- The paper introduces HyperGVL as a benchmark evaluating LVLMs for hypergraph understanding and NP-hard reasoning tasks.
- The benchmark comprises 84,000 vision-language QA pairs and 35 multimodal representation combinations to test structure recognition and reasoning.
- The WiseHyGR router adaptively selects optimal representation pairings, boosting both in-domain and out-of-domain LVLM performance.
HyperGVL: Benchmarking LVLMs in Hypergraph Understanding and Reasoning
Benchmark Goals, Design, and Structure
The paper introduces HyperGVL, a comprehensive benchmark for systematically evaluating Large Vision-LLMs (LVLMs) in hypergraph understanding and reasoning tasks (2604.15648). Unlike prior benchmarks restricted to ordinary graphs or textual hypergraph tasks, HyperGVL targets the high-order relational complexity characteristic of hypergraphs, integrating both synthetic and real-world structures sourced from domains such as citation networks and protein interaction networks. The benchmark consists of 84,000 vision-language QA pairs covering 12 distinct tasks, spanning basic element recognition (vertex/hyperedge counting), adjacency analysis, heuristic computations (degree, hyperedge order), and NP-hard reasoning (e.g., hypergraph coloring, strict hypercycle, Hamiltonian path planning). The tasks are precisely partitioned by difficulty and cognitive demands, ranging from atomic structural queries to advanced search/planning problems.

Figure 1: Overview of the HyperGVL benchmark, delineating LVLM evaluation scope over synthetic and real-world hypergraph tasks.
A salient innovation is the multimodal representation support in HyperGVL: seven textual and five visual hypergraph encoding types are implemented, yielding 35 vision-language representation combinations for rigorous capability boundary analysis. Textual formats include incidence-based, neighbor-set, matrix, and high-order descriptions, while visualizations range from bipartite incidence layouts to convex hull enclosures. This orthogonal representation matrix enables fine-grained evaluation of LVLMs' sensitivity to encoding biases and synergistic multimodal information processing.

Figure 2: The seven textual and five visual hypergraph representations in HyperGVL, facilitating detailed modality analysis for LVLMs.
Model Evaluation Protocol and Key Observations
Twelve advanced LVLMs, encompassing both widely adopted open-source and leading closed-source models, are benchmarked in a zero-shot QA setting. HyperGVL’s challenge spectrum exposes robust distinctions in model competence:
- Closed-source LVLMs (Gemini-3 Flash, GPT-4o) demonstrate elevated accuracy in both understanding and reasoning categories. Gemini-3 Flash achieves an average understanding accuracy (Avg.U) of 89.72% and reasoning accuracy (Avg.R) of 62.04%, while the best open-source LVLMs, Gemma3 and Qwen3-VL, reach Avg.U of 63.53% and Avg.R of 34.43%.
- Strong numerical results are observed in low-level tasks: Gemini-3 Flash attains >99% in vertex counting and >97% in neighborhood queries.
- All evaluated models exhibit a pronounced drop in reasoning tasks, especially NP-hard planning (Hamiltonian path <6% for all models), with pronounced representation sensitivity and error propagation in step-wise constraints.
- Parameter scale does not monotonically correlate with performance; smaller LVLMs such as Qwen3-VL-8B sometimes outperform larger models in reasoning, highlighting the need for specialized hypergraph-aware modeling in place of brute-force scaling.
Effects of Representation and Modality
The analysis reveals significant encoding-induced variance:
- Set-based representations (N-Set for text, Enc-Hy for vision) consistently yield the highest performance across both task categories, underscoring the importance of explicit hyperedge group semantics.
- Textual representations exhibit substantial variability, with high-performing formats (e.g., HO-Inc) greatly surpassing matrix-style encodings, the latter suffering from sparsity and indexing burdens.
- Visual representations confer robustness; LVLMs are less sensitive to visual encoding choices, but the addition of explicit hyperedge labeling further enhances performance.
- Pairwise vertex-vertex encodings marginally suffice for primitive queries but fail to support high-order reasoning, with LVLMs unable to reliably reconstruct hyperedge constraints from adjacency alone.
Multimodal Synergy: LVLMs vs LLMs
A direct comparison between LVLMs and corresponding LLMs shows LVLMs consistently outperform their text-only counterparts across all tasks, especially in structural reasoning and complex constraints.
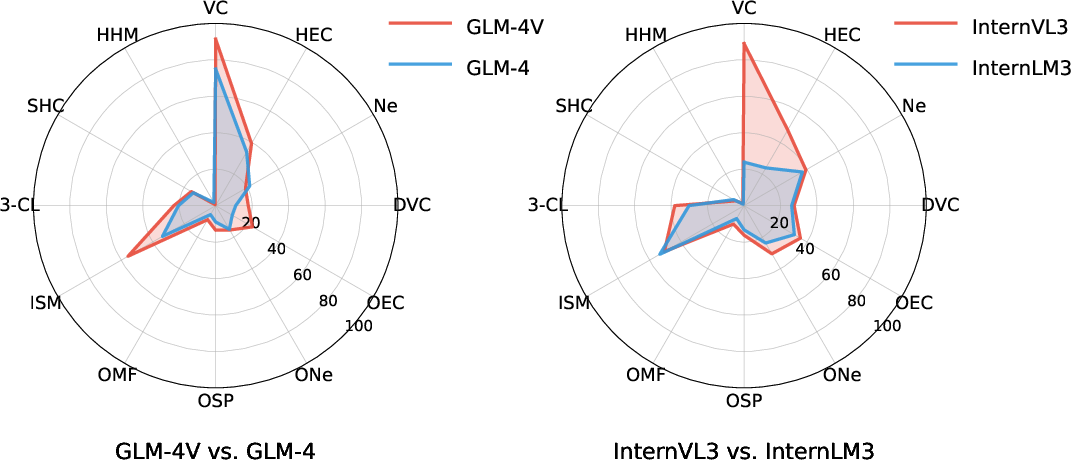
Figure 3: LVLMs (GLM-4V, InternVL3) exhibit broader capability boundaries than LLMs (GLM-4, InterLM3) in hypergraph domains.
Hypergraph Scale and Domain Effects
Model performance degrades as hypergraph size increases, especially on synthetic data, following expected complexity scaling. For real-world hypergraphs, certain reasoning tasks benefit from regular connectivity and structural motifs, permitting higher accuracy in larger instances.
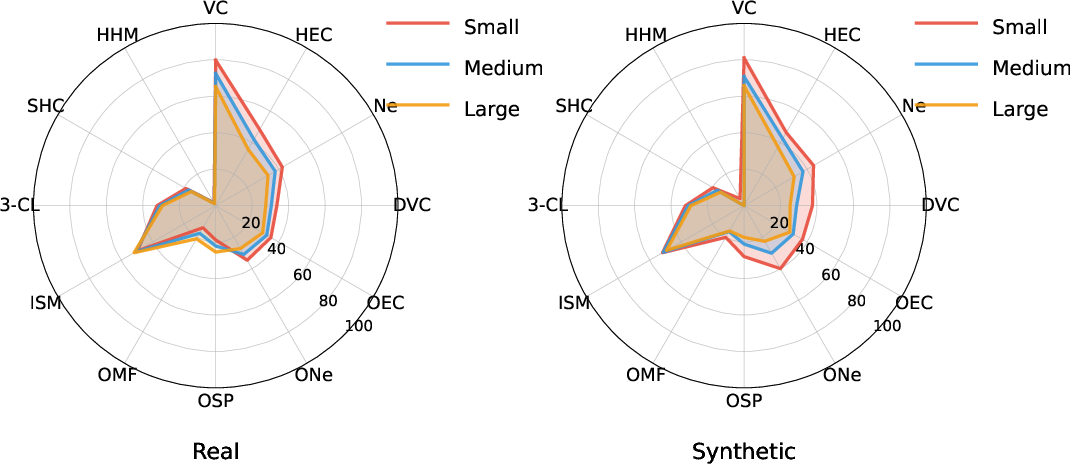
Figure 4: Real-world and synthetic hypergraph performance at varying sizes reveals pronounced complexity-linked accuracy drop.
WiseHyGR: Adaptive Representation Routing
To systematically address the representation sensitivity, WiseHyGR is proposed as a plug-and-play router, trained to select optimal representation pairings for given hypergraph tasks and queries. WiseHyGR leverages a DeBERTaV3-base classifier over Problem-Representation Mapping (PRM) datasets, feeding meta-problem descriptions and leveraging task semantics to adaptively route LVLM queries.
- WiseHyGR consistently boosts both open-source and closed-source LVLM performance in in-domain QA and out-of-domain tasks (e.g., hypergraph node classification) without the need for manual encoding selection.
- The router generalizes cross-task and cross-domain, validating the hypothesis that optimal representation selection improves downstream hypergraph reasoning and classification.
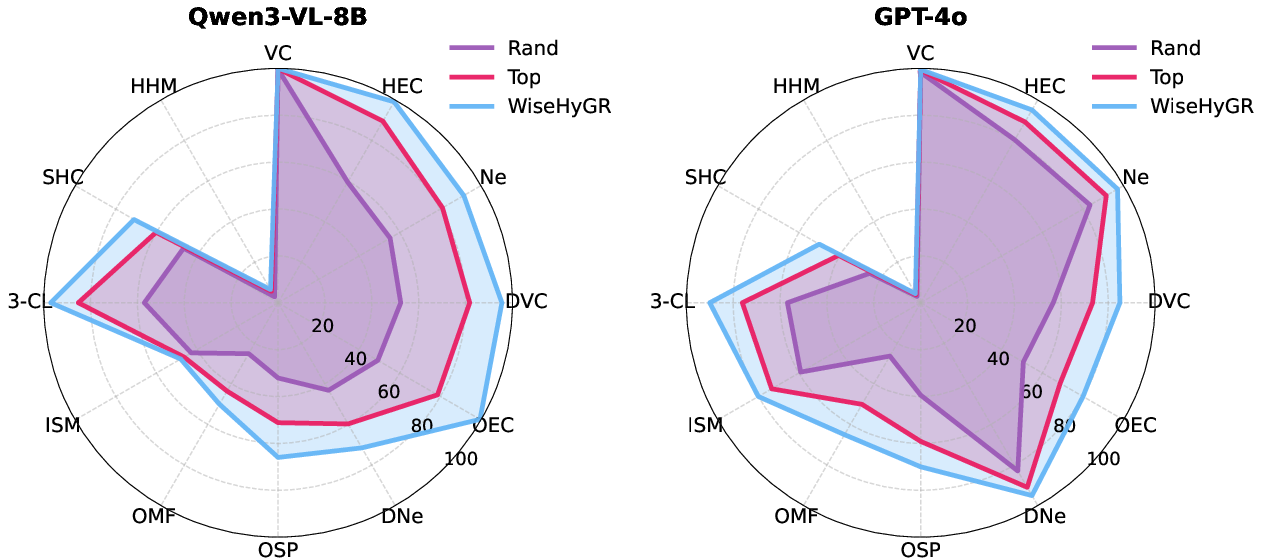
Figure 5: WiseHyGR enhances LVLM in-domain performance for hypergraph QA tasks via adaptive representation routing.
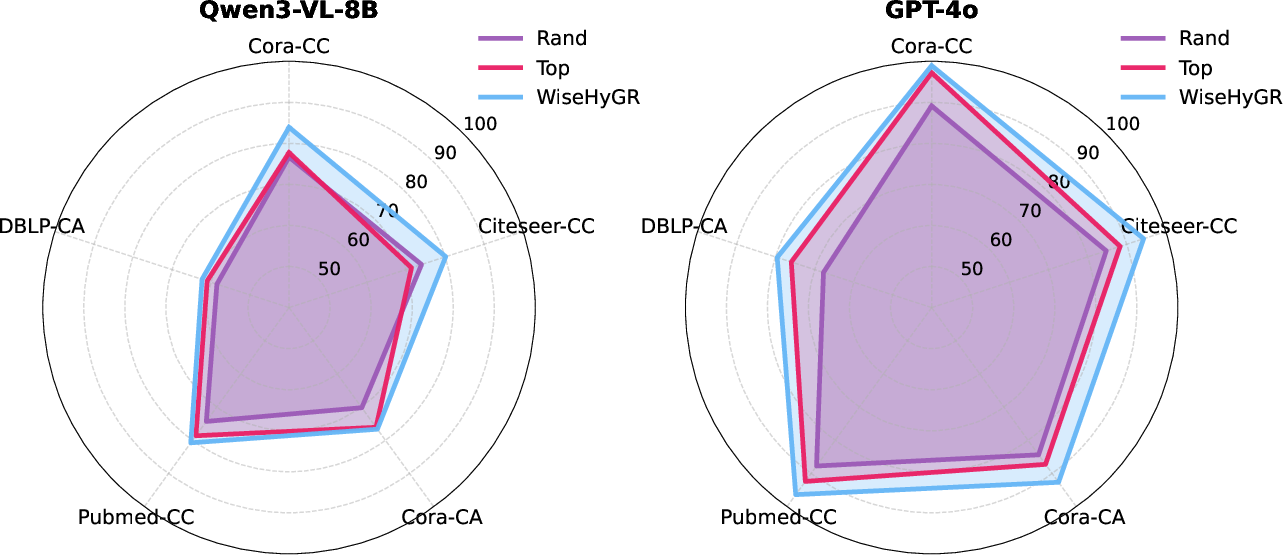
Figure 6: WiseHyGR demonstrates zero-shot generalizability in out-of-domain hypergraph node classification across multiple datasets.
Isomorphism Recognition Task Visuals
Notably, isomorphism detection tasks benefited from deterministic layouts that revealed structural equivalence via visual similarity, leading to unexpectedly strong LVLM performance.

Figure 7: Visual hypergraph representations for the ISM task illuminate straightforward cues for isomorphism recognition.
Implications, Limitations, and Future Perspectives
HyperGVL establishes a rigorous foundation for LVLM assessment on hypergraph scenarios, delineating capability gaps, modality synergies, and representation biases. It directly exposes both practical limitations (open-source models lagging on high-order reasoning, scale-dependent drop-offs, encoding-induced variance) and theoretical frontiers (multimodal integration, adaptive routing, cross-domain generalizability). The WiseHyGR router advances reproducible enhancement strategies, and the benchmark’s design principles can be applied to other high-order relational domains.
Practically, areas such as molecular modeling, semantic retrieval-augmentation, and multi-agent social community analysis can benefit from progress catalyzed by HyperGVL. Theoretically, the results advocate for explicit hyperedge modeling, intelligent representation selection, and multimodal co-training strategies in future LVLM architectures.
Resource and task coverage constraints (e.g., domain-specific hypergraph tasks, extremely large-scale models) are noted as limitations, but HyperGVL’s extensible paradigm is amenable to future expansion.
Conclusion
HyperGVL offers a technically precise, multimodal benchmark for LVLM evaluation in hypergraph understanding and reasoning, revealing substantial gaps and opportunities. Representation choice critically impacts performance, and multimodality enables enhanced structural reasoning. WiseHyGR delivers effective representation routing, improving LVLMs across-domain and task boundaries. This work steers the LVLM community toward more robust, adaptive, and scalable hypergraph modeling capabilities.

