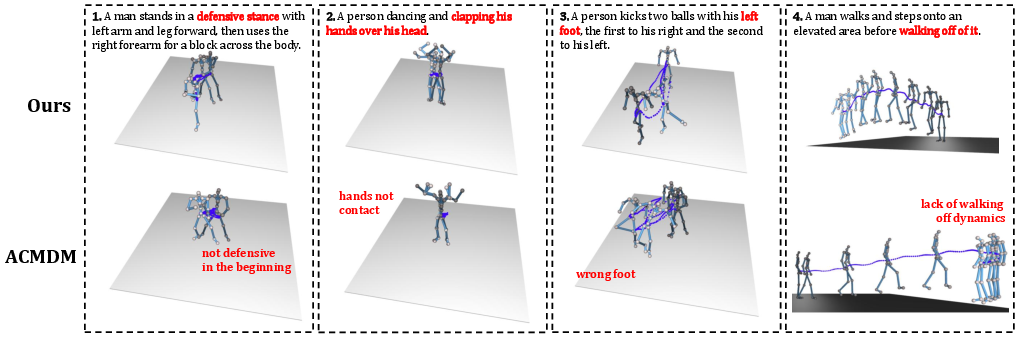
Figure 7: Visualization comparison between ACMDM-S and MLA-Gen-S, highlighting joint-level and temporal semantic fidelity.
Limitations and Prospects
Despite robust alignment improvements, MLA-Gen exhibits limitations with lengthy or syntactically ambiguous textual descriptions, where attention-based mechanisms struggle to capture complex hierarchical semantics.
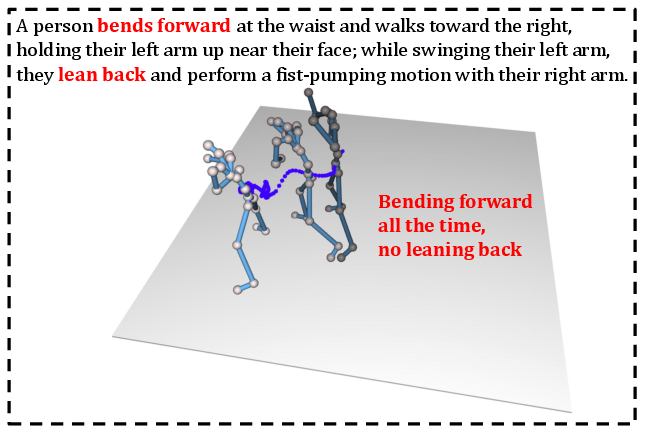
Figure 8: A failure case of MLA-Gen under a very long textual description.
SinkRatio, while effective for quantifying attention concentration, does not directly capture higher-order or structured semantic dependencies. Future research may involve extending alignment diagnostics, integrating structured priors, and scaling alignment-aware strategies to broader multimodal domains (e.g., video generation, agent control).
Conclusion
MLA-Gen advances text-driven motion generation via explicit motion-language alignment, mitigation of attention sink bias, and adaptive generation strategies. These findings underscore the criticality of detailed cross-modal alignment in multimodal generation architectures and highlight opportunities for future methodological innovation in semantically grounded synthesis.

