- The paper outlines the evolution of video generative models, transitioning from GANs to robust diffusion and autoregressive frameworks.
- It details methodological advances such as UNet backbones, tokenized AR approaches, and multimodal integration that enhance stability and visual fidelity.
- The review benchmarks current models on semantic alignment and temporal consistency, offering strategic insights for future video simulation and AGI research.
Evolution of Video Generative Foundations: An Expert Analysis
Introduction: Scope and Motivation
The rapid development of Artificial Intelligence Generated Content (AIGC) has fundamentally restructured the field of video generation, progressing from implicit adversarial models (GANs) toward explicit likelihood-based frameworks (Diffusion and Auto-Regressive Models) and, most recently, multimodal integration. The surveyed paper "Evolution of Video Generative Foundations" (2604.06339) provides a comprehensive and systematic review tracking this progression, emphasizing foundational methodology, comparative strengths and limitations, and the emerging fusion of modalities for next-generation video synthesis.
Paradigmatic Transitions in Video Generation
GANs, Diffusion, and Auto-Regressive Models: Principles and Shifts
The generative modeling landscape for video has evolved via three central paradigms. Initially, video GANs operated by implicitly minimizing divergence between model and data distributions through adversarial training—an approach marked by instability, mode collapse, and limited scalability for high-fidelity or open-domain scenarios. Diffusion models introduced explicit density estimation, leveraging score-matching and iterative denoising to surpass GANs in training stability and visual fidelity, albeit at increased computational costs. The trajectory further moves toward auto-regressive (AR) models, which factor video likelihood directly through the chain rule, supporting tractable exact maximum likelihood training and natural compatibility with LLMs.
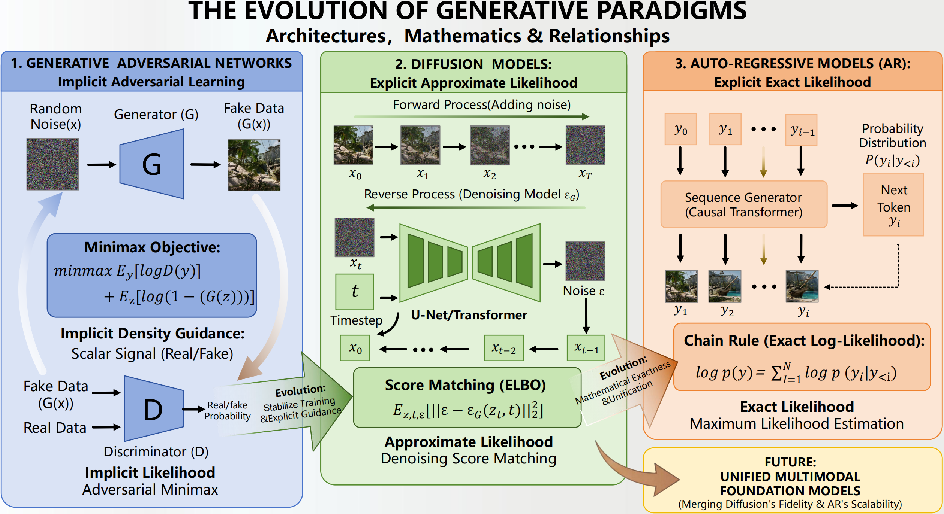
Figure 1: The evolution of generative paradigms in video generation, illustrating the shift from implicit adversarial learning (GANs) to explicit density estimation via denoising (Diffusion) and next-token prediction (Auto-Regressive).
AR-based approaches, particularly those using tokenized representations (e.g., VQ-VAE in VideoGPT and hybrid LLM frameworks), offer a unifying path for scalable, multimodal video modeling but contend with an information bottleneck and lower visual resolution compared to richer continuous latent spaces of diffusion models.
Statistical Dynamics and Community Trends
Analysis of top-tier conference literature from 2018 to 2025 reveals that GANs peaked around 2022, undergoing a rapid phase-out as diffusion models rose to dominance. The consolidation around diffusion models has coincided with a shift in research focus from motion and temporal consistency to compositionality, world modeling, physical simulation, and unified multimodal control.
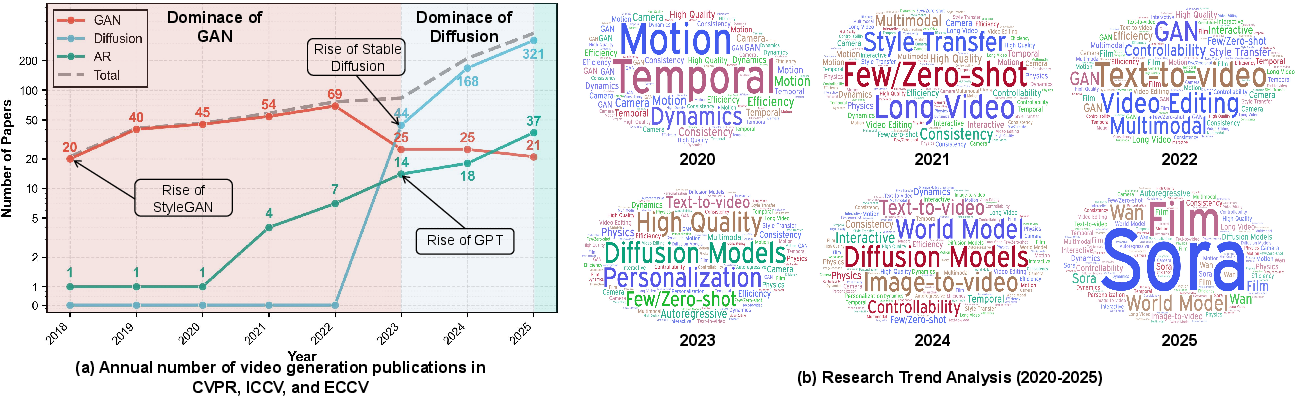
Figure 2: The trending of video generation models in the top-tier conferences, demonstrating the paradigm transition and the evolving focus of research topics.
Architectural and Algorithmic Diversification
Design Choices in Diffusion Video Models
Current diffusion-based video architectures are characterized by several lines of innovation: (1) UNet backbones with enhanced temporal modules (e.g., cascade models, cross-frame attention, LDM extensions), (2) scalable Diffusion Transformers (DiT) incorporating efficient spatio-temporal factorization, and (3) hybrid or streaming AR-diffusion variants bridging inference latency and train-test exposure gaps.
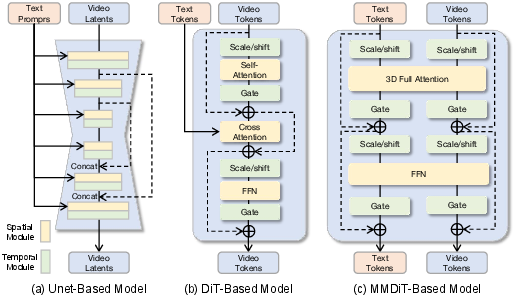
Figure 3: Comparison between different model structures for diffusion models, representing the diversity in architectural innovation.
Distillation and consistency regularization have produced one-step or few-step generators, considerably bridging the efficiency gap relative to GANs. Progressive training schemas, advanced spatio-temporal VAEs, and linear-attention modules (e.g., Mamba, RWKV) are now essential for mitigating quadratic complexity and supporting high-resolution synthesis.
Multimodal and Unified Video Generation
Parallel to backbone advances, the field is converging on tightly coupled multimodal systems. LLMs now routinely serve as high-level planners, decomposing abstract instructions or textual narratives into temporally and contextually aligned scene descriptors. Unified token models and hybrid AR-diffusion frameworks align pixel-level synthesis with semantic reasoning and instruction-following capabilities. These architectural trends anticipate robust compositionality, long-context reasoning, and flexible user control.
Benchmarks and Empirical Evaluation
Robust evaluation of generative video models has expanded across several axes: foundational spatial-temporal fidelity, semantic/prompt alignment, physical and logical consistency, safety and responsible AI, and narrative coherence. Foundational models such as Veo 3 and Sora exhibit high semantic alignment and aesthetic quality, with near-saturating scores on standard prompt-based metrics. However, on advanced benchmarks oriented toward physical plausibility, commonsense reasoning, and narrative length (e.g., VideoPhy-2), open and closed-source models still demonstrate substantial limitations, particularly for causal physical reasoning and nuanced long-range dependencies.
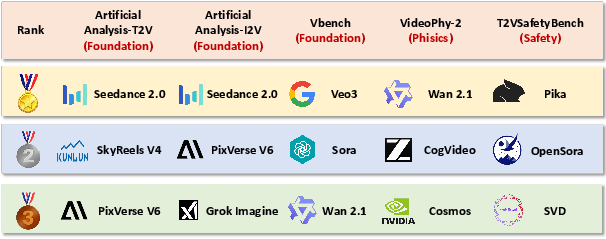
Figure 4: Benchmarks of video generation model, illustrating the multidimensional evaluation landscape the community now embraces.
Downstream Controllability and Application Axes
The utility of generative video models extends beyond unconditional synthesis to a taxonomy of controllable generation tasks:
- Video Customization: Subject- or identity-preserving generation based on user references, including both instance-specific and end-to-end solutions.
- Motion Control: Disentangled and explicit control of object and camera dynamics, leveraging trajectory, mask, and motion vector guidance.
- Video Editing: Text- or image-guided editing, encompassing both frame-propagated and holistic structural modifications, with increasing attention to multi-modal instruction following and disentangled representations.
- World Modeling: Emergent systems capable of persistent state, causal simulation, and agentive interaction—addressing the "hallucinatory amnesia" of traditional models via implicit or explicit memory modules, 3D/4D geometry integration, and physically grounded planning.

Figure 5: The downstream video generation tasks can be primarily classified into 4 groups according to the modality and granularity of user control, which are video editing (a), video customization (b), motion control (c), and world model (d).
Strategic Model Training and Efficiency
A salient contribution of the paper is its analysis of resource requirements and best-practices for training foundation video models. Approaches are distinguished as follows: industrial-scale brute-force training with exascale data (e.g., NVIDIA Cosmos), research-targeted balanced optimization (e.g., Seaweed-7B), and highly curated commercial pipelines (e.g., Open-Sora 2.0, CogVideoX) that maximize quality/computation ratios. Key technical recommendations include hierarchical data filtering, aggressive spatio-temporal compression (causal 3D VAEs), and progressive mixed-resolution schedules.
Implications, Theoretical Impact, and Future Directions
AGI and the "World Model" Hypothesis
The survey asserts that the ultimate ambition for generative video models—true "world simulators"—remains elusive. Current systems excel as short-clip generators but are fundamentally limited by catastrophic forgetting, semantic drift, computational bottlenecks, and a lack of intrinsic physical modeling. Theoretical progress toward AGI will require:
- Long-Horizon Consistency: Memory-augmented, hierarchical, or AR-Diffusion hybrid frameworks to maintain identity, narrative, and causal coherence.
- Real-Time and High-Resolution Generation: Single/few-step inference (consistency distillation, flow matching) and efficient large-scale distributed architectures.
- Physics-Awareness and 3D Consistency: Integration of synthetic/embodied data, explicit 3D representations, and reward-based or LLM-driven physical reasoning.
- Data-Centric and Omni-Modal Integration: Scaling to high-quality synthetic data, holistic interleaved training, and seamless vision/audio/text fusion.
Conclusion
The paper presents a rigorous synthesis of the foundational, algorithmic, and evaluative state of video generative modeling. By systematically bridging GANs, diffusion, AR models, and multimodal architectures, it clarifies the hierarchy of methods now available and articulates both the computational limits and scientific challenges that remain. The implications for practical content generation, simulation, interactive media, and ultimately the realization of AI world models are immediate. The paper's discussion of benchmarks and downstream applications, combined with its strategic guide for model development, provides a valuable foundation for future research aimed at closing the gap between short-clip generation and causal, embodied simulation.