TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Abstract: We introduce TurboDiffusion, a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200x while maintaining video quality. TurboDiffusion mainly relies on several components for acceleration: (1) Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation. (2) Step distillation: TurboDiffusion adopts rCM for efficient step distillation. (3) W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model. In addition, TurboDiffusion incorporates several other engineering optimizations. We conduct experiments on the Wan2.2-I2V-14B-720P, Wan2.1-T2V-1.3B-480P, Wan2.1-T2V-14B-720P, and Wan2.1-T2V-14B-480P models. Experimental results show that TurboDiffusion achieves 100-200x speedup for video generation even on a single RTX 5090 GPU, while maintaining comparable video quality. The GitHub repository, which includes model checkpoints and easy-to-use code, is available at https://github.com/thu-ml/TurboDiffusion.












Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces TurboDiffusion, a way to make AI video generators run much faster—about 100 to 200 times faster—without making the videos look worse. It focuses on speeding up “diffusion models,” which are popular AI systems that create images and videos step by step from random noise.
Objectives
The researchers wanted to:
- Make video generation super fast on one GPU (like an RTX 5090).
- Keep video quality close to the original model’s quality.
- Create a practical toolkit (with code and trained models) that others can use.
Methods and Approach
To understand the approach, it helps to know what a diffusion model does. Imagine starting with a very blurry video and “polishing” it a little at a time until it looks clear. That polishing happens in many small steps (often 50–100 or more). Each step uses big math operations, especially “attention” (which helps the model focus on the most important parts of the video) and “linear layers” (large matrix multiplications).
TurboDiffusion speeds things up by improving three major parts and tweaking a few others. Think of it like tuning a race car: lighter parts, smarter driving, and better fuel.
Here are the main techniques they used, explained with everyday analogies:
- Attention acceleration
- SageAttention (low-bit attention): Instead of always using big, precise numbers, it uses smaller 8-bit numbers where possible. This is like storing photos at a lower file size without noticeable quality loss—faster to load and process.
- Sparse-Linear Attention (SLA): Rather than looking at everything, the model focuses only on the most important parts (“Top-K”). It’s like skimming the most relevant paragraphs instead of reading the entire book. This reduces the amount of work the model does.
- Step distillation (rCM)
- Distillation teaches a “student” model to do in just a few steps what a “teacher” model does in many steps. Imagine learning shortcuts from an expert so you can finish a task in 3–4 steps instead of 100. The rCM method is a state-of-the-art way to do this well without losing quality.
- W8A8 quantization (8-bit weights and activations)
- Quantization shrinks the size of the numbers the model uses from bigger ones to 8-bit integers (INT8). It’s like packing items in smaller boxes so you can carry more and move faster. This speeds up the “linear layers” and also makes the model about half the size.
- Other engineering optimizations
- The team rewrote some parts (like LayerNorm and RMSNorm) in fast GPU languages (CUDA/Triton) to squeeze out extra speed.
Training and Inference
- Training (preparation):
- Replace full attention with SLA and finetune the original model so it learns to work with sparsity.
- At the same time, train a distilled “student” model using rCM so it can generate good videos in only 3–4 steps.
- Merge the improvements from both training processes into one model. This can use either real or synthetic (AI-made) data.
- Inference (actually making videos):
- Use a fast GPU implementation of the sparse attention (SageSLA).
- Cut the number of steps from ~100 down to 3 or 4.
- Run linear layers with INT8 numbers on special GPU hardware (“Tensor Cores”) for a big speed boost.
- Use efficient GPU implementations for other operations.
Main Findings
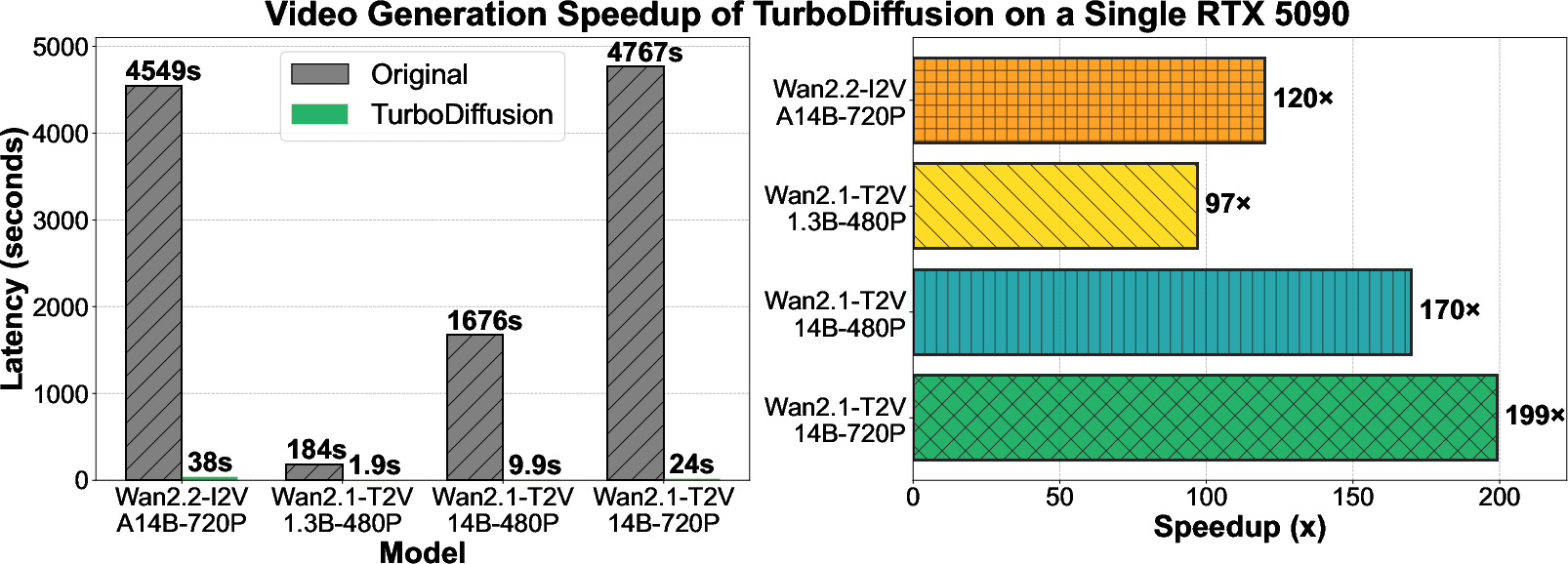
TurboDiffusion achieved very large speedups while keeping video quality comparable to the original models:
- On a single RTX 5090:
- A 5-second video with a medium-size model (Wan2.1-T2V-1.3B at 480p) dropped from about 184 seconds to about 1.9 seconds.
- A 5-second video with a very large model (Wan2.2-I2V-A14B at 720p) dropped from about 4549 seconds to about 38 seconds.
- Overall, this is roughly a 100–200× speedup.
- Compared to another fast method (FastVideo), TurboDiffusion was both faster and kept quality as good or better in visual comparisons.
These results come from combining smarter algorithms (like sparse attention and step distillation) with system-level optimizations (like INT8 quantization and GPU-specific code).
Why This Matters
- Faster generation means creators can experiment more, iterate quickly, and spend less money and energy.
- It opens the door to near real-time video generation, which could help in areas like:
- Content creation and editing
- Game development and interactive media
- Education, design, and animation
- Making high-quality video generation efficient on one GPU lowers the barrier to entry—more people can use these tools without huge computing resources.
Conclusion and Impact
TurboDiffusion shows that you can dramatically speed up video diffusion models—100 to 200 times faster—without hurting quality, by combining:
- Smarter attention (only looking at the most important parts),
- Fewer, better steps (distillation),
- Smaller, faster numbers (8-bit quantization),
- And optimized GPU code.
This approach could influence future research and commercial tools for video, images, and even other media generated by diffusion models. It makes advanced AI video generation more practical, cheaper, and more accessible for everyone.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address:
- Quantitative quality evaluation is missing: no FVD/FVD-k, LPIPS, CLIP-based metrics, temporal consistency (e.g., tLPIPS), or human preference studies to substantiate “maintaining video quality.”
- Absence of a systematic failure analysis: no documented cases where sparse attention, low-bit attention, or W8A8 quantization degrades quality (e.g., flicker, motion jitter, fine textures, faces, text legibility).
- Limited resolution and duration scope: evaluations focus on 480p/720p and ~5-second clips; impact on 1080p/4K, higher frame rates, longer videos (30–120s+), and wide aspect ratios is unexplored.
- Generalization across model families: results are only on Wan-series video diffusion models; applicability to other architectures (e.g., Stable Video Diffusion, SVD-XT, Gen-3, 3D U-Nets with different attention layouts) is untested.
- End-to-end latency exclusion: reported speedups exclude text encoding and VAE decoding; the overall user-perceived latency and potential bottlenecks in these stages remain unquantified and unoptimized.
- Hardware portability and reproducibility: speedups are primarily on RTX 5090; quantitative results on H100, 4090, A100, consumer laptops, mobile/edge devices (Apple, AMD, Intel ARC) and CPU-only environments are missing.
- Batch-size and throughput trade-offs: no analysis of how speedups scale with batch size, concurrent requests, or multi-stream inference in production settings.
- Multi-GPU scaling: the paper lacks evaluation of data/model parallelism, pipeline parallel strategies, and interconnect-induced overheads for larger batch or higher-resolution generation.
- Energy efficiency and cost: power consumption, energy-per-video, and cost-per-video are not reported; efficiency trade-offs across hardware are unclear.
- rCM step-distillation details: training recipe (losses, schedules, teacher-student setup, noise schedules), compute cost, convergence behavior, and robustness across prompts/domains are unspecified.
- Parameter merge methodology: how SLA finetuning updates and rCM distillation weights are merged (e.g., weighted averaging, layer-wise merges) and potential conflicts/instabilities are not described or ablated.
- Adaptive sparsity policies: Top-K is fixed (0.1–0.15); there is no investigation of layer-wise, head-wise, or time-step-adaptive sparsity schedules and their impact on quality/speed.
- Attention sparsity sensitivity: no sensitivity analyses relating sparsity to different prompt types (complex compositional scenes, camera motion, multi-object interactions) or sequence lengths.
- SageSLA vs SLA parity: the numerical and qualitative equivalence between training-time SLA and inference-time SageSLA kernels is not validated; potential kernel-induced drift is unexamined.
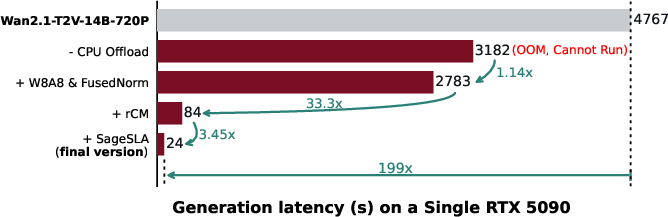
- Component-wise ablation: while a decomposition figure is shown, there is no detailed quantitative breakdown of each component’s contribution (SageAttention, SLA, rCM, W8A8, Triton/CUDA norms) on latency and quality.
- Quantization scope and strategy: only Linear layers are W8A8; effects of quantizing attention projections, convolutions, residual blocks, or cross-attention are not studied; layer-wise granularity or mixed-precision policies remain open.
- Post-training vs QAT: the paper does not clarify whether quantization-aware training or calibration is used; robustness of INT8 activation quantization under diverse content and long sequences is unknown.
- Block size choice: the rationale and sensitivity for the 128×128 block-wise granularity in INT8 quantization (per-layer/per-head optimality, small-layer behavior) is not evaluated.
- Temporal consistency under acceleration: explicit temporal metrics (e.g., optical flow consistency, temporal FVD) are missing; impact of 3–4 step sampling on motion coherence is unquantified.
- I2V dual-model overhead: the switching overhead between high-noise and low-noise models is acknowledged but not mitigated; techniques to unify or amortize the switch are not explored.
- Robustness to domain shifts: training claims to use real or synthetic data; there is no study of domain generalization (e.g., cartoons, low-light, fast action, egocentric footage).
- Prompt robustness and controllability: performance on complex prompts (camera paths, scene layout constraints, story consistency), and compatibility with control signals (ControlNet, keyframes) are untested.
- Personalization and adapters: compatibility and quality with LoRA, DreamBooth, or fine-tuned adapters under sparse/quantized attention and W8A8 linear layers is unknown.
- Determinism and stability: the effect of low-bit kernels and sparsity on output determinism across runs, driver versions, and kernel configurations is unreported.
- Integration with other samplers: interoperability with alternative fast samplers and distillation methods (e.g., progressive distillation, consistency models, FreeNoise) is not evaluated.
- VAE/decoder acceleration: no methods are proposed to speed up VAE decoding or video post-processing, despite their contribution to wall-clock time in practical pipelines.
- Memory footprint and capacity: VRAM savings and maximum video length/resolution achievable due to quantization are not quantified; memory fragmentation and allocator behavior with custom kernels are unaddressed.
- Safety and robustness: no analysis of adversarial or pathological prompts that may exacerbate artifacts under sparse/low-bit attention; mitigation strategies are absent.
- Licensing and model access constraints: practical reproducibility is unclear if Wan checkpoints or required assets are restricted; portability of TurboDiffusion to open-weight models is not demonstrated.
Practical Applications
Immediate Applications
Below is a concise set of practical use cases that can be deployed now, grounded in TurboDiffusion’s demonstrated 100–200× end-to-end speedup and maintained video quality on supported models and NVIDIA GPUs.
- Drop-in acceleration for existing text-to-video and image-to-video pipelines (media/entertainment, software)
- What: Replace baseline Wan2.x inference with TurboDiffusion to cut latency from minutes/hours to seconds (e.g., ~184s → ~1.9s for 480p, ~4549s → ~38s for 720p).
- Tools/workflows: Use the GitHub repo, SageSLA kernels, rCM-distilled checkpoints, W8A8 INT8 deployment; tune Top-K in [0.1, 0.15], steps in [3, 4].
- Assumptions/dependencies: NVIDIA RTX 5090/4090/H100 or similar with INT8 Tensor Cores; CUDA/Triton compatibility; availability and licensing of Wan model variants; acceptable quality at reduced steps.
- Real-time creative prototyping inside DCCs and game engines (advertising, film, gaming)
- What: Rapid iteration on storyboards, previz, mood reels, cutscenes, and in-engine generated assets.
- Tools/workflows: Plugins/extensions for Adobe After Effects/Premiere, Blender, Unreal Engine; local GPU inference on creator PCs.
- Assumptions/dependencies: Supported models and INT8 kernels; creators’ access to high-end NVIDIA GPUs; quality parity preserved for short clips.
- Cost-efficient cloud video generation services (cloud platforms, SaaS, media tech)
- What: Lower per-video cost and higher throughput for T2V/I2V APIs.
- Tools/workflows: Containerized inference (Kubernetes), autoscaling with quantized INT8 models, server-side scheduling for 3–4-step generation.
- Assumptions/dependencies: NVIDIA data center hardware; content moderation and watermarking pipelines; egress/storage optimization.
- Scalable e-commerce product video generation (retail/e-commerce)
- What: Batch creation of product demos, background variations, and localized promos from text prompts.
- Tools/workflows: Automated pipelines integrated with CMS/PIM; templated prompts; A/B testing at scale.
- Assumptions/dependencies: Brand safety and IP checks; style consistency; 480p/720p suffices for most channels; prompt libraries.
- Rapid internal training and safety materials (manufacturing, energy, logistics)
- What: Fast generation of procedural videos for SOPs, incident drills, and facility walkthroughs.
- Tools/workflows: Knowledge-base-to-video workflows; versioned prompt catalogs; review gates.
- Assumptions/dependencies: Non-technical staff-friendly UI; on-prem GPU or cloud; disclaimers on simulated content.
- Educational micro-animations for teaching (education)
- What: Quick visualizations for STEM topics, lab procedures, and concept explainers.
- Tools/workflows: LMS integration; instructors author prompts; library of reusable templates.
- Assumptions/dependencies: Institutional access to GPUs; accessibility accommodations; attribution/watermarking.
- Newsroom and social media b‑roll generation (journalism, marketing)
- What: Generate non-factual illustrative visuals for explainer pieces and social posts.
- Tools/workflows: Editorial review queue; prompt templates; watermarking rules.
- Assumptions/dependencies: Clear labeling of synthetic content; policy compliance; short-form video focus.
- Creator PC workflows (independent creators)
- What: Near-real-time local generation of short videos for channels and streams.
- Tools/workflows: Desktop apps using TurboDiffusion; prompt iteration loops; style presets.
- Assumptions/dependencies: Consumer GPUs (4090/5090); content policies of target platforms.
- Synthetic data augmentation for CV tasks (research/industry R&D, robotics)
- What: Generate stylized motion clips for robustness testing, background variations, or domain randomization (non-physics-critical).
- Tools/workflows: Data pipeline integrations; label-transfer or weak supervision; short clip synthesis at scale.
- Assumptions/dependencies: Labels may need separate generation; domain gap considerations; clip length limits.
- Academic experimentation and method development (academia)
- What: Faster ablations for attention sparsity, quantization, and distillation with open-source code and kernels.
- Tools/workflows: Reproducible pipelines using SageAttention2++, SLA, rCM, W8A8; porting to other video diffusion backbones.
- Assumptions/dependencies: Availability of training and inference scripts; compute to finetune/merge updates; appropriate datasets.
- Platform-level “TurboDiffusion inference engine” (software tooling)
- What: A reusable runtime library for accelerated video diffusion in existing ML stacks.
- Tools/workflows: Integration with NVIDIA Triton Inference Server or custom CUDA/Triton kernels; API endpoints for batch/real-time.
- Assumptions/dependencies: Vendor-locked to CUDA/Tensor Cores; ROCm/Metal ports not yet available; ops like LayerNorm/RMSNorm reimplemented.
Long-Term Applications
These opportunities require additional research, engineering, or ecosystem development (e.g., hardware portability, longer-form quality, regulatory guardrails).
- Mobile/edge deployment of video diffusion (consumer devices, telecom)
- What: On-device T2V/I2V generation on smartphones, AR/VR headsets, or set-top boxes.
- Tools/workflows: Model pruning/4-bit quantization, ONNX/Vulkan/Metal/NNAPI paths, NPU acceleration.
- Assumptions/dependencies: Porting SageSLA/INT8 kernels beyond CUDA; thermal/battery constraints; smaller model variants.
- Live generative video for broadcasts and streams (media, creator economy)
- What: Dynamic scenes/avatars rendered at interactive rates (e.g., 15–30 fps) during live content.
- Tools/workflows: Pipeline optimization including text encoding and VAE decoding; streaming-friendly batching; latency budgeting.
- Assumptions/dependencies: Further speedups in non-diffusion stages; quality stability under sustained generation; hardware scaling.
- 4K/long-form production video workflows (film/TV, advertising)
- What: High-resolution, minutes-long sequences with consistent characters, camera continuity, and narrative coherence.
- Tools/workflows: Hierarchical generation, temporal consistency modules, memory-optimized multi-GPU inference.
- Assumptions/dependencies: Additional research on long-horizon temporal fidelity; increased VRAM needs; robust editing controls.
- Cross-hardware and cross-framework support (software infrastructure)
- What: AMD/ROCm, Apple/Metal, and CPU/NPU support; broader integration into Diffusers and enterprise stacks.
- Tools/workflows: Kernel rewrites for non-CUDA backends; standardized INT8/low-bit APIs; CI for multi-vendor testing.
- Assumptions/dependencies: Vendor cooperation; performance parity; community maintenance.
- Personalized, on-the-fly ad creatives at scale (marketing/advertising)
- What: Real-time video targeting per user context (location, behavior, language).
- Tools/workflows: Privacy-preserving user modeling, prompt orchestration, policy-compliant content generation.
- Assumptions/dependencies: Consent and privacy safeguards; content safety filters; robust A/B measurement pipelines.
- Large-scale synthetic data engines for robotics/autonomous driving (robotics, automotive)
- What: Photorealistic sequences with accurate dynamics, sensor models, and annotations to train perception stacks.
- Tools/workflows: Simulator coupling (physics engines), ground-truth generation, domain adaptation.
- Assumptions/dependencies: Bridging domain gap; reliable labeling; regulatory acceptance for data provenance.
- Regulatory guardrails and watermarking standards (policy/governance)
- What: Enforcement mechanisms to label, trace, and moderate AI-generated videos at scale.
- Tools/workflows: Standardized watermarking, provenance metadata, audit logs, rate-limiting and content filters.
- Assumptions/dependencies: Industry and platform adoption; legal frameworks; alignment with international standards.
- Distillation-as-a-service for proprietary video models (enterprise ML)
- What: rCM-powered step distillation pipelines tailored to internal models to reduce inference steps without quality loss.
- Tools/workflows: Managed training services, weight merging workflows, validation suites.
- Assumptions/dependencies: Access to proprietary weights/data; QA for prompt-specific quality; compute for finetuning.
- Eco-efficiency and carbon-aware scheduling (energy/sustainability)
- What: Lower energy per video through quantization and sparsity; schedule jobs to green energy windows.
- Tools/workflows: Emissions tracking, energy-aware orchestrators, model compression beyond INT8 (e.g., 4-bit).
- Assumptions/dependencies: Accurate energy metering; infrastructure support; acceptable quality under deeper compression.
- Multimodal education pipelines (education, accessibility)
- What: Text → video → captions → TTS → localized variants generated on demand.
- Tools/workflows: Orchestration across generative modalities; compliance with accessibility standards; teacher-in-the-loop review.
- Assumptions/dependencies: Integration effort; quality guardrails across languages; content review processes.
- Continuous scene generation for games and virtual worlds (gaming)
- What: Procedural video events and cinematics driven by player state or AI directors.
- Tools/workflows: In-engine scheduling, asset caching, temporal stability modules, multi-GPU streaming.
- Assumptions/dependencies: Robustness under gameplay variability; consistent style/character preservation; engine integration.
- Enterprise on-prem deployments in regulated sectors (finance, healthcare, government)
- What: Controlled, private inference of internally-approved models for training, communications, or patient education.
- Tools/workflows: Security-hardened runtimes, audit trails, content governance dashboards.
- Assumptions/dependencies: Compliance (HIPAA/GDPR/etc.); strict content policies; watermarked outputs; non-clinical use in healthcare.
Glossary
- Activations: Intermediate outputs produced by neural network layers; quantizing them reduces memory and compute. "TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model."
- Algorithm and system co-optimization: Jointly optimizing algorithmic methods and system/hardware implementations for performance. "By algorithm and system co-optimization, TurboDiffusion reduces the diffusion inference latency of Wan2.1-T2V-14B-720P by around 200 red{on a single RTX 5090.}"
- Attention acceleration: Techniques to speed up computation in the attention mechanism. "Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation."
- Attention sparsity: The proportion of attention weights pruned to zero, often controlled by a Top-K threshold. "We set the Top-K ratio to $0.1$, corresponding to attention sparsity, and use $3$ sampling steps."
- Block-wise quantization granularity: Applying quantization parameters per fixed-size block of the weight/activation matrix. "Specifically, the data type is INT8 and the quantization granularity is block-wise with a block size of ."
- CUDA: NVIDIA’s parallel computing platform and programming model for GPUs. "SageSLA, which is a CUDA implementation of SLA built on top of SageAttention."
- Diffusion distillation: Training methods that compress diffusion sampling into fewer steps while maintaining quality. "TurboDiffusion uses rCM to reduce the number of sampling steps, which is currently a state-of-the-art diffusion distillation method."
- End-to-end diffusion generation: The complete diffusion process from initial noise to the final output. "speed up end-to-end diffusion generation by while maintaining video quality."
- Finetune: Additional training of a pretrained model to adapt it to new properties or constraints. "finetune the pretrained model to adapt to sparsity."
- INT8: An 8-bit integer data type commonly used for quantized inference. "Specifically, the data type is INT8"
- LayerNorm: A normalization technique that normalizes activations across the features of a layer. "We reimplement several other operations, such as LayerNorm and RMSNorm, using Triton or CUDA for better efficiency."
- Linear layer quantization: Quantizing weights and activations of linear (fully connected) layers to reduce compute and memory. "Linear layer quantization."
- Model weights merging: Combining parameter updates from different training processes into one set of weights. "Through model weights merging, rCM naturally inherits attention-level accelerations."
- Orthogonal (sparse computation): Independent and non-conflicting with another optimization; can be combined for cumulative speedups. "Since sparse computation is orthogonal to low-bit Tensor Core acceleration, SLA can build on top of SageAttention to provide cumulative speedup."
- rCM: A step-distillation and weight-merging method used to reduce the number of diffusion sampling steps. "TurboDiffusion uses rCM to reduce the number of sampling steps, which is currently a state-of-the-art diffusion distillation method."
- RMSNorm: Root Mean Square Normalization; an alternative to LayerNorm with different normalization statistics. "We reimplement several other operations, such as LayerNorm and RMSNorm, using Triton or CUDA for better efficiency."
- SageAttention: A low-bit quantized attention method that accelerates attention computation. "TurboDiffusion uses SageAttention~\cite{zhang2025sageattention,zhang2024sageattention2,zhang2025sageattention2++,zhang2025sageattention3} for low-bit quantized attention acceleration;"
- SageAttention2++: A specific variant of SageAttention used in this work. "specifically, TurboDiffusion uses the SageAttention2++~\cite{zhang2025sageattention2++} variant."
- SageSLA: A CUDA-based implementation of SLA that builds on SageAttention for faster inference. "We replace SLA with SageSLA, which is a CUDA implementation of SLA built on top of SageAttention."
- Sampling steps: The number of iterative denoising steps in diffusion sampling; fewer steps mean faster generation. "We reduce the number of sampling steps from 100 to a much smaller value, e.g., $4$ or $3$."
- Sparse-Linear Attention (SLA): An attention mechanism that enforces sparsity and enables more efficient, near-linear computation. "TurboDiffusion uses Sparse-Linear Attention (SLA)~\cite{zhang2025sla} for sparse attention acceleration."
- Tensor Cores: Specialized GPU units for fast matrix operations, leveraged for quantized INT8 compute. "use INT8 Tensor Cores to perform the Linear layer computation."
- Top-K ratio: The fraction of highest-scoring attention entries retained to control sparsity. "We set the Top-K ratio to $0.1$, corresponding to attention sparsity, and use $3$ sampling steps."
- Triton: A GPU kernel programming language/compiler used to implement efficient custom operations. "using Triton or CUDA for better efficiency."
- VAE decoding: The stage that decodes latents back to pixels using a Variational Autoencoder. "excluding the text encoding and VAE decoding stages."
- W8A8 quantization: A quantization scheme where weights (W) and activations (A) are both 8-bit. "W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model."
Collections
Sign up for free to add this paper to one or more collections.