- The paper introduces diffusion caching that reuses intermediate computations to reduce redundant processing and accelerate generation.
- It categorizes methods into static and dynamic caching, detailing adaptive techniques like timestep and layer-specific caching.
- The study highlights practical implications for real-time inference in multi-modal applications and efficient resource utilization.
A Survey on Cache Methods in Diffusion Models: Toward Efficient Multi-Modal Generation
Introduction
The paper "A Survey on Cache Methods in Diffusion Models: Toward Efficient Multi-Modal Generation" (2510.19755) addresses the computational bottleneck faced by Diffusion Models (DMs), which have become essential in generative AI due to their high quality and controllability in generating images and videos. Despite their proficiency, their multi-step iterative nature and complex architecture result in significant computational demands and latency, especially prohibitive in real-time applications. Current acceleration methods, while helpful, fall short due to their limited applicability, expensive training demands, or impacts on generation performance.
To circumvent these issues, the paper explores Diffusion Caching as a novel, architecture-agnostic, training-free acceleration method. This approach identifies and leverages computational redundancies during inference, reducing the computational load by reusing computations across steps, thus accelerating the process without parameter modifications. The survey provides a taxonomy and analysis of Diffusion Caching techniques, articulating their evolution from static to dynamic and potentially predictive methods, thereby suggesting an improved theoretical and practical framework for future advancement in multimodal generative AI.
Challenges and Motivation
Diffusion Models suffer from extended generation latency, a critical barrier against real-time deployment. Their computational model, involving step-by-step denoising through dense networks like U-Net and DiT, results in significant time costs that increase linearly or exponentially with image resolution and sequence lengths. Traditional acceleration efforts focus on either step reduction via numerical solvers and distillation or per-step computational cost reduction using model compression or system-level optimizations. These strategies generally struggle to balance between reducing computational demand and preserving generation quality.
Against this backdrop, the motivation behind Diffusion Caching as an acceleration paradigm centers around reducing redundant computation inherent in the iterative process. By caching and reusing intermediate activations whose changes are often minimal between closely spaced timesteps, computational efficiency can be significantly enhanced without re-training or reconfiguring model parameters. This makes Diffusion Caching an attractive solution offering orthogonality and composability with existing techniques, allowing combined acceleration effects without compromising generation quality.
Taxonomy of Diffusion Caching Methods
Diffusion Caching strategies are categorized into static and dynamic paradigms. Static caching methods rely on predetermined caching at fixed intervals or specific layers regardless of the input data and process changes. Techniques such as DeepCache and FasterDiffusion excel by caching layer outputs with minimal temporal variation to reduce redundant calculation.
On the other hand, dynamic caching methods adaptively decide when to compute or cache based on real-time assessment of computation needs. These methods include Timestep-Adaptive Caching, Layer-Adaptive Caching, and Predictive Caching. For instance, TeaCache dynamically adjusts caching intervals by evaluating relative changes in outputs between timesteps. LazyDiT employs learned mechanisms to decide caching influenced by layer behavior.
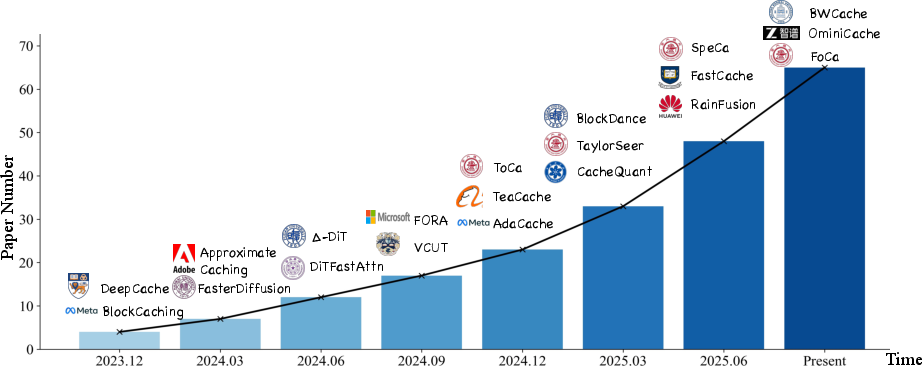
Figure 1: The development trend of Diffusion Caching The line chart illustrates the rapid growth in the number of related works from 2024 to the present. Representative works from each period are highlighted.
Applications and Implications
Diffusion Caching methods hold implications for both theoretical advances and practical implementations. They provide pathways for constructing an efficient generative inference framework key to multimodal and interactive applications. The caching techniques allow for integration with sampling optimization and model distillation, offering a robust strategy for improving system performance across computational environments. Furthermore, they set the stage for more seamless deployment in computationally constrained settings such as edge devices, opening up possibilities for real-time AI applications previously hindered by diffusion model inefficiencies.
The implementation of Diffusion Caching in industry settings could streamline computational resources, minimize latency, and catalyze the development of more responsive AI systems. This applicability is particularly relevant as demand grows for real-time interaction capabilities in augmented reality, gaming, and other digital media contexts.
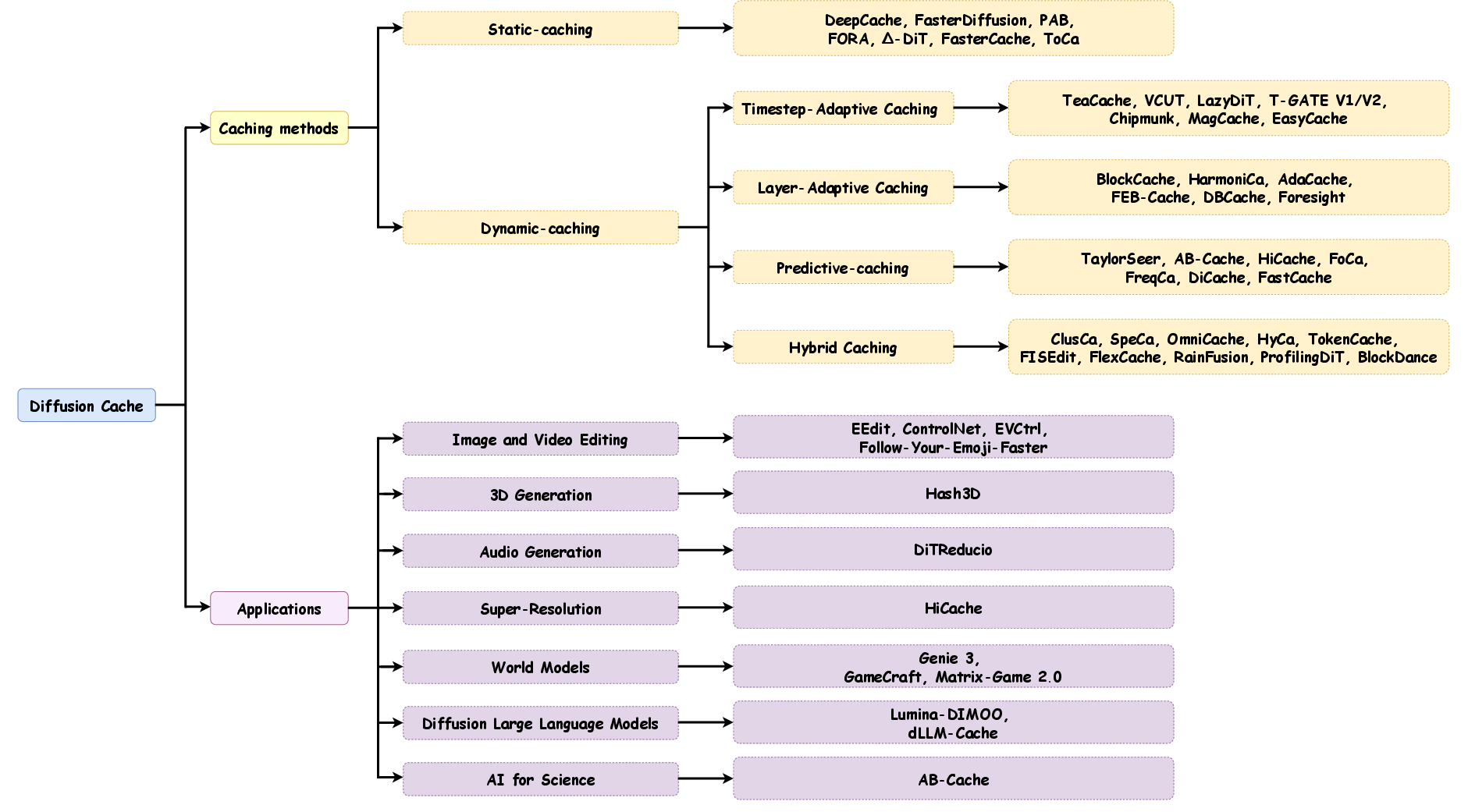
Figure 2: Overview of Diffusion Cache Framework The upper panel illustrates our unified taxonomy that categorizes caching methods into Static and Dynamic paradigms, with Dynamic Caching further divided into Timestep-Adaptive, Layer-Adaptive, Predictive, and Hybrid strategies. The lower panel shows applications across diverse generative tasks.
Conclusion
The surveyed paper provides a comprehensive look into the potential of Diffusion Caching as a powerful means to address computational overhead in generative models, broadening future perspectives in the field. As computational demands continue to rise with more complex AI systems, the efficient reuse of computations will be fundamental in achieving real-time performance and enabling large-scale practical implementations. Ultimately, Diffusion Caching may represent a cornerstone for the ongoing evolution toward efficient generative intelligence in AI.