- The paper presents GRN integrating hierarchical binary quantization, global non-causal refinement, and entropy-guided sampling to address inefficiencies in diffusion and AR models.
- Detailed ablation studies show GRN achieves competitive FID scores and near-lossless reconstruction with as few as four quantization rounds on ImageNet.
- GRN’s adaptive refinement mechanism dynamically allocates computational steps, ensuring efficient synthesis across both image and video modalities.
Generative Refinement Networks: A Next-Generation Paradigm for Visual Synthesis
Motivation and Limitations of Existing Methods
Prevailing visual synthesis methods are dominated by diffusion models, especially transformer-based approaches, which achieve compelling results in image and video synthesis via iterative denoising of continuous representations. However, these models suffer from computational inefficiency due to their uniform allocation of inference steps for all samples, independent of sample complexity. Autoregressive (AR) models, while inherently adaptable to complexity via sequential token likelihoods, are limited by the quantization error of discrete representations and unmitigated accumulation of generation errors—issues exacerbated by strictly causal or masked decoding.
Generative Refinement Networks (GRN): Core Framework
The Generative Refinement Network (GRN) paradigm addresses the computational, representational, and optimization deficiencies inherent in both diffusion and AR models. GRN integrates three principal innovations:
- Hierarchical Binary Quantization (HBQ) enables high-fidelity, near-lossless discrete representation of images and videos by exponentially suppressing quantization error with layered, bitwise encoding.
- Global Refinement Mechanism allows non-causal, iterative revisitation of the entire token map, supporting erasing, filling, and retroactive correction of errors, thus overcoming error propagation of standard AR models.
- Entropy-Guided Complexity-Aware Sampling dynamically allocates refinement steps based on predicted token entropy, enabling adaptive computational cost to sample complexity with negligible quality loss.
Hierarchical Binary Quantization as Lossless Discrete Tokenizer
HBQ operates on continuous VAE-encoded features, recursively partitioning the value space with a binary tree over M rounds of coarse-to-fine quantization. Each round produces a bit, progressively refining the recovered image or video and rapidly decaying quantization error, theoretically achieving losslessness as M increases.
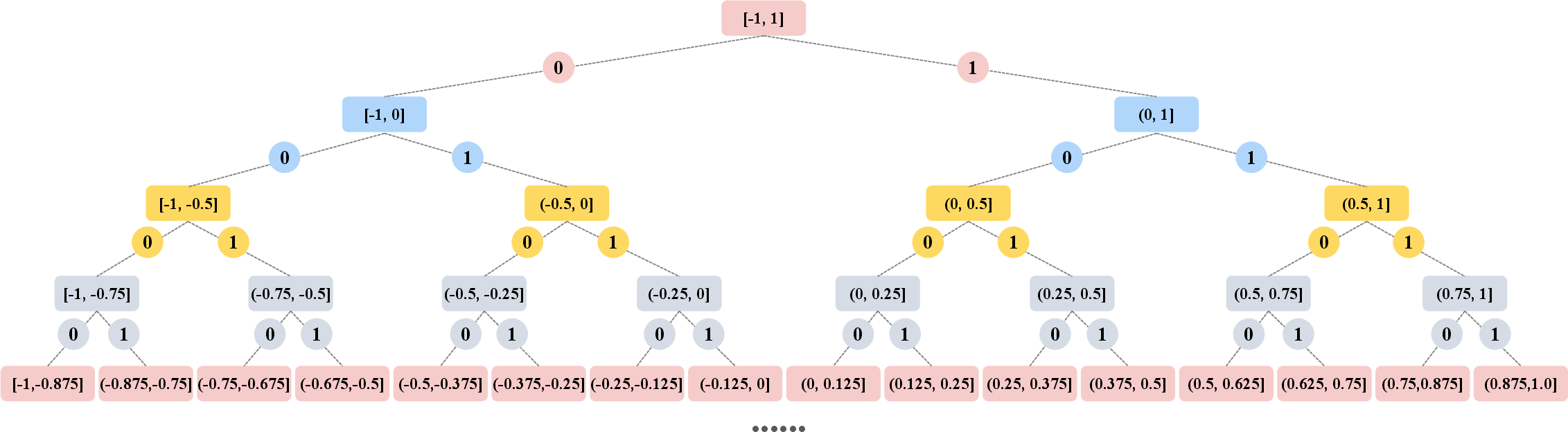
Figure 1: Each VAE feature undergoes several rounds of hierarchical binary quantization, with exponential decay in quantization error.
Empirical results indicate that with as few as four HBQ rounds, rFID drops to 0.56 on ImageNet at 256×256—substantially outperforming prior continuous and discrete tokenizers at equivalent or higher compression ratios.

Figure 2: Visualization of hierarchical quantization and progressive reconstruction for M=4.
Ablation studies further demonstrate that the 8-round HBQ matches continuous baselines without increasing latent channel count, establishing HBQ as the state-of-the-art in discrete latent tokenization for visual generation.

Figure 3: The 8-round HBQ configuration achieves parity with continuous-feature reconstruction baselines.
Global Refinement Sampling and Training
GRN initiates sampling with a random token map and partial state encoding (mixture of truth and noise). At each iteration, a transformer refines predictions globally—even on tokens previously predicted with high confidence—allowing for erasure and correction as context accumulates. The update mask is stochastically chosen, ensuring unbiased exposure to a mixture of correct and random contexts during training.

Figure 4: The GRN sampling process: partial filling, full refinement, and erasing unpredictable tokens is supported.
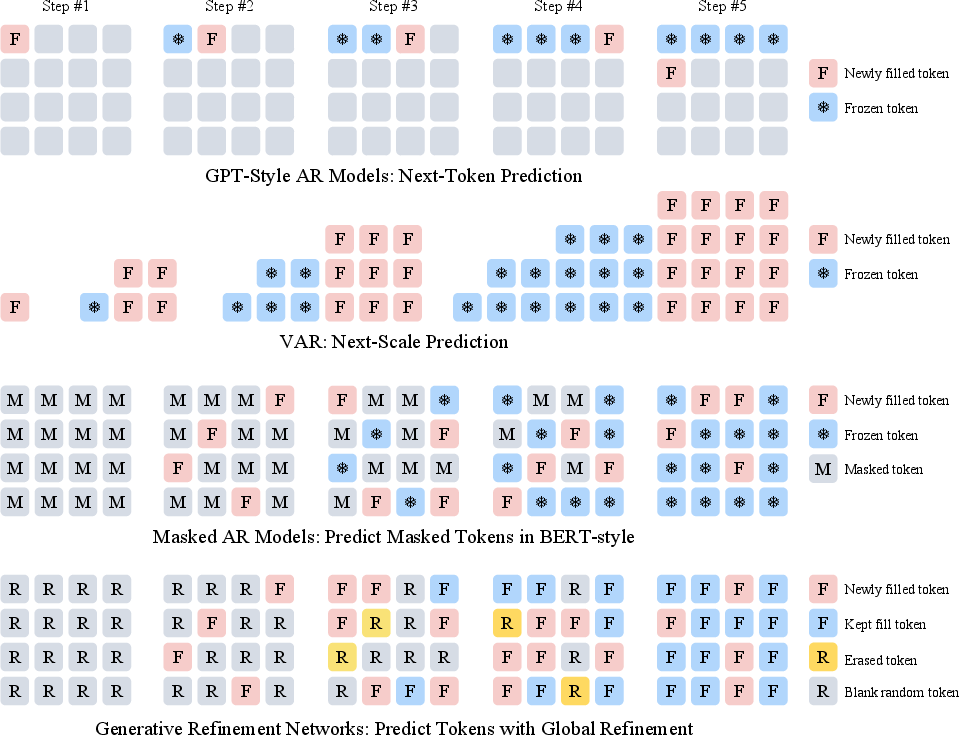
Figure 5: GRN's global refinement mechanism corrects and enhances the visual representation, in contrast to conventional AR methods which are fixed-order and prone to compounding errors.
Ablation results highlight the necessity of this mechanism: restricting to causal or fixed-token orders leads to model collapse and high FID, confirming that repeated flexible refinement is essential for stable AR visual synthesis.
Complexity-Aware, Adaptive-Step Generation
By adaptively controlling the refinement ratio based on each sample's predicted entropy, GRN achieves a spectrum of sampling complexity, efficiently allocating computational effort to more ambiguous or challenging samples while avoiding wasteful steps for simple ones. Histogram analysis confirms substantial compute savings: 62.7% of samples terminate prior to the hard cap, and about 200 complete in the absolute minimum steps allowed, with only minor FID degradation.

Figure 6: Illustration of GRN's adaptive refinement, showing generated image diversity for text-to-image samples under dynamic step allocation.
Benchmark Results: Image and Video Synthesis
On ImageNet 256×256 class-conditional image generation, GRN-G achieves FID 1.81 (rivaling or surpassing SOTA diffusion/flow and hybrid methods at similar parameter scales) and is strictly superior to competitive AR baselines by significant margins. The method consistently closes the performance gap between AR and diffusion architectures on both image and video domains.

Figure 7: Qualitative examples of GRN performance for class-to-image generation on ImageNet.
In text-to-image generation, GRN achieves GenEval scores (0.76 overall with a 2B parameter model) outperforming both SD3 Medium (0.62) and Infinity (0.71) at equivalent scales, rivaling much larger methods. For text-to-video, on VBench, GRN attains 82.99 overall, again outperforming both diffusion and AR competitors at similar or larger parameter counts.
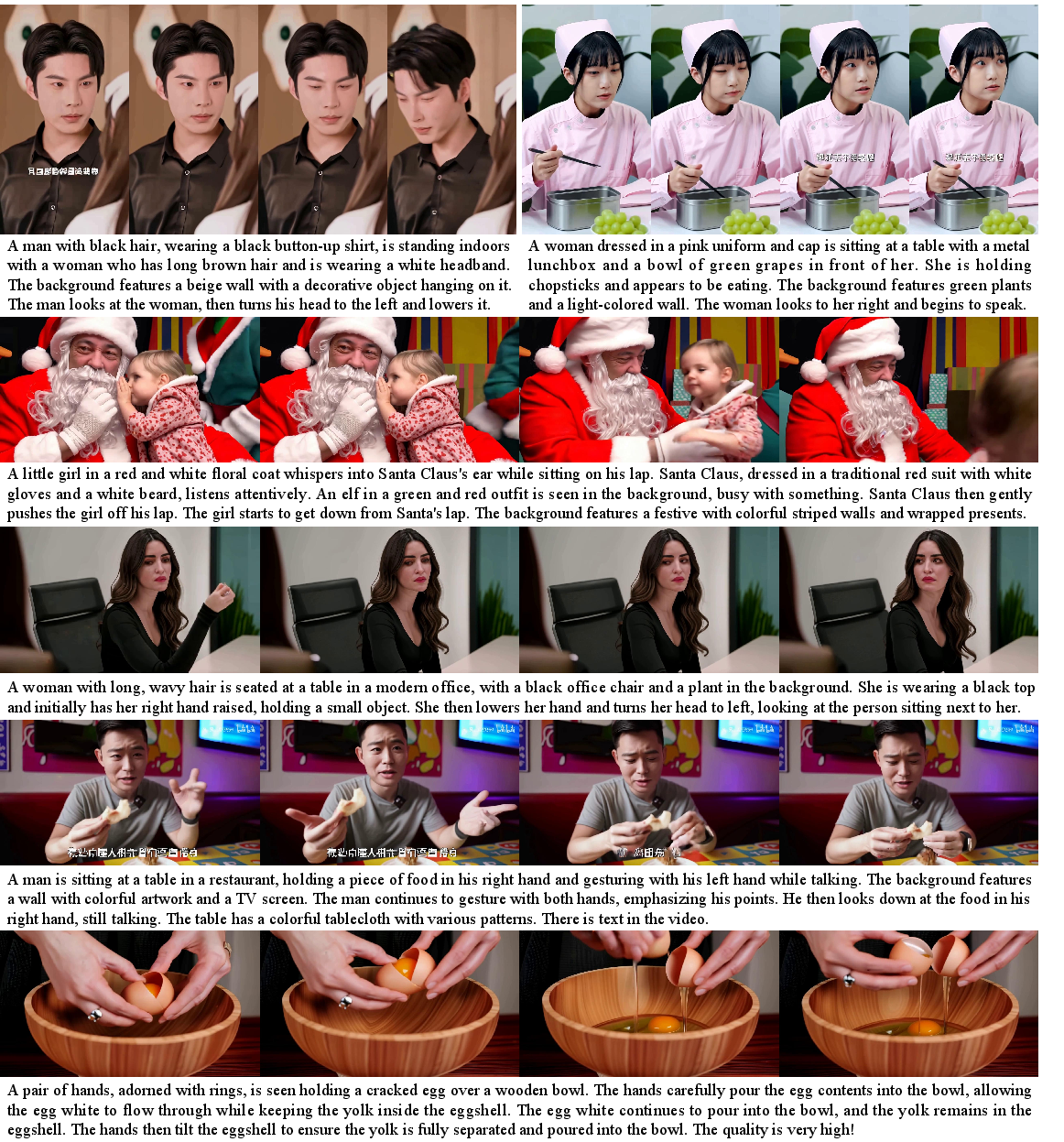
Figure 8: Sample video frames from GRN on text-to-video benchmarks. Output is high-fidelity, semantically controlled, and temporally consistent.
Scalability, Efficiency, and Modality Unification
The HBQ approach maintains competitive performance at high compression ratios and can be seamlessly scaled to high-resolution or long-duration visual synthesis without channel scaling or latent codebook explosion. By relying exclusively on discrete tokens, GRN facilitates direct, unified integration of visual generative modeling with language modeling architectures, removing the modality barrier inherent in continuous latent variable frameworks.
Implications and Future Directions
The advances presented with GRN have manifold implications:
- AR Model Viability: By eliminating the tokenization bottleneck and introducing efficient, flexible correction, AR architectures matched or exceeded diffusion/flow models in visual synthesis for the first time at similar scale.
- Computation-Efficiency Tradeoff: Adaptive refinement steps enable granular compute allocation, paving the way for more energy-proportional and real-time controllable synthesis.
- Multimodal Foundation Models: Since GRN operates fully on discrete representations, it allows for tight coupling with large-scale LLMs for text-image-video codejoint pretraining and decoding, advancing the development of unified multimodal models.
Despite its merits, scaling to extremely large models remains computationally constrained, and performance for non-human visual details in video may lag diffusion approaches—a limitation likely addressable with further scaling and curated data.
Conclusion
Generative Refinement Networks offer a unified solution to core limitations of visual generative modeling. By leveraging near-lossless hierarchical quantization and iterative global refinement, GRN achieves state-of-the-art performance across image and video domains, with superior efficiency and foundation model compatibility. These innovations not only re-establish the competitiveness of AR models but also chart a path toward unified, scalable, and fully discrete multimodal generative frameworks (2604.13030).