TokenGS: Decoupling 3D Gaussian Prediction from Pixels with Learnable Tokens
Abstract: In this work, we revisit several key design choices of modern Transformer-based approaches for feed-forward 3D Gaussian Splatting (3DGS) prediction. We argue that the common practice of regressing Gaussian means as depths along camera rays is suboptimal, and instead propose to directly regress 3D mean coordinates using only a self-supervised rendering loss. This formulation allows us to move from the standard encoder-only design to an encoder-decoder architecture with learnable Gaussian tokens, thereby unbinding the number of predicted primitives from input image resolution and number of views. Our resulting method, TokenGS, demonstrates improved robustness to pose noise and multiview inconsistencies, while naturally supporting efficient test-time optimization in token space without degrading learned priors. TokenGS achieves state-of-the-art feed-forward reconstruction performance on both static and dynamic scenes, producing more regularized geometry and more balanced 3DGS distribution, while seamlessly recovering emergent scene attributes such as static-dynamic decomposition and scene flow.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “TokenGS: Decoupling 3D Gaussian Prediction from Pixels with Learnable Tokens”
Overview
This paper is about building 3D scenes from a few ordinary photos, quickly and automatically. The authors use a technique called “3D Gaussian Splatting,” which represents a scene as a cloud of tiny, colored blobs (Gaussians) that you can render from different viewpoints. Their main idea, called TokenGS, makes this process smarter and more flexible by predicting where those blobs should be in 3D space directly, instead of tying them to the exact pixels of the input images.
Key Questions
The paper focuses on solving three practical problems in fast, feed-forward 3D reconstruction:
- Can we predict 3D points directly, without forcing them to lie along the camera’s sight lines (like laser beams)? This helps correct wonky camera poses and fill in hidden parts of the scene.
- Can we avoid making one blob per image pixel? That old habit creates millions of blobs, even for simple scenes, making the model heavy and redundant.
- Can we improve the scene at test time (when you run the model) without breaking what the model already learned? Directly tweaking all blob settings often hurts the overall structure.
How the Method Works (in simple terms)
Think of the 3D scene as a cloud of tiny paint dots in space. Each dot has:
- A position (where it is),
- A color,
- A size and shape,
- How see-through it is,
- A rotation.
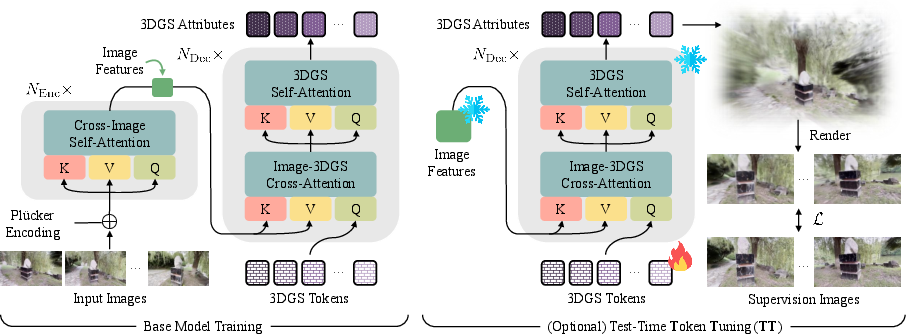
TokenGS predicts these dots using an “encoder–decoder” design, which you can imagine as:
- The encoder: Like a careful reader, it looks at the input photos and camera information, and summarizes them into compact “image features.”
- The decoder: Like a team of smart builders, it holds a fixed set of “tokens” (learnable placeholders) that decide where to place the dots and what they look like. These tokens cross-attend to the image features to gather clues before producing the final dots.
Key ingredients explained in everyday language:
- Direct 3D prediction: Instead of guessing “how far along each camera ray” the dots are, the model guesses their 3D coordinates directly. This lets it fix small camera mistakes and fill in areas you can’t see from the input photos.
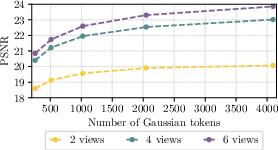
- Learnable tokens: Imagine the tokens as little specialists. Each token focuses on certain parts of the scene and produces a bundle of dots. The total number of tokens (and dots) is a knob you can set, independent of the number of input pixels or photos.
- Visibility loss: During training, some dots might drift far away where no camera can see them. The visibility loss acts like a gentle nudge, pulling those dots back into at least one camera’s field of view so they receive helpful feedback.
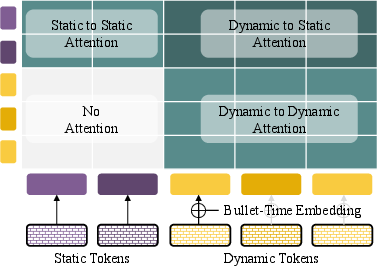
- Dynamic scenes (moving stuff): There are “static” tokens for things that don’t move (like walls) and “dynamic” tokens with a time stamp (like cars). Dynamic tokens can look at static tokens but not the other way around, encouraging a clean separation of “what” and “how it moves.”
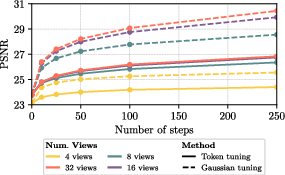
- Test-time scaling: Two simple ways to get better results when you run the model:
- Give it more input views (“context extension”), which helps it fill gaps.
- Do tiny updates to the tokens only (“token tuning”), which adapts the attention patterns to your specific scene while keeping the model’s general knowledge intact.
Main Findings and Why They Matter
The authors tested TokenGS on popular datasets of indoor/outdoor scenes and dynamic (moving) scenes. In short:
- Cleaner geometry: Predicting 3D coordinates directly removes “spiky” artifacts seen in pixel-aligned methods and produces more regular, balanced dot distributions.
- Fewer unnecessary dots: Because dots aren’t tied to pixels, the model uses them where they’re most needed, which can reduce redundancy and improve efficiency.
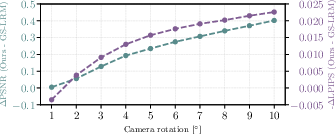
- Better at handling camera pose noise: If the camera angles or positions are a bit off, TokenGS still reconstructs the scene well, and the advantages grow as the noise increases.
- View extrapolation: It can render viewpoints beyond the input cameras more reliably, even without extra ground-truth 3D labels.
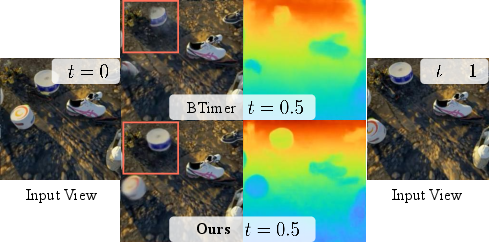
- Dynamic scenes: The time-aware tokens help separate static parts from motion and produce smoother object movement over time (the model can reveal “scene flow,” which is how things move in 3D).
- Test-time improvements: Adding more input views or lightly tuning the tokens boosts quality without harming the model’s learned prior knowledge.
These results show not just strong numbers, but practical robustness: the method does well across static and dynamic scenarios, and it adapts gracefully when conditions change.
Implications and Impact
TokenGS offers a flexible and efficient way to turn a handful of photos into a workable 3D model. That’s valuable for:
- AR/VR experiences (building accurate environments),
- Film and game production (fast scene capture),
- Robotics and autonomous navigation (understanding 3D space),
- Digital twins and mapping (reconstructing real-world spaces).
Beyond this specific technique, the paper highlights a useful idea: decoupling the 3D prediction from image pixels and using learnable tokens to control output size and quality. It shows that small test-time adjustments (especially token tuning) can improve results without harming the model’s general skills, pointing toward smarter and safer ways to refine large vision models in the wild.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and unresolved questions that future work could address:
- Perceptual fidelity gap: Despite PSNR/SSIM gains, LPIPS is consistently worse than strong baselines (e.g., on RE10K and DL3DV, and especially for dynamic scenes). What loss designs (e.g., perceptual, adversarial, anti-aliasing) or appearance models are needed to improve texture realism without harming geometry?
- Dynamic-scene generalization: Dynamic evaluation is limited to synthetic Kubric; robustness to real, complex nonrigid motion, occlusions, and long sequences is untested. How well do dynamic tokens scale to real-world videos with challenging motion and lighting?
- Lack of quantitative motion/flow evaluation: Emergent scene flow is only visualized. Can the method be benchmarked on datasets with ground-truth flow/trajectories and evaluated for object permanence and identity consistency over time?
- Limited camera-noise robustness study: Robustness is demonstrated only for single-view rotational perturbations up to 10°; effects of translational errors, intrinsics miscalibration, multi-view inconsistent noise, rolling-shutter, and outlier poses remain unknown.
- No joint pose refinement: The pipeline assumes given (possibly noisy) cameras and does not perform joint camera optimization. Can token-based reconstruction be coupled with self-supervised pose refinement or bundle-adjustment-like updates?
- Visibility loss design: The visibility regularizer ignores depth sign and near/far clipping (e.g., points behind the camera may still project “inside” the image) and does not reason about occlusions. What is the impact of adding z>0 constraints, frustum distance penalties, or differentiable occlusion-aware visibility terms?
- Hyperparameter sensitivity of visibility loss: The clipping threshold and weight λ_vis are heuristic; ablations on sensitivity and generality across datasets are missing. How do different formulations (e.g., soft-min, temperature-scaled soft visibility) affect convergence and out-of-frustum artifacts?
- Token allocation and adaptivity: The number of tokens (and 64 Gaussians per token) is fixed a priori. How to learn per-scene adaptive token counts, variable token-to-Gaussian multiplicity, and token splitting/merging for better complexity matching and efficiency?
- Coverage/repulsion priors: There is no explicit mechanism to avoid token/Gaussian collapse or to ensure spatial coverage. Can diversity/repulsion/entropy regularizers or coverage objectives reduce clumping and improve scene completeness?
- Test-time tuning (TT) scalability and control: TT requires dozens to hundreds of steps and lacks an early-stopping criterion. What schedules, trust-region constraints, or stopping rules balance gains vs. overfitting and compute, and how do they generalize across view counts and datasets?
- Joint TT of tokens and Gaussians: The paper notes that joint token and Gaussian optimization is left for future work. What stable strategies (e.g., alternating updates, regularized Gaussian tuning, or proximal objectives) preserve priors while capturing fine details?
- Context-length scaling limits: Decoder benefits up to ~4× more views than training, but behavior for larger contexts (e.g., 16–32 views) at high resolutions is untested. What are the memory/latency trade-offs and failure modes with very long contexts?
- Large-scale scene robustness: The method reportedly struggles with large environments and fine detail; no evaluation on large-scale benchmarks (e.g., outdoor scans, long trajectories). What architectural or hierarchical extensions enable city/block-scale scenes?
- Single-view generalization in the wild: Aside from an Objaverse study, there is no real-world single-view evaluation. How does the method perform under truly underconstrained settings, and what priors improve hallucination vs. realism trade-offs?
- Lack of 3D geometry metrics: Claims of “cleaner geometry” are supported by renderings but not by geometric metrics (e.g., depth error, Chamfer distance, normal consistency) on datasets with ground-truth geometry. Can geometric accuracy be quantified and optimized?
- Appearance and lighting modeling: The use of per-Gaussian color without view-dependent effects or lighting limits realism. Can view-dependent appearance (e.g., SH, MLPs) or simple lighting models be integrated without hurting feed-forward speed?
- Handling non-Lambertian phenomena: Reflective, transparent, and specular surfaces are not evaluated; how robust is the method to these materials, and what priors or supervisory signals are needed?
- Scale normalization and metric ambiguity: Training uses dataset-specific rescaling of camera translations; the approach to unknown metric scale at test time is unclear. Can the model learn scale-invariant priors or auto-calibrate scene scale?
- Photometric inconsistencies: Robustness to exposure/white-balance changes, motion blur, and sensor noise is not quantitatively studied. Do augmentations or photometric-invariance objectives improve stability?
- Token specialization control: Token “slot” specialization emerges but is not enforced or leveraged. Can token roles be made interpretable or constrained (e.g., by region, depth bands, semantics) to improve controllability and efficiency?
- Ablations on stability tricks: Training relies on LayerScale, QK-normalization, and removing the final LN, but their contributions are not quantified. Which components are critical across datasets and scales, and why?
- Fairness of GS budget comparisons: Comparisons vary in the number of Gaussians across methods; a controlled study at equal GS budgets is limited. How do relative advantages change under fixed compute/GS budgets?
- Renderer and anti-aliasing: Rendering supervision uses MSE+SSIM without explicit anti-aliasing or prefiltering; how much do aliasing artifacts affect gradients and final texture sharpness?
- Integration with semantics and downstream tasks: The framework yields token-structured 3DGS but does not leverage semantic priors or support tasks like segmentation or tracking. Can semantic conditioning or multi-task training improve both geometry and utility?
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today by leveraging TokenGS’s feed‑forward 3D Gaussian Splatting (3DGS) with learnable tokens, direct 3D mean regression, visibility regularization, and test‑time token tuning (TT).
- Rapid room and property scanning
- Sectors: Real estate, proptech, facilities management
- What: Generate compact 3D walkthroughs of interiors from a handful of photos; adjust Gaussian count (quality vs size) and refine with token tuning for difficult views; robust to mild pose noise; supports view extrapolation for occluded zones.
- Tools/Workflow: Mobile capture (ARKit/ARCore for poses) → TokenGS inference (edge or cloud) → 3DGS web viewer/engine integration → optional TT for final polish → publish link/asset.
- Assumptions/Dependencies: Requires posed multiview images (ARKit/ARCore, SfM like COLMAP); GPU for inference and TT; scenes are room‑scale; 3DGS renderer in the target app.
- On‑set previsualization and set capture
- Sectors: Media & entertainment, VFX, virtual production
- What: Build scene proxies on‑set from a few camera angles; decoupled tokens provide compact, artifact‑reduced geometry for layout, blocking, and camera planning; view extrapolation helps plan unseen shots.
- Tools/Workflow: Multicam stills → TokenGS → UE/Unity/Blender 3DGS plugin for previz → optional TT for hero areas.
- Assumptions/Dependencies: Poses from survey or calibration; GPU workstation; moderate scene scale; quality below full per‑scene optimization in fine details.
- Fast e‑commerce/product digitization
- Sectors: Retail, 3D asset marketplaces
- What: Turntable or handheld captures become high‑quality 3D models with balanced splat distributions; independent control of Gaussian count for SKU‑specific size/performance targets.
- Tools/Workflow: Turntable photos (known/estimated poses) → TokenGS → export 3DGS for web viewer or convert to meshes if needed → batch TT for top‑selling items.
- Assumptions/Dependencies: Controlled lighting/poses improve fidelity; GPU resources; conversion to mesh may require additional processing if needed by downstream tools.
- AR/VR environment occlusion and placement
- Sectors: Consumer AR, enterprise AR, education
- What: Quickly reconstruct surroundings for occlusion/physics proxies and precise virtual object placement; robustness to pose noise aids handheld capture.
- Tools/Workflow: ARKit/ARCore pose streams → TokenGS inference on device or tethered edge → 3DGS‑based occlusion → optional TT for stationary scenes.
- Assumptions/Dependencies: On‑device acceleration may be limited; edge compute recommended; stable tracking for poses.
- Robotics map initialization and update
- Sectors: Robotics, logistics, warehouse automation
- What: Use TokenGS to rapidly initialize a compact 3D map from sparse RGB views; static/dynamic decomposition helps separate persistent structure from moving objects; TT refines with incremental observations.
- Tools/Workflow: Multi‑view images + odometry/VO poses → TokenGS → integrate 3DGS into planning or convert to occupancy/ESDF → periodic TT or context extension as more views arrive.
- Assumptions/Dependencies: Requires approximate poses; real‑time constraints may restrict TT frequency; integration with existing SLAM requires adapters.
- Aerial/ground inspection and AEC site updates
- Sectors: Construction, infrastructure, energy
- What: Produce quick reconstructions for progress tracking or defect triage from a few drone/ground photos; view extrapolation helps in lightly observed areas; tune Gaussian count by task (preview vs detailed check).
- Tools/Workflow: Drone imagery with RTK/PPK or SfM poses → TokenGS → cloud viewer or BIM overlay → TT for critical zones.
- Assumptions/Dependencies: Pose accuracy, repetitive textures, and scale variations may affect quality; GPU backend; integration with BIM viewers.
- Education and rapid prototyping for 3D vision
- Sectors: Academia, edtech
- What: Demonstrate modern 3D reconstruction without depth labels using self‑supervised rendering; explore token specialization, context extension, and token‑only TT.
- Tools/Workflow: Course labs with open datasets (RE10K/DL3DV) → TokenGS training/inference notebooks → compare pixel‑aligned vs tokenized outputs.
- Assumptions/Dependencies: GPU availability; prepared datasets; didactic tools for 3DGS visualization.
- Insurance and claims triage
- Sectors: Insurance, finance, risk assessment
- What: Adjusters capture a few photos to generate a navigable 3D scene for remote assessment; token tuning used to refine damaged regions; robust to mild pose errors from handheld capture.
- Tools/Workflow: Mobile capture → automatic pose estimation → TokenGS cloud inference → secure viewer for assessors → optional TT on sensitive areas.
- Assumptions/Dependencies: Privacy/consent for interior capture; sufficient lighting; backend GPU resources.
- Cultural heritage artifact capture
- Sectors: Museums, archiving, education
- What: Quickly digitize small artifacts with sparse views; tokenized decoupling assigns Gaussians to complex regions for better preservation of geometry.
- Tools/Workflow: Turntable/light‑box capture → TokenGS → curation viewer → optional TT for fine details.
- Assumptions/Dependencies: Quality of poses and imaging; less suitable for very high‑relief microgeometry without additional capture.
- Bandwidth‑aware 3D content delivery
- Sectors: Web platforms, gaming, streaming
- What: Serve 3DGS at adjustable fidelity by varying token/Gaussian count; enable fast previews and progressive refinement on the client via TT or context extension.
- Tools/Workflow: Server‑side TokenGS export with multiple fidelity tiers → client 3DGS viewer → optional client‑side TT for close‑up views.
- Assumptions/Dependencies: 3DGS runtime on web/engine; GPU or efficient splatting on client devices.
Long‑Term Applications
These require further research, scaling, or productization beyond the current paper’s scope (e.g., larger scenes, real‑time constraints, mobile efficiency, or expanded sensor setups).
- Real‑time 4D volumetric capture and free‑viewpoint video
- Sectors: Sports broadcasting, live events, telepresence
- What: Use dynamic tokens for continuous motion, enabling bullet‑time and in‑between view synthesis; stream 3DGS over the network for live free‑viewpoint experiences.
- Tools/Workflow: Multi‑camera rigs with synchronized timestamps → TokenGS dynamic inference → low‑latency 3DGS streaming → client‑side rendering and optional TT.
- Assumptions/Dependencies: Tight time sync and robust multi‑view poses; significant compute; optimized streaming formats for 3DGS.
- Dynamic scene perception for autonomous systems
- Sectors: Autonomous driving, mobile robotics
- What: Leverage static/dynamic decomposition and emergent scene flow for mapping, motion forecasting, and planning from RGB; integrate with multi‑sensor stacks.
- Tools/Workflow: Cameras (+ IMU/LiDAR for pose priors) → TokenGS + fusion → planners consume static maps and dynamic object flows.
- Assumptions/Dependencies: Scalability to outdoor, long‑range, high‑speed conditions; sensor fusion; safety‑critical verification.
- City‑scale digital twins with hierarchical tokens
- Sectors: Smart cities, utilities, GIS
- What: Extend token‑based 3DGS to large‑scale mapping using hierarchical or streaming tokens and chunked training/inference.
- Tools/Workflow: Aerial/ground fleets → partitioned TokenGS pipelines → tiled 3DGS storage and streaming → progressive LoD.
- Assumptions/Dependencies: Research on hierarchical tokenization and memory; large‑scale pose estimation; data governance.
- On‑device mobile 3D capture with privacy preservation
- Sectors: Consumer apps, privacy tech
- What: Compress token embeddings and perform token‑only TT on‑device to avoid uploading imagery; share only compact 3DGS or tokens.
- Tools/Workflow: Efficient TokenGS variants (quantization, distillation) → mobile NN accelerators → secure token exchange.
- Assumptions/Dependencies: Model compression and fast splatting on mobile GPUs/NPUs; power/thermal constraints.
- Interactive region‑aware editing via token control
- Sectors: DCC tools (Blender/Maya), game dev
- What: Exploit token specialization to let users select/edit regions (geometry, color, opacity) by manipulating token embeddings or assignments.
- Tools/Workflow: DCC plugin exposing token handles → interactive re‑decoding/TT for local edits → export back to engine.
- Assumptions/Dependencies: UI/UX for token‑region mapping; stable, interpretable token assignments across edits.
- Standardization and streaming formats for 3DGS
- Sectors: Standards bodies, cloud platforms, ISVs
- What: Define interoperable 3DGS containers with token metadata, LoD tiers, and TT hooks for client adaptation; enable CDN‑friendly delivery.
- Tools/Workflow: Open format proposals, reference decoders, engine integrations; token‑aware streaming APIs.
- Assumptions/Dependencies: Ecosystem adoption; performance parity with established mesh/point‑cloud formats.
- Text‑ and task‑conditioned 3D reconstruction
- Sectors: Generative design, robotics, education
- What: Condition token decoding with language or task cues (e.g., “prioritize furniture surfaces”); guide allocation of Gaussians to task‑critical regions.
- Tools/Workflow: Multimodal encoder (text+image) → TokenGS decoder → task‑aware TT.
- Assumptions/Dependencies: Multimodal training data; alignment techniques; evaluation for task utility.
- Few‑shot domain adaptation via token tuning
- Sectors: Medical, industrial inspection, underwater, aerial
- What: Use token‑only TT to adapt to specialized domains with minimal data, preserving global priors while aligning to new appearance/geometry distributions.
- Tools/Workflow: Collect small in‑domain multiview sets → TT only tokens → deploy adapted model for that domain.
- Assumptions/Dependencies: Domain‑shift robustness; posed images in niche environments (e.g., endoscopy rigs, borescopes).
- Policy frameworks for responsible 3D capture
- Sectors: Public policy, compliance, enterprise governance
- What: Establish consent, privacy, and energy‑use guidelines for rapid scene capture and 3D sharing; encourage on‑device TT to limit data transfer.
- Tools/Workflow: Organizational policies, consent flows in capture apps, audit logs for reconstructions, redaction pipelines.
- Assumptions/Dependencies: Cross‑jurisdictional legal alignment; standardized privacy labels for 3D assets.
- Edge‑friendly robotics via distillation and sensor fusion
- Sectors: Drones, inspection robots, agriculture
- What: Distill TokenGS into compact models and fuse with IMU/LiDAR to run on embedded platforms for fast scene reconstruction and updating.
- Tools/Workflow: Teacher–student distillation, mixed‑precision inference, fusion modules; periodic token refresh from cloud.
- Assumptions/Dependencies: Quality retention under compression; robust fusion algorithms; intermittent connectivity handling.
- Foundation‑scale 3D token models and benchmarks
- Sectors: Academia, AI labs
- What: Train larger tokenized 3D models across diverse datasets; establish benchmarks for dynamic reconstruction, scene flow, view extrapolation, and token interpretability.
- Tools/Workflow: Curated multi‑domain datasets, scalable training with visibility loss, open evaluation suites.
- Assumptions/Dependencies: Data availability and licensing; compute resources; community consensus on metrics.
Notes on feasibility across applications:
- Most workflows require multi‑view images with known or estimated camera intrinsics/extrinsics; TokenGS is more robust to pose noise than pixel‑aligned methods but still depends on reasonable pose quality.
- GPU acceleration is needed for fast inference and token tuning; on‑device/mobile usage will require model compression and optimized splatting.
- 3DGS runtime support (engines, web viewers) is necessary for downstream visualization and interaction.
- Current limitations (noted by the authors) include reduced performance on very large scenes and extremely fine geometric details compared to per‑scene optimization; TT adds latency and compute at inference.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit 3D scene representation that renders images by splatting anisotropic Gaussians in space. "TokenGS is a feed-forward reconstruction framework that outputs a 3D Gaussian Splatting (3DGS) representation from posed input images."
- AdamW: An optimizer that decouples weight decay from the gradient-based update, improving generalization. "We optimize the model with AdamW~\cite{loshchilov2017decoupled} optimizer."
- Attention mask: A constraint applied to attention mechanisms that limits what tokens can attend to, encoding structure (e.g., causality). "We impose a structured attention mask over the combined token set"
- Bullet-time reconstruction: A dynamic-scene setup where the model reconstructs a scene at a specific timestamp across multiple views. "following a bullet-time reconstruction formulation~\cite{liang2024feed}."
- Canonical coordinate space: A global, view-independent 3D coordinate frame in which scene elements are predicted. "we directly regress 3D Gaussian means in a canonical coordinate space"
- Camera frusta: The pyramidal volumes of space visible to cameras; points outside receive no image supervision. "Gaussians that lie outside all camera frusta do not contribute to the rendered supervision images"
- Causal structure (in attention): An attention pattern where certain tokens can only attend in a single direction (e.g., dynamic to static) to enforce temporal or structural causality. "we impose a causal structure where the dynamic tokens can only attend/query unidirectionally to the static tokens."
- Chamfer distance: A set-to-set distance often used to supervise unordered 3D point predictions by matching to ground-truth points. "necessitating a Chamfer or similar distance for supervision, which adds further complexity."
- Context extension: A test-time scaling strategy that improves performance by providing more input views than used in training. "The first, context extension, is achieved by supplying more image tokens at inference time than were used during training"
- Cross-attention: An attention mechanism that lets one set of tokens query another set (e.g., Gaussian tokens query image tokens). "consisting of (i) cross-attention to the image tokens "
- DETR: A Transformer-based object detection architecture using learnable queries; here it informs the decoder design. "Our decoder follows the DETR design~\cite{carion2020end}."
- Encoder–decoder architecture: A Transformer design that encodes inputs into latent tokens and decodes outputs using learned queries. "move from the standard encoder-only design to an encoder-decoder architecture with learnable Gaussian tokens"
- Encoder-only Transformer: A Transformer comprising only self-attention layers on input tokens, without a separate decoder. "using a large encoder-only Transformer backbone to predict pixel-aligned 3D Gaussian primitives"
- Feed-forward reconstruction: Inferring a 3D scene in a single network pass without per-scene optimization. "Feed-forward reconstruction methods infer 3D scenes directly from input images in a single forward pass."
- FlashAttention2: A memory-efficient attention algorithm for faster and scalable Transformer training/inference. "We use FlashAttention2~\cite{dao2023flashattention} and FlexAttention~\cite{he2024flexattention} for attention and masked attention computation."
- FlexAttention: A flexible attention kernel enabling custom attention patterns (e.g., masks) efficiently. "We use FlashAttention2~\cite{dao2023flashattention} and FlexAttention~\cite{he2024flexattention} for attention and masked attention computation."
- Gaussian tokens (learnable): Learnable embeddings that each decode to a group of Gaussians, decoupling outputs from image pixels. "learnable 3DGS tokens cross-attend to the multi-view image tokens"
- Hash-grid encodings: A compact multi-resolution grid encoding for neural fields that accelerates learning of high-frequency details. "or hash-grid encodings~\cite{muller2022instant}"
- Key–value projections (in attention): The linear projections that produce key/value tensors used by attention; sharing them reduces memory. "all decoder cross-attention layers share their keyâvalue projections of image tokens."
- LayerScale: A stabilization technique that scales residual branches with learnable per-layer factors. "For both the encoder and the decoder, we use LayerScale~\cite{touvron2021going} and QK-normalization~\cite{henry2020query}"
- LPIPS: A learned perceptual similarity metric used to evaluate image quality from a human-perception standpoint. "we show the difference to GS-LRM~\cite{zhang2025gs} in terms of PSNR and LPIPS."
- NeRF (Neural Radiance Fields): A neural representation modeling 3D scenes as volumetric radiance fields for photorealistic rendering. "neural radiance fields (NeRF)~\cite{mildenhall2021nerf, barron2023zip}"
- Plücker coordinates: A 6D representation of 3D lines used here to encode viewing rays. "we patchify the Pl\"ucker coordinates associated with each view into a set of patches"
- Point map: A per-pixel prediction of 3D point coordinates in a global frame, often used in SfM contexts. "point map prediction in feed-forward Structure-from-Motion (SfM) models such as VGGT~\cite{wang2025vggt}"
- Point map supervision loss (PM-Loss): A loss that supervises predicted 3D point maps directly against ground-truth point coordinates. "Ours outperforms models finetuned with PM-Loss~\cite{shi2025revisiting}, a point map supervision loss."
- PSNR: A signal fidelity metric (in dB) measuring reconstruction quality by comparing pixel-wise differences. "we show the difference to GS-LRM~\cite{zhang2025gs} in terms of PSNR and LPIPS."
- QK-normalization: A technique that normalizes queries and keys to improve attention stability. "For both the encoder and the decoder, we use LayerScale~\cite{touvron2021going} and QK-normalization~\cite{henry2020query}"
- Quaternion (unit quaternion): A 4D unit-length representation of 3D rotations, avoiding gimbal lock. "rotation represented as a unit quaternion ."
- Scene flow: The 3D motion field of points in a dynamic scene across time. "such as static-dynamic decomposition and scene flow."
- SE(3): The Lie group of 3D rigid motions (rotations and translations), used to represent camera extrinsics. "the corresponding camera extrinsics "
- Self-attention: An attention mechanism where tokens attend to each other within the same sequence. "referring to a sequence of self-attention layers as in \cite{dosovitskiy2020image}."
- Self-supervised rendering loss: A training signal derived from rendering consistency without explicit 3D ground truth. "only a self-supervised rendering loss."
- Sinusoidal encoding: A positional/time embedding using sine/cosine functions to represent continuous variables. "where represents sinusoidal encoding which gets linearly projected to the latent space."
- Slot specialization: The emergent tendency of learnable slots/tokens to focus on consistent subparts across data. "a phenomenon similar to slot specialization reported in~\cite{carion2020end}."
- SSIM: A structural similarity metric assessing perceived image quality by comparing luminance, contrast, and structure. "a combination of pixel-wise mean squared error and SSIM losses"
- Structure-from-Motion (SfM): The process of recovering 3D structure and camera motion from multiple images. "feed-forward Structure-from-Motion (SfM) models such as VGGT~\cite{wang2025vggt}"
- Test-Time Scaling (TTS): Allocating extra compute during inference (e.g., adaptation or more context) to improve performance. "Test-Time Scaling (TTS) refers to allocating additional compute at inference time to improve model performance and robustness under unseen or challenging data distributions."
- Token tuning (TT): A lightweight test-time adaptation that optimizes only token embeddings while keeping network weights fixed. "token-tuning (TT), is a lightweight test-time training procedure"
- Transformer decoder blocks: Stacks of attention and feed-forward layers that decode outputs from encoded inputs using learned queries. "apply Transformer decoder blocks~\cite{vaswani2017attention} consisting of (i) cross-attention to the image tokens , (ii) self-attention among the GS tokens, and (iii) per-token MLP."
- ViT (Vision Transformer): A Transformer architecture that processes images as sequences of patches (tokens). "We use a ViT-based encoder~\cite{dosovitskiy2020image}."
- Visibility loss: A regularizer that encourages predicted 3D elements to project within at least one image view. "we introduce a visibility loss that softly constrains Gaussian particles to remain visible in at least one of the supervision views."
- Volume rendering: Rendering technique that accumulates radiance and transmittance along rays through a volumetric representation. "novel views can be synthesized through volume rendering~\cite{mildenhall2021nerf, kerbl20233d}."
Collections
Sign up for free to add this paper to one or more collections.