- The paper introduces a causal framework that uses agentic microphysics to link local interaction rules with emergent collective risks in AI systems.
- It employs controlled multi-agent simulations to pinpoint how factors like positional influence and social proof drive herding dynamics in LLM environments.
- The study outlines actionable interventions by adjusting protocol designs and memory regimes to mitigate emergent failures in multi-agent settings.
Agentic Microphysics as a Causal Framework for Generative AI Safety
Motivation for a Microphysical Approach to Multi-Agent AI Risks
Contemporary agentic AI systems increasingly exhibit features such as tool use, persistent identity, planning, and long-lived goal pursuit, resulting in complex population-level dynamics that cannot be explained by analyzsing the isolated capabilities or outputs of standalone models. The paper "Agentic Microphysics: A Manifesto for Generative AI Safety" (2604.15236) proposes a methodological shift: from model-centric safety towards a framework grounded in the explicit causal study of local interaction structures—termed "agentic microphysics"—and a generative, mechanism-based methodology for safety analysis and intervention. This framework aims to systematically bridge the micro-level interaction rules among agents and the macro-level risks that arise in multi-agent environments.
Limitations of Existing Taxonomic and Observational Frameworks
Traditional safety analysis in AI predominantly addresses risks at the agent level: e.g., misalignment, inadvertent deception, sycophancy, and in-context scheming. With the rise of multi-agent collectives, emergent phenomena such as collusion, information cascades, conformity, and coordinated failure manifest not as simple aggregates of individual agent failures but as products of recurrent inter-agent dynamics. Existing responses to these emergent risks are largely taxonomic (classifying higher-order failure modes and recurrent risk factors) or observational (documenting the collective behaviors in simulated agent societies). However, these approaches do not reveal which precise interaction topologies, protocol affordances, or environmental configurations are causally sufficient for risk emergence or which design interventions can eliminate them. Thus, a more mechanistic, generative approach is required.
Agentic Microphysics: The Level of Causal Analysis
Agentic microphysics formalizes the study of safety-relevant phenomena as micro-to-macro mechanisms operating in multi-agent populations. At this level, the explanatory focus is on how exposure, adaptation, protocol structure, and environment-specific affordances mediate the flow of influence and information: for instance, how memory regimes, action timing (sequential vs. simultaneous), observable signals, and communication graphs create feedback loops that can amplify or dampen collective risk phenomena. Crucially, many architectural variables—such as visibility, communication protocol, and privilege—are controllable design parameters in artificial environments.
A rigorous microphysical model must meet three adequacy criteria:
- Descriptive Adequacy: The model must be able to generate the observed phenomenon through explicit interaction rules.
- Explanatory Adequacy: The model should identify the causal process, not merely fit observed data.
- Observational Adequacy: The model’s generative process must accord with empirical evidence from real or simulated deployments.
These requirements ensure that proposed mechanisms are minimal, causally interpretable, and empirically grounded. The emphasis is on identifying which specific microspecifications (local rules and affordances) suffice to generate and control collective-level failures.
Generative Safety: The Experimental Pipeline
Generative safety extends agentic microphysics into an active methodology. The pipeline involves:
- Risk Identification: Select macro-level target phenomena (collusion, polarization, cascades, etc.).
- Microspecification: Develop testable hypotheses about local interaction rules and environmental parameters sufficient to produce the phenomenon.
- Generative Experimentation: Implement controlled multi-agent simulations, varying micro-level conditions to evaluate sufficiency and thresholds for risk emergence.
- Intervention Design: Use the same environment to develop and test interventions, targeting either model policies or the interaction architecture (e.g., modifying communication protocols, applying runtime governance, or adjusting incentive structures).
- Observational Validation: Compare in silico findings to field data or empirical baselines; iterate on model structure if empirical mismatch is found.
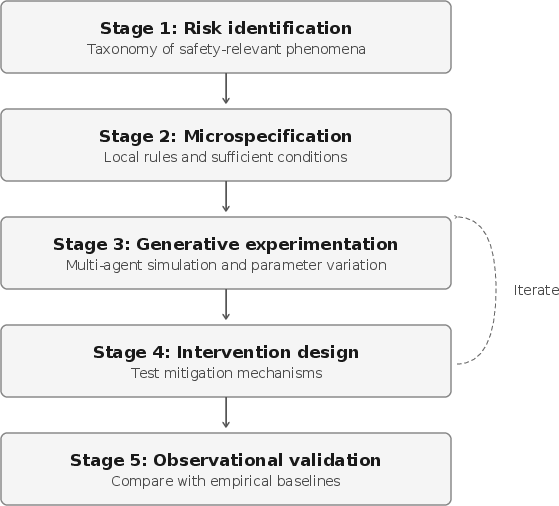
Figure 1: The generative safety pipeline operationalizes agentic microphysics for rigorous identification, testing, and mitigation of collective risks in agentic environments.
This methodology supports both the explanatory function (mechanism validation) and the engineering function (identifying architecture-level interventions with causal efficacy).
Empirical Application: Herding in LLM News-Feed Environments
To demonstrate the generative safety pipeline, the authors detail a microphysical experiment in a multi-agent LLM environment akin to social media. The core question is which interaction features—visible social proof ("likes") vs. feed presentation order—drive herding dynamics in a population of LLM agents:
- Design: Agents browse a fixed set of news items with randomized presentation order and variable exposure to endorsement signals (e.g., visible likes). Endorsement decisions are stateless and dependent only on the current state.
- Findings: Collective attention is governed almost exclusively by item position in the feed, not the absolute number of visible endorsements. Social proof only modulates choices within the (positional-gated) top-ranked subset. Increasing the visible magnitude of endorsements does not systematically increase selection probability beyond a low threshold, and strong social proof is insufficient to compensate for poor position. The mechanism, therefore, is a two-stage process: positional gating defines the choice set, and social proof modulates within that set.
- Implications for Adversarial Action: An adversary could exploit this mechanism not by fabricating endorsements but by manipulating item ranking, thereby inducing large-scale herding even among agents that are individually robust to content-based persuasion or conformity cues.
This case study exemplifies how small, systematically controlled experiments on micro-interaction structure can expose actionable safety vulnerabilities that would be obscured in aggregate observational studies.
Implications and Future Directions
By conceptualizing AI safety in terms of agentic microphysics, risk analysis and mitigation strategies move from the post hoc classification of failures to the principled identification of causal mechanisms and controllable design levers. The explicit emphasis on protocol, memory, and communication structure as sites for intervention suggests a new research agenda focused not only on model alignment but also on the architectural engineering of agentic environments. Generative safety, by requiring mechanistically explicit and empirically calibrated models, provides a robust framework for validation and iterative improvement of safety policies in synthetic societies of increasing scale and complexity.
Adoption of this framework would enable:
- Mechanistic validation of failure modes and intervention efficacy before deployment.
- Systematic design and evaluation of multi-agent protocols for resilience under adversarial or stochastic interaction.
- Integrative comparison with real-world empirical baselines, which is especially important as LLM-based systems are deployed in socio-technical contexts with high-stakes collective behaviors.
Conclusion
"Agentic Microphysics: A Manifesto for Generative AI Safety" (2604.15236) articulates a formal, mechanism-centric research agenda for the study and management of collective risks in agentic AI populations. The generative safety methodology provides a disciplined framework for linking local design choices to global risk outcomes, supporting both theoretical explanation and practical engineering of safe, robust generative AI ecosystems. Future research should extend this pipeline to larger-scale and more heterogeneous environments, and develop automated tools for microphysical diagnosis and protocol adaptation in live agent-based deployments.