- The paper demonstrates that hallucination in transformers emerges as a trajectory commitment event, identified through same-prompt bifurcation and causal activation patching.
- It employs bidirectional activation patching to reveal a marked asymmetry, with corruption rates up to 87.5% and limited correction efficacy around 33.3%.
- Results underscore an attractor basin dynamic, where early hidden-state divergence irreversibly channels outputs into correct or hallucinated regimes.
This paper investigates the internal mechanisms underlying hallucination in autoregressive transformers, specifically Qwen2.5-1.5B. Hallucination is characterized not as a mere retrieval or knowledge failure but as a trajectory-level commitment event governed by attractor dynamics in the hidden-state space. Central to the analysis are two methodological frameworks: (1) same-prompt bifurcation, sampling identical prompts under controlled stochasticity to disentangle prompt-based confounds from intrinsically stochastic trajectory divergence, and (2) bidirectional activation patching at fine spatial-temporal granularity, introducing causal evidence on the ease of corrupting versus correcting hallucinated states.
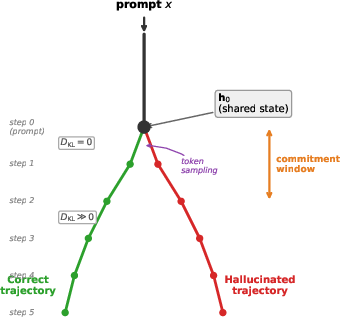
Figure 1: Overview of attractor basin dynamics—shared initial state, stochastic commitment, and asymmetry in corruption versus correction as revealed by causal patching.
Unlike previous works relying on correlational probes or representational readouts, this study establishes causal structure, scrutinizing the irreversibility and stability properties of hallucinated versus correct output regimes.
Bifurcation and Early Trajectory Commitment
A broad prompt set (61 prompts across factual, confabulation, false-premise, math, chain-of-thought, and leading categories) demonstrates that nearly half (44.3%) exhibit true bifurcation: repeated identical inputs elicit both correct and hallucinated outputs, confirming the existence of prompt-independent, trajectory-driven divergence. Notably, false-premise prompts almost universally bifurcate, while confabulations mostly deterministically hallucinate.
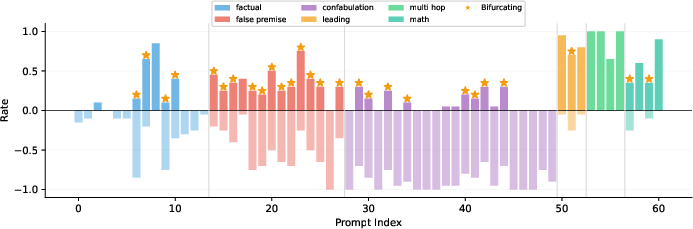
Figure 2: Per-prompt rates for correct and hallucinated generations, stratified by category, with stars indicating bifurcation; false-premise prompts robustly cluster as bifurcating.
Step-wise analysis of softmax output distributions finds vanishing KL divergence at the initial step, and an immediate, discontinuous divergence at the first generated token—minimal drift is observed, indicating that a singular sampling event commits the model to a distinct trajectory.
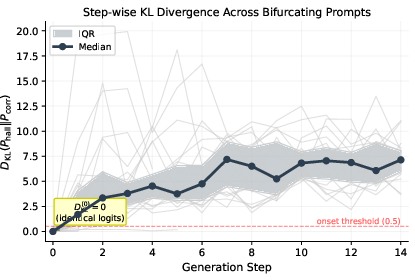
Figure 3: Median and per-prompt KL divergence, showing an abrupt transition at generation step 1, marking trajectory fork points.
Internal Separation and Divergence Geometry
Layer-resolved analysis with Cohen’s d quantifies the progressive separation of hidden states. Divergence initiates in upper layers at step 1, subsequently cascading to lower layers with monotonic growth.
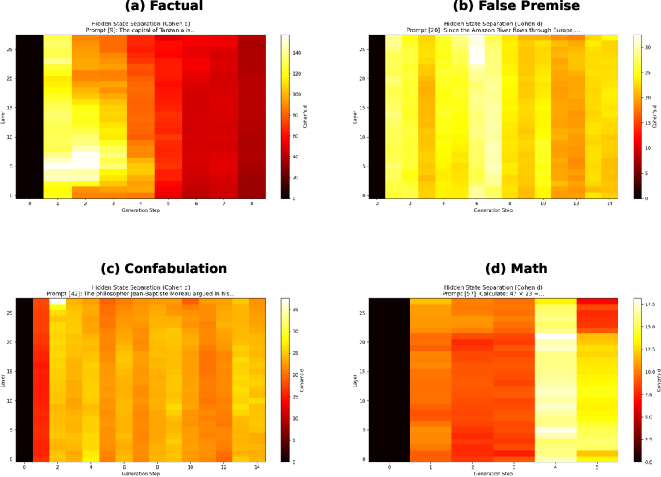
Figure 4: Heatmaps of hidden-state separation; step 0 uniformity and post-fork expansion in deep layers evidences rapid basin commitment and consolidation.
Principal component projections further show that, at all layers, correct and hallucinated trajectories share a point of origin, bifurcating immediately after the first sampled token. This visualizes the attractor geometry—proximity at onset, rapid and irreversible divergence with subsequent autoregression.
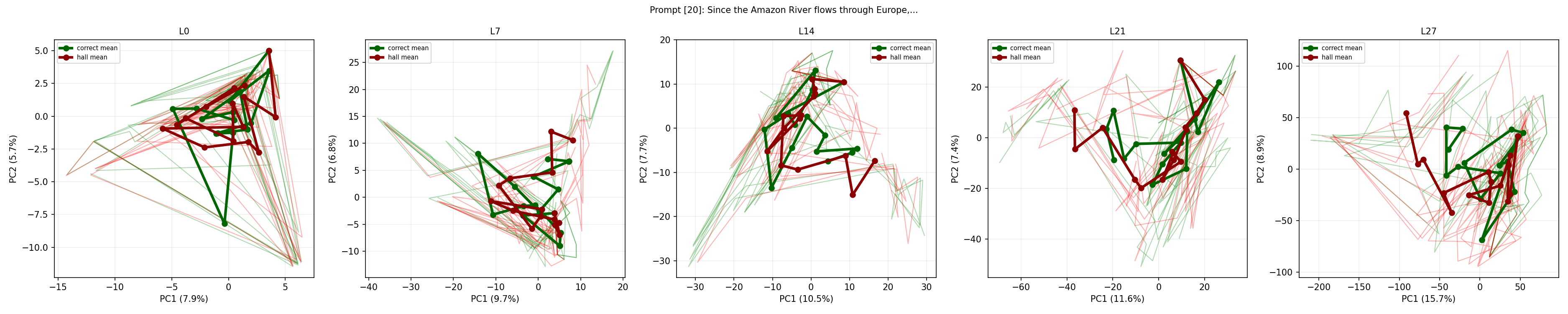
Figure 5: PCA projections for correct and hallucinated runs; trajectories initially coincide and subsequently follow divergent manifolds.
Causal Activation Patching: Asymmetry and Attractor Stability
Activation patching provides direct causal assessment. Replacing hallucinated activations with those from correct runs (H→C, correction) and vice versa (C→H, corruption) reveals a pronounced asymmetry. Corruption of correct runs succeeds in up to 87.5% of trials with a single-layer patch (L20), while correction of hallucinated runs peaks at only 33.3% (L24), both exceeding control and baseline rates but with a 2.6× disparity at the best layers.
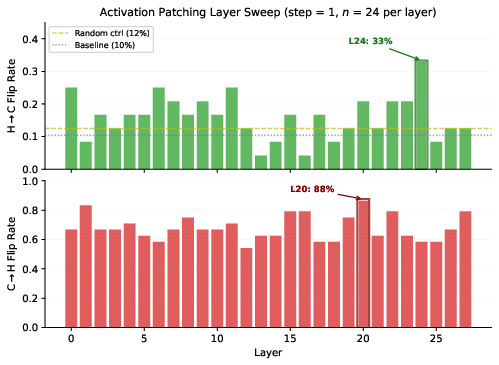
Figure 6: Layer-swept patching results highlight high susceptibility to corruption and resistance to correction; corruption rates approach 90% while correction saturates at one-third despite prompt-matched intervention.
This trend generalizes across steps: corruption remains high when applied at any point, but correction effects peak only with immediate intervention and decay thereafter, evidencing a narrow window for potential recovery.
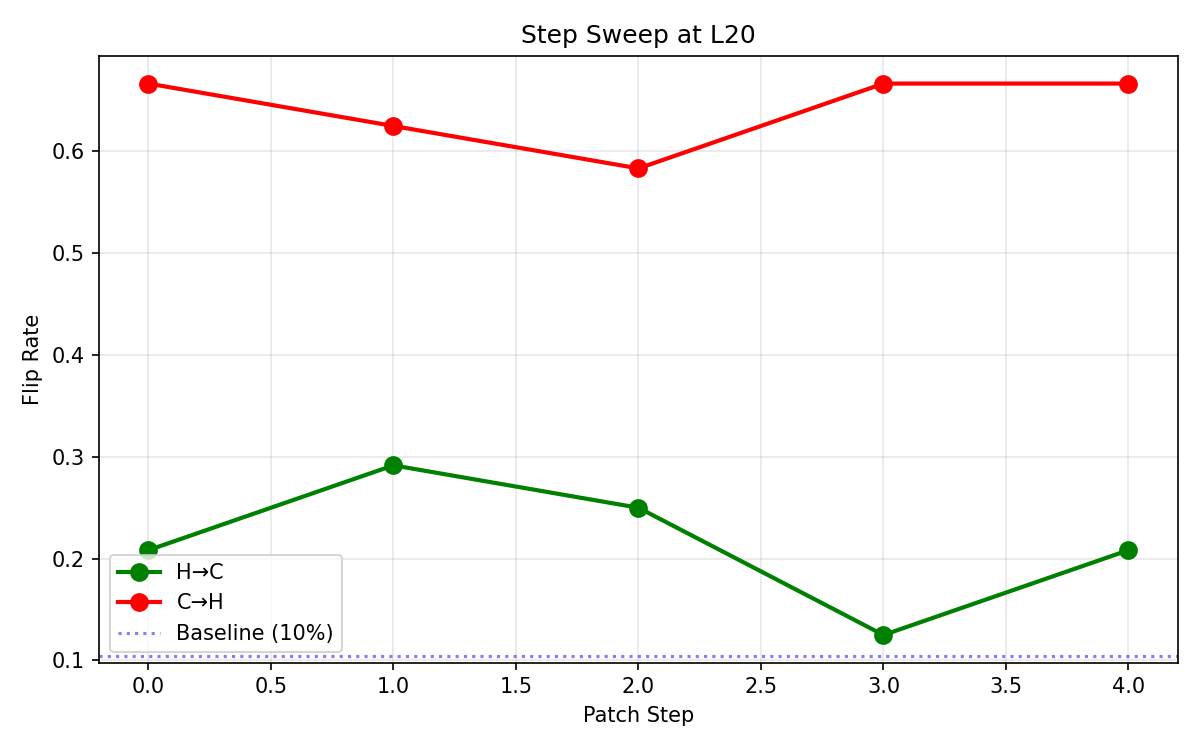
Figure 7: Step-wise sweep—correction is effective only immediately after bifurcation; corruption remains consistently high across generation steps.
Window (multi-step) patching demonstrates that recovery requires persistent multi-step intervention—single steps are insufficient to exit the hallucination basin, while multi-step patching scales correction rates monotonically.
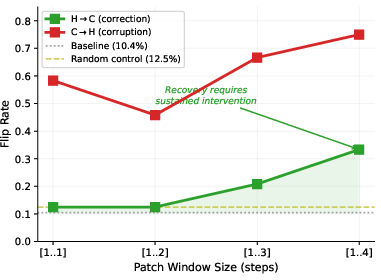
Figure 8: Correction effectiveness scales with patch duration, implicating deep attractor basins requiring coordinated, distributed intervention for escape.
Control conditions (random-prompt and wrong-to-wrong patches) remain at baseline rates, establishing that the correction effect is prompt- and direction-specific.
Regime Structure and Prompt-Encoding Predictivity
A linear probe analysis on step-0 residual activations (pre-sampling, post-encoding) shows that per-prompt hallucination rates are highly predictable from initial hidden states (r=0.776 at L15, p<0.001 permutation). Unsupervised clustering at the optimal layer reveals five distinct clusters accounting for a majority of between-prompt hallucination rate variance (η2≈0.55).
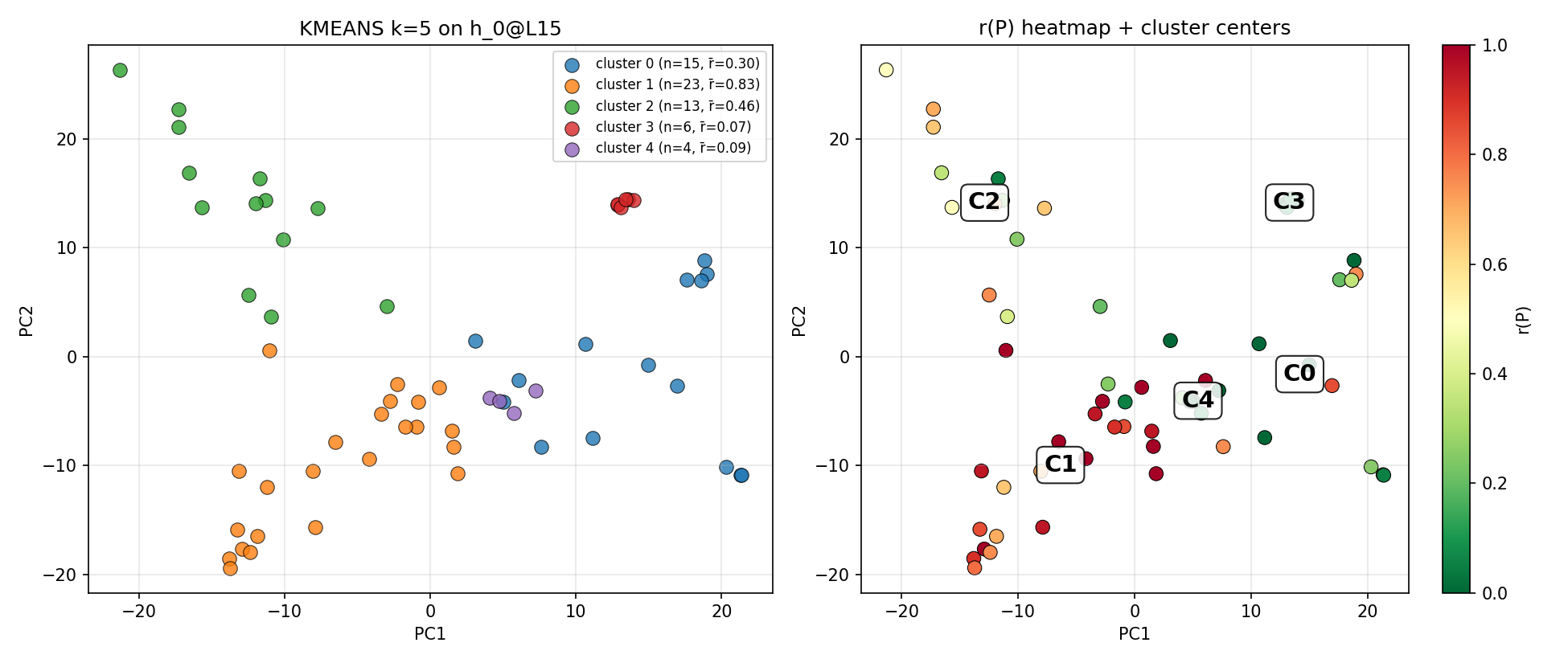
Figure 9: k-means clustering of initial encodings: discrete regime-like groupings correspond to factual, false-premise, confabulation, narrative, and computational prompts.
Step-0 regime probe performance and bifurcation predictions (AUROC up to 0.94) confirm that basin/attractor structure is established largely at encoding time, with the “saddle” cluster corresponding to prompts most likely to bifurcate.
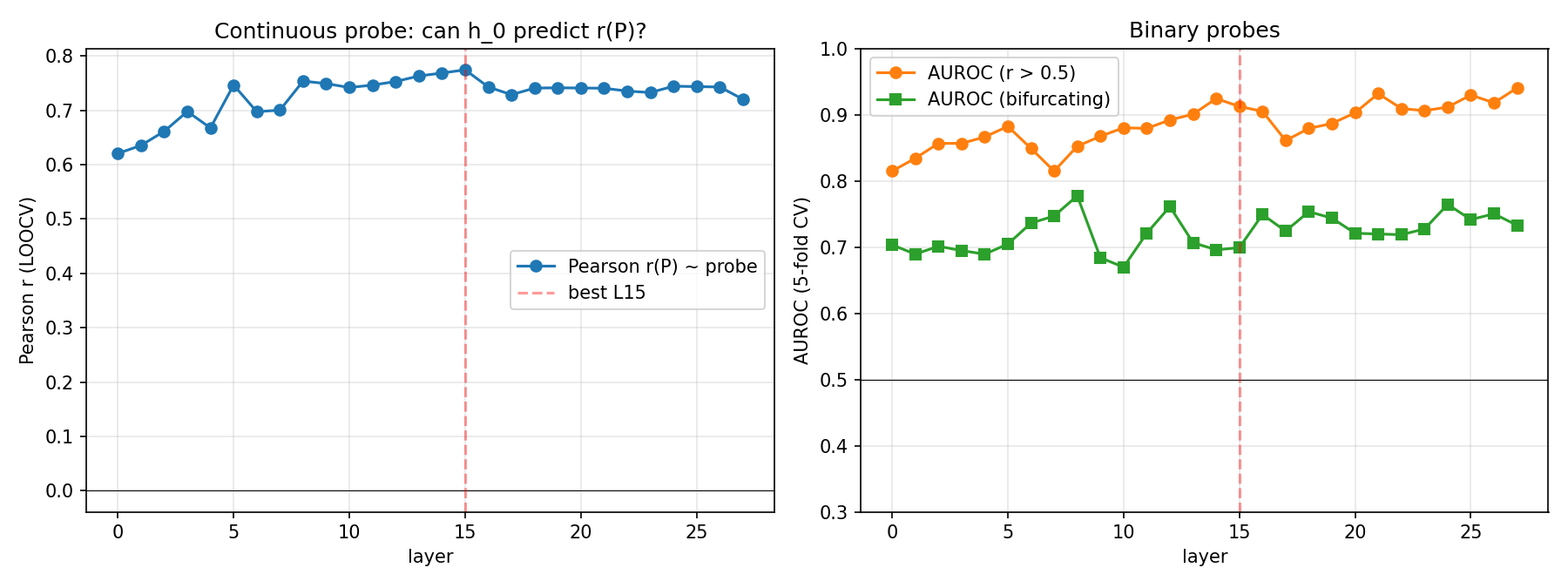
Figure 10: Layer-wise probe performance; regime signal plateaus in mid layers and tracks inter-category boundaries as opposed to fine intra-category differences.
Variance explained by clustering in encoding space peaks at k=5, indicating an optimal partitioning for hallucination risk structure.
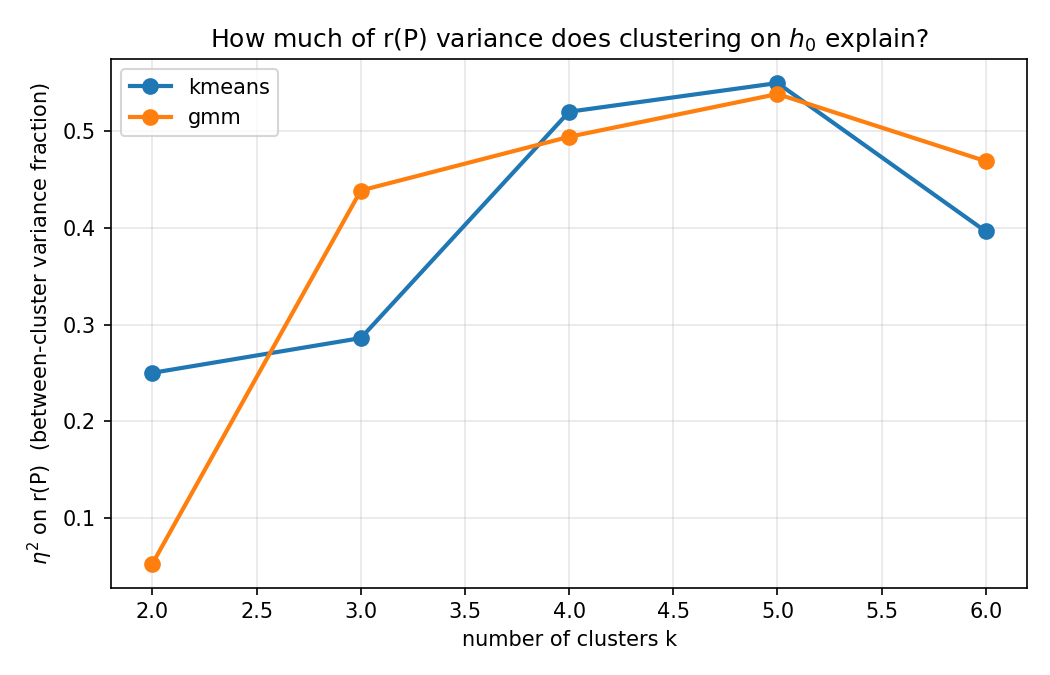
Figure 11: Variance explained by clustering as a function of k; five clusters best capture hallucination-related encoding features.
Permutation testing confirms statistical robustness: step-0 regime predictivity vastly exceeds any reasonable null.
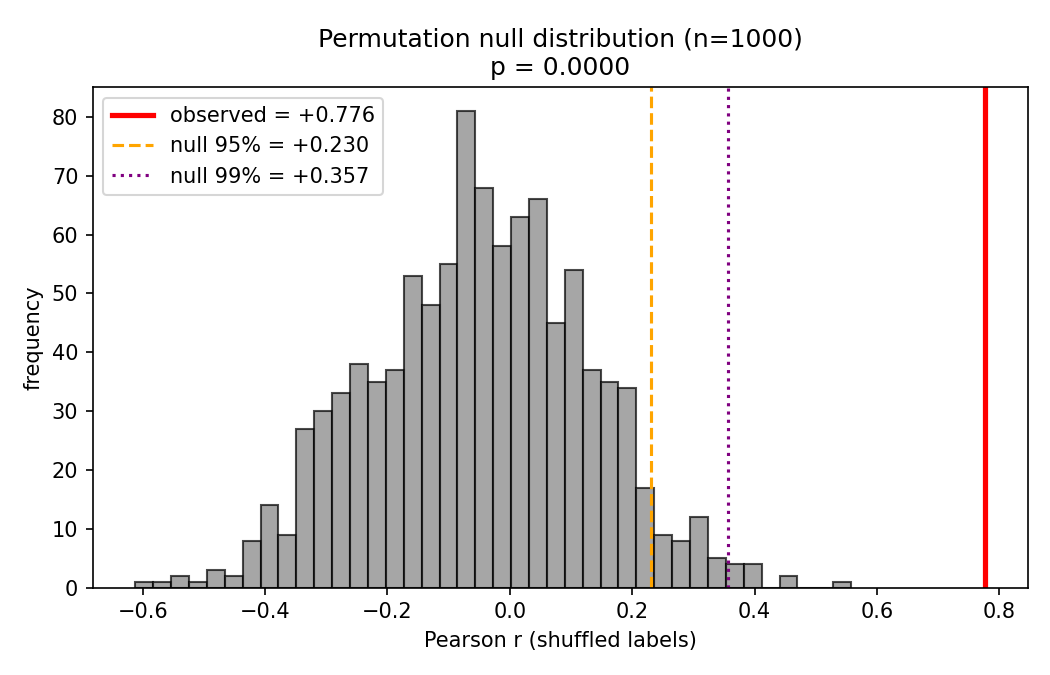
Figure 12: Permutation null distribution on probe correlation at best layer; observed effect exceeds all shuffles with →0.
Theoretical Implications
These findings operationalize hallucination as a dynamical phenomenon: stochastic events at the generation outset determine entry into deep, locally stable attractor basins corresponding to coherent (correct) or hallucinated trajectories. Once committed, escape from a hallucinated basin is highly resistant to single-point or linear interventions due to the nonlinear boundary structure—subsequent layers rapidly re-consolidate the hallucinated regime. This clarifies the limited efficacy of linear representation interventions and justifies the empirical irreversibility observed post-bifurcation.
The causal asymmetry in trajectory flipping indicates that hallucination is robustly encoded as a local minimum of the model’s iterative dynamics, and not merely as noise or uncertainty. The encoding-time predictivity and regime clustering further suggest that safety interventions might be most effective if deployed before generation begins, targeting prompt representations in “saddle” regions near the basin boundary.
Limitations and Future Directions
The study is limited to a single 1.5B parameter transformer without RLHF; scaling effects, training interventions, and alignment-specific fine-tuning could affect attractor geometry. Sample sizes per patching condition are modest, and more exhaustive multi-layer/multi-step patching strategies may yield higher correction rates and further resolve attractor support structure. Future work should extend cross-model generalization, formalize regime-detection tools for intervention timing, and develop nonlinear patching or “trajectory steering” mechanisms to robustly disrupt hallucination basins.
Conclusion
This work provides a comprehensive causal analysis of hallucination dynamics in transformers, showing that hallucination is not a simple error but an early, regime-selecting trajectory commitment induced by attractor dynamics with strong causal asymmetry. The attractor basin interpretation reframes hallucination as robust, prompt-encoded, and difficult to reverse post-hoc, with regime-level structure enabling potential pre-generation interventions. These insights significantly advance the mechanistic understanding of generative failure modes and bear on the design of next-generation alignment and interpretability tools for autoregressive models.