- The paper introduces a modular framework with four layers and a dynamic skill module for decomposing tasks and automated knowledge routing in 6-DoF spacecraft operations.
- It empirically demonstrates mode-specific resilience; notably, under degraded perception, the Prospective mode achieves a 47% search pass rate outperforming other reasoning regimes.
- The study features an innovative self-evolution pipeline that enables post-hoc skill mutation and robust failure recovery, ensuring seamless cross-domain hardware transfer.
Modular and Self-Evolving VLM-Based Framework for On-Orbit Autonomy: An Analysis of "SpaceMind"
Framework Architecture and Technical Innovations
SpaceMind presents a sophisticated modular framework for vision-language agent autonomy, delivering an architecture optimized for 6-DoF spacecraft operations. The framework is organized into four layers: (1) a dynamic skill module layer supporting knowledge decomposition and automatic routing, (2) a VLM-centric decision core leveraging multiple reasoning paradigms, (3) an MCP tool abstraction and Redis-based interface for seamless simulation-to-hardware transfer, and (4) an experience-driven self-evolution pipeline for persistent in-situ knowledge accumulation.
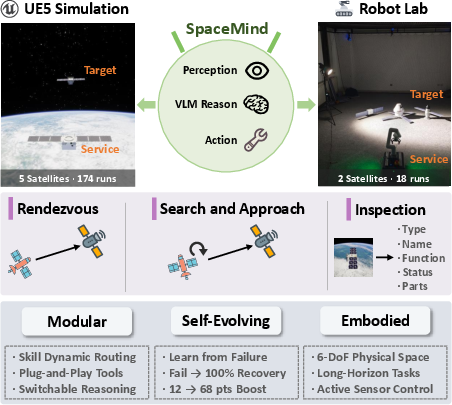
Figure 1: Overview of SpaceMind as a VLM-based control architecture addressing rendezvous, search, and inspection on both simulated and physical satellites.
The skill decomposition is formalized via a tiered taxonomy—core, task, and helper skills—invoked and combined dynamically through an LLM-powered gateway. Tools are declared via Machine Context Protocol profiles that gate agent perception and control affordances. Cross-hardware portability is achieved through a strict decoupling of the decision loop from backend implementation, enforced by Redis message passing adhering to a single communication contract.
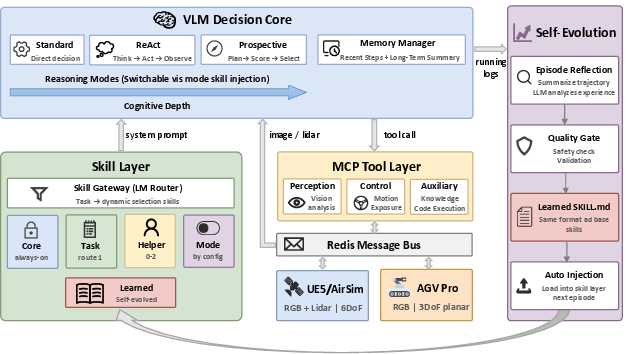
Figure 2: Detailed system architecture illustrating skill routing, reasoning core, tool abstraction, and evolution mechanisms.
Critically, SpaceMind incorporates three distinct reasoning regimes: Standard (direct action), ReAct (tool-use intertwined with chain-of-thought), and Prospective (deliberative candidate-based planning/selection). These modes are modular, activated through specialized prompt injection, and augmented by hierarchical memory structures for trajectory encoding and cross-step context preservation.
Experimental Regime and Empirical Results
The experimental validation is rigorous: 192 closed-loop episodes spanning five satellite platforms, three core tasks (rendezvous, search, inspection), and diverse initial conditions, both in photo-realistic Unreal Engine 5 simulation and on a physical robotic testbed. Tool ablation studies demonstrate that LiDAR range information is necessary for navigation convergence; visual-only profiles exhibit consistent failure, while the addition of runtime code execution yields no marginal gain—agent performance is tool-constrained, not computationally bottlenecked.
The cross-mode, multi-condition benchmarking reveals no universal mode dominance. In nominal cases, all modes achieve ≈100% navigation. Under perceptual degradation (offsets, underexposure), Standard maintains high rendezvous pass rates but fails in search; only Prospective mode demonstrates search-and-approach robustness in degraded contexts, with a search pass rate of 47% versus 27% for Standard and 33% for ReAct.
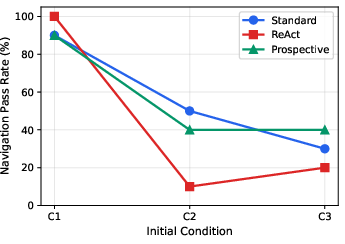
Figure 3: Navigation task pass rate degradation across initial conditions, contrasting reasoning mode resilience.
Inspection tasks reveal a notable pattern: ReAct's early-termination behavior is advantageous under degraded perception by minimizing hallucinated actions, outperforming Prospective in worst-case conditions (score 42.8 vs. 29.8). These results provide strong empirical guidance for reasoning-mode selection policies in real deployments.
Skill Self-Evolution: Autonomous Knowledge Accumulation
SpaceMind’s self-evolution pipeline introduces post-hoc reflection and structured skill mutation, operating entirely outside gradient-based optimization. After each episode, the agent executes a reflection protocol synthesizing trajectory summaries, which are filtered through a quality and safety gate as mutations (new skills, overlays, rewrites, disablements). Approved learned skills are incorporated into subsequent execution cycles via the existing dynamic routing path.
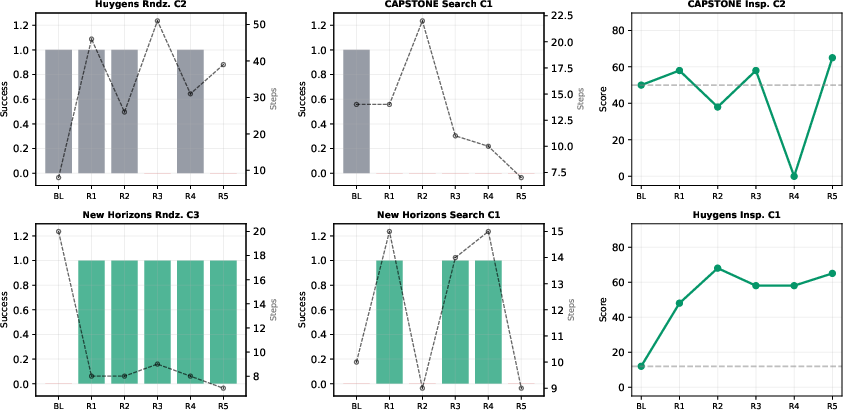
Figure 4: Longitudinal learning curves showing substantial performance recovery resulting from self-evolution-driven skill injection.
This mechanism delivers robust failure recovery even from single negative episodes. For instance, an initial total failure on a rendezvous or search task can, post-evolution, yield sustained 100% or 60% success for the remainder of the trial group, and inspection task scores are observed to increase by 30–467%, verifying the efficacy of structured experience accumulation. The mechanism’s value is restricted for initially successful regimes, echoing results from similar experiential learning approaches but with improved safety and auditability.
Physical System Transfer and Qualitative Behaviors
SpaceMind operates identically on laboratory hardware, requiring only a change in the MCP-Redis backend interface, with zero agent-side code modification. Key behaviors such as environment-specific step size adaptation, persistent skill utilization (e.g., yaw-sweep for target reacquisition), and emergent scale awareness manifest consistently across both simulated and physical domains.

Figure 5: Third-person laboratory-view of a search-and-approach sequence, substantiating cross-environmental behavioral transfer.
The qualitative analysis further underscores active perception control: dynamic adjustment of exposure under poor sensor input, context-driven re-routing behaviors, and the practical efficacy of self-evolved skills for error recovery and plan refinement.








Figure 6: Sensor-perspective visualizations from critical episodes, demonstrating adaptive behavior and the impact of learned skill injection.
Theoretical and Practical Implications
SpaceMind’s design directly addresses the critical challenges of onboard autonomy: modular knowledge scaling, reasoning-depth adaptability, persistent experience-driven improvement, and hardware-agnostic deployment. The hierarchical knowledge + skills paradigm supports rapid task composition and error correction, the multi-reasoning system enables regime-specific optimization, and the self-evolution pipeline extends operational longevity without on-orbit retraining or external supervision.
The results have immediate implications for both terrestrial and aerospace robotics: any system requiring robust, sensor-driven closed-loop control and long-horizon task decomposition can benefit from analogous modular, evolution-capable agent architectures. However, the abstracted 3D spatial reasoning of current VLMs remains a bottleneck under heavy perceptual degradation or unstructured physics, motivating research into task-adapted model pretraining, advanced sensor fusion, and formal assurance frameworks for experience-induced skill mutation.
Conclusion
SpaceMind exemplifies a systematic modularization of vision-language agent intelligence for space autonomy, validated through comprehensive empirical analysis and demonstrating practical self-improvement with explicit safety and transparency controls. The framework is extensible, auditable, and deployable across simulated and physical domains, establishing a new operational paradigm for robotic servicing agents and laying a clear path for research in persistent, evolution-capable embodied autonomy.