- The paper introduces RankEvolve, an LLM-guided evolutionary framework that automates the discovery of retrieval algorithms to surpass classic baselines.
- The methodology leverages Python seed implementations, island-based distributed evolution, and evaluator metrics over 28 datasets for robust optimization.
- Structural seed freedom enables innovative algorithmic designs in evolved BM25 and QL-Dir variants, though with increased computational latency.
RankEvolve: LLM-Guided Evolution for Automated Retrieval Algorithm Discovery
Motivation and Context
Traditional lexical retrieval algorithms such as BM25 and query likelihood with Dirichlet smoothing have persisted as competitive and efficient baselines for first-stage retrieval in IR pipelines. Decades of incremental improvements—BM25+, BM25-adapt, BM25L, alternative smoothing methods—mostly hinge on parameter tuning and incremental enhancement of isolated scoring components, limited by human expertise and intuition. Recent advances in LLM-guided scientific discovery (Novikov et al., 16 Jun 2025), evolutionary program synthesis (Lange et al., 17 Sep 2025), and open-ended algorithm design illuminate the possibility of automating such discovery processes. RankEvolve extends the AlphaEvolve framework, leveraging LLMs as mutation operators in an evolutionary coding loop to synthesize retrieval algorithms directly as code, selected for efficacy on diverse IR benchmarks.
Methodology: LLM-Driven Program Evolution Pipeline
RankEvolve frames retrieval algorithm discovery as a program synthesis task. Seed programs—BM25 and query likelihood with Dirichlet smoothing—are bootstrapped as fully-functional Python implementations, exposing modular abstractions for document representation, query representation, scoring function, and in QL-Dir, the collection LLM. The design deliberately maximizes structural freedom, allowing for architectural reconfiguration rather than mere parameter tuning.
A population database is managed through island-based distributed evolution [island], with each island maintaining a MAP-Elites grid (Mouret et al., 2015) spanning code complexity and population edit distance. Mutation proposals are generated by an LLM (GPT-5.2), conditioned on the top-performing candidates, reference programs, prior attempted variants, and evaluator metrics across datasets. Mutated programs are scored by an evaluator that runs full retrieval pipelines on 12 IR datasets, computing Recall@100, nDCG@10, and latency metrics. The optimization target is 0.8×Avg Recall@100+0.2×Avg nDCG@10.
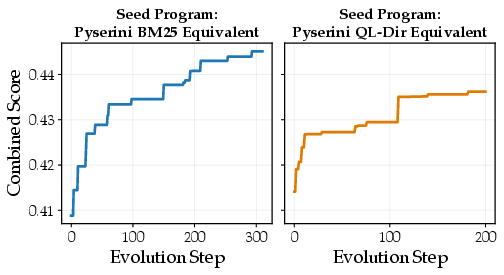
Figure 1: Combined score (0.8×Avg Recall@100+0.2×Avg nDCG@10) trajectories showing monotonic improvement across evolutionary steps for two seed programs.
Experimental Evaluation
RankEvolve is run for 300 steps from the BM25 seed and 200 from the QL-Dir seed, with the evolutionary search yielding novel algorithms. Comprehensive evaluation spans 28 datasets, including held-out BRIGHT and BEIR benchmarks as well as TREC Deep Learning 2019/2020. Results show that the best evolved variants (BM25⋆, QL-Dir⋆) consistently outperform their respective seeds and established baselines on Recall@100 and nDCG@10 across unseen benchmarks, with gains statistically significant by paired t-test (p<0.05). The improvements are robust, extending to both reasoning-intensive and classic ad hoc retrieval.
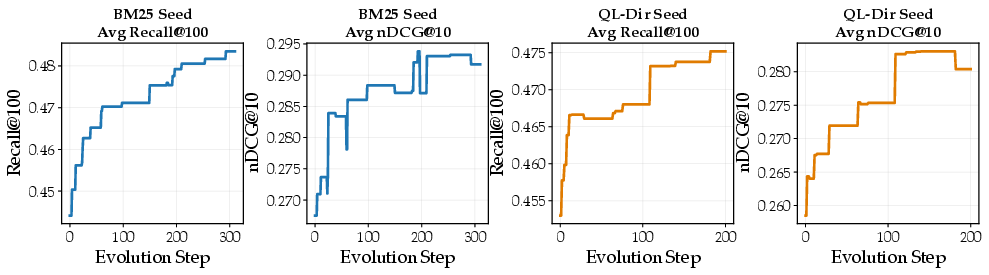
Figure 2: Evolutionary trajectories for Recall@100 and nDCG@10; near-monotonic Recall improvements and nDCG trade-offs reflect optimization for the weighted target.
Evolved Retrieval Algorithms: Structural and Functional Advances
Evolved BM25 Variant
The evolved BM25 demonstrates architectural innovation: a multi-channel modulated scoring function, leveraging four token spaces—base, prefix (stemming), bigram, and micro (sub-word character n-grams)—each weighted and combined via learned coefficients, including activation gating for micro channel sensitive to query rarity. Core scoring aggregates weighted log-TF evidence, modulated by bounded multipliers: query-term coverage, specificity (via pointwise mutual information), coordination, rare-term anchoring, and mild logarithmic document length normalization. The composite term weight is a triple IDF function, yielding a soft stopword filter and aggressive suppression of high-frequency terms. The specificity multiplier rewards documents with over-represented query terms. The length dampener addresses BM25's penalization of long documents via log-normalization, corroborating prior observations [BM25_plus, BM25L].
Evolved Query Likelihood Variant
The best evolved QL-Dir variant retains language modeling foundations but augments them with multiple non-trivial mechanisms. The collection LLM is flattened (power transform), interpolated with document frequency and uniform priors. Term frequency saturation is adaptive, with exponents determined by normalized IDF—common terms saturate faster, rare terms retain signal. Negative contributions are retained via a leaky rectifier, and explicit penalties apply for missing query terms. A soft-AND coverage bonus recognizes breadth of match. Document length prior penalizes both excessive and deficient lengths quadratically in log space. These augmentations yield recall robustness and precision, generalizing across benchmarks.
Convergent Principles and Structural Freedom
Remarkably, RankEvolve's evolutionary trajectories from distinct seeds (BM25, QL-Dir) converge to similar high-level principles: term-frequency saturation, soft stopword filtering, explicit coordination, and length normalization. However, implementation paradigms differ—multiplicative bounded modulation for BM25, additive penalties and coverage bonuses for QL-Dir. This suggests fundamental principles of lexical retrieval that transcend scoring frameworks.
Ablation studies on seed structure demonstrate that structural freedom sets the ceiling for algorithmic innovation. Constrained seeds restrict search to local optima via parameter tuning, composable seeds enable primitive modification but not architectural change, and freeform seeds support full pipeline restructuring. Evolution from freeform seeds achieves the highest overall scores, with complementary strengths observed across per-benchmark metrics.
Latency Profile and Practical Considerations
The evolved algorithms incur substantial computational overhead compared to their seeds. Query latency grows proportionally with program complexity; the best BM25⋆ (step 293) is 11× slower than classic BM25. Despite efficiency signals being exposed to the LLM, they are not part of the optimization objective. Early evolutionary steps yield high-return, efficient innovations, whereas later refinements add complexity for marginal gains. Integrating latency into the optimization target is an immediate extension for deployment-oriented algorithm synthesis.
Implications and Future Directions
RankEvolve demonstrates practical feasibility for LLM-guided, evaluator-driven retrieval algorithm discovery. Evolved programs autonomously rediscover established IR concepts and uncover novel scoring motifs, evidencing transferability to unseen datasets and robustness across evaluation metrics. The framework is agnostic to evaluator signals—efficacy, efficiency, or domain-specific constraints—and can extend to retrieval frameworks beyond lexical, including dense, hybrid, or neural reranking paradigms.
Automated IR research through LLM-driven evolution enables systematic exploration of algorithm design space, diminishing reliance on manual intuition and opening avenues for structured ensemble deployment tailored to workloads. As LLMs ingest increasing programmatic and scientific contexts, their mutation capabilities are anticipated to strengthen, yielding more elegant and efficient retrieval algorithms.
Conclusion
RankEvolve applies LLM-guided program synthesis to automate retrieval algorithm discovery, achieving robust improvements over legacy baselines and rediscovering principled IR motifs. Structural seed design critically impacts search space richness. Despite higher algorithmic complexity, RankEvolve algorithms are effective and transferable. Incorporation of efficiency constraints, extension to dense retrieval, and use of LLM reranking objectives represent tangible future directions. The framework exemplifies the potential of LLMs as coding agents for scientific algorithm design in IR and beyond (2602.16932).

