- The paper introduces an LLM-guided framework that automatically evolves causal estimators through iterative program synthesis.
- The methodology employs ensemble mutation, MAP-Elites for diversity, and multi-objective fitness functions to optimize estimator performance.
- Empirical results demonstrate significant improvements in RMSE and PEHE over human-designed estimators across multiple benchmarks.
Automated Causal Effect Discovery with Self-Evolving LLM Agents: A Technical Analysis of "InferenceEvolve"
Introduction
This essay presents an in-depth analysis of "InferenceEvolve: Towards Automated Causal Effect Estimators through Self-Evolving AI" (2604.04274). The manuscript proposes a new automated framework for the end-to-end discovery, refinement, and deployment of causal effect estimators using evolutionary strategies orchestrated by LLMs. It systematically positions estimator selection, structure discovery, and evaluation as an open-ended program-synthesis challenge, leveraging LLMs not merely as static code generators but as active agents navigating high-dimensional, compositional causal estimation spaces.
The framework is benchmarked against canonical causal inference tasks, validating that LLM-guided estimator evolution consistently outperforms standard baseline implementations and human-submitted methods on rigorous, replicable benchmarks. This analysis delineates the algorithmic underpinnings, empirical results, method adaptations, and research implications of InferenceEvolve, situating it within the emerging literature on automated methodological search and agentic scientific discovery.
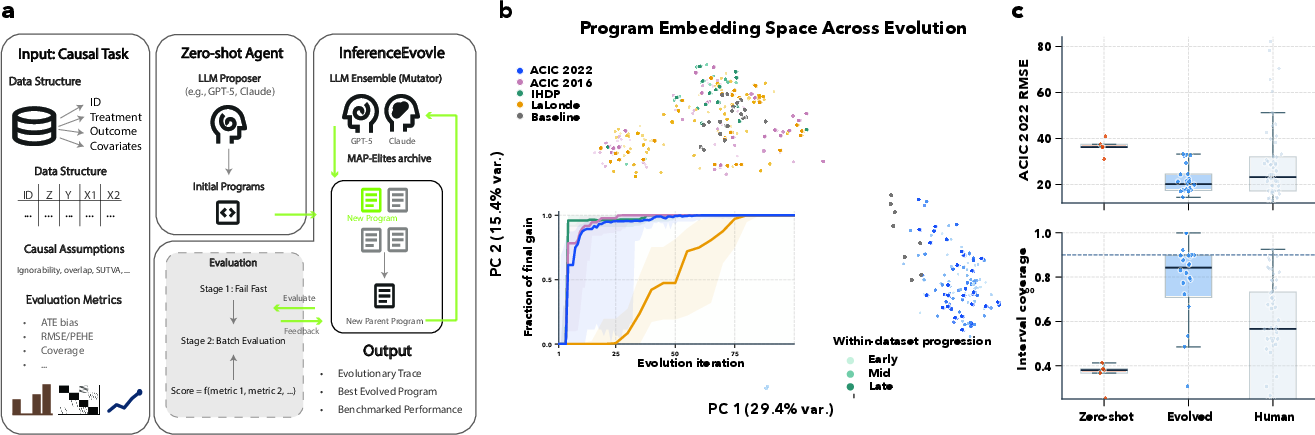
Figure 1: Schematic workflow of estimator discovery via LLM evolution and trajectory of program improvement in embedding space, showing superior held-out RMSE and coverage on ACIC 2022 relative to human entries.
InferenceEvolve Framework Architecture
InferenceEvolve operates by treating causal estimators as modifiable code artifacts. The pipeline initiates from a zero-shot program produced via LLM prompting with only data schema and task description. Subsequently, an LLM or an ensemble executes iterative mutation steps, generating new candidate estimators that are evaluated against a scalarized fitness objective derived from held-in benchmark replicates. Program selection and diversity are managed using MAP-Elites archiving, ensuring both exploitation towards optimal metrics and exploration of diverse estimator structures.
Crucial elements include:
- Prompt Design: Task- and dataset-specific instructions that focus LLM mutations on functional estimator code while restricting allowed libraries and enforcing deterministic, robust Python semantics.
- Ensemble Mutation Sampling: Incorporation of multiple LLMs (e.g., GPT-5, Gemini 3, Claude Sonnet 4) for code diversity and error-correction during evolution.
- Fail-Fast Candidate Evaluation: Rapid filtering of invalid/inefficient programs before full metric computation.
- Multi-objective Fitness: Dataset-dependent scalarization functions balancing root MSE, coverage deviation, and ATE/PEHE errors, with a tunable regularization parameter λ governing objective trade-offs.
- Train/Held-out Protocol: Ensuring generalization via strict separation—no evolution step ever exposes the held-out replicates, which serve for final unbiased evaluation.
The evaluation suite covers four canonical causal benchmarks:
- ACIC 2022: Panel data, SATT estimation with complex time-varying and hierarchical confounding.
- ACIC 2016: High-dimensional, mixed-type covariate semi-synthetic challenge.
- IHDP: Low-dimensional, semi-synthetic, well-calibrated ITE estimation.
- LaLonde: Small-sample, observational design with pronounced selection bias; considered with normalized metrics.
Using factorial designs crossing LLM choices, regularization (λ), split ratio, and random seed, the study generated a diverse pool of 96 evolved estimators. Held-out results demonstrate that, across all benchmarks:
- The best evolved estimators yield substantial reductions in RMSE and PEHE relative to human and package baselines.
- On ACIC 2022, the median RMSE of evolved estimators is 18.8, outperforming the human submission median of 23.2, with best evolved RMSE (14.4) dominating 51 of 58 competition submissions.
- For IHDP and ACIC 2016, best-case PEHE is reduced by 49.3% and 33.1% respectively compared to their strongest BART and Causal Forest baselines.
Performance improvements persist under both direct (oracle) and proxy-guided search objectives. The proxy setting replaces true counterfactual access with pseudo-outcomes via cross-fitted doubly robust estimators—key for practical scenarios lacking simulation access. Proxy-guided evolution achieves highly correlated scores with oracle results (Pearson r=0.97 on IHDP), with best proxy-evolved estimators exceeding tradition baselines.
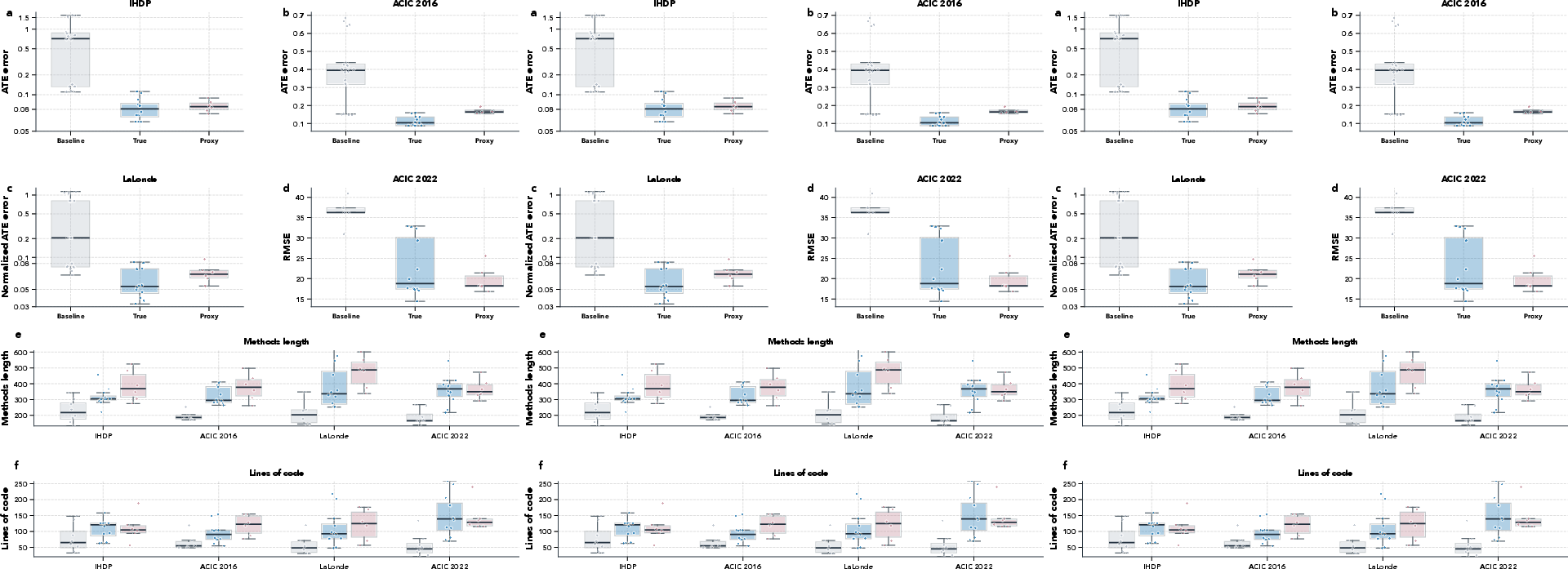
Figure 2: Distribution of held-out metrics across all benchmarks; includes code/text complexity summaries, revealing that evolved programs are larger and more computationally intricate than baselines.
Structural and Algorithmic Insights
A major finding is that LLM evolution does not simply overfit or collapse to the most common template but discovers dataset-specific estimator families characterized by compositional, principled structures.
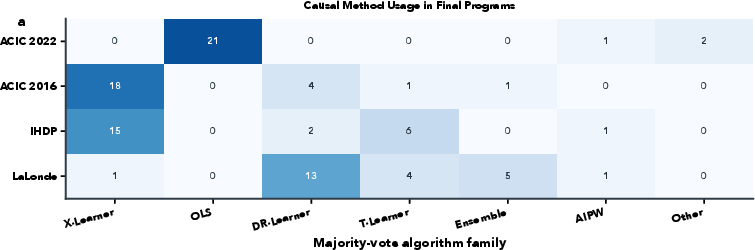
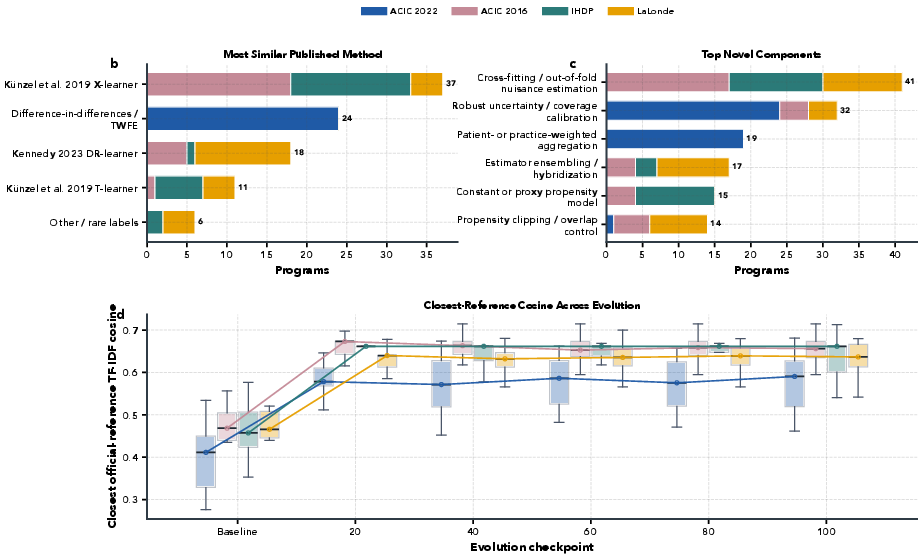
Figure 3: Evolutionary trajectories converge to distinct estimator families on each dataset, rather than copying a fixed template; novel hybrid components are recurrently extracted.
Empirical analyses and LLM-as-judge meta-evaluations indicate:
- Convergence to Distinct Families: TWFE/panel for ACIC 2022, boosting/cross-fitting-based X/DR-learners for ACIC 2016, neural- or ensemble-augmented T/X-learners for IHDP, and robust hybrid weighting for LaLonde.
- Component-level Novelty: Frequent discovery of cross-fitting, robust CI calibration, ensemble meta-weights, patient/practice-level reweighting, and overlap trimming.
- Code Diversity: Within-dataset program code similarity (TF-IDF, embedding cosine) far exceeds between-dataset similarity, indicating nontrivial adaptation to each benchmark’s structure.
Search Dynamics and Regularization
The evolutionary process is characterized by rapid early improvements followed by domain-specific refinements. In most benchmarks, 90% of final-best fitness is achieved in under 20 iterations, except for LaLonde, which exhibits a flatter, more gradual optimization trajectory. Variations in λ were found to modulate accuracy/robustness trade-offs, with smaller values favoring point estimation quality in most settings.
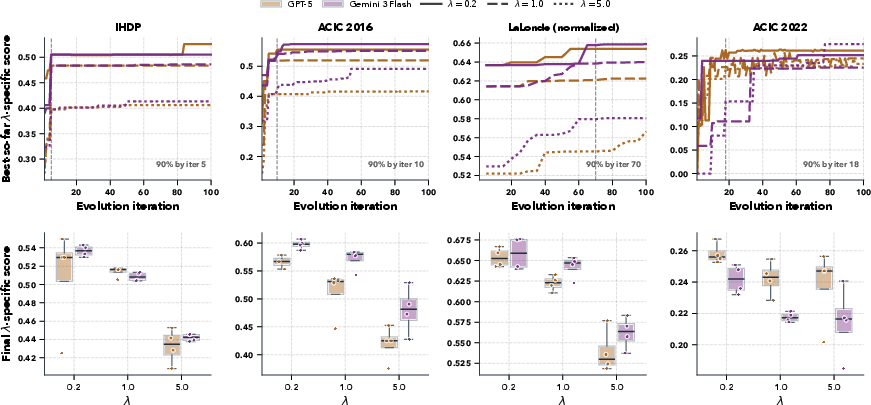
Figure 4: Search-score trajectories and distribution as a function of model and regularization regime; evolutionary progress is fastest on IHDP and ACIC 2016.
Complexity and Interpretability of Evolved Programs
Program complexity—both in raw code and natural language methods description—is consistently higher for evolved programs compared to baselines. This is evident in:
- Program length (character count, lines of code).
- Manuscript-style methods paragraph lengths, as transcribed by multiple LLMs.
Complexity is not driven solely by code verbosity but tracks genuine augmentation in estimator pipeline (e.g., blending, multi-model ensembles, out-of-fold calibration).
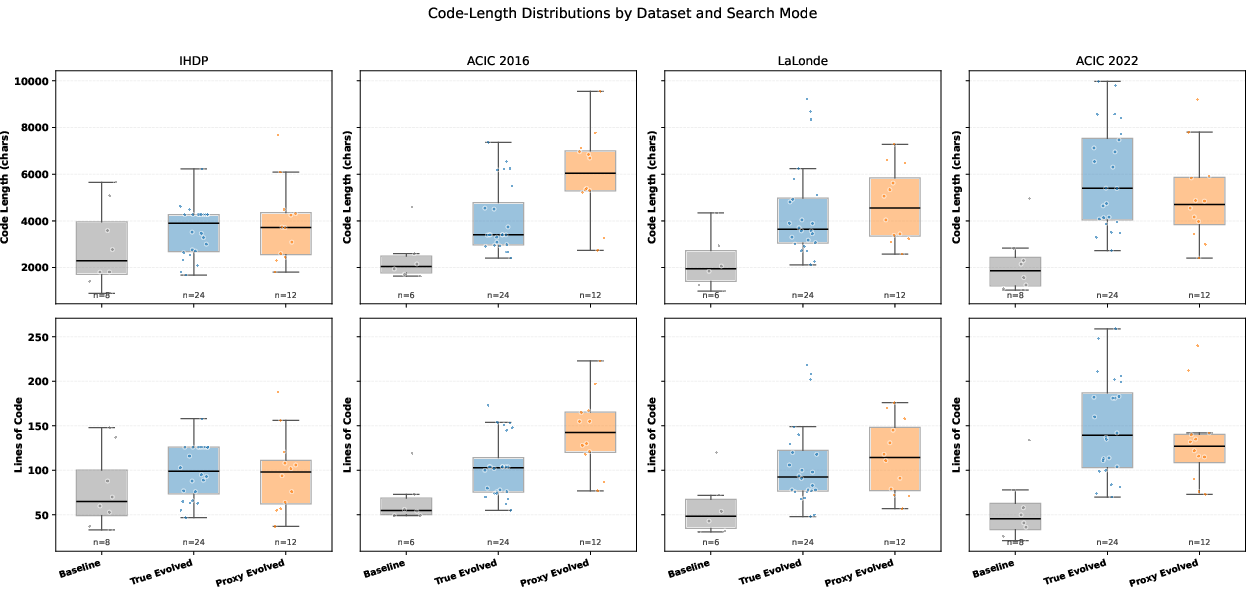
Figure 5: Evolved program code is consistently longer than baseline implementations, especially for the most challenging benchmarks.
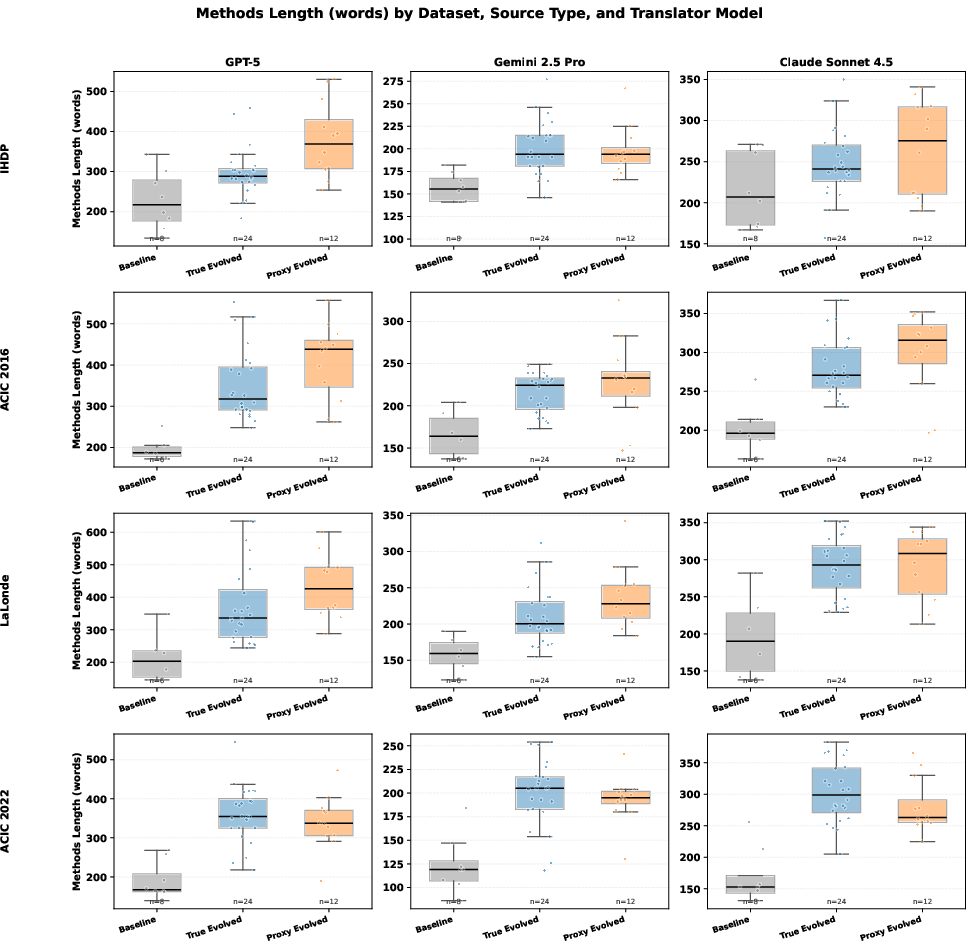
Figure 6: Methods descriptions generated from code by LLMs are significantly longer for evolved programs, underscoring methodical richness.
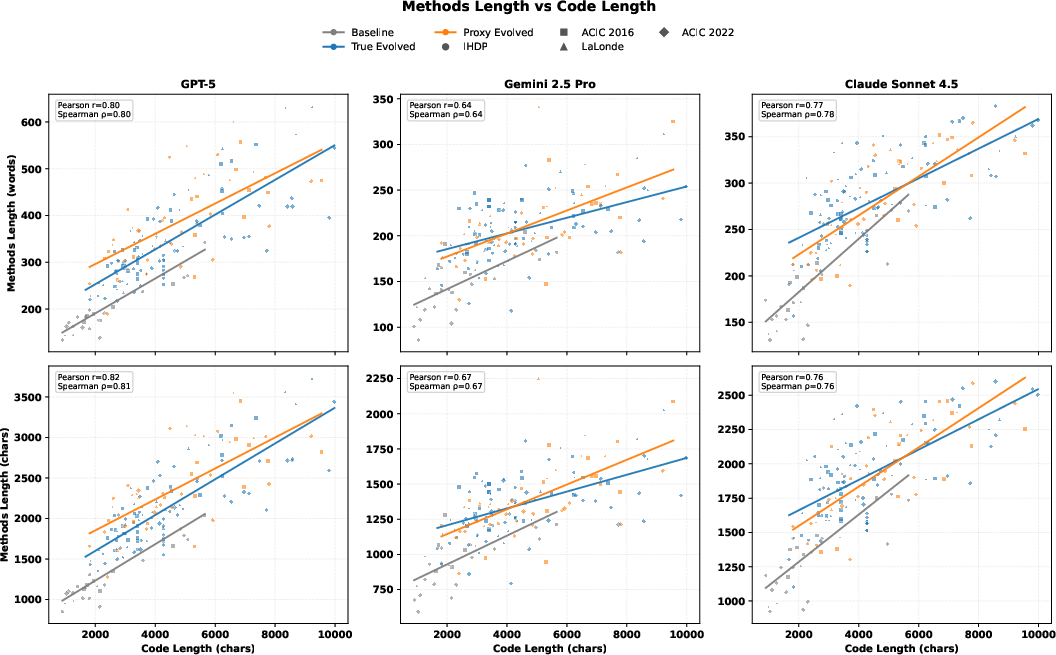
Figure 7: Manuscript description length correlates strongly with codebase size, mirroring growth in structural complexity.
Implications and Future Prospects
This work establishes the viability of LLM-based agentic discovery for highly structured tasks beyond language or static ML problems. By demonstrating the recovery, refinement, and in many cases, expansion past canonical estimator classes, InferenceEvolve provides evidence that automated search can (i) match and frequently surpass expert manual design, (ii) adapt estimator structure to challenging data-generating processes, and (iii) operate even without full oracle access via carefully constructed proxy objectives.
Challenges remain, particularly in: (a) robust generalization under distributional shift, (b) proxy metric design for real-world deployment, (c) extension to multimodal exposures/outcomes and high-missingness domains, and (d) integration with upstream causal discovery/representation-learning approaches.
The broader theoretical implication is that the causal inference pipeline—a historically manual and expert-driven process—can be encoded as an open-ended search space amenable to agent-based optimization with LLMs as program synthesizers and critics. This points to new research directions in automated statistics, interpretable scientific agent design, and joint methodology-data-driven discovery systems.
Conclusion
InferenceEvolve defines a reproducible, extensible template for automating structured causal estimator discovery via self-evolving LLM agents. Across a broad benchmark suite and multiple search settings, it delivers estimators that are both empirically superior and algorithmically interpretable, frequently exhibiting compositional innovations beyond static method selection. These results substantiate the role of LLM-guided program synthesis as a foundational tool for automating and democratizing rigorous causal analysis, and motivate further research in proxy-based search, robustness, and integration with broader scientific pipelines.