- The paper presents a unified taxonomy that accelerates video diffusion models using step distillation, efficient attention, model compression, and cache optimization.
- It introduces techniques that reduce computational demands by compressing multi-step denoising into few-step generators while managing high memory and spatial-temporal costs.
- The study outlines future directions including hardware/software co-design and error-budget strategies to enable scalable, real-time, long-horizon video synthesis.
Efficient Video Diffusion Models: Advancements, Challenges, and Systematic Analysis
The paper "Efficient Video Diffusion Models: Advancements and Challenges" (2604.15911) presents the first deployment-oriented systematic survey of algorithmic and architectural accelerations for video diffusion models (VDMs), consolidating and unifying a rapidly emerging and fragmented literature. While transformer-based VDMs (notably DiT-family and MMDiT) have achieved state-of-the-art fidelity, their computational requirements—owing to the joint burdens of high spatial resolution, long temporal context, and expensive iterative denoising—far exceed those of image diffusion counterparts. These costs are compounded multiplicatively rather than additively, making attention and memory management principal bottlenecks in real-time, interactive, or long-horizon video synthesis tasks. The paper distinguishes the unique efficiency challenges in VDMs and delivers a technical taxonomy, organizing the literature into four primary acceleration paradigms: step distillation, efficient attention, model compression, and cache/trajectory optimization, each addressing distinct and often complementary aspects of sampling cost.
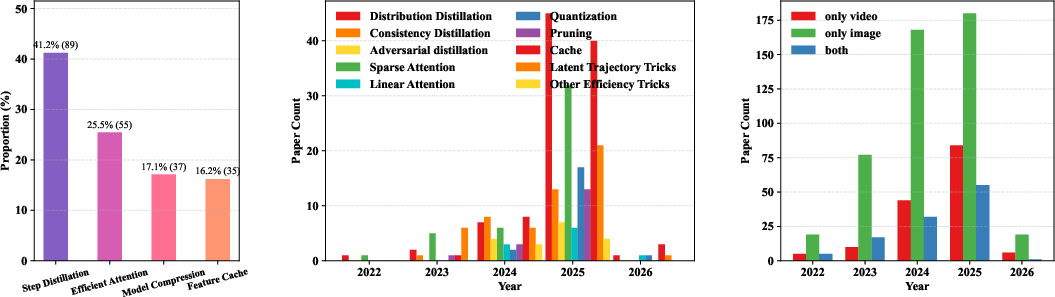
Figure 1: The distribution and temporal trends of accelerated sampling research and adoption in video diffusion models versus image diffusion, indicating a recent surge and diversification of approaches targeting the video domain.
Taxonomy of Efficient Video Diffusion Methods
To systematize the landscape, the survey proposes a four-fold categorization, visualized in (Figure 2):
Step Distillation: Distribution Matching, Consistency, Adversarial Roots
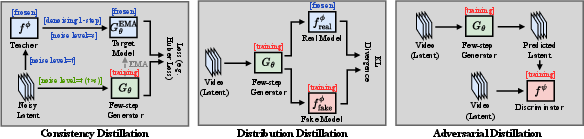
Figure 3: Schematic of the step distillation paradigm: mapping long multi-step denoising into low-step generators using distributional, consistency, and adversarial methods.
Step distillation is the most aggressive and effective pathway for minimizing overall video generation latency, compressing typical sampling counts (∼50–100 steps) into as few as one to four. Two major families exist:
- Consistency Distillation: Enforces self-consistency between noisy states on the denoising path, yielding stable few-step models (e.g., LCD, VideoLCM) and broad task robustness, though aggressive reduction in NFE remains challenging due to its conservative objectives.
- Distribution Distillation (DMD, DMD2, TDM, etc.): Aligns student and teacher output distributions, enabling successful scaling to very low-step regimes at the cost of stability and increased reliance on critic auxiliaries and rollout techniques (e.g., CausVid, Self-Forcing, see Figure 4).
- Adversarial Distillation: Used primarily for sharpening and fine detail enhancement, typically as an auxiliary to distribution/consistency objectives rather than standalone.
Recent work on streaming and real-time video generation employs causal frameworks and autoregressive train-test bridging (e.g., Self-Forcing, Live Avatar) to address error accumulation and exposure bias.
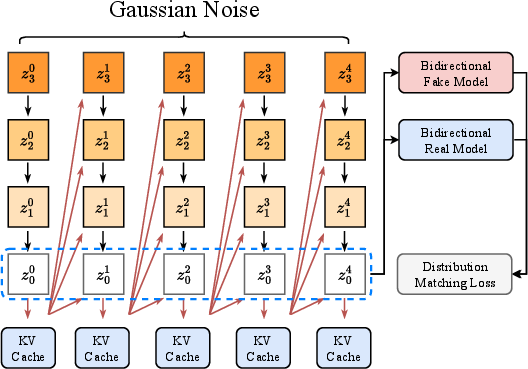
Figure 4: Schematic of the Self-Forcing algorithm, a causal real-time framework leveraging DMD for robust low-step streaming video generation.
Efficient Attention: Static/Dynamic Sparsity and Model Redesign
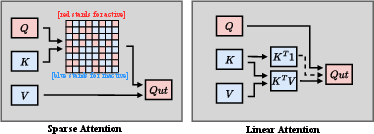
Figure 5: Taxonomy of efficient attention designs for VDM acceleration, highlighting dynamic/static sparsity and hybrid/linear attention.
High token counts in video DiTs sharply escalate raw attention costs. The state-of-the-art splits into:
Sparse attention with hardware-aware block patterns dominates practical acceleration; fully dynamic or linearized approaches present integration and expressivity challenges, especially in open-ended or temporally complex scenes.
Model Compression: Quantization, VAE, Pruning
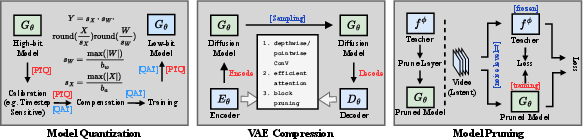
Figure 7: Model compression strategies for VDMs, including quantization-aware/post-training quantization, VAE latent compression, and multi-granular pruning schemata.
Compression reduces per-step overhead, with methodology split as follows:
- Quantization: Both quantization-aware training (QAT) and post-training quantization (PTQ) are mature, with a trend towards fine-tuned (timestep-/group-/layer-aware) calibration to handle the heavy-tailed, temporally variant statistics of VDMs.
- VAE Compression: Reduces both encode/decode cost and the input sequence length for downstream denoising, increasingly favoring compatibility-preserving and structure-motion disentanglement designs. Lossy compression can exacerbate upstream errors.
- Pruning: Token, channel, and model pruning are less impactful than attention/step/NFE approaches; current successful strategies involve distillation-based quality recovery and sensitivity-aware removal (e.g., block/FFN-depth prioritization).
Cache and Trajectory Optimization: Feature/KV Reuse, Denoising Path Engineering
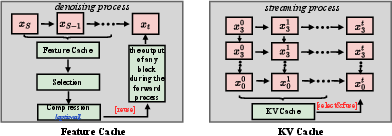
Figure 8: Methods for cache and trajectory optimization including feature and KV reuse, local/global trajectory editing, and system-level execution enhancements.
Execution-side methods eschew parameter changes and instead:
- Feature Cache: Skips or reuses intermediate activations when inter-step drift is minimal, but must balance adaptive refresh with error control to avoid temporal inconsistency.
- KV Cache: Essential for autoregressive/streaming generation; the main challenges are how to compress/summarize history while preserving cross-chunk consistency.
- Noise/State/Trajectory Modification: Local or global denoising route tweaks (e.g., adaptive timestep allocation, coarse-to-fine schedulers) to exploit redundancy or skip unneeded passes.
- Parallelization and System Design: Includes overlapping across temporal blocks, pipeline-level optimization, and memory scheduling for large/batch generation.
Implications, Open Problems, and Future Directions
The survey emphasizes that effective video diffusion acceleration arises from synergistic co-optimization, not from isolated method stacking. Most notably:
- Quality degradation in composite-acceleration pipelines is nonlinear; naively combining step reduction with aggressive per-step approximations, or feature/kV reuse without explicit error budgeting, can amplify temporal drift and loss of fidelity.
- Hardware/software co-design is essential: Algorithmic gains must translate into kernel and bandwidth efficiency to realize end-to-end speedup.
- Real-time and long-horizon generation pushes error-control and memory-scaling requirements to the forefront—the shift to streaming/infinitely-long contexts exposes new systems failure modes.
The paper also speculates on future acceleration frontiers, including the integration of sparse mixture-of-experts backbones, explicit error-budget-based optimization of composite methods, and open, acceleration-oriented data infrastructure as crucial enablers.
Conclusion
"Efficient Video Diffusion Models: Advancements and Challenges" (2604.15911) provides a unified technical survey and analytic foundation for video diffusion acceleration, clarifying the trade-offs and convergence points across step distillation, efficient attention, model compression, and cache/trajectory optimization. Progress in this field will require not only algorithmic advances but a systems view—jointly balancing speed, fidelity, temporal consistency, and hardware realization. As the ecosystem moves towards real-time, long-form video generation and deployable models, the research roadmap outlined by this work is set to influence both method development and architectural co-design for efficient, reliable, and scalable VDMs.

