- The paper demonstrates that momentum restricts sharpness by forcing batch sharpness to plateau at a momentum- and batch size–dependent threshold.
- It employs both extensive empirical experiments and mean-square stability analysis to reveal distinct sharpness regimes in small- versus large-batch settings.
- The results have practical implications for tuning hyperparameters, linking effective step size, momentum, and batch size with generalization and training stability.
Momentum-Induced Batch-Dependent Sharpness at the Edge of Stochastic Stability
The paper "Momentum Further Constrains Sharpness at the Edge of Stochastic Stability" (2604.14108) advances the understanding of how momentum methods in mini-batch stochastic gradient descent (SGDM/SGDN) interact with curvature constraints and the dynamic phenomenon known as the Edge of Stochastic Stability (EoSS). This work provides an empirical and theoretical analysis elucidating the batch-size–dependent behavior of curvature statistics under momentum, challenging established intuitions carried over from full-batch regimes and introducing critical implications for optimizer hyperparameterization, generalization, and the geometric understanding of neural network training.
Background and Context
Optimization in modern deep learning often operates near an instability boundary, where curvature statistics such as the maximum Hessian eigenvalue (λmax) or directional mini-batch curvatures self-organize around a critical threshold related to the learning rate. For full-batch gradient descent, sharpness at stationarity is well-characterized: training hovers around λmax≈2/η, and with momentum, around 2(1+β)/η [cohen_gradient_2021]. However, mini-batch SGD introduces stochasticity whose interaction with momentum modifies both stability and implicit bias.
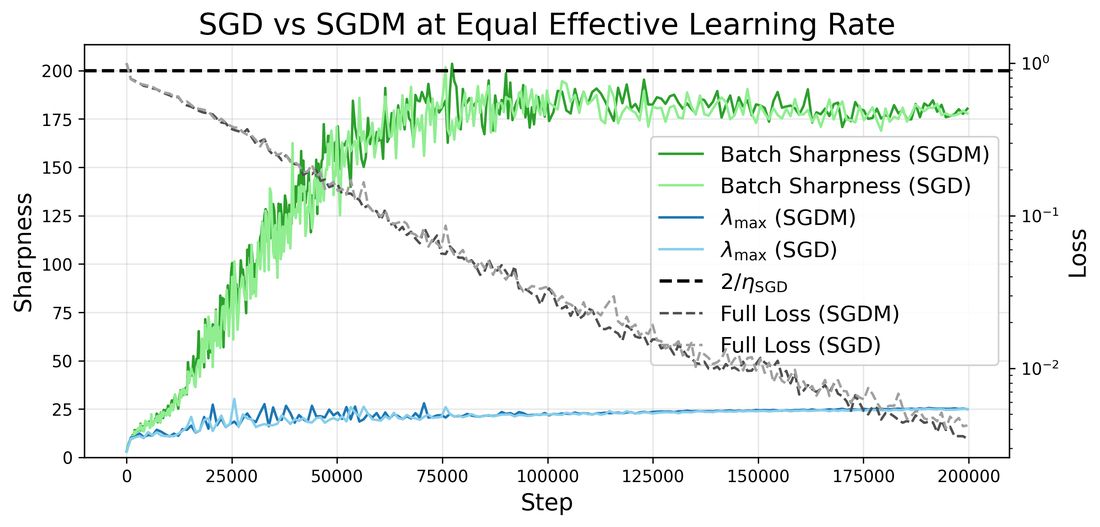
The central phenomenon, Edge of Stochastic Stability (EoSS), is characterized by the saturation of directional mini-batch sharpness (Batch Sharpness, BS) at a specific threshold, previously established as 2/η for vanilla SGD [andreyev_edge_2024]. Momentum introduces additional complexity, and this work interrogates whether and how self-organization at the edge occurs under momentum for both Polyak (SGDM) and Nesterov (SGDN) dynamics.
Empirical Findings: Regime-Specific Sharpness Plateaus
Through extensive experiments (MLPs, CNNs, ResNets, CIFAR-10/SVHN), the authors reveal that Batch Sharpness plateaus at values fundamentally dependent on batch size and momentum hyperparameters:
- Small-batch regime (b small): BS stabilizes at 2(1−β)/η, a threshold strictly below both vanilla SGD (2/η) and the deterministic momentum threshold (2(1+β)/η).
- Large-batch regime (λmax≈2/η0 large): λmax≈2/η1 matches the deterministic momentum threshold, i.e., λmax≈2/η2 for SGDM, λmax≈2/η3 for SGDN.
This behavior constitutes a "qualitative flip": momentum, typically understood as stabilizing and permitting sharper curvature in deterministic settings, induces tighter stability constraints and biases training toward notably flatter regions in noise-dominated (small-batch) settings.
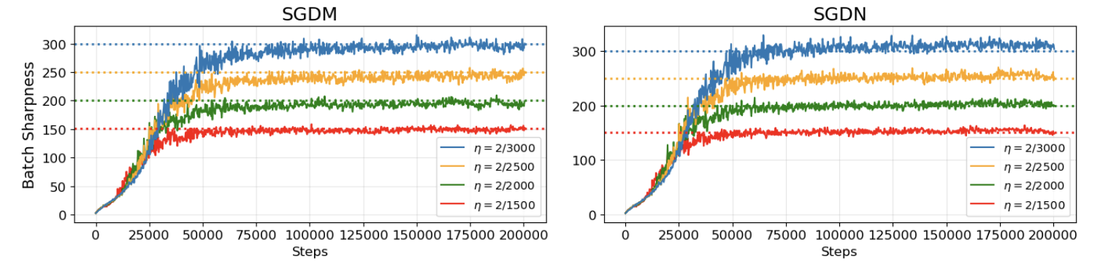
Figure 2: Batch Sharpness in SGDM and SGDN self-organizes near the batch-size-dependent EoSS threshold, transitioning between strict flatness at small λmax≈2/η4 and sharper, momentum-allowed levels at large λmax≈2/η5.
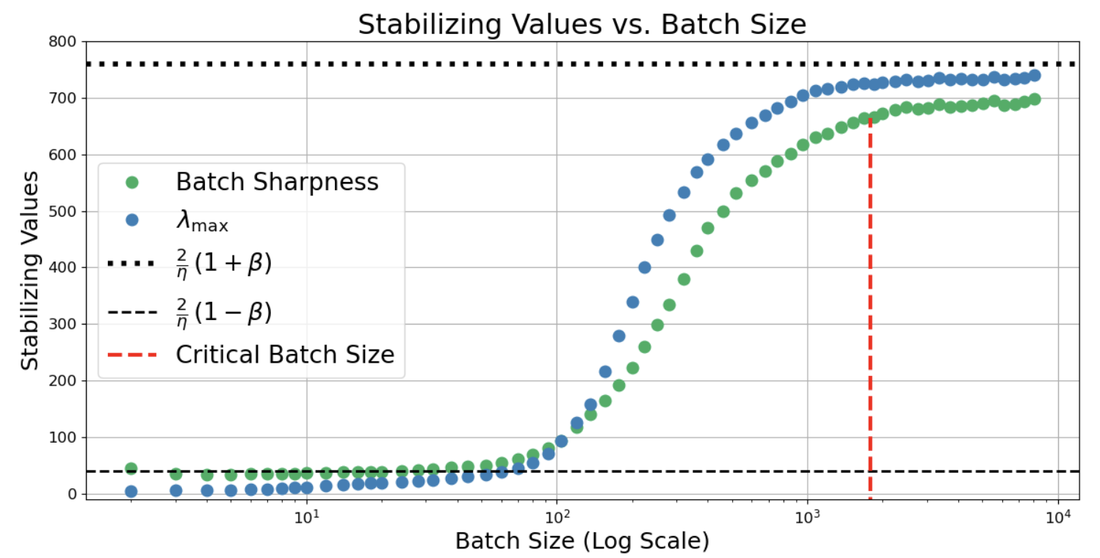
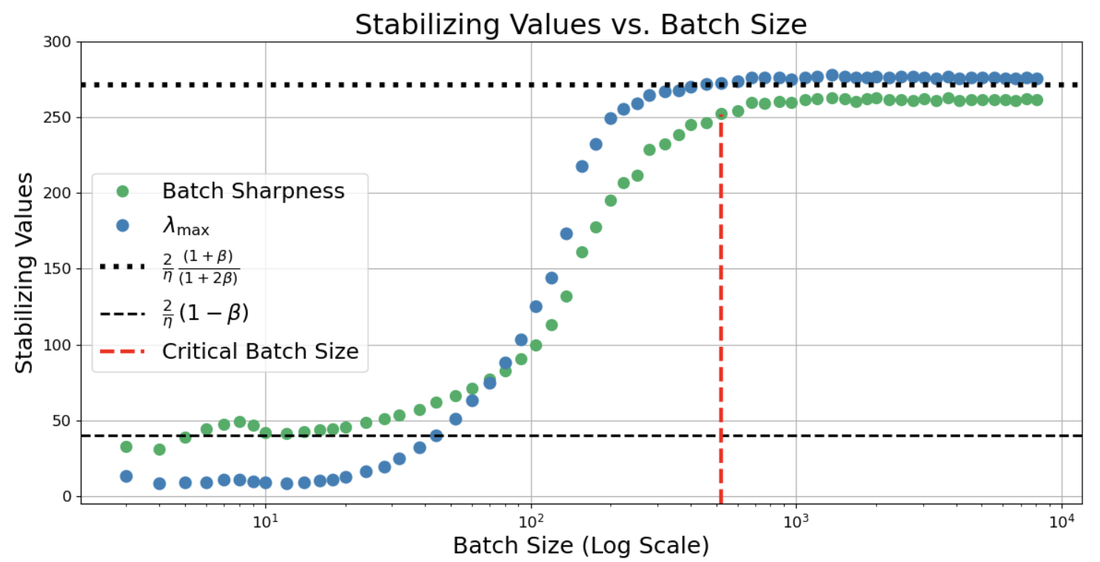
Figure 1: Batch Sharpness plateau increases monotonically with batch size, with distinct transitions for SGDM versus SGDN, the latter reaching deterministic regime at smaller λmax≈2/η6.
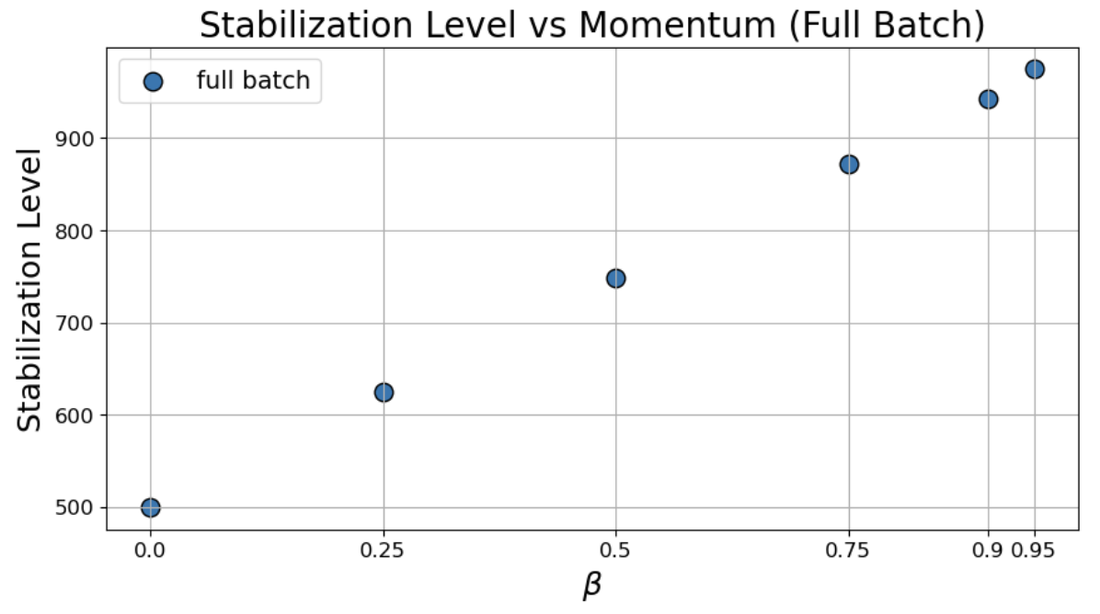
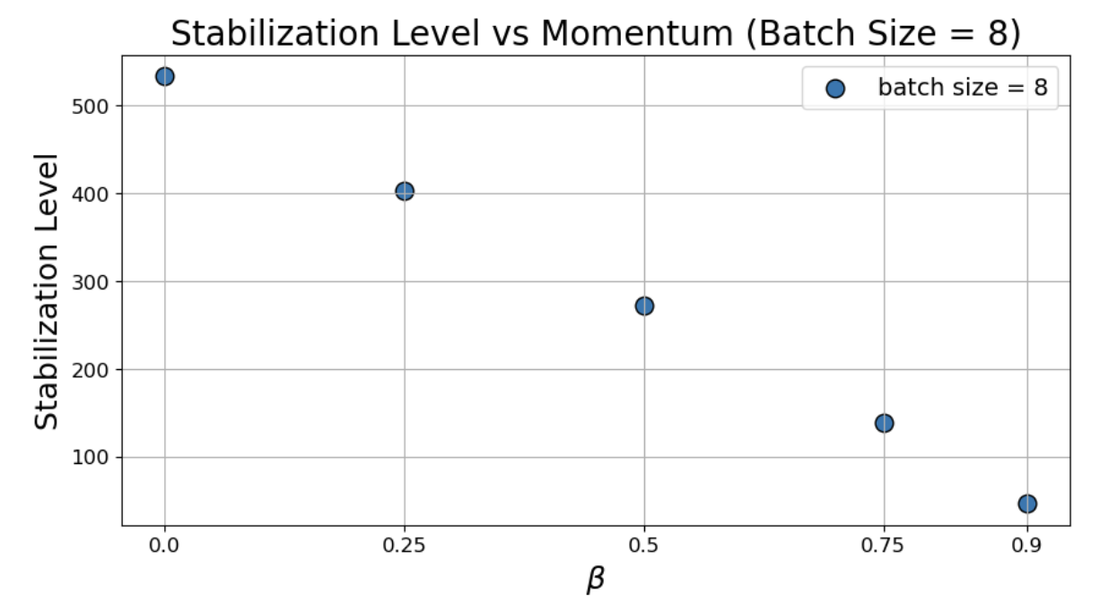
Figure 3: λmax≈2/η7 behavior in full-batch versus small-batch dynamics under fixed λmax≈2/η8 and variable λmax≈2/η9 highlights the reversal in monotonicity at small 2(1+β)/η0.
Mechanistic Explanation: Mean-Square Stability and Sharpness Criteria
A rigorous mean-square stability analysis houses the origin of these empirical thresholds. In the small-batch regime, the effective step size for SGDM becomes 2(1+β)/η1, mirroring the leading-order linearized stochastic stability of vanilla SGD but with momentum acting as a step-size amplifier for purposes of curvature constraint. Thus, the critical Batch Sharpness transitions to 2(1+β)/η2. In the deterministic regime, classical momentum stability theory applies.
This analysis aligns with Kronecker-structured operator perspectives, confirming noise-amplification mechanisms and providing an indirect theoretical warrant for the observed Batch Sharpness plateaus. However, the direct mapping from momentum-augmented mean-square stability to the stochastic sharpness measure in realistic, non-quadratic, high-dimensional settings remains an open question.
Instability-Adjacent Dynamics: Intervention Evidence
To operationally validate training at the EoSS boundary, the authors enact checkpoint interventions—perturbing 2(1+β)/η3, 2(1+β)/η4, or 2(1+β)/η5 mid-run:
This consistently demonstrates that training dynamics are not merely descriptive plateaus, but reflect true proximity to an instability boundary governed by Batch Sharpness.
Theoretical and Practical Implications
Hyperparameter Coupling and Implicit Bias
The batch-size–dependency of the instability threshold directly informs hyperparameter schedules. In small-batch training, the emergent effective step size BS5 should remain constant when tuning BS6, rationalizing empirical "coupling rules" for stability. Importantly, small-batch momentum may enhance implicit regularization, steering optimization towards flatter, potentially more generalizable solutions.
Limits of Diffusion, SGD+Noise, and SDE Models
Diffusion approximations that neglect the discrete-time or batch structure fail to capture the batch-size–sensitive sharpness constraints, reducing their utility in modeling optimizer-induced regularization effects.
Sharpness as a Diagnostic for Instability
Batch Sharpness emerges as the operative diagnostic for stochastic stability in momentum-accelerated mini-batch training. Unlike BS7, which is agnostic to batch size and optimizer, BS8 tightly predicts when sharpness-driven catapults will occur and where optimizer-determined flatness terminates.
Practical Tuning
Monitoring Batch Sharpness during training can provide dynamic feedback for adaptive control of BS9, 2/η0, or 2/η1 to remain near—but not beyond—the stochastic edge, maximizing stability without unnecessarily limiting curvature-admissible solutions.
Numerical Results and Contradictory Claims
- In the small-batch regime, momentum tightens rather than relaxes curvature constraints, directly contradicting the classical notion that momentum universally enlarges the set of admissible sharpness levels.
- The empirical sharpness thresholds are strongly batch-size dependent, and claims that "momentum-corrected" learning rates suffice to explain curvature behavior fail in the presence of batch-induced stochasticity.
Future Outlook
Open directions include:
- Formal derivation of instability criteria linking momentum dynamics to directional mini-batch curvature measures beyond linear/quadratic approximations.
- Characterizing momentum's effect on generalization, sharpness, and solution structure in large-scale, overparameterized regimes.
- Extending the diagnostic framework to adaptive methods (Adam, AdamW, Muon) with more complex second-moment dynamics.
- Dynamic, sharpness-based adaptive tuning of 2/η2 and 2/η3 to operationalize regularization control and stability in practical deep learning workflows.
Conclusion
This work robustly demonstrates that momentum modifies the landscape of stochastic stability in mini-batch deep learning, introducing two qualitatively distinct sharpness regimes. In small-batch training, momentum amplifies noise-driven curvature constraints, promoting flatter solution selection—an effect opposite to its deterministic role. By integrating empirical investigation, intervention-based diagnosis, and mechanistic analysis, the paper situates momentum optimizers within a refined EoSS framework and identifies Batch Sharpness as a central geometric quantity for both theoretical inquiry and practical optimizer design (2604.14108).