- The paper introduces EVIL, an LLM-driven evolutionary pipeline that evolves interpretable, zero-shot Python/NumPy heuristics for dynamical systems inference.
- It demonstrates competitive accuracy and speed, outperforming neural models on tasks such as event prediction, rate estimation, and time series imputation.
- Evolved algorithms are transparent and data-efficient, enabling rapid deployment and scientific auditability without dataset-specific retraining.
LLM-Guided Evolution of Interpretable Algorithms for Zero-Shot Inference on Event Sequences and Time Series
Introduction
The paper "EVIL: Evolving Interpretable Algorithms for Zero-Shot Inference on Event Sequences and Time Series with LLMs" (2604.15787) proposes EVIL, an LLM-guided evolutionary pipeline for discovering interpretable, zero-shot inference algorithms for dynamical systems. EVIL leverages LLMs to guide evolutionary search over programs, yielding pure Python/NumPy heuristics per task. Unlike neural network-based approaches that require dataset-specific training, the evolved programs are designed to operate without retraining, generalizing across datasets and output dimensions within a task family.
This approach is demonstrated on three core inference tasks: prediction in marked temporal point processes (MTPPs), rate matrix estimation for Markov jump processes (MJPs), and time series imputation. The resulting algorithms are not only competitive with, and sometimes outperform, state-of-the-art neural baselines, but also provide orders-of-magnitude efficiency gains and full interpretability.
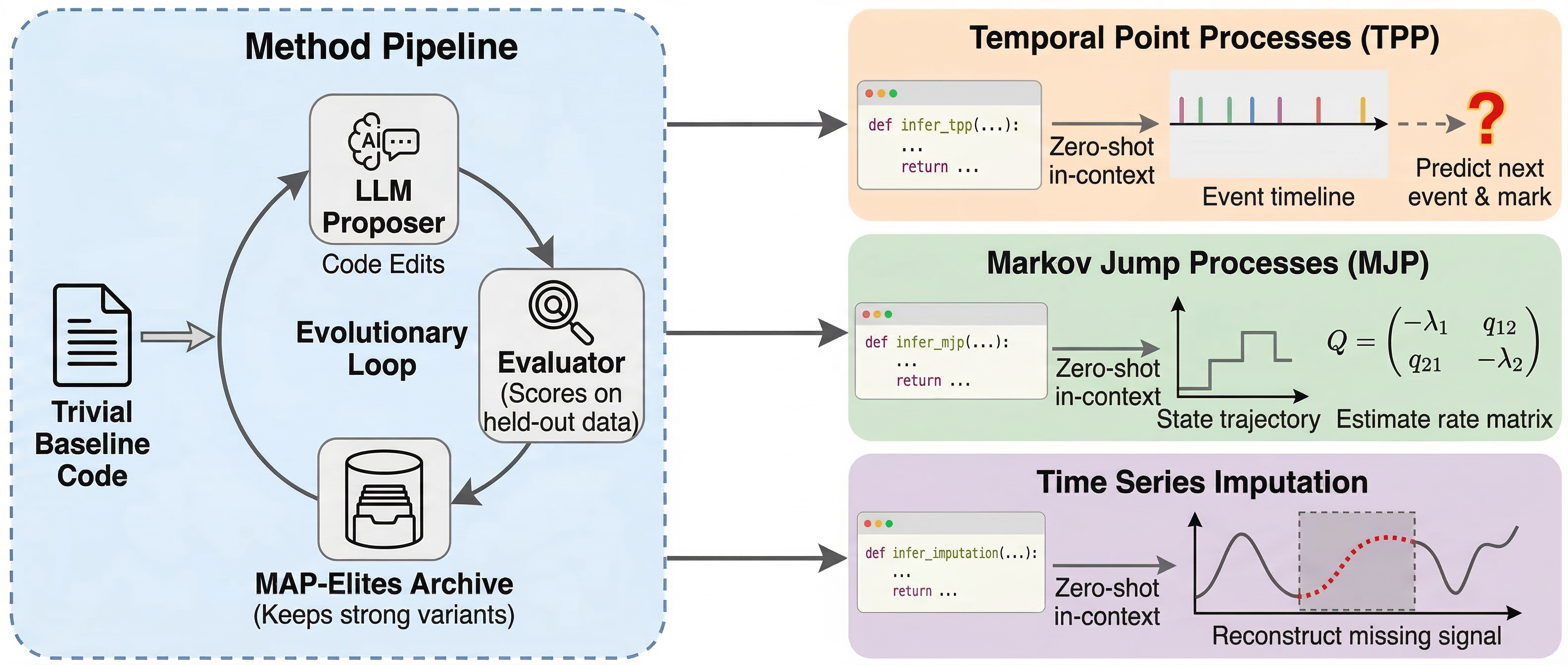
Figure 1: Overview of the EVIL approach. The same EVIL evolutionary procedure is applied separately to temporal point processes, Markov jump processes, and time series imputation, yielding one interpretable Python/NumPy inference function per task that generalizes across datasets in a zero-shot, in-context manner.
Methodology
EVIL employs LLM-driven program evolution (specifically, OpenEvolve/AlphaEvolve-style (2604.15787)) to discover compact, interpretable Python/NumPy routines for zero-shot amortized inference. Solutions are evolved to maximize a task-specific fitness function (e.g., prediction accuracy, log-likelihood, MAE), operating on minimal evaluation splits subsampled from benchmark datasets or on fully synthetic data priors.
Key methodological features:
- Evolutionary Search: An ensemble of LLMs proposes code changes; candidate programs are evaluated, and the search is organized via MAP-Elites with island-based populations for diversity.
- Strict Simplicity/Interpretability Constraints: Only Python/NumPy is allowed; no deep learning libraries, and the returned function must be short and fully readable.
- Zero-Shot Setting: There is no per-dataset finetuning; a single algorithm is discovered per task, meant to work out-of-the-box on any dataset or mark dimension within the problem class.
- Evaluation Protocol: For real datasets, only partial training splits are used for evolution, while the test set and full training data remain unseen. For "synthetic prior" baselines, all evolution is on synthetic data, evaluating transfer to real-world datasets.
Marked Temporal Point Processes
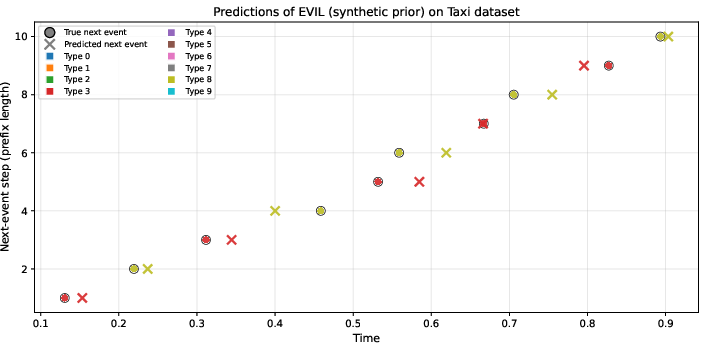
For MTPP next-event and long-horizon prediction, evolutionary search discovers algorithms that utilize context mark transition statistics and robust interval estimates. The heuristics combine recency-weighted inter-event gaps, mark-conditioned averages, and context-derived transition matrices. Notably, the discovered programs:
In contrast to deep neural models, the logic of the evolved solution can be directly inspected, typically blending local sequence statistics with context-level regularities via recency-weighting, smoothing, and explicit fallbacks for underrepresented transitions.
Markov Jump Processes
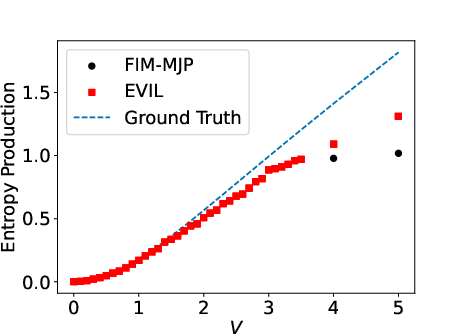
For continuous-time MJPs, EVIL evolves global estimators for the initial-state distribution and rate matrix from discretized, noisy observations. The inferred rate matrices are constructed through robust exposure and transition counting, with adaptive smoothing and exposure clipping for noise suppression.
Major observations:
Importantly, all rate estimation is transparent: the evolved logic for noise filtering, exposure reweighting, and rate assignment is human-auditable, facilitating scientific trust in applications.
Time Series Imputation
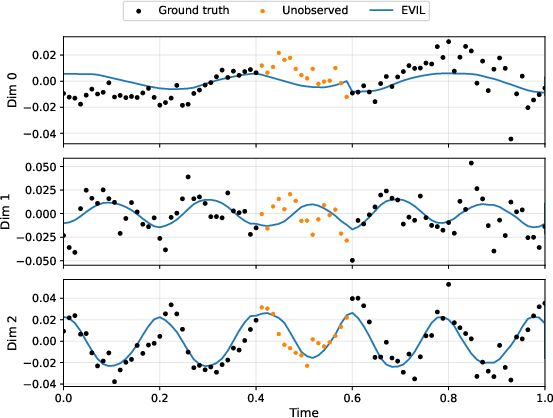
For multivariate time-series imputation, the evolved heuristics are hybrid, employing motif retrieval for large missing windows and linear interpolation for short, local gaps. The motif retrieval mechanism searches the series for recurring patterns with matching pre-gap context and pastes the continuation, applying a level shift to preserve continuity.
Performance characteristics:
Motif-based strategies have emerged in concurrent work, such as context parroting [zhang2026context], supporting the hypothesis that motif retrieval provides a strong inductive bias for imputation in dynamical systems.
Search Dynamics and Program Discovery
Extended evolutionary runs indicate that while the majority of validation test performance is obtained within 100 search iterations, continued evolution does find new, sometimes more complex programs. However, gains plateau quickly, and the simplicity bias persists: most highly performant solutions remain short and parsimonious, with little evidence that much larger or more intricate heuristics are necessary for benchmark-level performance.
Figure 5: Discovery trajectory of new best validation-set programs over an 800-iteration run, highlighting continuous algorithmic innovation.
Discussion and Implications
The core empirical finding is that LLM-guided program evolution can reliably discover compact, interpretable algorithms that rival or exceed the predictive performance of state-of-the-art neural models in zero-shot, in-context settings across multiple dynamical systems domains. The evolved solutions are generically applicable, highly data-efficient (often requiring only small synthetic or subsample-based evolution datasets), rapid to evaluate, and fully transparent.
The demonstration that such amortized inference procedures exist—and are discoverable by LLM-driven search—has theoretical implications for algorithmic induction and interpretable machine learning: it reinforces the Occam bias induced by program induction and suggests the prior encoded in pretrained LLMs is strong enough that effective heuristics for rich, history-dependent processes can be edited and audited directly.
Practically, EVIL can serve as a lightweight, trustworthy baseline for scientific, industrial, and medical domains where interpretability, speed, and cross-dataset transferability are paramount. For rapid prototyping, exploratory data analysis, or deployment on resource-constrained hardware, EVIL-discovered programs provide an alternative to expo-heavy, opaque neural architectures. For iterative scientific discovery, the transparency of the program space facilitates direct integration of domain knowledge and rapid modification.
Conclusion
This work validates that LLM-guided evolutionary search is a practical method for automated scientific heuristic discovery. By focusing the search on the space of transparent, parameter-free algorithms, EVIL achieves strong (and at times superior) zero-shot inference across diverse dynamical systems tasks with minimal data, compute, and engineering overhead. Future avenues include extending the framework to tasks that require explicit modeling of epistemic uncertainty, augmenting the search space with probabilistic constructs, and integrating richer forms of domain-specific prior knowledge through prompt engineering. The results prompt a reevaluation of when deep neural architectures are necessary and underscore the continuing value of interpretable, computable baselines for the modern AI pipeline.