- The paper demonstrates that transformer models generate coherent semantic concepts from pure noise, revealing structured activation patterns with sparse autoencoders.
- The methodology employs sparse autoencoders to decompose internal activations, achieving up to 73% accuracy in predicting and mitigating hallucination risk.
- The findings imply that targeted suppression of specific concept activations can serve as an effective intervention to reduce model hallucinations.
Introduction
This work presents a systematic investigation into the mechanistic origins of hallucinations in pre-trained transformer models, focusing on both vision and language modalities. The authors employ sparse autoencoders (SAEs) to decompose the internal activations of transformers into interpretable, high-dimensional concept spaces. By probing these spaces under controlled input uncertainty—including pure noise and structured perturbations—they reveal that transformers impose coherent semantic structure even on semantically void inputs. The study further demonstrates that the activation patterns of these internal concepts are predictive of hallucination risk in model outputs, and that targeted suppression of specific concepts can reduce hallucination rates. These findings have direct implications for model interpretability, alignment, and safety.
The core methodological innovation is the use of SAEs to map transformer residual stream activations into a sparse, overcomplete basis of semantic concepts. The SAE is trained to reconstruct the original activation vector x∈Rdmodel as a sparse linear combination of learned direction vectors di:
x≈i∑fi(x)di+b
where fi(x) are non-negative, sparse activations, and b is a bias term. The loss function combines L2 reconstruction error with L1 sparsity regularization. SAEs are trained on activations from both natural and perturbed (including pure noise) inputs, across all layers of several transformer architectures (e.g., CLIP ViT-B/32, Pythia-160m, Gemma 2B-IT).
The workflow for evaluating hallucination risk and concept emergence is illustrated in Figure 1.
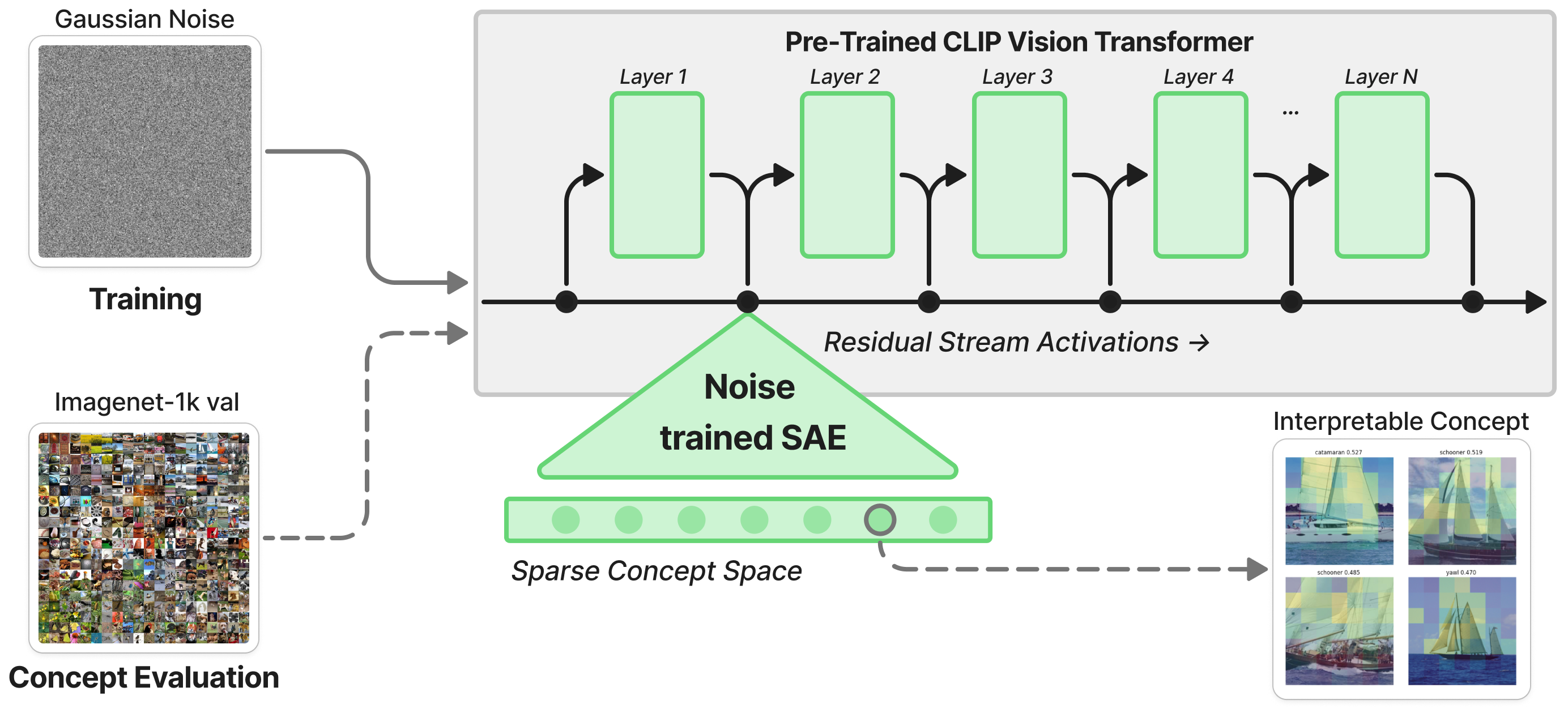
Figure 1: Workflow for examining hallucination risk in each transformer layer by training SAEs on residual stream activations from pure noise and probing with natural images.
Emergence of Semantic Concepts from Noise
A central empirical finding is that, when presented with pure Gaussian noise, pre-trained vision transformers (e.g., CLIP ViT-B/32) exhibit robust, highly interpretable concept activations in their intermediate layers. SAEs trained on noise activations, when probed with natural images, identify features that correspond to coherent semantic categories—despite never being exposed to real data during training. The semantic purity of these features is quantified by the clustering of CLIP-derived text labels for maximally activating images, with many features exceeding a strict threshold (cosine similarity > 0.75).

Figure 2: Top-activating ImageNet images for semantic concepts defined by a noise-trained SAE at layer 9 of a CLIP vision transformer, showing high semantic consistency.
Notably, a subset of these concepts is steerable: injecting the corresponding direction vector into the residual stream of a neutral input can causally induce the model to predict the associated semantic label. This demonstrates that the emergent concepts are not only interpretable but also functionally actionable within the model.
Layerwise Dynamics and Conceptual Wandering
Analysis across layers reveals a three-phase pattern in concept emergence and overlap:
- Early layers: High overlap in concepts across SAE initializations, reflecting low-level, input-driven features.
- Middle layers: Sharp drop in concept overlap and a dramatic increase in the number of active concepts (L0 norm), indicating stochastic exploration and "conceptual wandering" as the model imposes structure on ambiguous inputs.
- Late layers: Partial reconvergence to a stable set of high-level features.
This pattern is robust to both vision and language modalities and is accentuated as input structure is degraded (e.g., by patch or n-gram shuffling). The number of active concepts peaks in the middle layers under high input uncertainty, contrary to the expectation that less structured inputs would yield fewer concepts.
Predicting and Suppressing Hallucinations via Concept Activations
The study establishes a direct, quantitative link between the constellation of concept activations in the input and the hallucination propensity of the model's output. Using Gemma 2B-IT, the authors prompt the model to summarize long-form texts and score the outputs for hallucination using HHEM-2.1. Partial least squares (PLS) regression is then fit to predict hallucination scores from SAE concept activations at each layer.
The predictive power is maximized in intermediate layers (e.g., layer 13, R2=0.271±0.010), with later layers showing no predictive capacity above chance. For binary classification (above/below median hallucination), mean accuracy reaches 73.0%±5.3%.
Crucially, suppressing the top 10 hallucination-associated concepts (as identified by PLS variable importance) in the residual stream of layer 11 leads to a mean reduction in hallucination score of 0.19 in the most hallucinated quartile of examples. This demonstrates a primitive but effective mechanism for causal intervention on model behavior via internal concept manipulation.
Implications and Theoretical Significance
The findings challenge the assumption that transformer representations are strictly input-driven, revealing a strong inductive bias toward imposing semantic structure even in the absence of meaningful input. This has several implications:
- Interpretability: The approach provides a scalable, dataset-independent framework for surfacing and quantifying internal model biases and failure modes.
- Alignment and Safety: The ability to predict and suppress hallucinations via concept activations opens new avenues for model alignment and risk monitoring.
- Adversarial Robustness: The expansion of concept usage under input uncertainty suggests a potential attack surface for adversarial manipulation.
- Generalization: The consistency of results across modalities and architectures suggests that these phenomena are fundamental to transformer-based models.
Limitations and Future Directions
While the study covers a range of model sizes and modalities, it remains to be seen how these results extrapolate to the largest frontier models. The reliance on SAEs, while empirically validated, is not a guarantee of perfect interpretability. Further work is needed to refine concept extraction methods, extend the approach to more complex tasks, and develop real-time hallucination monitoring and mitigation strategies for deployed systems.
Conclusion
This work provides a rigorous, quantitative framework for tracing the origins of hallucinations in transformer models by linking internal concept activations to output faithfulness. The demonstration that transformers impose semantic structure on noise, and that this structure predicts and can be used to suppress hallucinations, represents a significant advance in mechanistic interpretability. These insights lay the groundwork for principled monitoring, diagnosis, and intervention in transformer-based AI systems, with broad implications for safety, alignment, and robust deployment.