- The paper introduces DST, a unified interpretability framework that causally maps internal semantic representations in LLMs to pinpoint failure modes leading to hallucinations.
- It employs mechanistic tools such as causal path tracing, patching interventions, and subsequence tracing to construct semantic networks and identify the critical 'commitment layer'.
- Empirical results show a strong negative correlation between pathway coherence (DSS) and hallucination rate, suggesting actionable targets for architectural interventions.
Mechanistic Tracing of Hallucinations in LLMs via Distributional Semantics
Introduction and Motivation
The persistent issue of hallucination—generation of plausible but factually incorrect content—remains a critical obstacle for the deployment of LLMs in high-stakes domains. The paper "Distributional Semantics Tracing: A Framework for Explaining Hallucinations in LLMs" (2510.06107) addresses the architectural and mechanistic origins of hallucination, moving beyond data-centric or black-box detection paradigms. The authors introduce Distributional Semantics Tracing (DST), a unified interpretability framework that integrates multiple mechanistic tools to causally map the evolution of internal semantic representations and pinpoint the precise computational failure modes leading to hallucination.
Distributional Semantics Tracing (DST): Framework and Methodology
DST is designed to provide a layer-wise, causal account of how meaning is constructed and, in the case of hallucination, corrupted within the Transformer architecture. The framework synthesizes signals from concept importance (via causal path tracing), representational drift (via patching interventions), and subsequence tracing to construct a semantic network at each layer.
Figure 1: The DST framework integrates concept importance, patched representations, and subsequence tracing to build a semantic network that reveals the conceptual relationships driving a prediction.
The DST pipeline operates as follows:
- Concept Importance: Identification of critical components (neurons, heads, MLPs) responsible for a prediction using causal path tracing.
- Patching Interventions: Application of patching (e.g., Patchscopes) to measure the causal effect of specific representations on output, quantifying representational drift.
- Subsequence Tracing: Attribution of internal states to specific input tokens or subsequences, enabling fine-grained localization of failure points.
- Semantic Network Construction: Integration of the above into a directed, weighted graph where nodes are concepts and edges represent the strength of semantic associations, denoted as Ω(A⇒B).
This network provides a local, instance-specific explanation of the model's reasoning trajectory, rather than a global behavioral summary.
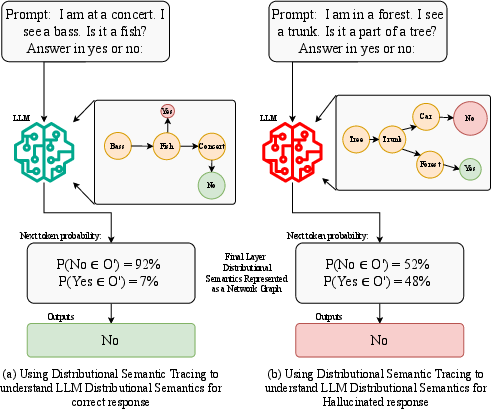
Figure 2: DST exposes the final-layer semantic network for (a) a correct response and (b) a hallucination, where a spurious association corrupts the reasoning.
Layer-wise Hallucination Dynamics and the Commitment Layer
A central contribution is the identification of a "commitment layer"—the point at which the model's internal representations irreversibly diverge from factuality, rendering hallucination inevitable. DST enables the tracking of semantic drift across layers, revealing three critical stages:
- Prediction Onset: Emergence of a competing, spurious association.
- Semantic Inversion Point: The incorrect pathway overtakes the correct contextual pathway in strength.
- Commitment Layer: The model's internal state stabilizes on the hallucinated pathway, precluding recovery.
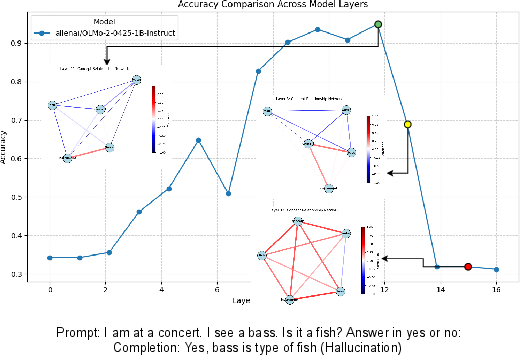
Figure 3: A layer-wise view of how a hallucination unfolds inside a LLM, tracking confidence and semantic drift through prediction onset, inversion, and commitment.
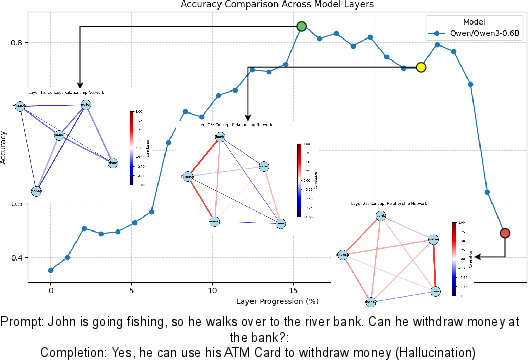
Figure 4: Layer-wise analysis of a reasoning failure for Qwen 3, showing the progression from prediction onset to semantic inversion and commitment.
This granular, mechanistic decomposition is generalizable across hallucination types, as validated on diverse benchmarks (HALoGEN, Racing Thoughts).
Quantifying Pathway Coherence: Distributional Semantics Strength (DSS)
To operationalize the notion of pathway coherence, the authors introduce the Distributional Semantics Strength (DSS) metric:
DSS=∑p∈Asp∑p∈Csp
where C is the set of correct contextual pathways, A is the set of all active pathways, and sp is the edge weight for pathway p. DSS provides a quantitative measure of the dominance of contextually correct reasoning over spurious associations.
A strong negative correlation (ρ=−0.863, R2=0.746) is observed between DSS and hallucination rate, establishing that lower pathway coherence is a primary and predictable vulnerability.
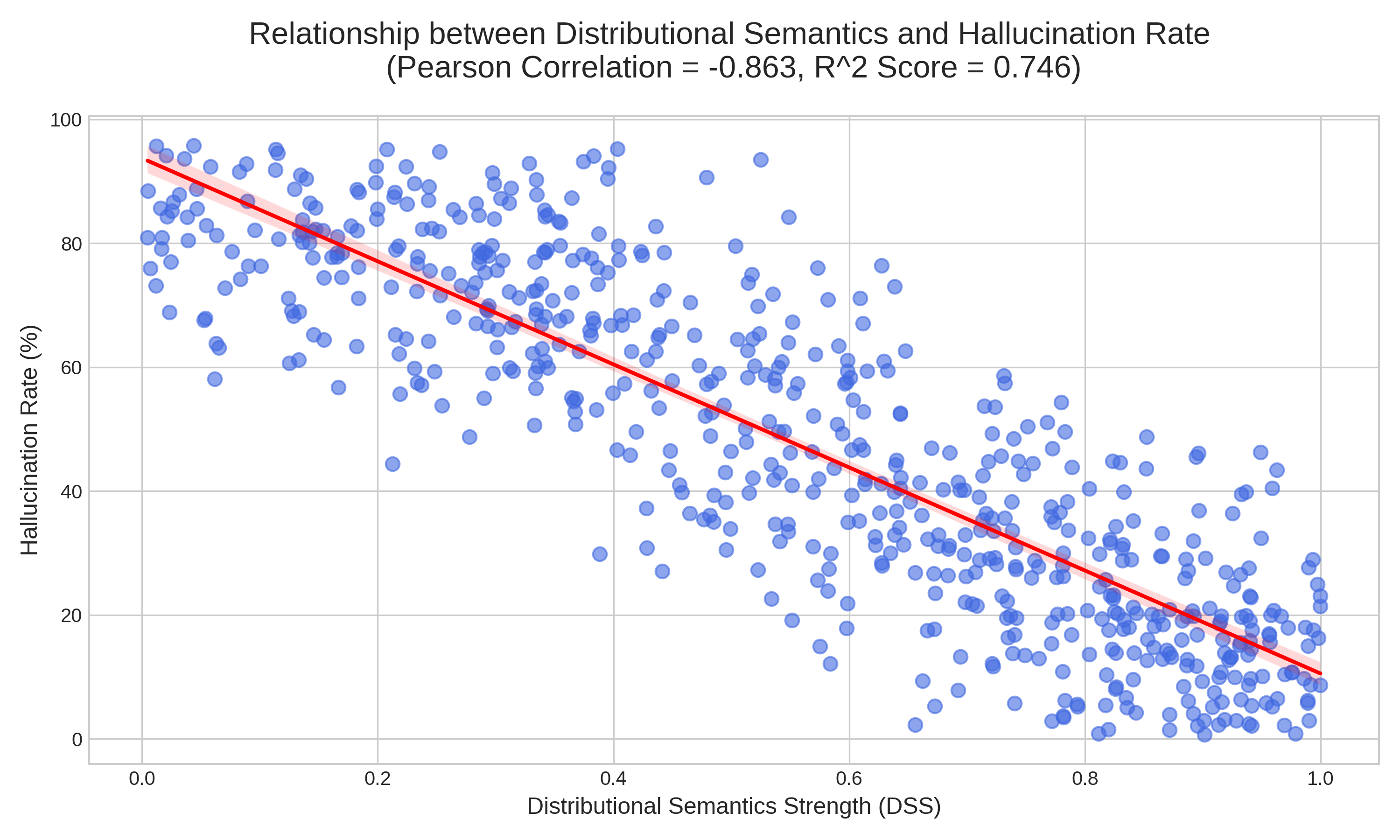
Figure 5: The relationship between a model's internal reasoning coherence (DSS) and its tendency to hallucinate, showing a strong negative linear relationship.
Mechanistic Failure Modes: Pathway Conflict and Reasoning Shortcut Hijack
DST reveals that hallucinations frequently arise from a conflict between two computational pathways, functionally analogous to dual-process theories in cognitive science:
- System 1 (Associative Pathway): Fast, heuristic, and driven by strong statistical co-occurrences (often implemented in MLPs).
- System 2 (Contextual Pathway): Slow, deliberate, and responsible for compositional, context-sensitive reasoning (primarily via attention).
When the System 1 pathway is disproportionately strong, it can hijack the reasoning process, leading to "Reasoning Shortcut Hijack" failures.
Figure 6: A mechanistic view of a Reasoning Shortcut Hijack, where the fast, heuristic System 1 pathway overpowers the deliberate System 2 pathway, forcing a hallucination.
A related failure, "Analogical Collapse," occurs when the model defaults to high-frequency topical associations rather than executing the required analogical logic.
Figure 7: Visualization of an Analogical Collapse, where the deliberate System 2 pathway is abandoned in favor of a computationally cheaper System 1 association.
The DST framework enables direct visualization and quantification of these pathway competitions.
Figure 8: DST reveals two competing computational pathways: a fast, associative System 1 shortcut and a slow, contextually correct System 2 pathway.
Empirical Validation and Faithfulness
DST is evaluated against a suite of explainability methods (attention, LIME, SHAP, Patchscopes, SAEs, Causal Path Tracing) on the Racing Thoughts and HALoGEN benchmarks. DST achieves the highest average faithfulness scores (0.71 and 0.79, respectively), with statistically significant improvements over all baselines. The faithfulness metric is rigorously validated via LLM-as-Judge and human studies, demonstrating high alignment with expert assessments.
Implications, Limitations, and Future Directions
Theoretical and Practical Implications
- Mechanistic Predictability: The strong correlation between DSS and hallucination rate implies that hallucinations are not random but are predictable consequences of internal semantic weakness.
- Architectural Targeting: Identification of the commitment layer and pathway conflict provides concrete targets for intervention, such as representation engineering or lightweight steering to rebalance pathway dominance.
- Unified Interpretability: DST demonstrates the value of integrating multiple mechanistic tools into a single, causal narrative, moving beyond fragmented or post-hoc explanations.
Limitations
- Representation Dependence: DST's fidelity is contingent on the quality and separability of internal representations; models with poor or highly polysemantic embeddings may yield weaker or noisier traces.
- Computational Cost: The pipeline is computationally intensive due to layer-wise tracing and patching, limiting scalability for large models or datasets.
- Abstraction Risk: The System 1/System 2 dichotomy is a functional abstraction; the precise mapping of these pathways to architectural components (MLP vs. attention) is not causally isolated and remains a hypothesis.
Future Directions
- Intervention and Control: Leveraging DST to design targeted interventions (e.g., representation editing, dynamic pathway reweighting) to preempt or correct hallucinations at the commitment layer.
- Scalable Tracing: Development of approximate or sparsified tracing methods to enable DST at scale.
- Generalization: Aggregating DST traces across instances to infer global regularities, reusable circuits, or architectural motifs associated with robust reasoning.
Conclusion
Distributional Semantics Tracing provides a principled, mechanistic framework for explaining hallucinations in LLMs, reframing them as predictable outcomes of architectural pathway conflicts rather than idiosyncratic data artifacts. By integrating multiple interpretability signals into a unified semantic network, DST enables fine-grained, causal diagnosis of when, how, and why hallucinations occur. This work lays the foundation for proactive, architecture-level interventions and advances the field toward more transparent, controllable, and trustworthy LLMs.