- The paper presents a structured, hierarchical model that decomposes images into stages for fine-to-coarse synthesis.
- It employs a dual-generation pipeline with structure and content generators guided by RoPE and refined embeddings.
- Empirical results on ImageNet show improved FID, Inception Score, and recall with fewer parameters.
Next Visual Granularity Generation: Structured, Hierarchical Image Synthesis
The "Next Visual Granularity Generation" (NVG) framework introduces a novel paradigm for image generation by explicitly modeling and controlling hierarchical visual structure. Unlike prior approaches that treat images as flat sequences or holistic distributions, NVG decomposes images into a sequence of stages, each corresponding to a distinct level of visual granularity. This enables structured, coarse-to-fine synthesis and fine-grained control over the generative process.
Hierarchical Visual Granularity: Representation and Construction
NVG represents an image as a sequence of content and structure pairs, each at a fixed spatial resolution but with a varying number of unique tokens. At each stage, a structure map defines the spatial arrangement of tokens, and a content vector specifies the token values. The construction of this sequence is fully data-driven: starting from the finest granularity (each spatial location is a unique token), tokens are iteratively clustered based on feature similarity, halving the number of unique tokens at each stage. This bottom-up clustering yields a hierarchy of structure maps, naturally capturing the progression from fine details to global layout.




Figure 1: Construction of the visual granularity sequence on a 2562 image and the next visual granularity generation in the 162 latent space. Top-to-bottom: Number of unique tokens, structure map, generated image.
The content tokens for each stage are constructed in a residual manner, quantizing the difference between the current canvas and the ground truth latent. This approach, inspired by VAR but guided by the induced structure map rather than spatial downsampling, results in a more semantically meaningful decomposition and improved codebook utilization.
Structure Embedding and Hierarchical Encoding
To encode the hierarchical relationships across stages, NVG introduces a compact structure embedding scheme. Each spatial location is assigned a K-dimensional bit-style vector, where each bit encodes the parent-child relationship at a given stage. This embedding is RoPE-compatible and enables efficient, stage-aware positional encoding for both content and structure generators.

Figure 2: K-dimensional structure embedding encodes parent-child relations across all stages, with padding and bit patterns distinguishing clusters and stages.
Generation Pipeline: Stage-wise Structure and Content Synthesis
The NVG generation pipeline alternates between structure and content generation at each stage. At each step, the structure generator predicts the structure map for the current granularity, conditioned on the input text, the current canvas, and the hierarchical structure embedding. The content generator then predicts the content tokens for the current structure, refining the canvas towards the final image.
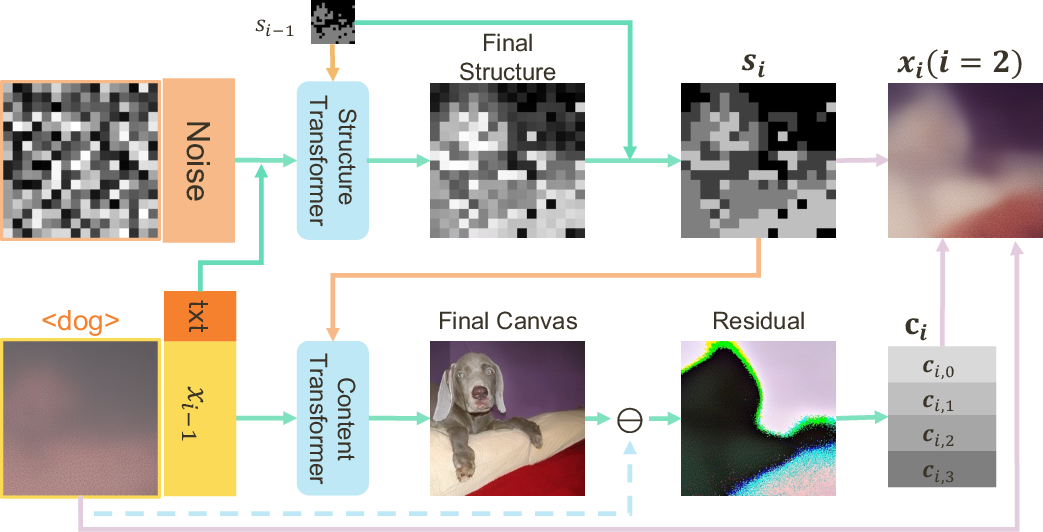
Figure 3: At each stage, structure is generated first, followed by content, both conditioned on text, current canvas, and hierarchical structure.
The structure generator employs a lightweight rectified flow model, treating structure prediction as a structure inpainting task. Known parts of the structure embedding are fixed, and the model predicts the remaining unknowns. Gumbel-top-k sampling is used to increase diversity in structure assignment. The content generator uses a transformer-based architecture with structure-aware RoPE, predicting the final canvas and the content tokens for the current stage. Training is supervised by both MSE loss on the canvas and cross-entropy loss on the content tokens.
Empirical Results: Quantitative and Qualitative Analysis
NVG models are evaluated on class-conditional ImageNet generation, demonstrating strong scaling behavior and outperforming the VAR baseline in FID, Inception Score, and recall across all model sizes. Notably, NVG achieves these results with fewer training steps and parameters compared to many state-of-the-art models.

Figure 4: Iterative generation process (top), alignment of structure maps with final images (middle), and diverse, high-quality samples from NVG-d24 (bottom).
Ablation studies confirm the importance of autoregressive content modeling, partial noise in structure inpainting, and structure-aware RoPE. Direct prediction of the next content token (as opposed to the final canvas) leads to overfitting and degraded performance, highlighting the benefit of richer supervision.
Structure-Guided and Stage-wise Controlled Generation
A key advantage of NVG is explicit structure control. By providing custom structure maps—such as geometric shapes or reference image structures—users can guide the generation process, enabling flexible and interpretable manipulation of image layout and semantics.

Figure 5: Structure-guided generation using geometric binary structure maps and reference image structures.
Stage-wise control experiments demonstrate that fixing structure and/or content at different stages allows for precise manipulation of layout, pose, and fine details. The model exhibits strong error-correction capabilities, enabling it to adapt to out-of-distribution class labels even when early-stage structure/content is fixed.

Figure 6: Stage-wise controlled generation: top—reference reconstruction; middle—content and structure fixed; bottom—structure only fixed, with in-domain and OOD class guidance.
Theoretical and Practical Implications
NVG addresses a key limitation of prior generative models: the lack of explicit, hierarchical structure modeling. By decomposing images into sequences of increasing granularity and guiding generation through structure-aware mechanisms, NVG enables:
- Fine-grained, interpretable control over the generative process at multiple levels of abstraction.
- Improved codebook utilization and more semantically meaningful tokenization compared to scale-based approaches.
- Efficient, few-step generation with strong scaling properties, making it suitable for high-resolution synthesis.
- Error correction and flexible adaptation to new conditions, surpassing the rigidity of autoregressive models.
Future Directions
The explicit structure modeling in NVG opens several avenues for further research:
- Region-aware generation: Leveraging domain-specific annotations to define custom granularity sequences for targeted control.
- Physically-aware video generation: Tracking structured regions over time to enforce temporal coherence and physical constraints.
- Hierarchical spatial reasoning: Integrating NVG with spatial reasoning models to enable divide-and-conquer inference in visual tasks.
Conclusion
The NVG framework represents a significant advance in structured image generation, providing a principled approach to hierarchical decomposition and control. Its empirical performance, scalability, and flexibility suggest broad applicability in domains where structure and interpretability are paramount. The explicit separation of structure and content, combined with stage-wise generation, offers a new foundation for controllable, efficient, and semantically meaningful generative modeling.

