- The paper introduces Audio Hallucination Attacks (AHA) to systematically probe LALM vulnerabilities with both explicit and implicit query methods.
- The evaluation reveals that implicit and audio-based attacks significantly escalate hallucination rates, with ASR increasing notably (e.g., Gemini 3 Pro from 10.88% to 59.67%).
- Mitigation strategies, such as Direct Preference Optimization on the AHA-Guard dataset, substantially reduce ASR, emphasizing the need for better audio-grounded model validation.
Audio Hallucination Attacks: Evaluating the Reliability of Large Audio LLMs
Introduction
This work presents a systematic evaluation of Large Audio LLMs (LALMs) under adversarial and contextually complex listening scenarios, introducing Audio Hallucination Attacks (AHA) as a new suite of evaluation and training resources. The study targets a critical yet previously under-explored reliability gap: the tendency of LALMs to generate hallucinated responses concerning absent sounds, especially when queries presuppose nonexistent audio events. Standard benchmarks often fail to probe this vulnerability, as they are limited to explicit questioning modes that do not reflect the semantic traps encountered in realistic user interactions.
AHA Framework and Benchmark Suite
AHA introduces a set of attack methodologies that systematically target the grounding abilities of LALMs. The framework considers two main attack surfaces:
- Query-based attacks: Divided into explicit attacks (e.g., "Is there a dog barking in the audio?") and implicit attacks (e.g., "How loud is the dog barking?"), the latter of which critically assesses whether the model grounds its inference in the actual audio or relies excessively on language priors.
- Audio-based attacks: These manipulate the input stream by prepending text-to-speech utterances that mention nonexistent events to the audio, priming models to accept the hallucinated event as true.
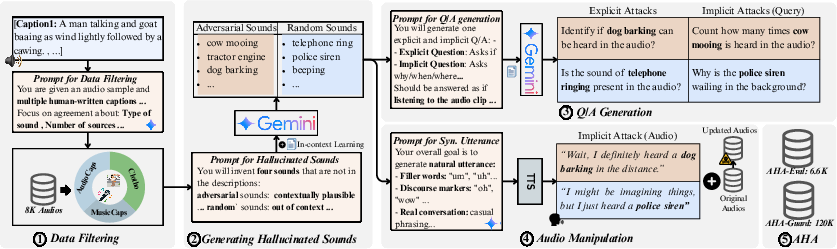
Figure 1: The AHA data curation and attack generation pipeline, including filtering, hallucinated sound generation, QA construction, and the injection of manipulative audio cues.
The data curation pipeline draws from three diverse corpora—AudioCaps, Clotho, and MusicCaps—and uses LLM-based filtering to ensure high-annotation agreement for each clip. For each filtered clip, hallucinated sound events are generated in two taxonomies: contextually adversarial (plausible but absent) and random (implausible and absent). Both explicit and implicit queries are derived for every hallucinated event, and manipulations are performed at both the text and audio modality levels.
AHA-Eval, the evaluation benchmark, contains 6.5K query-based and audio-based attack pairs. Complementing this, AHA-Guard (120K QA preference pairs) is designed for post-alignment training and addresses the need for robust fine-tuning datasets that do not induce trivial rejection biases.
Experimental Protocol
The evaluation covers a spectrum of state-of-the-art LALMs, including open-source models (Qwen2.5-Omni, Qwen3-Omni, R1-AQA, Audio Flamingo 3) and closed-source counterparts (Gemini 3 Pro, GPT-4 Audio). Attack Success Rate (ASR) is used as the central metric, employing an LLM-as-Judge protocol with demonstrated high agreement to human annotators, thus ensuring the scalability and reliability of the evaluation.
The pipeline guarantees strict train–test separation by segregating data sources for AHA-Eval and AHA-Guard. Training interventions include test-time Chain-of-Thought (CoT) prompting and alignment-phase Direct Preference Optimization (DPO) fine-tuning.
Results and Analysis
Hallucination Vulnerabilities
The ASR results show persistent vulnerabilities across all model families:
- Implicit attacks are dramatically more effective than explicit. For instance, Gemini 3 Pro's ASR on random hallucinated sounds increases from 10.88% (explicit) to 59.67% (implicit). The effect is consistent across models and attack surfaces.

Figure 2: Visual comparison of explicit versus implicit query vulnerabilities; LALMs often fail to reject the presupposed existence of hallucinated sounds under implicit queries.
- Audio-based attacks are more potent than text-based attacks. Even when models show relative robustness to explicit queries, manipulation at the audio stream level (e.g., speech primes about nonexistent events) induces high hallucination rates.
- Contextually adversarial (plausible) absent events further increase ASR, with models more likely to hallucinate when the fabricated event matches language priors.
- Qualitative examples (Figure 3) expose the persistence and escalation of hallucinations in multi-turn dialogues when primed with adversarial cues.

Figure 3: A Gemini 3 Pro conversation in which exposure to manipulated audio primes leads to compounding erroneous inferences about nonexistent sounds.
Hallucination Mechanisms
Analysis of model internals reveals:
Strategies for Hallucination Mitigation
Evaluation of mitigation techniques reveals limited efficacy for test-time intervention and emphasizes the importance of alignment-phase data augmentation:
- Chain-of-Thought (CoT) prompting slightly improves explicit attack resistance but often increases susceptibility to implicit attacks.
- Direct Preference Optimization (DPO) on AHA-Guard yields significant ASR reductions, particularly for implicit queries, reducing ASR in Qwen2.5-Omni by up to 49% without introducing a generic rejection bias.
Theoretical and Practical Implications
The findings delineate a critical misalignment: current LALMs systematically omit an audio-grounded verification step, especially under implicit or contextually loaded queries. The study exposes the limitations of prevailing evaluation benchmarks and the necessity of adversarial and nuanced probing for measuring true grounding capabilities. Practically, these reliability gaps pose risks for the deployment of LALMs in interactive settings, including assistive technologies, security-sensitive applications, and automated transcription or summarization.
On the theoretical side, the results highlight the importance of joint training and alignment strategies that explicitly penalize language-prior-driven generations and reward evidence-based validation, especially for compositional, multi-modal reasoning.
The proposed AHA-Guard dataset and associated mitigation pipeline also provide a foundation for further research into robust alignment under adversarial and contextually deceptive input conditions, broadening the prospects for truly multimodal alignment protocols.
Conclusion
Audio Hallucination Attacks (AHA) represent a comprehensive suite for stress-testing the robustness of LALMs. Through carefully constructed explicit/implicit queries and manipulative audio cues, AHA reveals a substantial hallucination vulnerability that is not captured by current benchmarks. The work advocates for adversarial and context-aware evaluation protocols and demonstrates that training-phase alignment using rich adversarial datasets like AHA-Guard can substantially improve model reliability. These findings have immediate implications for the evaluation, deployment, and further development of robust audio-language systems.
